
In this blog, I’ll share my experience and method to Build a Machine Learning Model for predicting Heart Disease.

Dataset Used– https://www.kaggle.com/ronitf/heart-disease-uci
About the dataset:
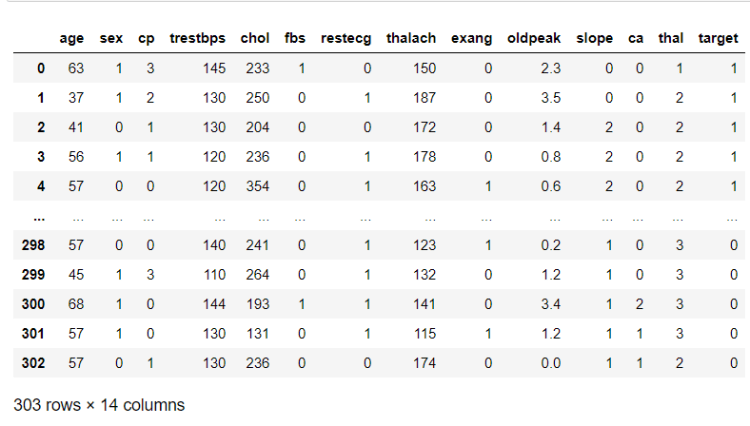
So as you all can see this dataset contains 14 features.
- age: The person’s age in years
- sex: The person’s sex (1 = male, 0 = female)
- cp: The chest pain experienced (Value 1: typical angina, Value 2: atypical angina, Value 3: non-anginal pain, Value 4: asymptomatic)
- trestbps: The person’s resting blood pressure (mm Hg on admission to the hospital)
- chol: The person’s cholesterol measurement in mg/dl
- fbs: The person’s fasting blood sugar (> 120 mg/dl, 1 = true; 0 = false)
- restecg: Resting electrocardiographic measurement (0 = normal, 1 = having ST-T wave abnormality, 2 = showing probable or definite left ventricular hypertrophy by Estes’ criteria)
- thalach: The person’s maximum heart rate achieved
- exang: Exercise induced angina (1 = yes; 0 = no)
- oldpeak: ST depression induced by exercise relative to rest (‘ST’ relates to positions on the ECG plot. See more here)
- slope: the slope of the peak exercise ST segment (Value 1: upsloping, Value 2: flat, Value 3: downsloping)
- ca: The number of major vessels (0–3)
- thal: A blood disorder called thalassemia (3 = normal; 6 = fixed defect; 7 = reversable defect)
- target: Heart disease (0 = no, 1 = yes)
Steps to be followed while creating a Heart Disease Model are: —

- Load the necessary libraries.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.cm import rainbow
from matplotlib import rcParams
%matplotlib inline
import warnings
warnings.filterwarnings(‘ignore’)
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import cross_val_score
from sklearn.metrics import confusion_matrix
#importing 3 different classifiers KNeighborsClassifier, DecisionTreeClassifier, RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
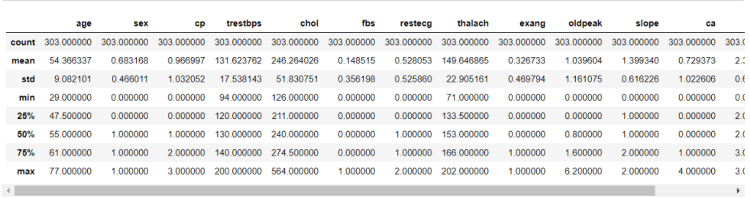
2. Get the dataset description
df.describe()
3. Get the dataset information
df.info()

4. Perform some Data Preprocessing and StandardScaler
#Data Preprocessing.
dataset = pd.get_dummies(df, columns = [‘sex’, ‘cp’, ‘fbs’, ‘restecg’, ‘exang’, ‘slope’, ‘ca’, ‘thal’])
standardScaler = StandardScaler()
columns_to_scale = [‘age’, ‘trestbps’, ‘chol’, ‘thalach’, ‘oldpeak’]
dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
5. Fix your data in X and y.
y = dataset[‘target’]
X = dataset.drop([‘target’], axis = 1)
Here y-axis contains target data and X-axis contains rest all the features.
6. Now let’s split the dataset into training and testing for this we will use train_test_split library.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
Here I have kept 25% for testing and the rest 75% is for training the model.
Top 4 Most Popular Ai Articles:
3. Real vs Fake Tweet Detection using a BERT Transformer Model in few lines of code
7. Now decide the model and try to fit the dataset into it. Here we are going to use KNN classifier to classify the data.
knn_classifier = KNeighborsClassifier(n_neighbors = 5, metric = ‘minkowski’, p = 2)
knn_classifier.fit(X_train, y_train)
y_pred_knn=knn_classifier.predict(X_test)
knn_classifier.score(X_test,y_test)
OUTPUT
88.15% Accuracy.
Our accuracy is 88.15%. Our accuracy is good. Try out the dataset with different classifier model and comment me your accuracy.
To view my GitHub repository Click here
I’ll try the same dataset with TensorFlow also and soon post the blog for that too. So follow me so that you can get my blog updates regularly.
I hope you like this blog. Feel free to share your thoughts in the comment section and you can also connect with me in:-
Linkedin — https://www.linkedin.com/in/shreyak007/
Github — https://github.com/Shreyakkk
Twitter — https://twitter.com/Shreyakkkk
Instagram — https://www.instagram.com/shreyakkk/
Snapchat — shreyak001
Facebook — https://www.facebook.com/007shreyak
Thank You!
Don’t forget to give us your ? !




Machine Learning Model For Predicting Heart Disease was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
