

Introduction
Computer vision is a field under development that is improving quickly with new researches and ideas. Millions have been invested in technology and the benefits has spread in many fields like autonomous driving, health, security and banking. One of the works that meant a huge leap towards the improvements of the networks that processes images and makes computer vision posible was the winner from the ILSVRC 2012 competition.
The work of Krizhevsky, Sutskever and Hinton in his paper ImageNet Classification with Deep Convolutional Neural Networks is one of the most influential in computer vision. They called the architecture of the network AlexNet.

The purpose of this writing is to explain AlexNet, what it brings over previous convolutional network architectures and what procedures were involved to be so influential in the field.
Trending AI Articles:
3. Real vs Fake Tweet Detection using a BERT Transformer Model in few lines of code
Before continuing, is important to know that in the field of computer vision, the convolutional neural networks are of great importance. The inclusion of convolutional layers in a network allows to process a huge amount of parameters and perform a classification by highlighting the most important features of an image. An architecture of a network may differ in it’s resulting test error in the task of classifying an images under a category and also how good is its performance over datasets which has not be included in the training.

Procedures
What did they do to be winners of the competition and have such good results?
- First it is important to know which data they used. In the case of the ILSVRC competition, it has a subset of the ImageNet with roughly 1000 images for each of the 1000 categories. They took advantage of the ILSVRC-2010 data set which has test set labels to perform the majority of their experiments. The pictures from ImageNet are of variable resolution but their system required constant dimensions so they cropped them to 256 x 256 each with RGB.
- They put several novels on their architecture that today are very used. The use of the ReLu nonlinearity as an activation for the neurons is a very important feature that allowed faster training over the use of Tanh or sigmoid.
- Two GTX 580 GPUs with 3GB of memory with parallelization scheme helped them to train the over 1.2 million examples they used for training the networks.

- ReLu makes unnecessary the normalization of input to prevent saturating but they used Local Response Normalization (LRN) that helps normalize data. That reduced top-1 and top-5 error rates by 1.4% and 1.2%, respectively.
- To avoid overfitting they used data augmentation, dropout and weight decay (0.0005) as regularization methods. To optimize, they separated the process in batch sizes of 128 examples using gradient descent, also used momentum of 0.9.
The architecture
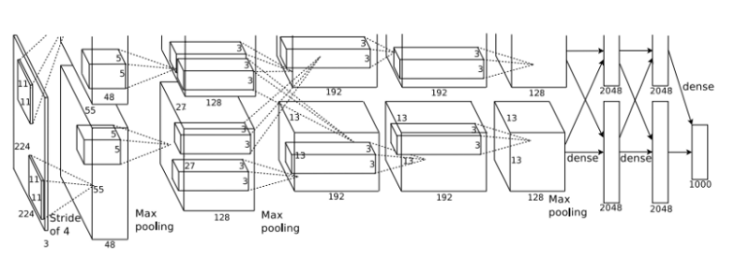
The network contains 8 layers in total, 5 are convolutional layers and 3 are fully connected layers. At the end of each layer ReLu activation is performed except for the last one which outputs with a softmax with a distribution over the 1000 class labels. Dropout is applied in the first two fully connected layers. As the figure from above shows, they also apply Max-pooling after the first, second and fifth convolutional layer. Remember that each input image has dimensions of 224 x 224 x 3 since are color images although later discussion of the paper says that 227 x 227 x 3 makes more sense for the dimension calculations for the next of the network.
Results
- I think that what is most important from their work is the use of ReLu which will mark a general use of this activation function after the paper for most works of convolutional neural networks. They got from testing with CIFAR-10 dataset a 25% training error rate that was six times faster than Tanh.
- I was also very important for this field the use of multiple GPUs since training requieres a lot of iteration and time. Faster computation means more testing and that way more discovers.
- The results in numbers they obtained was of 37.5% for top-1 and 17.0% for top-5 error rate. For ImageNet, these two errors are report, top-1 is the normal error rate for classification and top-5 is the fraction of test images which correct label is not among the five labels considered most probable my the model. This result surpassed results of previous convolutional neural networks.

Conclusion
AlexNet is a work of supervised learning and got very good results. It is not easy to have low classification errors without having of overfitting. They say that removing one convolutional layer from their network would reduce drastically the performance so its no easy task to choose the architecture. It was also important the selection of methods like dropout and data augmentation that helped the performance of the network. Finally, the tools they used sped up a training process which otherwise would be very daunting with 1.2 million high resolution images.
Personal Notes
- What impresses a lot is the carefully crafted result of their network, it involved a lot of testing and decision because every run of the model would take a lot of time. The idea of put one element and a layer where it is made a difference and every % reduction of error counted.
- It is no easy work to avoid overfitting when you build a bigger neural network while you keep a low classification error. Regularization is very important.
- There are many opensource datasets with labeled data like CIFAR and ImageNet that didn’t exists that today makes possible to train models and facilitate investigations.
- Hackatons and challenges encourages the generation of ideas. They bring solutions to common problems on society so its nice that such competitions are promoted and more people participate.
- AlexNet is still relevant today but it is true that there are new researches. It is important for someone who wants to dig into Machine Learning field to know how to read papers and gather the information on how the networks depicted were constructed.
References
- ImageNet Classification with Deep Convolutional Neural Networks
- ImageNet Large Scale Visual Recognition Competition 2012 (ILSVRC2012)
Don’t forget to give us your ? !




Explanation of AlexNet and its leap for CNNs was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
