
Welcome to My Week in AI! Each week this blog will have the following parts:
- What I have done this week in AI
- An overview of an exciting and emerging piece of AI research
Progress Update
Discovering Metric Learning
I have spent a lot of time this week reading the latest literature on time series forecasting and visual search, as I am working on projects in these two areas.
During my research into visual search, I came across the Pytorch Metric Learning library. Metric learning is automatically building task-specific distance metrics from supervised data instead of using a standard distance metric such as Euclidean distance. This task is especially important for developing a metric to determine image similarity, which is the primary application I was considering. The library allows easy implementation of loss functions and miners with regards to metric learning, such as triplet loss, angular loss, tuple miners and subset batch miners. I believe this is a very convenient library for anyone implementing visual search algorithms.
Trending AI Articles:
1. Natural Language Generation:
The Commercial State of the Art in 2020
4. Becoming a Data Scientist, Data Analyst, Financial Analyst and Research Analyst
Emerging Research
Multivariate Time Series Forecasting
The research I will be featuring this week is on time series forecasting. I have been working on time series forecasting for a year now through my work at Blueprint Power, so I try to keep abreast of the latest advancements in this field.
The forecasting of multivariate time series is challenging as it is high dimensional, has spatial-temporal dependency characteristics and each variable depends not only on its own past values but on the values of other variables, too. Du et al. proposed a novel method of forecasting such time series in their paper, ‘Multivariate time series forecasting via attention-based encoder-decoder framework.’¹
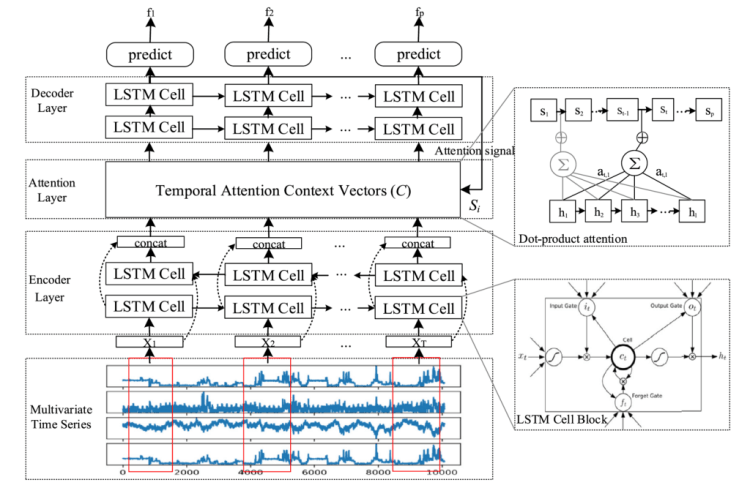
The researchers’ proposed framework was made up of a Bi-LSTM encoder, a temporal attention context layer and an LSTM decoder. The attention layer is important because in a typical encoder-decoder structure, the encoder compresses the hidden representation of the time series into a fixed length vector, which means information can be lost. The temporal attention context vectors are created based on a weighted sum of the hidden states of the encoder, and give context on which parts of these hidden states are most useful to the decoder. This allows the decoder to extract the most useful information from the outputs of the encoder.
In experiments on commonly used time series datasets, this proposed framework performed better than vanilla deep learning models such as LSTM and GRU, and also better than other encoder-decoder architectures. For me, the key takeaways from this research are the use of the Bi-LSTM encoder, which the researchers demonstrated had improved performance over an LSTM encoder, and also that the addition of the attention layer improved performance. These are two methods that I will be looking to integrate into my time series forecasting work in the future.

Join me next week for an update on my week’s work and an overview of a piece of exciting and emerging research. Thanks for reading and I appreciate any comments/feedback/questions.
References
[1] Du, Shengdong, et al. “Multivariate Time Series Forecasting via Attention-Based Encoder–Decoder Framework.” Neurocomputing, vol. 388, 2020, pp. 269–279., doi:10.1016/j.neucom.2019.12.118.
Don’t forget to give us your ? !




My Week in AI: Part 4 was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Via https://becominghuman.ai/my-week-in-ai-part-4-f7dd694dbdc6?source=rss—-5e5bef33608a—4
source https://365datascience.weebly.com/the-best-data-science-blog-2020/my-week-in-ai-part-4
