

Face Presentation Attack Detection a.k.a Face Anti-spoofing
Face recognition is one of the most convenient biometric for access control. The wide popularity of face recognition can be attributed to ease of acquisition with cheap sensors, contact-less nature, high accuracy of algorithms, and so on. While everything is well and good there, the vulnerability to presentation attacks limits its use in safety-critical situations.
Imagine your phone locked with face recognition being unlocked by someone simply showing a photo or video of you in front of the phone. There you have it, its called a presentation attack (also known as spoofing attacks). The design of face recognition systems mostly optimizes for telling people apart, such a network may not be able to tell whether the face in front of it is real (bonafide)or an attack .
Before you take your phone to disable face recognition, there is good news. Researchers have been working on this problem for years, and there is some level of resistance built into commercial face recognition systems these days. The methods which can identify these attacks are known as presentation attack detection (PAD) methods, which is essentially classifying each image as real or spoof.
Here are a few images from publicly available attacks (Taken from [Paper]). Can you tell apart which ones are real and which ones are attacks?

As you can see it is not very easy to say whether they are real or not (Answers at the bottom of the page). It would become more and more difficult once we have better cameras and screens.
There are several publicly available datasets for doing PAD research. Most of them consider print and replay attacks.
Trending AI Articles:
1. Natural Language Generation:
The Commercial State of the Art in 2020
4. Becoming a Data Scientist, Data Analyst, Financial Analyst and Research Analyst
This doesn’t mean the problem is solved. In fact, its very far from being solved. The main two challenges with PAD approaches are:
Unseen attacks
Most of the PAD methods treat the problem as a binary classification problem. But, it can be seen that the quality of attacks can evolve with the improved quality of capturing and display devices, which makes it an arms race. Also, creative attackers can come up with novel types of attacks (makeups, masks), etc to fool the PAD systems. It becomes difficult to detect attacks which has not been seen in training. In general, most of the methods fail against unseen attacks.
Cross-database performance
It can be seen that a lot of work in presentation attacks focus on cross-database performance. Methods, especially deep learning methods tend to overfit to the biases in a dataset, which might achieve good results in the intra-dataset scenario but could fail miserably when tested in a different dataset. It can be thought of as, the networks are learning some inherent biases in the datasets rather than learning the useful differences between real and spoof images. This is particularly important if we want to deploy a PAD system in real-world conditions.
Here is an implementation
Most of the recent state of the art methods are CNN based. Ideally, a frame-level PAD system should decide by just processing a single frame.
Here I introduce an introductory network for PAD. The architecture uses a densely connected neural network trained using both binary and pixel-wise binary supervision called DeepPixBiS.
Here the idea is to predict the pixel /patch-wise labels of an image for PAD. The labels for real and attacks are shown below.
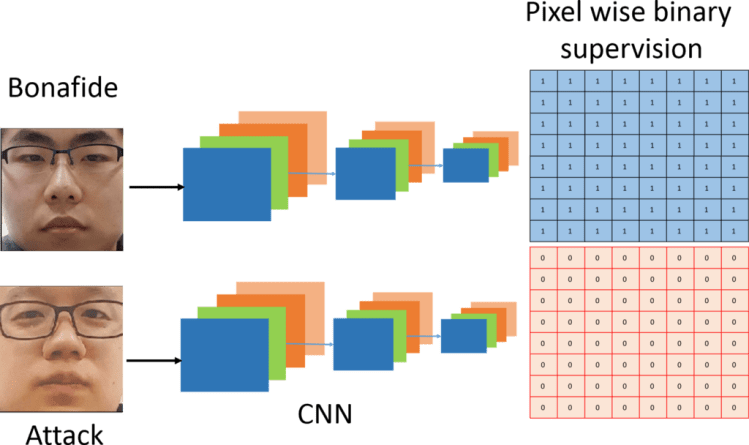
For a fully convolutional network, the output feature map from the network can be considered as the scores generated from the patches in an image, depending on the receptive fields of the convolutional filters in the network. Each pixel/ patch is labeled as bonafide or attack. In a way, this framework combines the advantages of patch-based methods and holistic CNN based methods using a single network. For a 2D attack, we can consider all the patches have the same label. The advantage here is that the pixel-wise supervision forces the network to learn features that are shared, thus minimizing the number of learnable parameters significantly.

The architecture is based on DenseNet, you can look at our open-source implementation if you would like to try it out.
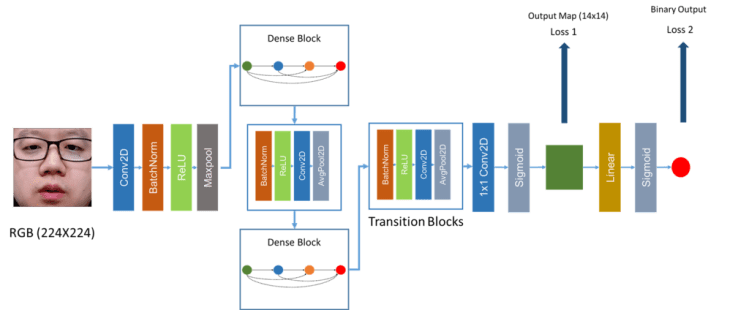
We have seen that there are limits to what RGB only PAD can do. In the next article, we will focus on how to improve multiple channels of information to improve the results.
Answer to quiz: In each pair, the one on the left is real, and the other one is an attack.
The source codes (PyTorch) are available in the following link:
bob / bob.paper.deep_pix_bis_pad.icb2019
And the reference paper is available at:
Don’t forget to give us your ? !




Face Presentation Attack Detection a.k.a Face Antispoofing was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
