

Welcome to My Week in AI! Each week this blog will have the following parts:
- What I have done this week in AI
- An overview of an exciting and emerging piece of AI research
Progress Update
Testing for machine-learning code
In my work this week at Blueprint Power, I spent a lot of time developing time series forecasting models. It is important that these models are robust from a software engineering perspective; a part of that is unit testing, which is not an easy task for machine-learning code. There are several reasons why this is difficult, including:
· A bug can be confused with poor model architecture or hyperparameters
· We don’t always know what the expected outputs should be
· Interpretability is difficult with neural networks, so it can be hard to pinpoint where an error occurs

Unit testing is especially challenging when using a deep learning framework, such as PyTorch, where much of the computation is done for you by the framework. That is why I was excited to come across torchtest, a library that directly tests for common bugs in a PyTorch deep learning model. The library tests for four bugs:
1. Variables that are supposed to change during training change, and the variables that are not supposed to change don’t change
2. Output range of the logits is unreasonable (as defined by the user)
3. There are no NaN outputs
4. There are no inf outputs
This library makes implementing unit tests for PyTorch code much easier. Although it is limited because it does not allow you to reach 100% test coverage, it is a start, and should make model development a less frustrating process as I will be able to catch and identify bugs more quickly.
Trending AI Articles:
1. Natural Language Generation:
The Commercial State of the Art in 2020
2. This Entire Article Was Written by Open AI’s GPT2
3. Learning To Classify Images Without Labels
4. Becoming a Data Scientist, Data Analyst, Financial Analyst and Research Analyst
Emerging Research
Identifying unknown samples at test time
As I mentioned in my last post , this week I’m presenting research on the use of autoencoders in computer vision, specifically in open-set recognition. ‘C2AE: Class Conditioned Auto-Encoder for Open-set Recognition’ by Oza and Patel presents a new, open-set recognition method based on class-conditioned auto-encoders that divides the open-set problem into sub-tasks. The open-set problem occurs when a classification algorithm sees an unknown class sample during inference and is forced to classify this sample as a class from the closed-set used in training. This negatively impacts the performance of such a classifier. In this scenario, we would instead like to classify that sample as ‘unknown’.
The proposed method splits the open-set recognition task into two sub-tasks: closed-set classification and open-set identification. The closed-set classification sub-task is trained using the commonly used encoder and classifier architecture. The open-set identification sub-task is split into two further components: conditional decoder training and Extreme Value Theory modeling of the reconstruction errors. For conditional decoder training, the encoder is used to extract the latent vectors and then the decoder is trained to perfectly reconstruct the original input when given the label condition vector matching the class of the input. In this research, the decoder was also trained to badly reconstruct the original input when given the label condition vector that does not match the class of the input. The authors showed that this non-match training was representative of an open-set situation at inference. Next, Extreme Value Theory modeling was used to model the reconstruction errors and to classify a sample as known/unknown.
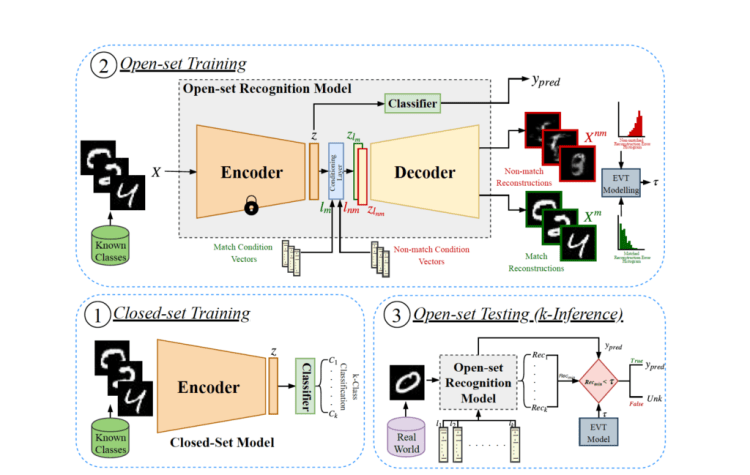
The researchers saw significant improvement when evaluating this method against previous state-of-the-art techniques,, and this approach also achieves a near 0.2 increase in F-score performance on the Labeled Faces in the Wild dataset when compared with the next best method.
I found this work fascinating as it provides a strong and interpretable solution to the problem of samples of unknown classes during inference. Beyond naively setting a threshold on the Softmax values to classify low probability samples as ‘unknown’, I had not previously considered any solutions to this problem. I also thought this was a noteworthy use of autoencoders, which are becoming more and more prevalent in deep learning literature.
Next week I will be presenting more of my work in AI, and once again, sharing a piece of exciting research. Thanks for reading and I appreciate any comments/feedback/questions.
References
[1] Oza, P., & Patel, V. M. (2019). C2AE: Class Conditioned Auto-Encoder for Open-Set Recognition. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). doi:10.1109/cvpr.2019.00241
Don’t forget to give us your ? !




My Week in AI: Part 7 was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Via https://becominghuman.ai/my-week-in-ai-part-7-15d86038dd7a?source=rss—-5e5bef33608a—4
source https://365datascience.weebly.com/the-best-data-science-blog-2020/my-week-in-ai-part-7
