
I have struggled in the past to really understand the real meaning behind the use of activation functions in the CNN architecture.
I will try to make it very clear using a simple use case
Let’s take a 3 layer neural Network architecture (below figure), w1, w2, w3, b1, b2, b3 are the weight vectors and bias vectors between the layers. Assume X [x1, x2, x3] is the input to the network.
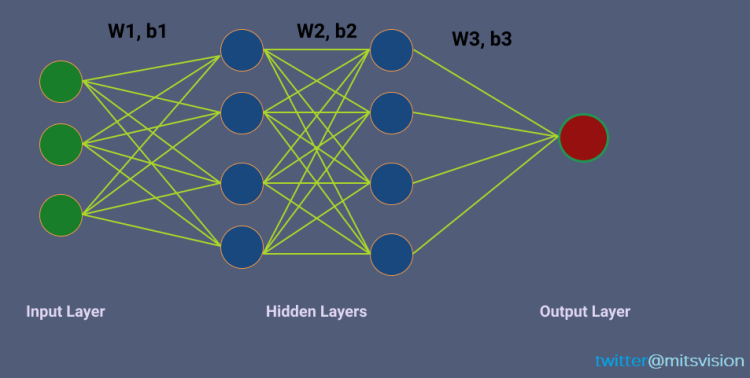
As we know the output after a layer (neuron) is multiplication between weight and “output from the last layer” and then added bias i.e (Y = WX + b)
Let’s focus on the first row (w11,b11,w21,b21 ..)of the network.

Output after neuron 1 (first neuron in row 1) and 2 (second neuron )
y1 = w11 * x1 + b11
y2 = W21 * y1+ b21 (here input is output from the last layer)
if you have deeper network then this continues. output = W * (output -1) + b
Breaking down Y2,
y2 = W21 * (W11 * x1 + b11) + b21
Y2 = (W21 * W11) * x1 + (W21 * b11) + b21
Y2 = NewConstant1 * x1 + NewConstant2
Y2 holds same linear combination with the input x1, weight (newConstant1) and bias (newConstant2) i.e W*X + b.
Even if you have very deeper network without activation functions, your networks ends-up doing nothing but simple linear classification or equivalent to one layer network.
Trending AI Articles:
1. Machine Learning Concepts Every Data Scientist Should Know
3. AI Fail: To Popularize and Scale Chatbots, We Need Better Data
When you add activation functions, such as Relu, Tanh, Sigmoid, ELU, They introduce non linearity inside the network which allow the network to learn/fit flexible complex polynomial behavior.
Now the formula for the Y2 becomes,
Y2 = W21 * Relu(y1) + b21
Y2 = W21 * newX + b21
If you see the Y2 now, it is no more linear combination of input x1.
Thanks for reading

Still not clear, drop me your questions below ??
Don’t forget to give us your ? !




Why to use activation units/functions (non-linearity) inside convolution neural networks (CNNs) was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
