

Language-guided Navigation in a 3D Environment
Language-guided navigation is a widely studied field and a very complex one. Indeed, it may seem simple for a human to just walk through a house to get to your coffee that you left on your nightstand to the left of your bed. But it is a whole other story for an agent, which is an autonomous AI-driven system using deep learning to perform tasks.
Indeed, current approaches try to understand how to move in a 3D environment in order to let the agent freely move like a human. This new approach I will be covering in this article changes that by letting the agent only executing low-level actions in order to follow language navigation directions, such as “Enter the house, walk to your bedroom, go in front of the nightstand to the left of your bed.”
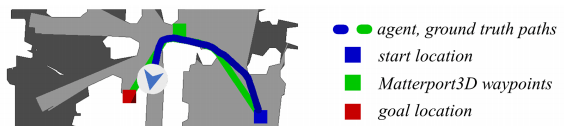

They’ve achieved this by using only four actions; “Turn-left”, “Turn-right”, “move forward for 0.25 m”, “Stop”. This allowed the researchers to lift a number of assumptions that prior work were using, such as the need to know exactly where your agent is at all time.
Using this technique makes the trajectories significantly longer, using an average of 55.88 steps rather than 4 to 6 steps from current approaches. But again, these steps are much smaller and make the agent much more precise and “human-like.”
Let’s see how they achieved such thing and some amazing examples. Feel free to read the paper and check out their code, which are both linked at the end of this article.


Trending AI Articles:
1. Machine Learning Concepts Every Data Scientist Should Know
3. AI Fail: To Popularize and Scale Chatbots, We Need Better Data

As the name says, they developed a language-guided navigation task for 3D environments where the agents follow language navigation directions given by a user in order to realistically move in the environment.

In short, the agent is given first-person vision, which they call Egocentric, and a human-generated instruction, such as this example; “Leave the bedroom and enter the kitchen. Walk forward and take a left at the couch. Stop in front of the window.”
Then, using this input alone, the agent must take a series of simple control actions like “move forward for 0.25 m”, “turn left for 15 degrees”, to navigate to the goal.
Using such simple actions, VLN-CE lifts assumptions of the original VLN task and aims to bring simulated agents closer to reality.
Just to give a comparison, current state-of-the-art approaches move between panoramas and cover 2.25 meters on average including avoiding obstacles for a single action.

The 2-model method
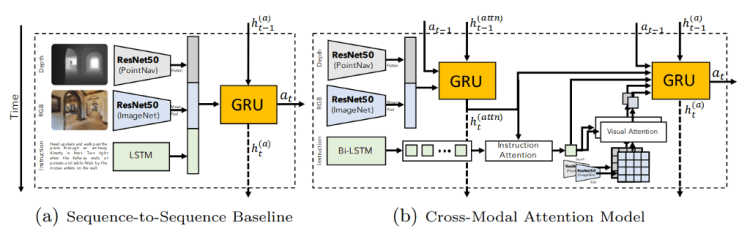
They developped two different models in order to achieve such task.
The first one (a) is a simple sequence-to-sequence baseline.
The second one (b) is a more powerful cross-modal attentional model, which we can both see in this picture.
The first model

This first model takes a visual representation of the observation, containing depth and RGB features, and instructions for each time step.
Then, using this information and the instructions given by the user, it predicts a series of action to take, denoted as “at” in this image.

The RGB frames and depths are respectively encoded using two ResNets-50 architectures, one pre-trained on ImageNet and the other one trained to perform point-goal navigation.

Then, it uses an LSTM to encode the instructions from the user.
LSTM is the short for Long short-term memory, which is a recurrent neural network architecture widely used in natural language processing applications due to its memory capabilities allowing it to use previous words information as well.
The second model

These actions, a, are then fed into the second model.
The goal of this second model is to compensate for the lack of visual reasoning in the first model, which is super important for this kind of navigation application.
For example, you need a good spatial visual reasoning in order to understand an instruction such as “to the left of the table.”
Your agent needs to know that it first needs to know where’s the table, and then, go to the left of that table.

Which is done using attention.
Attention is basically based on a common intuition that we “attend to” a certain part when processing a large amount of information, like the pixels of an image.
More specifically, it is done using two recurrent networks, as you can see in the image, one tracking observations using the same RGB and depths input as the first model.
While the other network’s role is to make decisions based on the user’s fed instructions and visual features.

This time, the user’s instructions are encoded using a bidirectional LSTM.
Then, they compute a list of simple instructions which is used to extract both visual and depth features.
Following that, the second recurrent network uses a concatenation of all the features discussed including an action encoding as inputs and predicts a final action.
The dataset
To train such task, they used a total of 4475 trajectories split from the train and validation split. For each of those trajectories, they provided multiple language instructions and an annotated “shortest path ground truth via low-level actions” as seen in this image.
At first, it looks like it needs a lot more details and time to achieve such task. Shown in this picture below, where (a) being the current approaches, using real-time localization of the agent, and (b) being the covered approach with low-level actions.

But when we compare it to the traditional panoramic view with perfect location instead of having no position given and using only low-level actions it is clear that it needs way less computation time in order to succeed, just as you can see in the amount of information given for each approaches in the picture above.
Results
This is a comparison on the VLN validation/test datasets between this and the current state-of-the-art approaches.
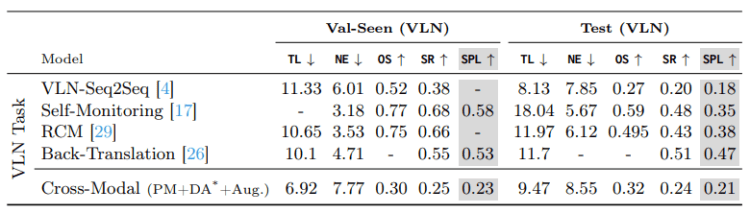
From these quantitative results, we can clearly see that using this cross-modal approach with multiple low-level actions in a continuous environment outperforms the nav-graph navigation approaches in every way. It is hard to visualize such results from a theoretical comparison basis, so here are some impressive examples using this new technique:
Watch the video to see more examples of this new technique:
I invite you to check out the public release version of the code on their GitHub. Of course, this was just an introduction to the paper. Both are linked below for more information.
The paper: https://arxiv.org/pdf/2004.02857.pdf
The project: https://jacobkrantz.github.io/vlnce/?fbclid=IwAR2VO1jwjaq4Uydz2O25ZaLXVFjoD46QirYnW1zNeNAJyNkleA0KS_PDBrE
GitHub with code: https://github.com/jacobkrantz/VLN-CE
Don’t forget to give us your ? !




Language-Guided Navigation in a 3D Environment was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
