

About me
I am a young data scientist just graduated, I love everything related to new technology and innovation, especially deep learning. This first article is the first in a series about NLP, computer vision, speech to text. Feel free to give me feedback, so that I can improve my work.
Ps: You can also follow me daily on instagram @frenchaiguy
Why using a transformer model?
In recent years NLP has become the fastest evolving area in deep learning along with computer vision. The transformer architecture has made it possible to develop new models capable of being trained on large corpora while being much better than recurrent neural networks such as LSTM. These new models are used for Sequence Classification, Question Answering, Language Modeling, Named Entity Recognition, Summarization, or Translation.
In this post, we will study the key components of the transformers in order to understand how they have become the basis of the state of the art in different tasks.
Transformer architecture
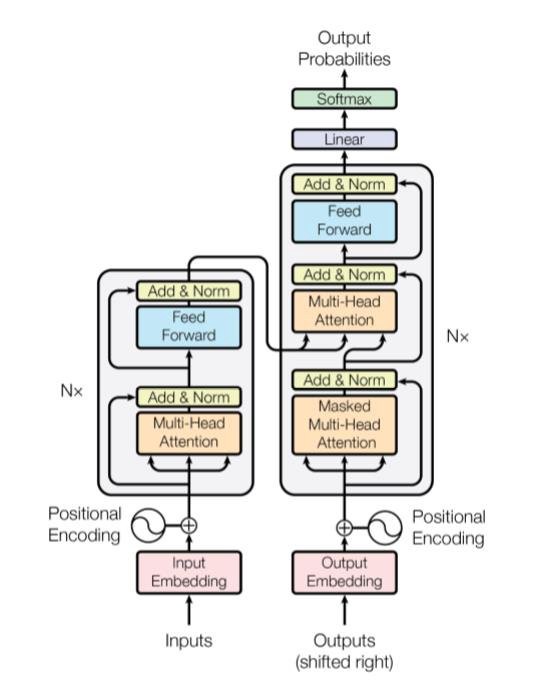
A transformer is composed of an encoder and a decoder. The encoder’s role is to encode the inputs(i.e sentence) in a state, which often contains several tensors. Then the state is passed into the decoder to generate the outputs. In machine translation, the encoder transforms a source sentence, e.g., “Hello world.”, in a state, e.g., a vector, that captures its semantic information. The decoder then uses this state to generate the translated target sentence, e.g., “Bonjour le monde.”. Encoder and decoder have some submodules, but as you can see both of them use mainly Multi-Head Attention and Feed Forward Network. They are the main focus of this post. The final code for this implementation is available on my Github.

Explaining main submodules
Part 1: Input Embedding
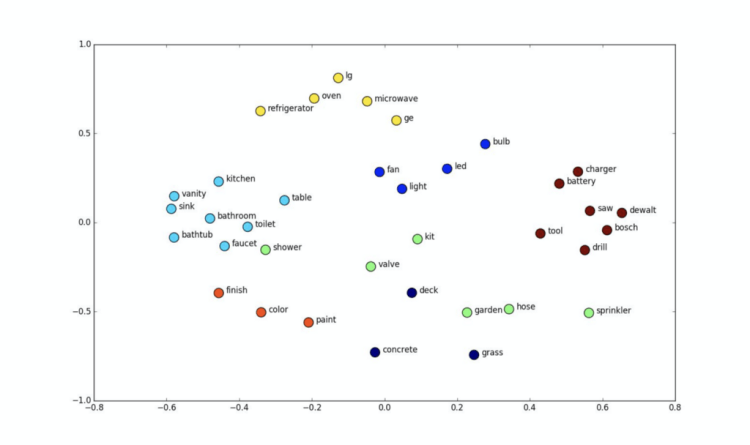
Embedding aims at creating a vector representation of words. Words that have the same meaning will be close in terms of euclidian distance. For example, the word bathroom and shower are associated with the same concept, so we can see that the two words are close in Euclidean space, they express similar senses or concept.
For the encoder, the authors decided to use an embedding of size 512 (i.e each word is modeled by a vector of size 512).
Part 2: Positional Encoding
The position of a word plays a determining role in understanding the sequence we try to model. Therefore, we add positional information about the word within the sequence in the vector. The authors of the paper used the following functions (see figure 2) to model the position of a word within a sequence.
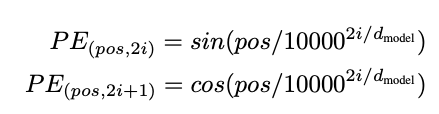
We will try to explain positional encoding in more detail. Let us take an example.
The big yellow cat
1 2 3 4
We note the position of the word in the sequence p_t € [1, 4].
d_model is the dimension of the embedding, in our case d_model = 512, i is the dimension(i.e the dimension of vector). We can now rewrite the two postionnal equation

We can see that the wavelength (i.e. frequency) lambda_t decreases as the dimension increases, this forms a progression along the wave from 2pi to 10000.2pi.

In the case of this model the information of the absolute position of a word in a sequence is added directly to the initial vector. To do this the encoding position must have the same size as the initial vector d_model.
If you want to better understand the notion of relative position is how the sinusoidal function allows you to have this notion of relative position, I recommend this post.
Part 3: Attention mechanism
Scaled Dot-Product Attention
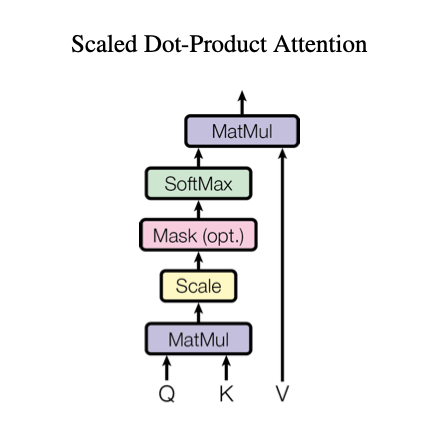
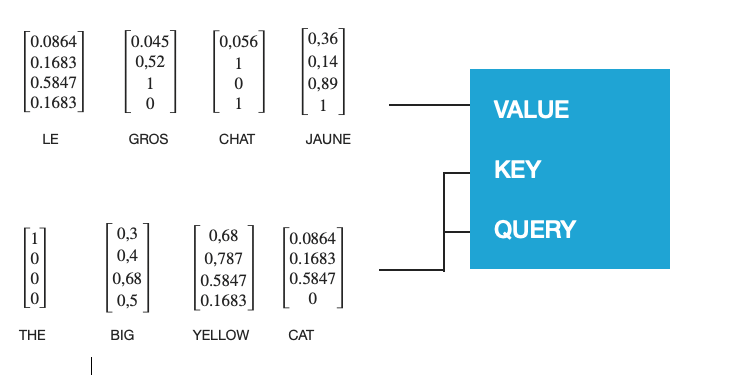
Let’s start by explaining the mechanism of attention. The main purpose of attention is to estimate the relative importance of the keys term compared to the query term related to the same person or concept. To that end, the attention mechanism takes query Q that represents a vector word, the keys K which are all other words in the sentence, and value V represents the vector of the word.
In our case, V is equal to Q (for the two self-attention layers). In other words, the attention mechanism gives us the importance of the word in a specific sentence.
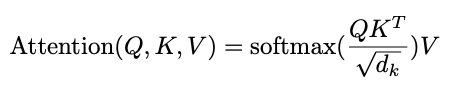
Let’s show an example of what this function does.
Let’s take the following sequence for example: “The big yellow cats”
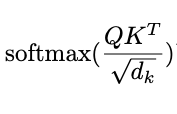
When we compute the normalized dot product between the query and the keys, we get a tensor that represents the relative importance of each other word for the query.
tensor([0.0864, 0.5847, 0.1607, 0.1683]) #example for query big
To go deeper in mathematics, we can try to understand why the authors used dot product to calculate the relation between two words.
A word is represented by a vector in an Euclidian space, in this case a vector of size 512.
Example: “big” -> [0.33, 0.85,……………., -0.74]
When computing the dot product between Q and K.T, we compute the product between the orthogonal projection of Q in K. In other words, we try to estimate how the vectors (i.e words between query and keys) are aligned and return a weight for each word in the sentence.
Then, we normalize the result squared of d_k, because ON A large scale the magnitude of Q and K can grow bY pushing the softmax function in regions where it has extremely small gradients. To counter this effect, we scale the dot product by 1/squaRe(d_k). The softmax function regularizes the terms and rescales them between 0 and 1(i.e transform the dot product to a probability law), the main goal is to normalize the whole weight between 0 and 1.
Finally, we multiply the result( i.e weights) by the value (i.e all words) to reduce the importance of non-relevant words and focus only on the most important words.
Multi Head Attention
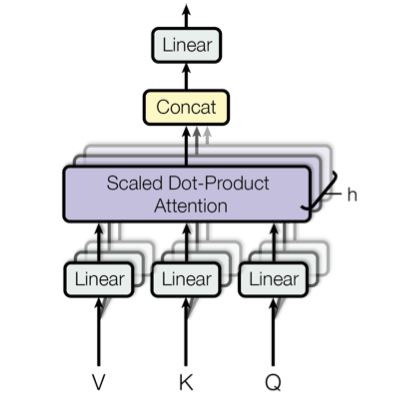
IThe Transformer model uses the Multi-Head Attention mechanism, it’s simply a projection of Q, K and V in h Linear Spaces.
On each of these projected versions of queries, keys and values we then perform the attention function in parallel, producing dv -dimensional output values. These are concatenated and projected again, which gives the final values, as depicted in Figure 6.
During the training phase, the Multi-Head Attention mechanism has to learn the best projection matrices (WQ, WK, WV).

The output of the Multi-Head Attention mechanism, h attention matrix for each word, are then concatenated to produce one matrix per word. This Attention architecture allows us to learn more complex dependencies between words without adding any training time thanks to the linear projection which reduces the size of each word vector. (in this paper we have 8 projections in space of size 64, 8*64 = 512 the initial size of vector)
How encoder decoder architecture works ?
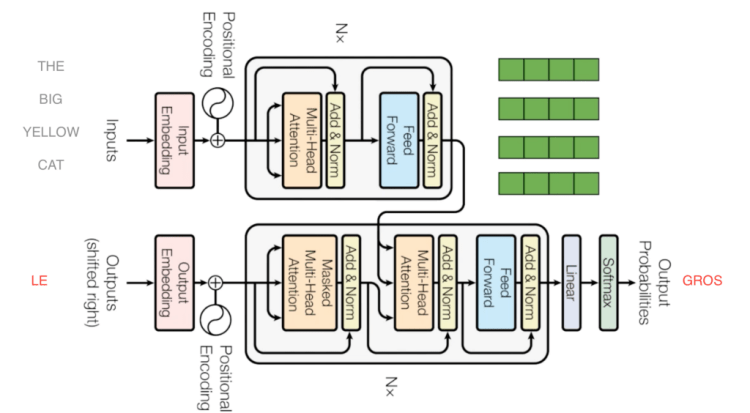
In this part, we are going to describe how the encoder and the decoder work to translate an english sentence to a french sentence part by part.
Part 1: Encoder
- Use embedding to convert a sequence of tokens to a sequence of vectors.

The embedding part, convert word sequences to vectors, in our case each sentence is converted to a vector of size 512.
2. Add position information in each word vector
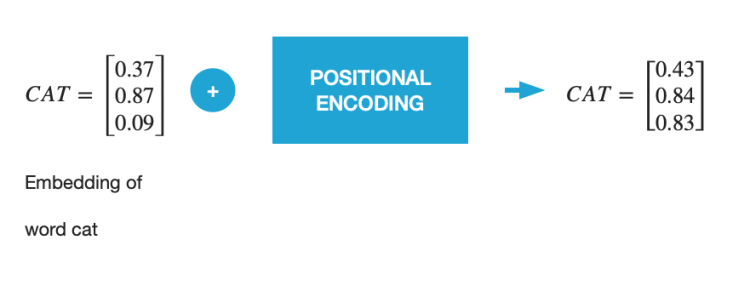
The great strength of recurrent neural networks is their ability to learn complex dependencies between sequences and to remember. Transformers use positional coding to introduce the relative position of a word within a sequence.
3. Apply Multi Head Attention

4. Use Feed Forward
Part 2: Decoder
- Use embedding to convert french sentence to vectors
2. Add positional information in each vector word

3. Apply Multi Head Attention

4. Feed Forward network
5. Use Multi Head Attention with encoder output
In this part, we can see that the Transformer uses an output from the encoder and the input from the decoder, this allows it to determine how the vectors which encode the sentence in English are related to the vectors which encode the sentence in French.
6. Feed forward again
7. Linear + softmax
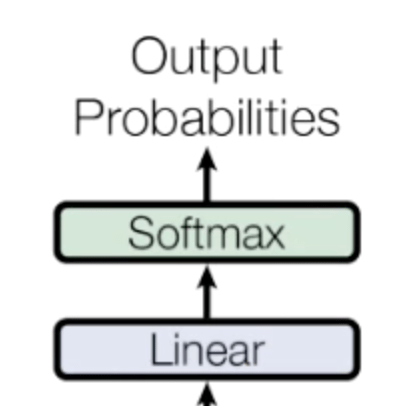
These two blocks compute the probability for the next word, at the output the decoder return the highest probability as the next word.
In our case the next word after “LE” is “GROS”.
Results
The authors of the research paper compared the architecture of the transformers and other state of the art model in 2017.
As, you can see the transformer model outperforms all models on BLEU test, this test evaluates the algorithm on a translation task. It compared the diference bewteen the translation provided by the algorithm and humans.
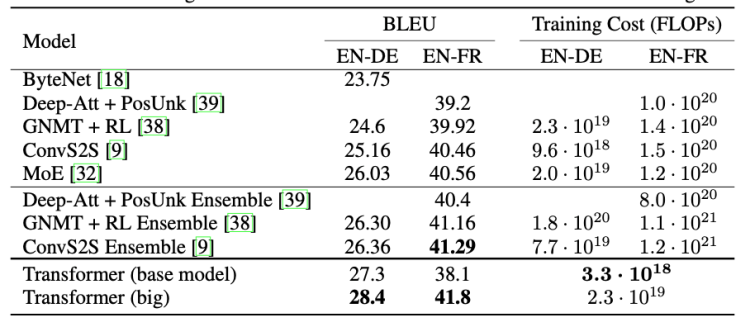
State of the art
Transformers are a major advance in NLP, they exceed RNN by having a lower training cost allowing to train models on larger corpora. Even today, transformers remains the basis of state-of-the-art models such as BERT, Roberta, XLNET, GPT.
We can find all my implementation on my Github.
Bibliography
- https://arxiv.org/pdf/1706.03762.pdf
- https://arxiv.org/pdf/1607.06450.pdf
- http://nlp.seas.harvard.edu/2018/04/03/attention.html
Don’t forget to give us your ? !




Attention is all you need was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Via https://becominghuman.ai/attention-is-all-you-need-16bf481d8b5c?source=rss—-5e5bef33608a—4
source https://365datascience.weebly.com/the-best-data-science-blog-2020/attention-is-all-you-need
