
Pipelining the architecture :
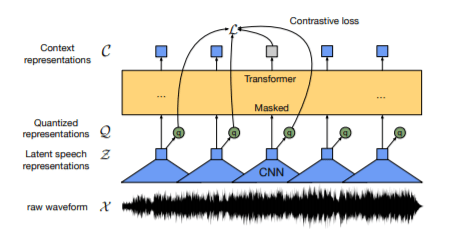
- The raw speech is passed through a feature encoder (temporal CNN blocks + layer norm + GeLU activation) and the latent features are extracted.
- The latent features are continuous and we need to discretize them for learning speech representations so these features are quantized using some code books to obtain the quantized features.
- The quantized features are masked with some (arbitrary) probability. We don’t mask the inputs to the quantization module, instead we mask the output of quantized module in the latent feature encoder space. With some arbitrary probability we select the indices and mask them along with M-consecutive indices w.r.t sampled indices.
- These features are passed through a contextualized model like transformers and the masked features are predicted.

Problems with Quantization:
We choose quantized vector representations each from multiple codebooks and then they are concatenated. But how to choose the quantized vector? We choose the one which is having minimum difference with the extracted feature and this operation is done using argmin operator which is converted into argmax by introducing negation. But argmax is non-differentiable hence backprop is a problem. So here comes the role of Gumbel SoftMax which provides a way of choosing a quantized vector representation from codebooks, with the benefits of being differentiable in nature. So, we use argmax in forward prop and while backprop we use Gumbel SoftMax.
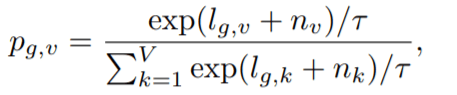
T = non-negative temperature constant ; nv, nk= Gumbel Noise ; here, the term l(g,v) represents code at index v from codebook id = g
Trending AI Articles:
Pretraining Objective:
We try to predict the quantized vectors from the set of distractors (distractors are uniformly sampled from other masked time steps from the same utterance) at the time steps which are masked by minimizing the loss between prediction and the quantized vector at that certain masked time steps.
What are the losses to be minimized?
- Contrastive Loss (Lm): The objective of this loss is to bring the prediction of current masked timestep closer to the actual quantized latent speech representation which should have been there at the same time step, followed by pushing the prediction far away from distractors.
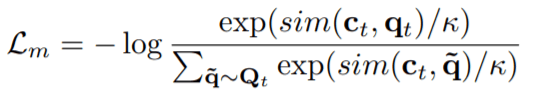
Here, sim() function is cosine-similarity function and the term Ct is output of the model at timestep=t.
- Diversity Loss (Ld): This loss objective is responsible for bringing in equal opportunities of selection for all the V entries present in each of the G-codebooks. So, we maximize the entropy of averaged SoftMax distribution for each of the entries in the codebook and to bring in equal opportunity across a batch of utterances. This is naïve SoftMax which doesn’t include non-negative temperature coefficient and Gumbel noise.
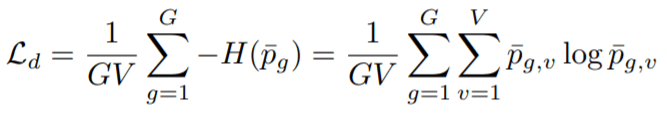
Here, probability term represents probability of finding v-th entry from g-th codebook.
- Total Loss:
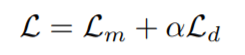
Often, the setting is little bit changed when we pretrain on smaller Librispeech dataset, by introducing L2 penalty in the activations of the final layer of feature encoder to regularize training and reducing the gradient by a factor of 10. The authors have also suggested to remove the layer normalization step in the feature encoder and normalizing the output of only first layer of feature encoder. Checkpoint is set for the epoch where contrastive loss is minimum on the validation set.
For decoding, there are two schools of thoughts, one is via a 4-gram LM and other idea is to use a pretrained (on Librispeech LM corpus) Transformer LM, followed by choosing the best of both worlds using beam search decoding scheme. For more details I would request you to see these details in the original paper.
Fine-tuning:
The pretrained model can be finetuned for downstream tasks like Speech Recognition using little amount of labelled dataset. What we need to do is to just apply a linear projection layer over transformer decoder to convert the dimension size equal to the vocabulary size of the data on which you are training and minimizing the CTC loss objective.
Results:
The authors have developed Phoneme Recognizer for TIMIT dataset and have achieved SOTA, following standard protocol of collapsing the phone labels into 39 labelled classes. The results show that jointly learning discrete speech units with contextualized representations achieves substantially better results than fixed units learned in older architectures. The authors have demonstrated the feasibility of ultra-low resource speech recognition: when using only 10 minutes of labelled data, they achieved word error rate (WER) 4.8/8.2 on the clean/other test sets of Librispeech. The authors have set a new state of the art on TIMIT phoneme recognition as well as the 100-hour clean subset of Librispeech. Moreover, when lowering the amount of labelled data to just one hour, this approach still outperforms the previous state of the art self-training method while using 100 times less labelled data and the same amount of unlabelled data. When all 960 hours of labelled data were used from Librispeech, then the model achieved 1.8/3.3 WER
I have explained the mechanism of the architecture and the observations but if you are interested about the exact figures in the results obtained and the dataset used for training and testing, I will suggest to refer to this paper. It will help you gain more insights and the original paper will look easier to understand once you finish this article. I have tried to explain it lucidly from my end, hoping that it might have helped you and I thank you for your patience. Hoping the best for you in your journey, thankyou until next time!
Don’t forget to give us your ? !




Wav2Vec 2.0: Learning Speech Representations via Self-Supervised Objective was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
