
So, are you confused by the title? Of course I got an interview for amazon ML Engineer position and I have failed because of my mistakes. I want to share my experience with you, so that you don’t make mistakes I have made.
I have given interview to amazon for ML Engineer position in January 2021. I am sharing my experience from how I got the interview and how not to bomb it.
So, in November 2020, amazon hosted a hackathon on Hacker-Earth website to hire ML Engineers in India. Naturally as a data science learner I have participated in the Hackathon.
In round 1 of the hackathon we were asked to built a classifier for an ecommerce website to know whether to target a person or not based on the historical data available for the ecommerce website. We were also told to make a presentation for the same.

Data Cleaning
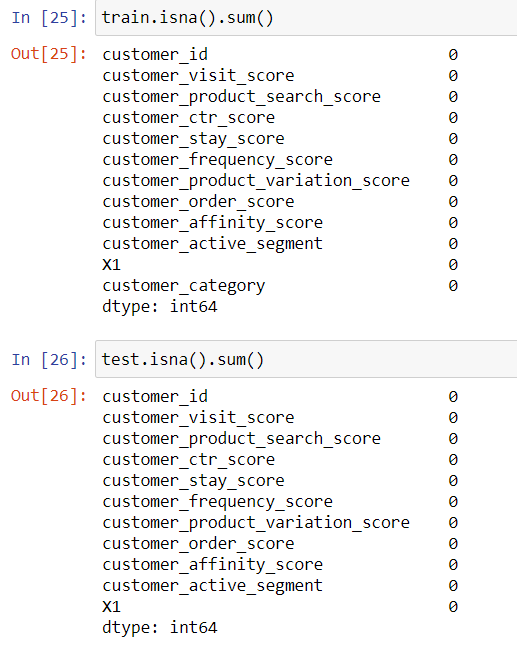
I have loaded the train and test data and checked for null values.

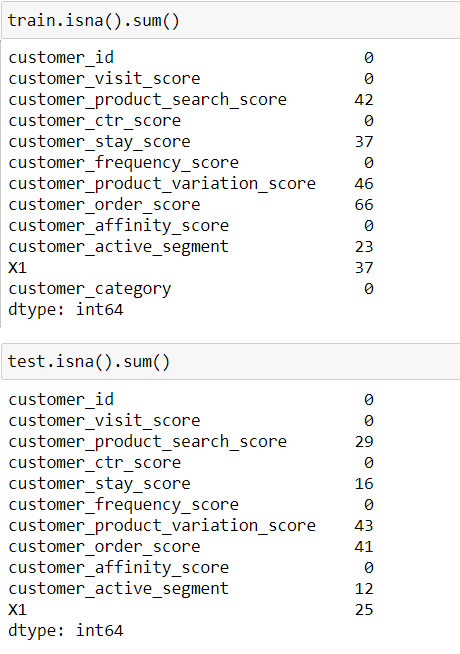
I have filled the null values in columns having object data type by mode values and numeric data types by their median values.
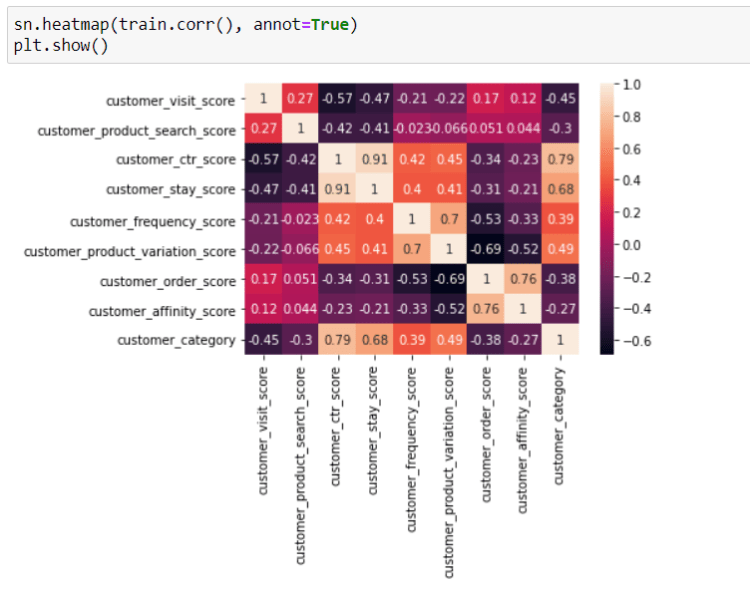
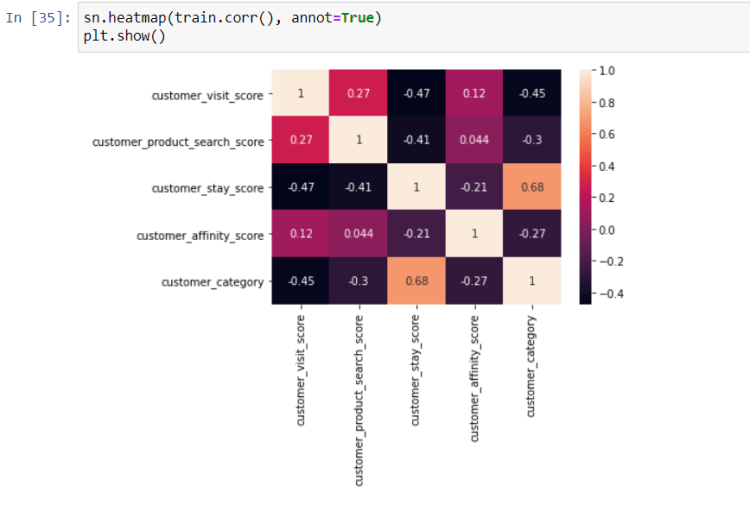
Later on I have to eliminate the numerical features which were highly correlated with each other, so that the model will have lower the variance of the weights. I have retained features having correlation coefficients between -0.5 and 0.5.
Trending AI Articles:
1. Preparing for the Great Reset and The Future of Work in the New Normal
Before eliminating features:
After eliminating the features:
Removing outliers:
I found that customer_affinity_score column has outliers. Removing outliers by keeping data points between IQR range was resulting in removing some of the unique categorical data points and was giving problems while doing One Hot Encoding. Hence I have retained the data points with outliers having customer_affinity_score less than 125. I have done One Hot Encoding for the object dtype columns to convert them to numeric data type.
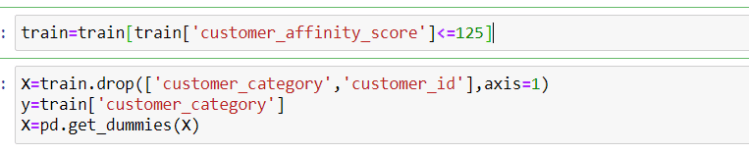
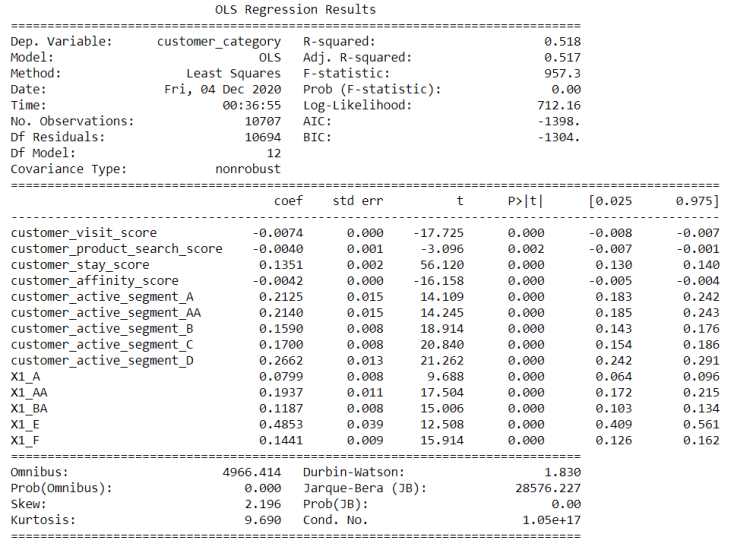
At this point data was cleaned and I have to decide which features to keep for further analysis. I have created an OLS model to know the p values of the columns to find out which columns are important. Since, all p values were less than 0.05 that is in the range 0f 95% confidence interval, I have retained all the columns.
Model creation
Now it was the time to create the model. I have tried Random Forest, XG Boost and SVM models for this particular problem. Since, random state at the time of splitting the data gives different train and test data, I experimented with it. I have looped the data from 0 to 99 random state and calculated the score for each model with different split by random state. I chose the model with highest score for the evaluation of each SVM classifier, Random Forest Classifier and XG Boost Classifier. I chose SVM Classifier as it was giving me a generalized model compared to Random Forest Classifier and XG Boost Classifier.
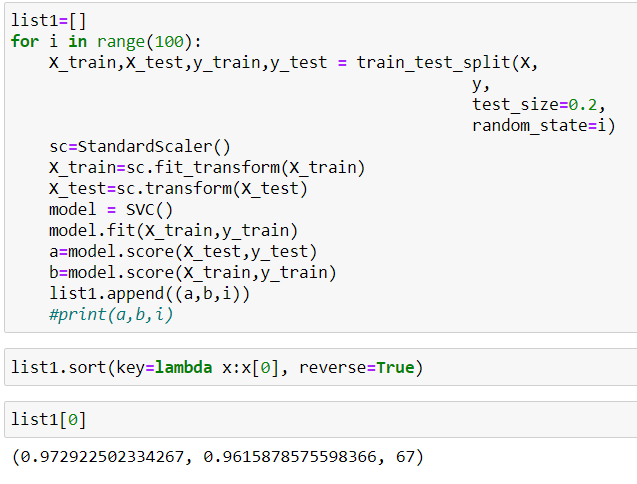
I found that random state 67 giving best score on test data set. Also the model is generalized model as it is giving more score on validation dataset than the train dataset.

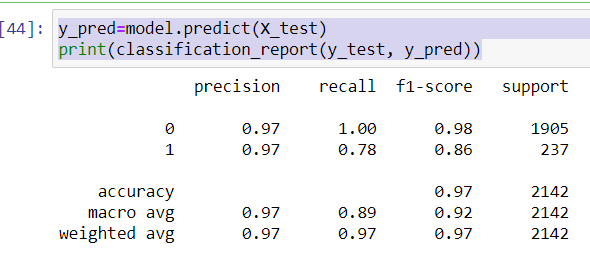
Since, the evaluation metric for this hackathon was precision and I was getting 97% precision on validation data, I have moved forward with this model.
Finally I have made prediction on test data and saved it as final submission.
Prediction


So, I have prepared the notebook and presentation for the hackathon and submitted it for evaluation. I have got 93.7% precision on their actual test data.
Round 1 was cleared, round 2 was a coding exercise, I have cleared that as well. Now, I was so happy after hearing that I have cleared the initial rounds, when the recruiter asked, if is it fine to schedule interview next day? I immediately told yes and that was my biggest mistake.
It was the interview of world’s most customer centric company which promises to deliver the customer anything they wanted on their online platform and I have not thought of how am I going to prepare for the interview in one day.
The result was, I failed to crack the amazon interview. I learnt from my this mistake that impatience is the enemy of success. I wanted to share my experience with you all so that you don’t repeat the mistake I have done.
After all patience is bitter but the fruit is sweet!
GitHub link for the repository:- https://github.com/pratikskarnik/Amazon_ML_Engineer_Hiring_Challenge_2020
Don’t forget to give us your ? !




How to land an Amazon ML Engineer Interview and mistakes to avoid was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
