
Every project in data science begins with discovering the correct features. The issue is that there is not a unique, centralized place to browse for the most part; features are hosted everywhere. First and foremost, therefore, a feature store offers a single glass pane to share all the features available. When a new project is launched by a data scientist, he or she can go to this catalog and quickly locate the characteristics they are searching for. But not only is a data layer a function store, but it is also a data transformation provision that allows users to access raw data and organize it as features that are ready for any machine learning algorithms to use. Candidly, the future of ai will look like those who build it, likewise, the race is still on to be the prime architect.
Most of today’s artificial intelligence can be labeled as either historical or streamed and is stored in libraries, data lakes, and warehouses of data. All are on-site, in the cloud, and at the edge of the premises. Plenty or even hundreds of networks handle critical data about clients, patients, supply chains, etc. This fragmentation makes it exceedingly difficult to conduct enterprise-wide real-time simulations.

Imagine an executive who needs to know how many patients have visited three or more health centers in the last five years, broken down by geographic area and result, as an incredibly simplistic example of how data is usually accessed for research. Traditionally, a researcher writes the necessary queries and pushes them down to the individual database to return information, or a centralized copy of the data is compiled in the case of data lakes or feature store for ML systems. An operation such as this can take hours or days to plan, at best. Real-time performance cannot help the query duration alone.
The global AI software market is projected to grow by around 54 percent year-on-year in 2020, hitting a forecast size of US$ 22.6 billion. AI is a term used to describe a range of technologies that are capable of learning and solving problems by producing sophisticated software or hardware.
Maybe that manager doesn’t mind waiting hours or days, but what if he or she wants to see a constantly updated hospital bed efficiency prediction to make critical strategic decisions? Conventional methods can easily transform into a big organizational undertaking to satisfy a forecasting, real-time necessity like this.
Benefits:
Rapid advancement
Preferably, data scientists will concentrate on what they have been learning to do and what building models are effective. They still indeed, find themselves having to spend much of their time in architectures for data engineering. Some functions are costly to compute and require consolidation of structures, whereas others are transparent.
Smooth model implementation
One of the key challenges in the implementation of machine learning in manufacturing emerges from the reality that the features used in the development environment for training a model are not the same as the features in the production feeding layer Consequently, it allows a smoother implementation phase to enable a compatible form factor between the training and delivering layer, ensuring that the trained model actually represents the way things will function in production.
Trending AI Articles:
2. Generating neural speech synthesis voice acting using xVASynth
Enhanced reliability of frameworks
The feature store holds added metadata for each feature, in addition to the original features. For instance, a statistic that measures the effect of the function on the model with which it is affiliated. When choosing features for a new model, this knowledge will benefit data scientists immensely, enabling them to concentrate on those that will have a better effect on similar existing models.
Better cooperation in the performance
Communication is trusting, the fact today is that almost every new business service is focused on machine learning, so there is an exponential increase in the number of project activities and features. This decreases our ability, because there are just too many, to provide a good detailed overview of the features available. Instead of creating in processing facilities, the feature store enables us to share with our colleagues our features alongside their metadata. In large organizations, it is becoming a frequent issue that multiple teams end up creating similar solutions and they’re not aware of the duties of each other. Feature stores connect the distance and allow anybody to share their job and prevent redundancy.
Track lineage and discuss compliance with regulations
It is important to monitor the lineage of algorithms being developed to comply with guidelines and regulations, particularly in cases where the AI models being produced serve industries such as medicine, finance, and defense. To achieve this, insight into the overall start to end data flow is needed to better understand how the model produces its outcomes. There is a need to monitor the flow of the feature generation process as characteristics are generated as part of the process. We can preserve the data lineage of a component in a feature store. This provides the required tracking information that collects how the role was produced and provides the required insight and reports for compliance with the rules.

Features store and MLOps
MLOps is a DevOps extension where the idea is to apply the concepts of DevOps to machine learning channels. Designing a machine learning pipeline, primarily because of the data element, is different from developing apps. The model’s quality is not just dependent on the code performance. It is also dependent on the quality of the information that is used for running the simulation from raw data.
In ML pipelines, the Features Store solves the major issues:
· By sharing features between teams/projects hence reuse of feature store.
· Enables web applications to serve functionality at scale and with low latency.
· Ensures the continuity of functionality between training and operation. Features are created once and can be stored in online and offline feature stores.
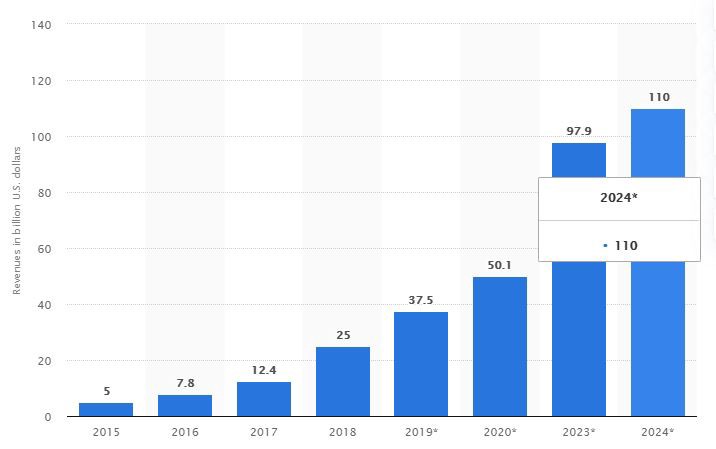
· When a prediction has been made and a result comes later, we need to be able to question the values of various features at a given moment in the past. It ensures point-in-time accuracy for the feature store. Revenues from both the intellectual and AI systems industry are projected to hit 50.1 billion U.S. dollars in 2020.
· The estimated value of the proportion of AI contributions to GDP reached its peak, theoretically contributing to around 26.1% of its GDP. This was by North America, which contributed to about 14.5% of GDP.
Conclusion
Data scientists can now scan for functions and conveniently use them with API software to build models with complete data engineering. In addition, other models will store and recreate features, minimizing model training time and expense of facilities. Features in the Company are now a regulated, controlled commodity. The API for the Feature Store is used to read/write features from/to the feature store. There are two modules in the feature store; one interface to write tailored content into the feature store and another functionality to read information from the feature store for training or operation.
It becomes easier and quicker to build new designs as the feature store is designed with more features, while the new models will recycle features that reside in the feature store. For the AI tech to advance in its domain, the feature store initiative will be a supercharger. This in turn will reduce the cost of training the models repeatedly. Based on the AI/ML revenue numbers, it is promising for the feature store to be a strong substratum for all the AI/ML models.
Don’t forget to give us your ? !




Why Feature Store Is the Future For AI was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
