

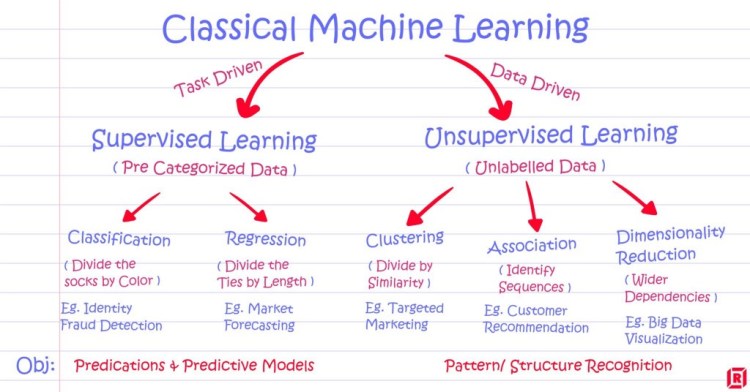
What is Machine Learning? Machine Learning is the process of letting your machine use the data to learn the relationship between predictor variables and the target variable. It is one of the first steps toward becoming a data scientist.
There are two kinds of Machine Learning; supervised, and unsupervised learning. In supervised learning, there are two types; Regression and Classification. In this blog, I will be focusing on the Regression model.
In weeks 3 and 4 of my general assembly data science immersive program, we learn about the sklearn library and using machine learning on the regression. While using the regression model, we cannot use string datatypes in a model. So, to deal with data that are not numeric, we use feature engineering or create a dummy variable. By using feature engineering, we can convert an object(string) into a numerical value. By creating a dummy variable; creates a binary column of 1s and 0s for the column.
To showcase the new skills learned from the sklearn library. Our class had a little Kaggle competition to see who had the best model. The project is:

AMES HOUSING DATA SALE PRICE PREDICTION:
My project’s problem statement was
“A Realtor is looking to renovate and build houses in Ames, Iowa. They want me to look at the data to see what to invest in to get the best R.O.I. Which features will raise the price of the house value?”
Data is from the Kaggle (‘https://www.kaggle.com/c/dsir-28-project-2-regression-challenge/data’). Train data contains all of the training data for your model. Test data contains the testing data for your model.
Trending AI Articles:
1. Top 5 Open-Source Machine Learning Recommender System Projects With Resources
4. Why You Should Ditch Your In-House Training Data Tools (And Avoid Building Your Own)
Different types of data:
Nominal: used for labeling variables(m- male and f- female)
Ordinal: used for measuring non-numeric with an order of the values(1-unhappy, 2-ok, 3- happy)
Data Cleaning: In this data set, there are 2051 rows with 80 columns. So, there were a lot of missing and null values to be clean. By reading the data dictionary provided on the Kaggle website, I cleaned the data using the pandas’ library. For discrete or ordinal features, I added the mode in order not to input a float number. I imputed the null values with the mean of the continuous column.
Exploratory Data Analysis: The best correlation between the sale price and features was the overall quality of the house.
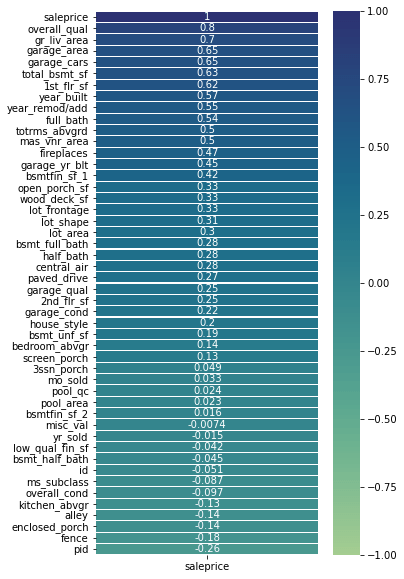
Features that have the best correlation to the Sale Price
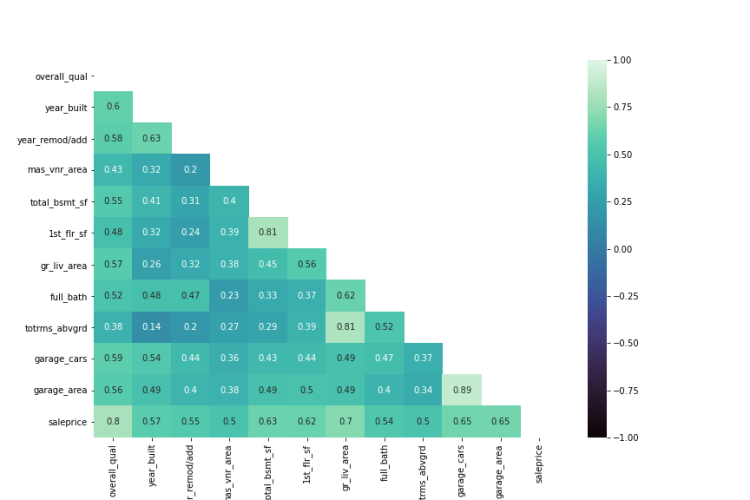
FEATURE ENGINEERING: In order to predict the outcome variable(y variable) you need to turn all the objects type column into numeric in order to predict the Sale Price. So first, I converted all the ordinal columns into numeric by assigning them by numbers, and for all the other features I created a dummy variable.
MODELING: After creating all the features to predict the sale prices, using sklearn, we train-test-split the training data. In Regression, there is a lot of models you can choose from to get the best performing model. In this model, I ran the model in Linear Regression, Ridge, and Lasso Model.
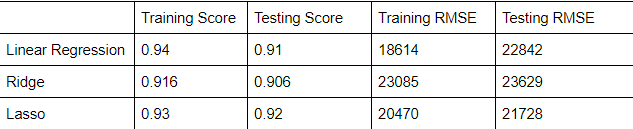
Training Score: How the model fitted the training data
Testing Score: How the model generalized to new data
RMSE: Shows how far predictions fall from measured true values using Euclidean distance.
The baseline model had an RMSE of $80,000. A baseline measures how effective your model is. So all of the models perform extremely better than the baseline; telling us that our model is working.
Lasso performs the best out of the Linear Regression and ridge, as it gives a score of 92 on the test and 21728 on the RMSE. I choose Lasso because the model had a lot of features and the lasso model shrinks and removes the coefficients, reduce variance without a substantial increase of the bias
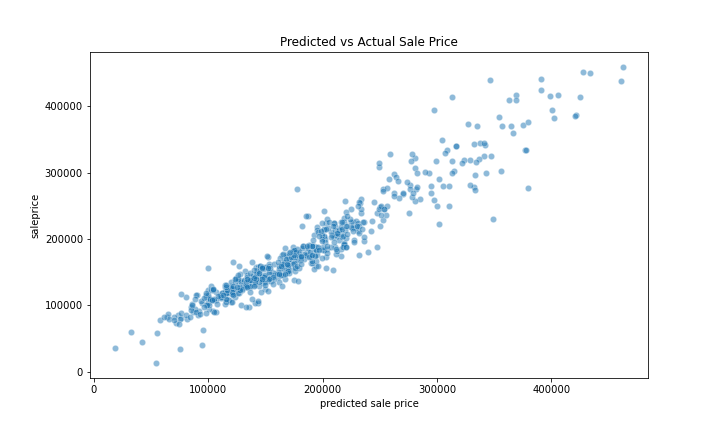
This shows the relationship between predicted and actual sale price, as you can see it is pretty linear. It means that our model performs well.
Below is the link for GitHub for the project if you want to check it out.
https://github.com/tw1270/AMES-HOUSING-DATA-SALE-PRICE-PREDICTION
Tenzin Wangdu – Data Science Fellow – General Assembly | LinkedIn
Don’t forget to give us your ? !




Machine Learning by Using Regression Model was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
