
Data Labeling Service — How to Get Good Training Data for ML Project?
Four Customer Pain Points in Getting No Bias Training Data

With the commercialization of AI products, auto-driving, face recognition, security, and other fields have become popular scenarios, and AI companies begin to focus on scenario-based landing capability.
As the basis of the AI industry, high-quality training data is one of the decisive elements of the model launching.
Relevant statistics show that the amount of data generated in 2025 will be as high as 163ZB, 90% of which are unstructured data. These unstructured data can only be “awakened” by cleaning and labeling. The potential and large demands allow the data labeling service to keep booming and expanding.

In the coming days, large scalable and highly customized data products have become the main forms of service in the data labeling industry. However, due to the low threshold and uneven service quality, clients often encounter pain points such as data quality, efficiency, data security, and customer service when choosing outsourcing partners.
1. Data quality
The deep learning algorithm training under supervised learning relies heavily on annotated data, and the quality of the data set will directly determine the performance of the AI model.
However, there are serious data quality problems in the data annotation industry. It is shown that the current first-time pass rate is less than 50%, and the third-time pass rate is less than 90%, which is far from meeting the needs of AI enterprises.
The clients hope that the data service company can improve the first-time pass rate and significantly reduce the rework situation.

2. Efficiency
At present, the two main data labeling operation and management types are “crowdsourcing” and “subcontracting”, which is difficult to manage the annotation team directly and effectively. Therefore, project delay has become a normal issue.
For customers, project delay means the loss of first-mover advantage in the fierce competition. Therefore, the data service is expected to have an efficient project management system, improving efficiency, and completing the project as scheduled.
3. Data security
A lot of sensitive data, such as face data, license plate data, and so on, would be frequently exposing. Therefore, the storage and transmission of the data require a high level of security.
The demander expects the data service provider to have clear and specific security management and pay enough attention to the process such as data transmission, storage, and data destruction.
4. Management skills
Under the mode of “crowdsourcing” and “subcontracting”, it is difficult for companies with weak management ability to serve high-quality data while multiple projects are ongoing.
Therefore, the demander hopes that the data service enterprise can establish a perfect managed labeling loop, optimizing the project experience.
ByteBridge — A Human-Powered Data Labeling SAAS Platform
There is a SAAS labeling platform. The biggest advantage is clients can individually decide when to start their projects and get their results back instantly.
- Set labeling rules, iterate data features, attributes, and task flows, scale up or down, make changes.
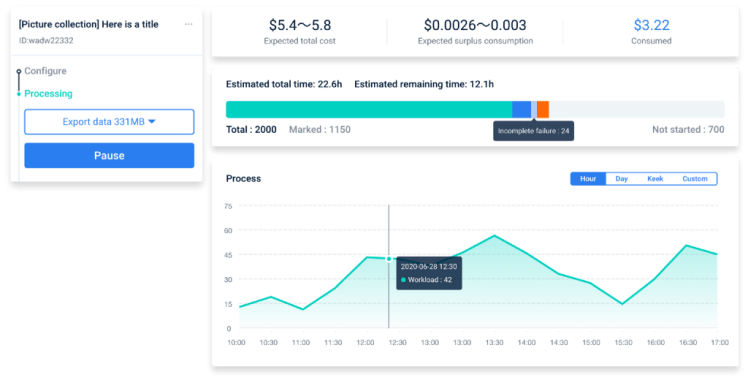
- Monitor the labeling progress and get the results in real-time on our dashboard.
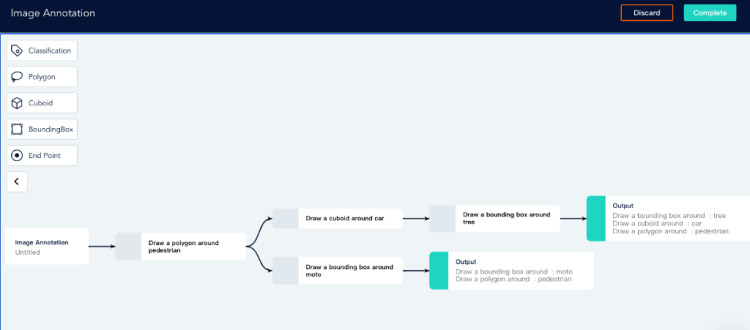
These labeling tools are available on the dashboard: Image Classification, 2D boxing, Polygon, Cuboid.
Once task flow well settled, the project can start in 24h. A medium-level project with 10,000 image labeling will take less than 1 business day.
If you need data labeling and collection services, please have a look at bytebridge.io, the clear pricing is available.
Please feel free to contact us: support@bytebridge.io
Don’t forget to give us your ? !




How to Get Good Training Data for ML Project? was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
