365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Read this article on machine learning model deployment using serverless deployment. Serverless compute abstracts away provisioning, managing severs and configuring software, simplifying model deployment.
Learn how to work with time series in Python; Tips for improving Machine Learning model accuracy from 80% to over 90%; Geographical Plots with Python; Best methods for making Python programs blazingly fast; Read a complete guide to PyTorch; KDD Best Paper Awards and more.
How are the fields of Data Analytics and Data Science related? Read this post by John Thompson, author of the new Packt book “Building Analytics Teams” to gain an understanding of the link between the two.
Detecting and handling missing values in the correct way is important, as they can impact the results of the analysis, and there are algorithms that can’t handle them. So what is the correct way?
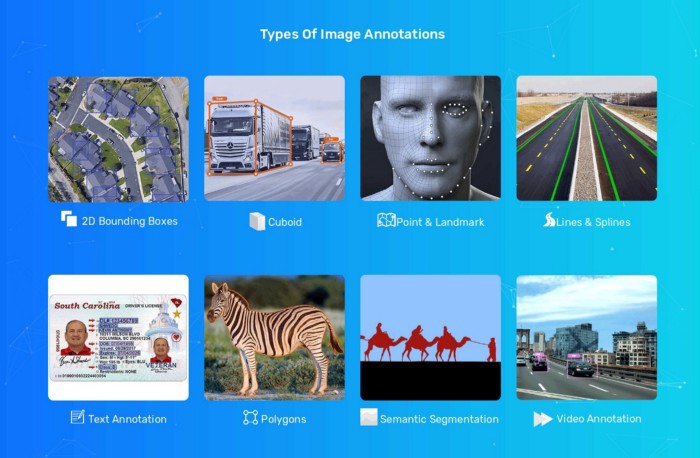
We have the smart things in hand; do you know what the next breakthrough is for the future that is piling up? Let’s discuss the fundamentals of Data Annotation before I address the question and direct you later through the process involved. Data annotation is the method of marking machine-recognizable content through computer vision or ML training based on natural language processing (NLP) accessible in a variety of formats such as text, images, and videos.
It is simply the marking or annotation method that renders the object of interest measurable or identifiable when fed into algorithms. And there are various processes and forms of data marking conducted according to the mission’s requirements. Now switching to my query above, with Automation systems that are under the training stage utilizing machine learning.
What is Data Annotation?
The process of identifying the available data in different formats, such as text, video, or pictures, is data annotation. Labeled data sets are necessary for supervised machine learning so that machines can interpret the input sequence accurately and clearly.
And data must be correctly annotated using the right methods and techniques in order to train the computer vision-based machine learning model. And for such needs, there are several types of data annotation techniques used to construct such data sets. To conduct the annotation process, we have different steps, allow me to proceed with its significance and combined strengths.
Machine Learning Jobs
Text Annotation
For NLP or speech recognition by computers, text annotation is simply done to develop a communication mechanism between humans communicating in their local languages. Text annotation is designed to develop virtual assistant devices and Automation chatbots to provide answers in their particular words to different questions posed by individuals.
Metadata is also introduced in-text annotation tool for machine learning to create the keywords identifiable for search engines and use the same while trying to make critical decisions for future searches. NLP annotation systems do this same job by using the correct tools to compile the texts.
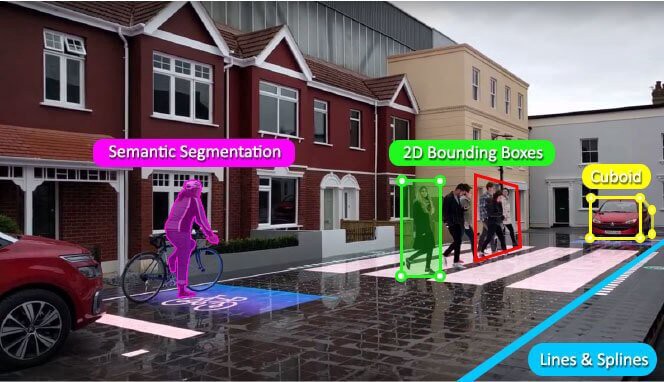
Image Annotation for training in high-quality visualization
Video annotation is also performed, just like text annotation, but now the objective is to make moving vehicles through computer vision recognizable to machines.
Through video annotation, frame — by — frame objects are accurately annotated. And the video annotation service is essentially used to construct training data for self-driving cars or autonomous cars focused on a visual perception model.
Image for Object Detection and Identification Annotation. In order to build the AI model, the most significant and precious data annotation procedure. The main aim of image annotation is to render objects recognizable by ML — Based models determined by visual interpretation.
The object is labeled in image annotation and tagged with additional elements that make it simple for AI-enabled systems to perceive various kinds of objects. There are numerous image annotation strategies for the development of training data sets for Automation businesses. The leading methods used during image annotation according to the customization demands of the ML projects are the rectangular box, textual segmentation, 3D cylindrical shape annotation, landmarks annotation, geometrical annotation, and 3d data annotation.
Machine learning is among the most growing technologies, brings amazing developments that offer global benefits to various fields. And a huge number of data sets are needed to build such automated systems or computers.
And the technique of image annotation is often used to construct certain data sets to allow the objects identifiable for machine learning. And this annotation process helps not just the Automation released, but also provides other stakeholders with benefits. We will talk about the benefits of data annotation in different sectors here.
The distinction between supervised and unsupervised machine learning needs to deal with pre-defined various sectors. The training data has been labeled with supervised machine learning so the system can understand more about the strong demand. For example, if the program’s aim is to recognize animals in pictures, there are already many images labeled as animals or not in the system. It then uses these references to compare new data in order to generate its observations.
There are no identifiers for unsupervised machine learning, and so the framework is using characteristics and several other strategies to classify the creatures. Engineers can educate the software to identify animals’ visual characteristics such as tails or paws, but the task is hardly as simple as it is in supervised machine learning where such indications play a vital role.
The method of attaching identifiers to the training data sources is data annotation. In several ways, these can be implemented-we discussed binary data annotation above that-pets or not pets-but other types of data annotation are also necessary for ML. For example, in the healthcare profession, data annotation can include labeling specific biological image data for other medical value with identifiers defining diagnosis or illness signs.
Data annotation requires time and is mostly performed by people’s thoughts or by alike teams, but it is an important component of what makes many machine learning type projects function correctly. It provides the basic framework for educating a program what it needs to understand and how to differentiate in order to generate correct outputs across different inputs.
What are the Advantages of Data Annotation?
Data annotation explicitly benefits the machine learning model to be accurately trained for correct prediction with supervised learning processes. There are a few benefits you need to identify; however, we can appreciate its significance in the world of Automation.
Educated ML algorithms or automated systems based on machine learning offer a completely different and streamlined experience for end-users. Chatbot or digital assistant systems allow users to answer their questions quickly according to their demands.
I can answer questions about the present weather conditions from people asking about a product, services, or basic information or update the news, etc.
Similarly, the machine learning technology works in web search engines such as Google offer the most significant results that use search relevance technologies to enhance the accuracy of the result according to the past search behavior of end-users.
Similarly, speech recognition technology is being used in virtual assistance to understand the human language and communicating with the aid of the natural language process.
We have several database companies offering a full-fledged machine learning data annotation service. It requires the use of all types of strategies in text, video, and photo annotation as needed by the clients. Beginning to work with highly qualified annotators to ensure the highest quality of training data sets at the lowest prices for Automation clients.
Conclusion
I think you have now understood why data annotation is critical for machine learning ventures. The training data obtained in the form of annotated texts, photos, or videos is the power that could only be generated by certain autonomous models in order to prepare the algorithm. Without appropriate training data sets, you cannot imagine Machine learning programs.
Stripper well is mechanical equipment , which is used for oil mining , it is entry level well property which does not exceed the specific amount of barrels of oil in oil mining industry and due to it’s low capacity of production in oil mining , it is near to the end of its economical application in industry, but in present it is widely adopted in US oil mine Industry
2. Business problem:-
Stripper wells are very cheap and companies have been using it since very long time, and it Might get expensive to implement new well technology to produce larger amount of oil from mining,
but it is mechanical property so industries have to maintain it every year and they have to fix all mechanical failures that comes within those strippers well, otherwise, it may causes money losses in oil production,
Machine Learning Jobs
and when these kind of failure occurs, oil prices can go higher….That’s why it becomes mandatory to find and fix these mechanical equipment failure as soon as possible, but again it requires expertise in finding the process of equipment failure,
“ but what if we can detect these equipment failures by enabling the power of machine learning?? “
3. ML Formulation:-
Our problem is to find equipment failure in stripper well with help of machine learning,
Yes, we can solve this issue by predicting surface and down-hole failure in equipment and save the amount of time that can wasted in to detecting process of failure in manual way, and after the prediction of equipment failure, engineers can fix the equipment on surface or send the workout rig to well location to pull out the down-hole equipment so that engineers can fix it on surface level.
4. Business Constraint:-
As machine learning prediction pipeline will going to be implemented on well using sensors ,
failure will be going to be predicted using these ML pipeline by getting input data from sensors ,
So that, field engineers will be able to monitor the equipment failure whenever they want, due to this implementation strategy we can figure out that our ML pipeline should be capable enough to predict a failure within the few seconds or maybe in 1–2 mins , then we will be able to address this failure issue as soon as possible
Basically, Dataset that we have chosen to solve this problem contains 109 columns
1) Id: which is Unique id number for each sensor’s input.
2) Target: in this column label has been given given for equipment failure ,if 0 then “ no failure ” and if 1 then “failure occured”.
3) There are two types of sensor columns:
Measure columns: these columns are single measurement for the sensor.
Histogram bin columns: These are set of 10 columns that are different bins of a sensor that show its distribution over time
6. Performance Matrix:-
As we are posing our problem as Binary Classification problem ,
We will use 1) micros f1-score to measure the performance of our model’s prediction
7. EDA:
Here we have reached at the most important part of our Case Study EDA, in this section, we will discussed about how we have done the Exploratory Data Analysis on Our Data,
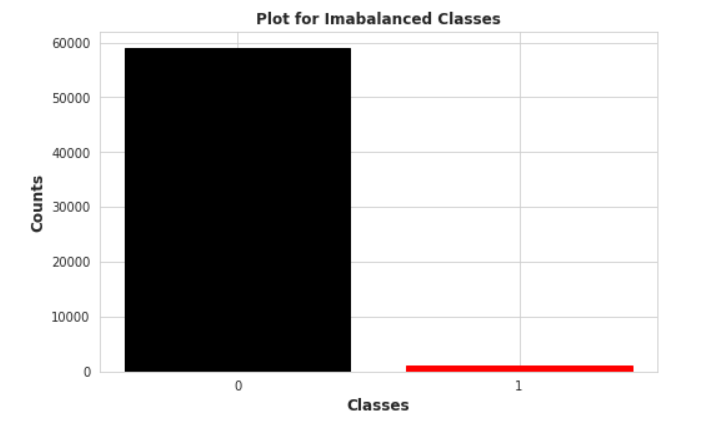
1 Class Imbalanced :
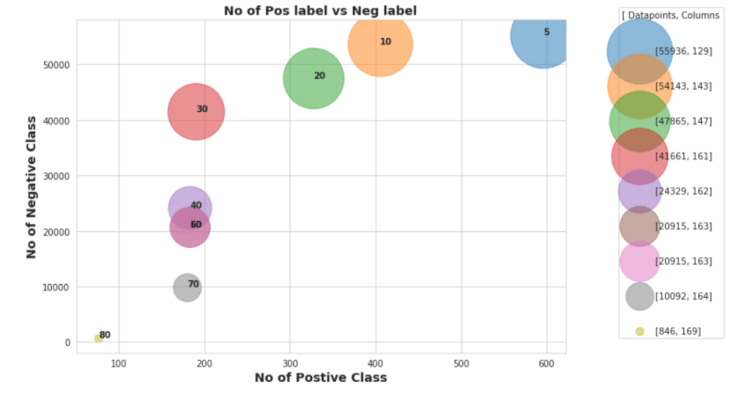
Here in this class imbalaced plot, we can clearly notice that classes are highly imbalanced , we have only 1000 positive datapoints which carries the data values when the equipment failure was occured, so we know that machine learning model becomes easily biased and produce very low recall value for minority class when we carries the class imabalaced problem in our dataset
2. Data Cleaning:
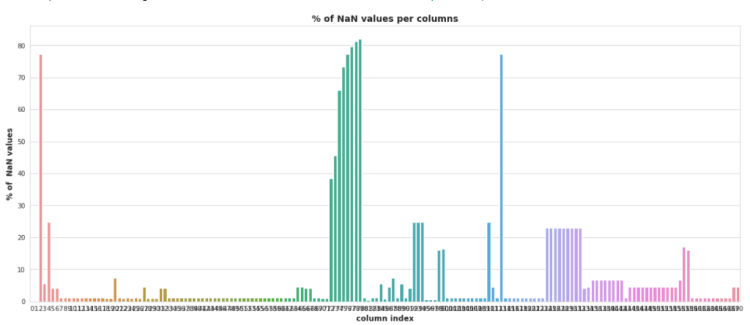
this plot shows the percentage of Nan value in each column , it is clear that there are plenty of Nan values in our dataset, and there are almost 24–25 columns which carries more than 20% of Nan values, so we have find out a way to get rid of these Nan values.
there is one of the most basic solution is to drop the columns which carries atleast one Nan value , but applyting that operation we just left with only 593 raws out of 60,000 , which means there are only 1% raw which does not have any Nan-value, so that it may lead us towards the very high data-loss
That’s why we have to find the optimal threshold percentage value by looking at this plot, so that we remove those columns which carries Nan-value percentage more than that choosen threshold and replace the Nan-value with constants in rest of other columns, But..
But how can we select that threshold ??
Here, we have selected some threshold values like [5,10,20,30,40,50,60,70,80] using which we are going to perform some experiments on data to check how dropping of Nan-value affects on
1) Class Distribution
2) Dimensionality of Data
but you will ask why did i selected the 80 as maximum because there are few columns which has Nan-values between 80–85%.
so here in this plot annotation of each scatter point suggests the threshold value that we have selected for dropping the columns and after dropping those columns which contains Nan value more than the percentage of that annoted threshold ,
we dropped all rows which carries at least 1 Nan value , because previously we have seen that if we directly drops the rows then we are loosing 99% of datapoints because of some columns which carries more than 50% of Nan values within it’s, so that first we have dropped those columns and then we dropped the rows to check whether it is affecting on class imbalance issue or not
in this plot, we can analyze that if we first drops the columns using 80% as threshold , then we are getting rid from the class imbalanced problem but we only lefts with the 846 datapoints with 164 columns , which may cause the curse dimentionality issue in model training so it is not good threshold value,
and we choose 5% as threshold then it clear that we won’t have to face datapoints loss , because with 5% we will have ~56,000 datapoints but , if you have noticed or not but we lost the almost 129 columns and classes are also highly imbalanced by selecting 5% we are loosing around 400 datapoints from class-1(positive) , which is also not preferred value to drop the columns
so after spending some time on selecting optimal threshold value to dropped the Columns, i found that 20% as a threshold as which we had selected in previous
after selecting the threshold we have dropped the columns which was carrying more than 20% of Nan values, and
then we will impute the constant in rest of Nan values based on it’s column mean or median values.
3. Feature Selection:
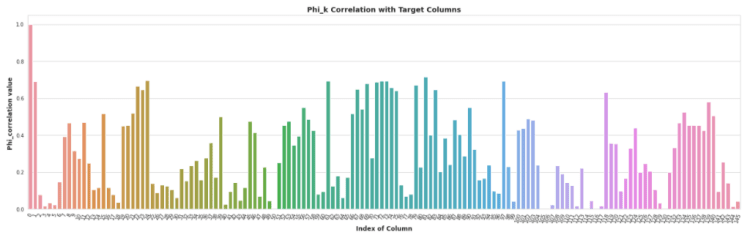
for feature selection i used Phi_k feature correlation metric to check the correlation of input variables with the target variable
Above Heatmap shows the Phi_K matrix, but we can’t analyze, how much columns should we select by just looking at this heatmp, but yeah we can say we some points in first columns which shows more than 50 of correlation value with targeted column
So we have plotted the Barplot to Analyze and select the best features those are highly correlated with the Target Column
in Phi_k Correlation Method column is highly Correlative when it Phi_k correlation value is near to 1 and less Correlative when it nears to 0.
here we also wanted to select top 15 columns based on the phi_k correlation with target columns but if we choose 15 then it might have a chance that not a any single columns would be seleted from histogram_bin’s column set,
therefore we are going select top 30 columns based on them phi_k correlation score with target column
4. Univariate Analysis:-
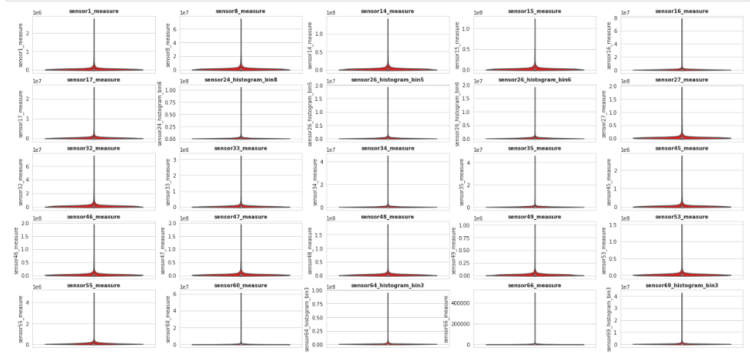
here we have selected top 30 features based on it’s phi_k correlation score now it’s time to check how these features are distributed
so to check this we have plotted violin plot for each columns so that we can analyze the distribution of the columns
In these plot we can see the violin plots for each feature column, and we have noticed one thing that each column contains the some amount of outliers, that we have detect and remove specially if it is from negative class, because number of points in Negative class is very high as compare to the Positive class, and if we toss the dataset for training with ouliers especially from the Negative class then Prediction model will become biased the Mejority class(in our case Negative Class)
therefore, further try to detect and remove the outliers of the Negative class and we will put as it is the positive class’s outliers because it will help use to make model equally biased for both classes
5. Detect Remove Outliers:
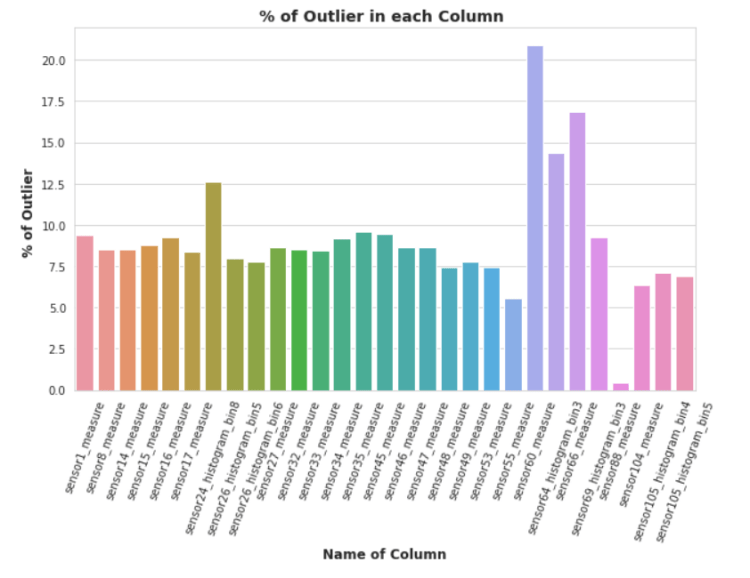
So Here in above plot it’s clear that almost all columns have outliers and most of them carries more than 5% of outliers. so if we will remove these outlier points then we might have to face loss of datapoint and will have less than 1000 of datapoints out of 60000 datapoints, and it will also increased class imbalanced problem,if it removes the outlier of minority class(Positive) then
so, we can do one thing in, future when we will start to developing a model for prediciton at that time we have to do undersampling on majority class which is negative class in our case, so somehow it will alliviate the problem of outliers and class imbalance,therefore we will remove the outliers of only negative class so that it will decreased the number of negative class points
Shape of Final : (31131, 30) Class-Distribution: 0.0 30131 1.0 1000 Name: target, dtype: int64
After removing the outliers from the negative class , we can see that the number of datapoints of negative class has decreased from 59,000 to 34,735.
8. ML Modelling:-
Performance Metric: F1-Score(Micro): so to select best model we will use F1 score (micro) because ‘micros’ Calculate metrics globally by counting the total true positives, false negatives and false positives, and for our problem false positives and false positives matters a lot so instead of taking simple f1-score, we choose this as KPI metric for our problem
here we will train 6 different models and will find best hyperparameters by train and testing the model on cv-set using Linear Search , And then we will train these model using that tuned hyperparameter and after these trained model we will calculate the micro F1-score of test data and then we will compare the best result and select the best model which will give the highest micro F1-score on Test data
Models that we are going to train for this Experiments:
Random (For findng the worst case)
Logistic Regression
KNN
SVM(Linear)
SVM(RBF)
Decision Tree Classifier
Random-Forest (ensemble)
Gradient Boosting (Boosting)
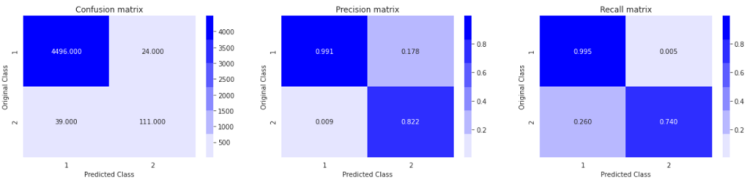
So, after completion of the various Machine Learning model’s training. we can conlude that the Random-Forest is best model among the other models which has achieved micro F1-Score = 0.9854 on Test Data after Tuning with the “n_estimator” hyperparameter on cross-validation set.
Result the we get on Test Data with our Best model
9. Custom Ensemble Classifier (Stacking):-
Even of having such a good results , we tried one new approach to get better results
here to train this Custom Ensemble Classifier ,
we followed these steps
1) First we have Split your whole data into train and test(80–20)
2) then in the 80% train set, again we split the train set into D1 and D2.(50–50).
then we did sampling with replacement from D1 to create d1,d2,d3….dk(k samples)
after that we created ‘k’ models and trained each of these models with each of these k samples.
3) so after done with training of k model , we passed the D2 set to each of these k models, and then we get k predictions for D2, from each of these models.
4) after it using these k predictions we created a new dataset, and for D2, and as we already know it’s corresponding target values, so then we trained a meta model with these k predictions by considering it as a meta data.
5) and for model evaluation, we have used the 20% data that we have kept as the test set. Passed that test set to each of the base models and we got ‘k’ predictions. after that we created a new dataset with these k predictions and passed it to meta-model
and we got the final prediction. Then using this final prediction as well as the targets for the test set, we have calculated the models performance score.
To get more insights about this approach ,you can check this paper:
Base k Leaner : we used Decision Tree classifer with higher “max_depth”
Meta Model : Random Forest Classifer (with n_estimator=k)
we had K (number of base learner as a Hyper parameter & n_esimator of random forest (meta-model))
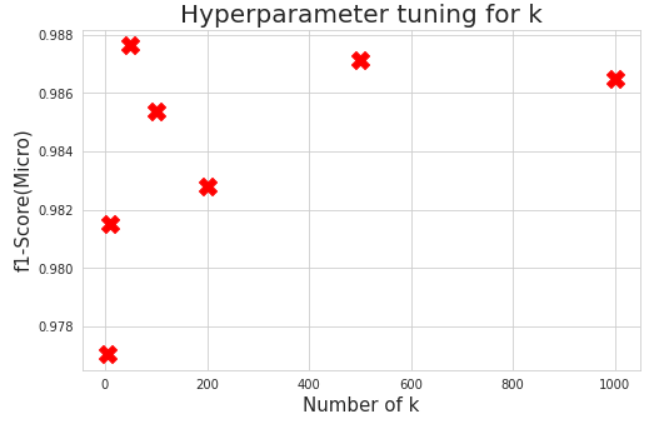
So to pick best number of k ,we did Gridsearch using different values([5, 10, 50, 100, 200, 500, 1000]) of K and then compare the results that we have calculated on test set
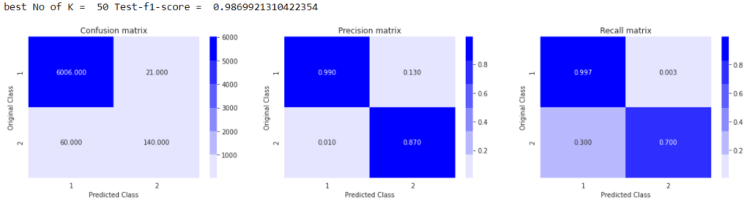
here we can see that we have achieved micro f1-score ~0.9880 with k=50, so now we are going to train our model with k=50.
even with both type of columns’s dataset (measuree + Histogram bin’s columns) results are looking much better again micro f1-score doesn’t improved much but yeah we can see improvment in the precision and Recall matrix and also no of True Postives have increased upto ~140
here, you can notice that we have achieved better results then using only just Randomforest Classifier ,
because of having good Precision and Recall we have finalized this Custom Stacking Classifier
10. Inference Pipeline:
So for inference Pipeline we will take the input from only selected sensor’s data which we have selected using Feature Selection
Above we have given Inference pipeline’s code, you can visit this from “Code for inference pipeline“ , or you guys can visit my GitHub repository for this project from where you can get it
10. Future Work:-
So to Carry this project For more batter results, you can train NN instead of using Custom Stacking Classifier or You can Combine both of this
and for more Advanced approach, you can Trained RNN, LSTM based Classifier using Only Histogram bin’s Columns from our Dataset.
11. Conclusion:-
after looking at these results of the inference pipeline, for industry purpose this pipeline can be installed at the onside Computers or maybe on cloud. Next industry operator or Engineers can connect the sensors with IoT devices to get the reading from sensors and then they can monitor the health of the stripper wells periodically by looking at the predictions of that readings, which will be collected through Sensors
While Kaggle might be the most well-known, go-to data science competition platform to test your skills at model building and performance, additional regional platforms are available around the world that offer even more opportunities to learn… and win.
In this blog, we look at a disruptive AI program – Morpheus – developed by Researchers at UC Santa Cruz that can analyze astronomical image data and classify galaxies and stars with surgical precision. If you’re reading this with “starry” eyes, we bet we’ve got you hooked.