365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Keras is a high-level Python API to build Neural networks, which has made life easier for people who want to start building Neural networks all the way to researchers.
Use Case
With this project, I want to address a problem that all of us have: too many Whatsapp images and no way to sort them. As an initial experiment, I made a model that differentiates pictures of people from memes, so that they can be labelled or moved to be stored separately (currently working, hopefully there will be a part 2).
Keras is a BIG library, and thus many of it’s useful functions fly under the radar. In this post, I explore two of such functions:
ImageDataGenerator
ImageDataGenerator is a powerful tool that can be used for image augmentation and feeding these images into our model. The augmentation takes place in memory, and the generators make it very easy to setup training and testing data, without the need of manual labeling of the images
Transfer Learning
Transfer learning is a popular technique, especially while using CNNs for computer vision tasks. In transfer learning, we take a big model that has already been trained for days (even weeks) on a huge dataset, use the low-level features it has learned and fine-tune it to out dataset to obtain a high level of accuracy.
ML Jobs
Combined, ImageDataGenerators and Transfer Learning drastically reduce both:
The amount of data required to train the model
The amount of time required to setup our own data
Setting up our Data
To use the ImageDataGenerator, we set up our data on our machine in a specific directory structure. We then point the generators to these directories in the code, to tell them where they can fetch the images from.
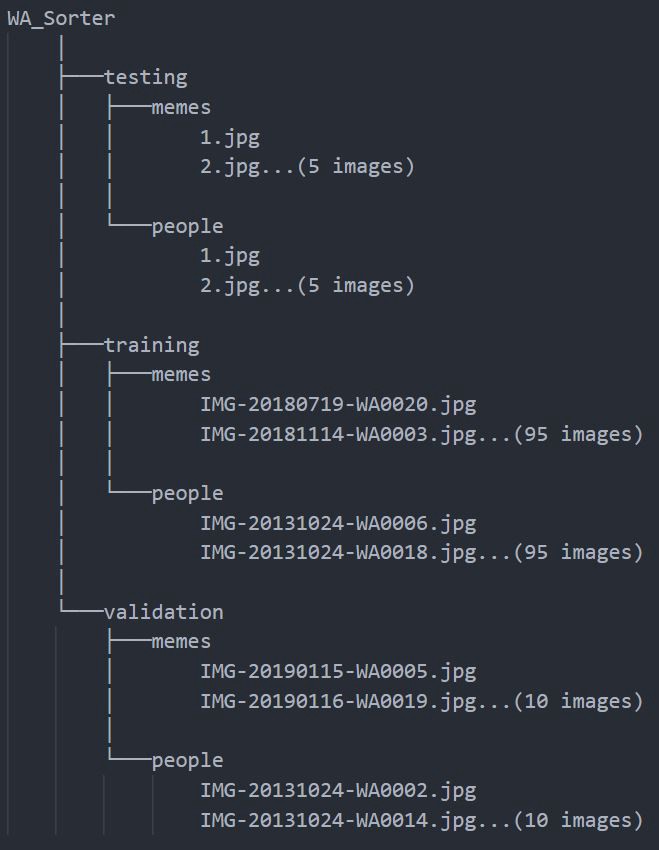
The directory structure for our task looks like this:
Directory Structure for our data
As you can observe, I use only 110 images of each class. I can get away with using so little data and still getting results due to the power of transfer learning and using already learned features.
Image augmentation is a technique of preprocessing image data. It involves applying transformations (rotation, cropping, shearing, zooming etc.) on our existing images and adding these images to our database.
These transformed images are completely new to our model and help us in 2 two ways:
Increases the size of our dataset
Makes our model more robust and capable of handling ‘true-to-life’ images, which are not ‘perfect’
Firstly, we import required libraries for image preprocessing
Next, we setup our Training and Validation DataGenerators and point them to our image directories
This line of code is used to define the transformations that the training DataGenerator will apply on all the images to augment the size of the dataset. The names are pretty self-explanatory, more information can be found in the docs
For the validation DataGenerator, we only specify the scaling factor. The other transformations are not required because we are not training the model on this data.
Next, we define the Model. I am using a VGG-16 as my base model, and add custom output layers to it for Binary Classification
We set layer.trainable=False for each layer of the VGG model, as we are using the pre-trained weights of the model.
Next, we flatten the outputs, add a custom Dense layer with ReLU activation and an Output layer with a Sigmoid activation.
Now we compile our model and train it on the dataset, that is augmented using ImageDataGenerators
After the model is done training, it is very important to save the model, so that it can be reused
To view the performance of the Model graphically, we use Matplotlib
To feed a test image into the model, we need to preprocess it first
The result of the prediction is inferred as follows:
But how do we know the classes?
I spent a considerable time to understand what the numbers in the results mean, as it is not explicitly apparent.
ImageDataGenerator assigns numbers to classes based on the Alphabetic order of the class names. Since ‘memes’ comes before ‘people’ lexicographically, it is assigned the class number 0 and ‘people’ is assigned the class number 1.
Conclusion
This concludes our discussion for Part 1 of the series. The next article will focus on expanding the Model to cove more classes (Notes/Posters etc.), followed by minifying the model and serving it as a mobile application.
Hello world! Ardi here. Today I would like to share my simple project regarding to the implementation of a Neural Network for classification problem. As shown in the title of this writing, I will be performing classification on MNIST Handwritten Digit dataset. So now, without further talk, let’s do this!
Note: full code available in the end of this writing.
So the first thing to do is to import all the required modules. Here I use NumPy to process matrix values, Matplotlib to show images and Keras to build the Neural Network model. Additionally, the MNIST dataset itself is also taken from Keras framework.
import numpy as np import matplotlib.pyplot as plt from keras.layers import Dense, Flatten from keras.models import Sequential from keras.utils import to_categorical from keras.datasets import mnist
Next, we can load the dataset by using the following code. Note that this may take a while especially if this is your first time working with MNIST dataset. After running the code below, we will have 4 variables namely X_train, y_train, X_test and y_test, where X is the image and y is the target label. These train and test data consist of 60000 and 10000 images respectively, in which all those images are already in the same size (28 by 28 pixels).
By the way you can check those numbers I mentioned above by using the following script:
print(X_train.shape) print(X_test.shape)
Then the output is going to be something like this:
(60000, 28, 28) (10000, 28, 28)
It is also worth to remember that the first 28 of each row indicates the height of the image in pixels while the last 28 indicates the width.
You can also try to print out the shape of the target label (y) like this:
print(y_train.shape) print(y_test.shape)
Then it gives the following output:
(60000,) (10000,)
The values of the target label are stored in a 1-dimensional array since essentially all the labels are represented as a single number. However, this kind of label representation is not the one that a Neural Network expect, so we need to turn this into one-hot representation before training the model (we will discuss about this later).
Up to this point you might be wondering how the MNIST Digit images look like. So now I want to show the first 5 images in the dataset by using the following code:
# Display some images fig, axes = plt.subplots(ncols=5, sharex=False, sharey=True, figsize=(10, 4)) for i in range(5): axes[i].set_title(y_train[i]) axes[i].imshow(X_train[i], cmap='gray') axes[i].get_xaxis().set_visible(False) axes[i].get_yaxis().set_visible(False) plt.show()
After running the code you will have this output:
The first 5 images of MNIST Digit dataset.
The images above show the digit written by hand (X) along with the label (y) above each images.
As I promise earlier, now we will turn all the labels into one-hot representation. It can be done easily by using to_categorical() function from Keras module. Before using the function into our main program, I will explain a bit about how the function works. So in the example below I am going to find out the one-hot representation of class with label 3 in which the total number of classes are 10.
You can see here that the output is a simple array which has all-zero values except the value of index 3. And that’s it. Such representation is called as one-hot encoding. Now what we want to do in our program is to one-hot-encode all the target labels (both y_train and y_test), which can be done by using the following code:
# Convert y_train into one-hot format temp = [] for i in range(len(y_train): temp.append(to_categorical(y_train[i], num_classes=10)) y_train = np.array(temp)
# Convert y_test into one-hot format temp = [] for i in range(len(y_test)): temp.append(to_categorical(y_test[i], num_classes=10)) y_test = np.array(temp)
Now that we can check the new shape of y_train and y_test.
print(y_train.shape) print(y_test.shape)
If all target labels are already in form of one-hot representation, then the output should look something like this:
(60000, 10) (10000, 10)
Alright, so up to this point, we have already had a correct target label shape. Now we can start to create the Neural Network model using Keras.
ML Jobs
The first thing to do is to initialize a sequential model. Afterwards, we are now able to add layers to it. Here I start the Neural Network model with a flatten layer because we need to reshape the 28 by 28 pixels image (2-dimensions) into 784 values (1-dimension). Next, we connect this 784 values into 5 neurons with sigmoid activation function. Actually, you can freely choose any number of neurons for this layer, but since I want to make the Neural Network model to be simple and fast to train so I just go with 5 neurons for this case. The last thing to add is another dense layer (here I use softmax activation function) which acts as our output layer. In the last layer we need to use 10 neurons because our classification task have 10 different classes.
# Create simple Neural Network model model = Sequential() model.add(Flatten(input_shape=(28,28))) model.add(Dense(5, activation='sigmoid')) model.add(Dense(10, activation='softmax'))
We can also use the code below in order to see the details of our architecture:
model.summary()
The output tells the details of the layers inside our Neural Network:
The code above shows that we pass categorical cross entropy for the loss function argument because it is just the best one to be used in multiclass classification problem. Next, we use Adam optimizer since it is also the best one for most cases. Lastly we have accuracy to be passed in metrics argument in order to measure the performance of our classifier.
Now into the fun part: training our Neural Network! So basically training a model is easy as what we need to do is just to run the fit() method on our model.
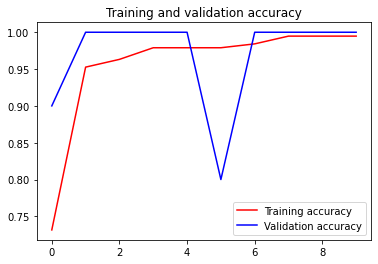
According to the output above, we can see that the accuracy is increasing (both towards training and test data) in our 5-iteration training process. I think this result is pretty good because only with relatively simple Neural Network model we can obtain approximately 75% of accuracy, even though this result can still be improved.
Now we can try to perform predictions on several images stored in our X_test variable.
So actually, this output shape is (10000, 10) in which it stores the classification probability value of each sample. Run the following code find out the actual prediction of the model:
Then it gives the following result (this is the prediction of each test sample):
[7 2 1 ... 4 5 6]
Lastly, using the code below we can try to print some images along with its predictions:
fig, axes = plt.subplots(ncols=10, sharex=False, sharey=True, figsize=(20, 4)) for i in range(10): axes[i].set_title(predictions[i]) axes[i].imshow(X_test[i], cmap='gray') axes[i].get_xaxis().set_visible(False) axes[i].get_yaxis().set_visible(False) plt.show()
Which will give an output that looks like this:
Image predictions.
The output image above shows the first 10 test images along with its predictions above each those digit images. You can see there that most of those handwritings are classified correctly. Only the 9th picture (from the left) is the misclassified sample as it should be a five (I think) but it is predicted as a four.
So that’s it! I hope you learn something from this post! Feel free to ask a question or give a suggestion so that I can give better tutorial in the next posts.
Note: here is the full code that I promised earlier. I suggest you to run on Jupyter Notebook / Google Colab / Kaggle Notebook or something like that so you can understand better each of the line of this code.
Flask is a straightforward and lightweight web application framework for Python applications. This guide walks you through how to write an application using Flask with a deployment on Heroku.
Starting off as a data analyst intern is one of the best ways to begin a career in the field of analytics and data science if you don’t have any prior working experience. The benefits of a data analyst internship are countless, beginning with the opportunity to be mentored by professionals in the field and build up your analytics skillset, up to exploring the numerous networking opportunities that internships provide.
So, in this article, we’ll discuss how to become a data analyst intern.
We’ll look at who the data analyst intern is, what do they do, and what skills and education you need to become one.
Who Is the Data Analyst Intern?
Data analyst intern is an entry-level position that plays an auxiliary role in the analytics department of a company.
That means a data analyst intern supports both data analysts and data scientists in their projects; usually by performing various data mining or data quality tasks.
However, don’t be quick to judge this internship as a boring service job. it’s a quid-pro-quo game. In turn, full-time data analysts and data scientists have less workload. And that makes them happy to spend time showing data analyst interns key practical aspects of their work.
That said, data analyst interns are usually assigned to a data analyst or a data scientist who provides them with advice and technical guidance throughout the internship.
Yet sometimes, a data analyst intern is part of a team and has pre-defined duties. At least that’s the case in team structures where there’s always an intern on a rolling basis.
In the meantime, Big Brother is watching – throughout the internship, current data analysts monitor the ability of interns to work with data, turn it into information, then leverage the information and obtain insights that can be used to improve business decisions. A data analyst intern needs to show they are perfectly capable of deriving insights and communicating the results from their findings. Their goal during the internship should be to demonstrate that they are detailed-oriented professionals who can answer critical business questions by using available data sources.
Sounds cool, doesn’t it?
A data analyst career is a great option to explore, both on its own and as a gateway into a data scientist position.
And a data analyst internship can be the first step on the data scientist career path. Many companies across literally all industries offer internship positions as part of their recruitment strategy, especially large firms who like to select their talent carefully and can dedicate the necessary management resources to an internship program.
What Skills Do You Need to Apply for a Data Analyst Internship?
We researched many job postings to discover the desired tools and skills data analyst intern candidates must have. For the record, 25% of the job ads belong to companies with 10,000 or more employees.
But don’t think that being tech-savvy is the only thing that matters. At least 50% of the job postings make an emphasis on communication. So, you need to work on your soft skills as well. After all, one of the key prerequisites is to be able to share your findings with people from the business.
What Degree Do You Need to Become a Data Analyst Intern?
50% of data analyst internships require a Bachelor’s degree… and the rest didn’t… That means formal education is not that important as long as you’re well-versed in statistics, preprocessing with programming languages, ability to work with data and navigate databases, ability to extract information from data and turn it into insights, and willingness to go the extra mile and engage with data mining and data quality tasks.
Next Steps: Starting a Data Analyst Career
Overall, to be successful in this position, you need:
some programming abilities
to know how to work with data
and to internalize different statistical and advanced statistical techniques
Ideally, you should be able to see how these methods can be applied in practice in a business environment. In fact, it will benefit you greatly if you have already learned these skills prior to your internship. This way, you’ll make the best possible impression, which is super important because – as we mentioned earlier – this is your audition to a full-time data analyst role and a data scientist job.
Now you’re aware of the most important aspects of the data analyst intern position. And you know what skills to focus on in order to become one.
Here’s another free eBook for those looking to up their skills. If you are seeking a resource that exhaustively treats the topic of causal inference, this book has you covered.
Protecting what we value little but companies value highly
Privacy is not a value explicitly written into the US Constitution, but the essentials are there. As a democratic republic, we expect to have privacy as a lack of privacy is tied to tyranny. The founding of our nation was opposed to tyranny, at least ideologically, even though we have had some major issues with the subject. Overtime, we have been able to fix many, and the major issue du jour is privacy with respect to machine learning. So, what is PII, and why is it so important to the future of machine learning?
On April 10th, 2018, the term PII was introduced to the American people thanks to Mark. Mark had a small company that violated privacy by selling people’s Personally Identifiable Information (PII), and Congress wanted to chat with him. In the introduction to the hearing, the head of the committee used the term PII, and my heart jumped. We had been having the PII discussion ever since I started at Apple, and the protocols to keep it secure only increased. PII is also close to my heart because I had found it very important to me personally and professionally back when I started grad school; I just didn’t have a better name other than privacy.
PII covers any data that could be linked back to the original subject just by having that data or some combination of data. Face images are inherently PII data. Some times data is PII because when combined with other subject information, you could determine the subject’s identity. The resulting issues with Face ID is clear, but with health data, it may not be obvious to everyone. For example, if I participate in a user study, and some health issue is discovered. If my health insurance company gets a hold of that data, maybe they would increase my rates. I’m not sure what they would do with that data, but people have been known to misuse data and PII data before.
Grad School
Originally, I wanted to work on autonomous vehicles, but I ended up doing biometrics. Back in 2006, biometrics paid the bills for many computer vision projects. My lab collected data every year. People would sign a consent form (ICF), get 5 Domer dollars, and go through a few stations to give some biometric data. Their data was de-identified with a subject ID, but there was a list tying the two together in case someone withdrew from the study. This list was more limited in who could see it for privacy reasons of course. The data collected could be used in publications, so people’s faces were shown even though they didn’t have a name tied to them. This was a normal part of the Informed Consent Form (ICF).
However, I did not participate in having my data collected. I was an anomaly for other researchers. I didn’t feel comfortable with it, and data collection was voluntary. Not everyone was happy with the concept that I would ask for people’s help but wouldn’t help myself. I was stubborn in my belief that I didn’t feel the system was private enough. I didn’t want my picture in research papers either. Ultimately, my advisors said nothing about it, which is in keeping with voluntary data collection. I proposed a system that would not keep any information to tie to the subject, but instead use a face or iris scan to recognize return people and enter new subjects into the database. That would have been a dream.
AI Jobs
I then went on to collect 4,600 3D face scans of ~500 subjects. I did my dissertation, and I graduated.
DSC
I went to work at Digital Signal Corp (DSC), and again, I declined to participate in data collection again. This time was a bit different. I was the one asking for more data. We didn’t do external data collections, and we actually didn’t even use an ICF. People were asked and volunteered, and I think more people were rubbed the wrong way that I didn’t participate. I would have if I had some assurance that my privacy would have been kept.
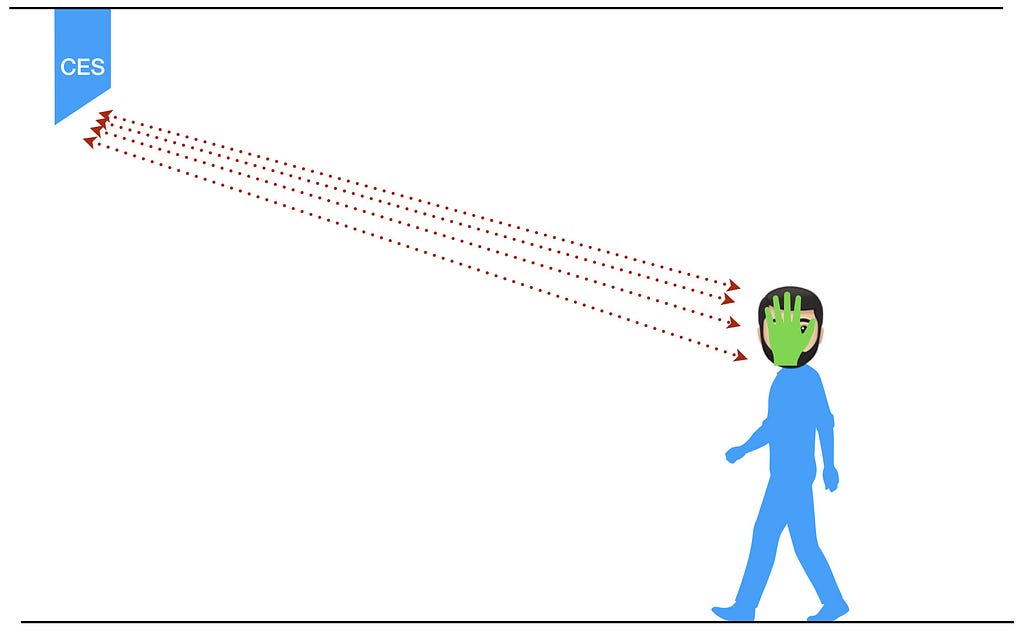
DSC had a long range (15 to 25 meters) 3D face scanner that could provide decent scans even while the subject was walking. Two years after I started, two were mounted in the hallways for tests and demos. We had a few others for data collection. However, these two scanners were constantly collecting data as people walked down the hall. Again, no ICF was signed by the employees or any visitors. Most people didn’t mind. I did and covered my face every time I walked by. I was so good at it that two years later, some guys in QA we’re thrilled when the face detector got a partial of my chin.
The ICF was eventually addressed and baked into the employment agreement. I’m not sure the legal implications of this method, and they wanted all the employees to sign a new employment contract. Many refused at first. They offered stock options, but that’s just paper to me. Unless the company has a chance at going public, stock options are as valuable as the paper they’re printed on. The amount also paled in comparison to what I had been given in a round of stock options a year previous.
I may have been the last holdout. I refused to sign a brand new agreement, only an addendum. The addendum said that if they happened to capture data of me while in the office, it was okay to use. After this fun event, I lost all trust in them. I was also in charge of the data we had, and I continued to ask for more because algorithms always needs more data. I was working on the algorithms, determining scan quality, validating data, design of experiment for more data, and failure analysis.
I don’t regret the stance I took especially given that the company went under a few years after I left. I have no idea what happened to the PII data they had. The company was bought, and fat chance without a lawsuit, anyone would be able to get their data deleted.
I left DSC to come out to California. I participated in data collection because it was heart rate and the benefits for healthcare seemed very clear. I also wasn’t giving my image. Something interesting happened: I got to see how they handled private information. I saw how everyone including myself took privacy seriously. We had ICF’s for everything. There is a Human Studies Review Board (HSRB) for any human user study collecting any data.
On top of that, I got more insight into the metrics collected from customers when they opt-in. Any metric could not be used in combination with others to uniquely identify any specific person. The only desirable data was what could help make a better product without compromising the customer’s privacy. Privacy is an essential component in the company’s DNA. Privacy was just as important as the user experience because it was part of the user experience.
PII: To consent or not consent, that is the question.
Then I switched to Face ID. Would I participate in data collections? Would I use my own data to improve the customer experience? More importantly, could I trust my company to securely store and use my PII?
I decided, I could trust them. I saw how they acted in the previous two years, and I didn’t see any intention from anyone I worked with to convince me otherwise. Everyone I’ve worked with have been professional and steeled with integrity with respect to PII data.
Privacy is a virtue I hold dear.
My PII journey may seem very boring, but if you’ve read this article to this point, maybe you find it interesting. Only when a user experience is important to us do we care so much about it to make it right for them. I have cherished my privacy for years, and I’m glad to have worked on a project that collected so much data while working so hard to make sure it is secure and kept safe.
If you like, follow me on Twitter and YouTube where I post videos espresso shots on different machines and espresso related stuff. You can also find me on LinkedIn.
Using AI & ML to Fight Against Pandemics Like the Coronavirus (COVID-19)
This year, the world changed in the span of a few months, in unprecedented ways that surprised and overwhelmed every country on this planet.
The greatest global crisis since World War II and the largest global pandemic since the 1918–19 Spanish Flu fell upon us. Everybody spent a better part of their day looking at the daily rise of the death toll and the rapid, exponential spread of this novel strain of the COVID-19 virus.
Millions of people lost their jobs, unemployment rose through the roof, global travel and hospitality industries were all but decimated, international relationships were frayed, healthcare systems were stressed to the limits.
Of course, the fight was not one-sided. Governments, private enterprises, community organizers, healthcare organizations, scientists and engineers, front-line workers, supply chain and logistics organizations — all pitched in to battle against the (still raging) tiny, invisible enemy.
This was, in many ways, the first truly global pandemic of the 21st century, which impacted the largest swath of global population and economies. Therefore, it is also the first time that the most modern and ambitious tools of our scientific and industrial might are being deployed to control and mitigate the impacts of a pandemic.
Therefore, it’s natural to raise the question:
How can the tools of Artificial Intelligence (AI) and Machine Learning (ML) help in this fight against the current and future pandemics?
After all, AI/ML is regularly hailed as the most transformative and promising technologies of the 21st-century civilization and are rightly expected to help humankind fight against future pandemics.
AI Jobs
In this article, we discuss a few possible ideas in this regard including:
Personalized Risk Assessment to Aid Epidemiological Models
Vaccine Development with the help of Artificial Intelligence (AI)
Protein Structure Prediction
Risk Classification & Clustering for Better Contact Tracing
Digital Surveillance of Epidemics
So, let’s take a look at how artificial intelligence and machine learning can be put to use in fighting against pandemics, now and in the years ahead.
Personalized Risk Assessment to Aid Epidemiological Models
AI and ML are already widely used in a variety of recommendation systems and business practices for personalizing the consumer choice for products and services. Amazon, Netflix, Facebook, Twitter, decide — both on the basis of our personal profile and macro-level data from other users — what to show us for books, movies, household products, friends’ comments, community messages, etc.
Going forward, the same strategy could work for fighting against future pandemics. Using multiple sources of data, machine-learning models can be trained to model and predict the clinical risk (or at least a probability measure) of an individual suffering severe outcomes if infected with diseases like COVID-19. This can lead to the prediction of the probable usage of critical care resources in a given healthcare system to better allocate resources to those in greatest need.
The final goal will determine the choice of the type of the models. If they are mostly used for predictions, then powerful Deep Learningalgorithms can be used for this purpose. On the other hand, if explainability is a key requirement, then models with less parametric complexity, like decision trees or logistic regression can be used in a supervisory setting. Given a large dataset, and feature engineering by domain experts and data scientists, even a classical ML algorithm can demonstrate high accuracy and sensitivity/specificity.
Many epidemiological models already work this way. However, they mostly focus on the disease-spreading dynamics and related mathematical parameters of the particular epidemic on hand, without pulling data from all the possible sources. Large-scale ML systems are adept at dealing with disparate data sources at high velocity, and therefore, changing demographics and overall health pattern of a large population can be integrated into the existing epidemiological models using ML algorithms in a synergistic manner.
Standard epidemiological models operate on the macro signals and do not always lead to resource optimization, but the characteristics of individuals can be important for estimating critical care requirements in a particular region. In this regard, future pandemics will be fought with greater efficiency and lesser wastage of resources, with the help of AI/ML.
Vaccine Development with the help of Artificial Intelligence (AI)
As this article points out, the Harvard T.H. Chan School of Public Health and the Human Vaccines Project have announced the Human Immunomics Initiative, a joint effort that will use artificial intelligence models to accelerate vaccine development.
It will bring together experts in epidemiology, causal inference, immunology, statistical modeling, computer science, and computational/systems biology to develop AI-powered models of human immune system and response mechanisms that can be used to accelerate the design and testing of vaccines and therapeutics for a wide range of diseases.
AI-powered models inherently allow for stochastic scenario analyses, which is critical for such an enterprise, where multiple vaccine trials may be undergoing at the same time and healthcare and Government authorities have to make speedy decisions about the actual human trial and distribution by looking at various scenarios and weighting them properly. An individual, anecdotal approach is sure to fail in such complex situations. Large-scale data analytics is the only tool we have to make sound decisions.
Although the focus is on a large variety of diseases, it is needless to say that these kinds of AI-based models will be most effective where the largest amount of raw data is available. Global pandemics, such as COVID-19, play that role of data generator perfectly. While this kind of ambitious project takes time to develop robust models and safe drug-design mechanisms, and cannot be readily applied for an ongoing pandemic, they are the right kind of initiatives for preparing human society to fight against future pandemics.
Protein Structure Prediction
Global pandemics such as COVID-19 are most often caused by viruses. At the fundamental structural level, a virus mainly consists of a single (or a few) strands of DNA/RNA. Determining the 3D protein structure, i.e. the sequence of amino acid molecules from the genetic test data, is the key to develop certain classes — subunit and nucleic acid type — of vaccines.
This task is computationally infeasible (no matter how much hardware resources you throw at it) if tried using conventional protein-folding algorithms. Artificial intelligence can play a significant role to help solve this challenge with the latest techniques of deep reinforcement learning(DRL) and Bayesian optimization.
In fact, on that cue, DeepMind, the famous DL research unit of Google, introduced AlphaFold, a DRL-based system that predicts the 3D structure of a protein based on its genetic sequence. In early March, the system was put to the test on COVID-19. AI researchers at DeepMind were able to release structural predictions of several under-studied proteins associated with SARS-CoV-2 to help the worldwide clinical and virology research community better understand the virus and its impact on human biology.
It is indeed a strong testament to the generalizability and universality of the techniques developed in the fields of deep learning, game theory, and reinforcement learning, that the same underlying platform that powers AlphaGo (which beat world champion Lee Sedol in the classical game of Go) could be adapted for this protein structure prediction task with only some suitable injection of domain knowledge.
Multiple other research groups, at UT Austin and University of Washington, are trying to build 3D atomic scale models of the COVID-19 spike protein, which attaches to the human body cells. They employ AI tools to search for the optimal structure from a host of candidate designs.
Risk Classification & Clustering for Better Contact Tracing
One lesson learned from COVID-19 has been that forceful government interventions with shelter-in-place orders are only sustainable up to a point, beyond which, the enormous economic burdens start to pile up. Therefore, widespread testing and contact tracing have been acknowledged as the best possible policies to tackle any future pandemic beyond the most critical phase in order to mitigate the spread of a virus.
Traditional contact tracing techniques are dependent on isolated data chunks gathered from individual testing centers and government/health authorities. When tens of millions of data points start streaming in, conventional techniques can easily fail.
Drawing from the same idea above, we can put AI and ML techniques to use for real-time classification and clustering of micro-populations, who are at elevated risk of contracting or spreading the disease. This will be incredibly helpful for isolation and contact tracing, even with limited resources.
Advanced clustering techniques such as DBSCAN, hierarchical agglomerative clustering, multi-exemplar affinity propagation (MEAP), graph-based multi-prototype competitive learning (GMPCL), and clustering based on geospatial regression techniques, can be brought to bear on this problem.
Many of these modern methods are particularly optimized to work with large-scale streaming data, which is suitable for a scenario with ever-increasing testing and travel data constantly feeding into the ML system.
On top of clustering, dimensionality reduction techniques can also be used on this kind of data to identify the key factors which are giving rise to such clusters. These factors can be communicated to the appropriate authorities for high-level policy decisions with regard to travel, testing, isolation, and other suitable community-based actions.
Digital Surveillance of Epidemics
Ever-growing amounts of data are present on social media, blogs, chat rooms, and local news reports that give us clues about disease outbreaks happening on a daily basis. This trend is only going to grow as more people (particularly in countries like India, Brazil, South Africa, or China) go online and share their fear and symptoms, search for medicine or doctors, discuss governmental and healthcare policies.
Digital surveillance is the next-generation AI-powered tool that promises to track these conversations, data streams, search patterns, and the associated digital demographics — at an exabyte scale — to model, predict, and warn healthcare systems and Governments about emerging epidemics throughout the world.
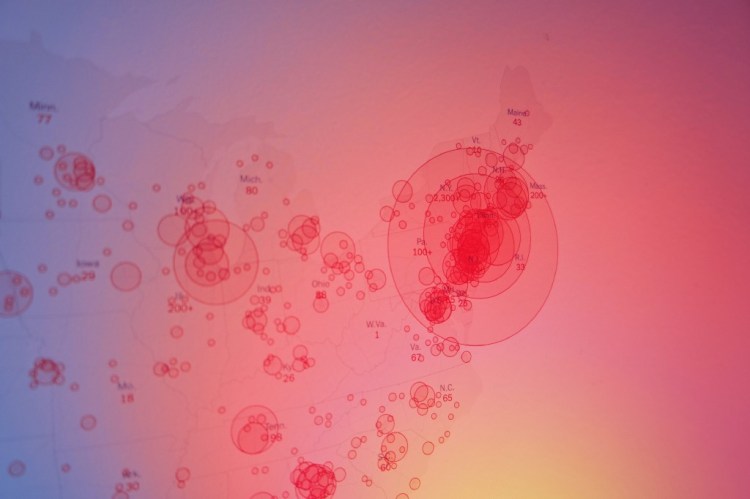
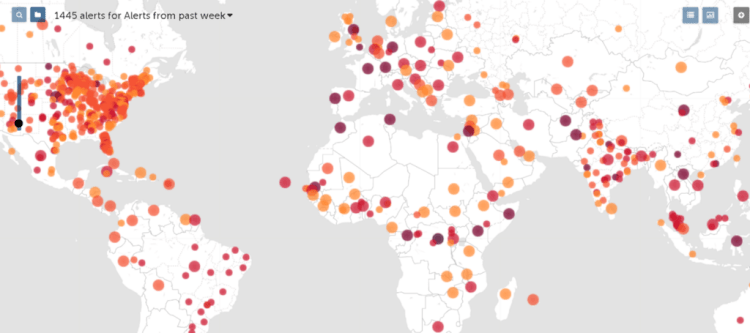
Efficacy of such digital tools have already been demonstrated. Nearly a week before the WHO first warned of a mysterious new respiratory disease in Wuhan, China, a team of global disease experts based in Boston captured digital clues about the outbreak from online press reports and released their findings in a real-time monitoring system called HealthMap.
When you visit their website, you will be presented with this kind of interactive global map, which is being updated every hour.
This is being touted as Digital Epidemiology, where traditional mathematical models are being replaced with or complemented by machine learning and pattern-finding models, generated by Big Data technologies. The key advantages of this approach are, not surprisingly, speed and volume.
The trustworthiness or the so-called ‘veracity’ of disparate data sources still remains a pressing issue. Although, ML researchers have always liked to work with a diversified source of data, which can be readily ingested by ensemble models (e.g gradient-boosted trees) to democratize the predictive power and reduce bias in the models.
Looking Into the Future of AI & ML Predicting Spread of Pathogens
In this article, we took a quick tour of the various promising technologies and initiatives that are using AI/ML tools and techniques for solving the great challenge of modeling, mitigating, and predicting the spread of infectious pathogens, which cause global pandemics.
As the world becomes more digitally connected, the healthcare systems and policy initiatives which embrace data-driven technologies (like artificial intelligence and machine learning) are likely to stay ahead in the battle against epidemics.