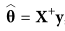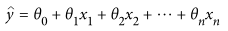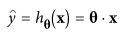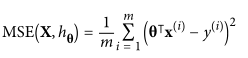A review outside the common datasets for Machine Learning
When you being in the Machine Learning field, you usually use the common datasets such as MNIST, Iris, the 20 newsgroups, … But there are hundreds of rare and interesting datasets that can be found online. At Immune Technology Institute we have asked our teachers to create a list of the most strange datasets they have found. Here we go!!
Price of Weed
This is a repository which contains a registry of the historical marijuana prices, which shows significant differentiation at the state level in prices. The question here is how the data has been collected?
Although it may seem a useless dataset, it may be very relevant in the times we live in, as many countries are considering legalizing marijuana.
Length of chopsticks
If you have never asked you, as is normal, what is the optimal length of chopsticks, no worries, someone has asked this question before. A researcher team tried to evaluate the effects of the length of the chopsticks on the food-serving performance of adults and children. For this reason, they created this dataset for finding the optimal length of chopsticks.

They concluded that the food-pinching performance was considerably affected by the length of the chopsticks. The researchers suggested that families with children should provide both 240 and 180 mm long chopsticks. In addition, restaurants could provide 210 mm long chopsticks, considering the trade-offs between ergonomics and cost.
Rice Images
A dataset which contains more than of 3500 rice grain’s images of 2 different species. Different properties were extracted from each grain of rice, such as:
- The longest line that can be drawn on the rice grain
- The shortest line that can be drawn on the rice grain
- Or the perimeter of each grain.

Popular dog names in Sweden
Did you know that the most popular dog name in Sweden is Molly?
Sweden: popular dog names, by number of animals 2018 | Statista
This dataset collects the most popular dog names in Sweden in 2018 by number of animals. Bella ranked the second most popular name, with almost six thousand animals, followed by the name Charlie, reaching a number of approximately 4600.
Flags Data Set
I am pretty sure that Sheldon will love this one… This dataset contains details of various nations and their flags, such as:
- The religion of each country.
- The predominant colour in the flag.
- If the flag contains a crescent moon or sunstars.
- If it contains an eagle, a tree, …
Maybe it is interesting for predicting the religion of a country from its size and the colours in its flag.
Trending AI Articles:
1. Microsoft Azure Machine Learning x Udacity — Lesson 4 Notes
2. Fundamentals of AI, ML and Deep Learning for Product Managers
Sometimes it is also interesting to see how people find relationships in data where they are not visible to the naked eye. This website is an expert in finding correlations where no one else can find them, for example:
Cheese consumption vs Number of people who died by becoming tangled in their sheets

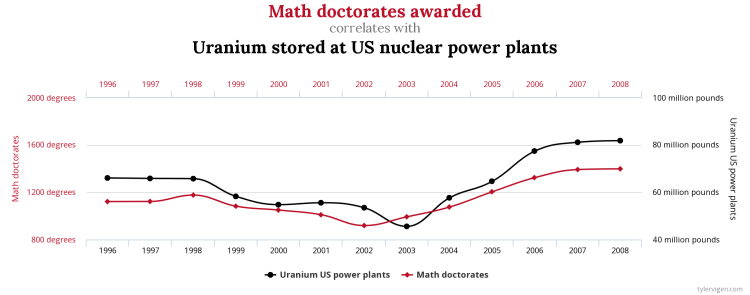
Math doctorates awarded vs Uranium stored at US nuclear power plants
Total revenues generated by arcades vs Computer science doctorates awarded in the US
Discover new correlations using this website and share your results with us! ?
Who we are?
At Immune Technology Institute we try to apply and teach the most advanced technology at the computational field. Furthermore, we love sharing knowledge since we consider that it is when it becomes powerful.
If you want to learn how to develop real-world applications or how to handle large amounts of data, you could be interested in our Master in Data Science. It is a program aimed at professionals that seek to specialize in Data Science, know the main Artificial Intelligence techniques and how to apply them into different industries.
We will host an online information session on September 24, with the director of the master, Mónica Villas. IMMUNE can help you boost your career through its partner companies and contacts with recruiters and professionals in the sector. You can sign up HERE.
Wait one more thing — Datathon
Do you want to be a data scientist? Sign up for the virtual Datathon organized by IMMUNE Technology Institute in collaboration with Spanish Startups on September 19th. Online training from the best data experts and a great challenge to test your knowledge. Don’t miss out on the prize! You can sign up HERE.
This article have been written by: Alejandro Diaz Santos — (LinkedIn, GitHub) for IMMUNE Technology Institute.
Don’t forget to give us your ? !




A little bit of strange/interesting Datasets for Machine Learning was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.