365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
How to Deploy AI models? Part 6- Deploying Web-application on Streamlit via Github
This Part is the continuation of the Deploying AI models , where we deployed Iris classification model using Decision Tree Classifier, had a glance of version control i.e. Git. In this article, we will see how we can deploy data science as well as Machine Learning application easily with the help of open source library streamlit.
1. Digit Classification Model Web application using Streamlit.
1.1. Packages
The following packages were used to create the application.
1.1.1. Numpy, pandas
1.1 .2. Streamlit
1.3. Dataset, SVC, Model Selection from sklearn
Big Data Jobs
1.2. Dataset
The dataset is used to train the model is of digit dataset composed of 10 classes i.e. label is 10 from 0–9 with 180 samples per class where each sample is represented as a vector with dimension of vector of length 64 thought it can be reshaped into 8*8 vector to represent the dataset into 1-D image
Predictors: Pixel value in form of vector with length 64, where each piel value ranges between 0–16
Target : Digit labelled from 0–10
Dataset Shape: 1797 * 65 metrics
Figure 1. Dataset Overview
1.3. Model
For training the model we followed the following procedure:
DataSplit up: 8:2 i.e. 80% training set and 20% for the test set
Model: Support Vector Machine Classifier
Below is the code for the training the model.
import sklearnimport sklearn.datasetsimport sklearn.ensemble import sklearn.model_selection from sklearn import svm, metrics import pickle import os
#load data
data = data=sklearn.datasets.load_digits() #Split the data into test and
#Train a model using random model = svm.SVC(kernel=parameters['kernal'],tol=float(parameters['Tol']),max_iter=int(parameters['Max_Iteration'])).fit(X_train,y_train)
#test the model result = model.score(test_data, test_labels) print(result)
#save the model filename = ‘iris_model.pkl’ pickle.dump(model, open(filename, ‘wb’))
1.4. Frontend using Streamlit
For feeding the value in the trained model we need some User Interface to accept the data from the user and feed into the trained neural network for classification. As we have seen in the section in 1.2 Dataset where we have 64 vectors for each samples with 10 classes .
We will use streamlit API to create the frontend and for displaying the various frontend part of this application. Instead of creating the separate the html files for the front end file streamlit API gives us the flexibility to write the code in the same script which is shown below (as refrence):
import streamlit as st import pandas as pd import numpy as np import matplotlib.pyplot as plt import sklearn.datasets from sklearn.model_selection import train_test_split
col1, col2= st.beta_columns(2) with col1: st.write("**Profile :** https://www.rstiwari.com") with col2: st.write("**Blog :** https://tiwari11-rst.medium.com/")
# Text/Title
st.title("Logistic Regression - Mnist Dataset") }
Similarly you can create the various frontend elements for reference please refer to the Link. This article does not covers the concept of how to use streamlit for developing the model — It covers how we can deploy the model on streamlit.
1.5. Extracting Packages and their respective versions
We need to create the require.txt file which contains the name of package we used in our application along with their respective version. The process of extracting the requirement.txt file is explained in the Article:Deep Learning/Machine Learning Libraries — An overview.
For this application below is the requirement.txt file content.
Streamlit is gaining popularity in Machine learning and Data Science. It is a very easy library to create a perfect dashboard by spending a little amount of time. It also comes with the inbuilt webserver and lets you deploy in the docker container.
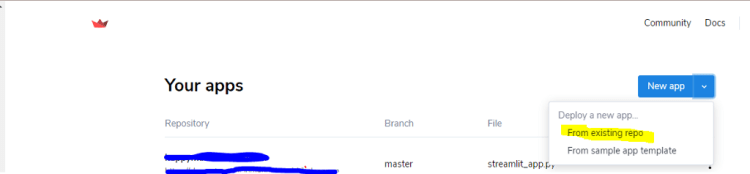
Click on the New app and select Deploy from existing repo option as shown in below image.
Fig 2. Deploying the branch
Step 2:
Select the Repository
The branch of the repository where the files are present main or master and the name of the script file as shown in below image:
Fig 3. Deployement ProcedureFig 4. Application is being deployed
Congratulation!!! we have successfully deployed an Iris classifier web application.
4. Deployed Web Application
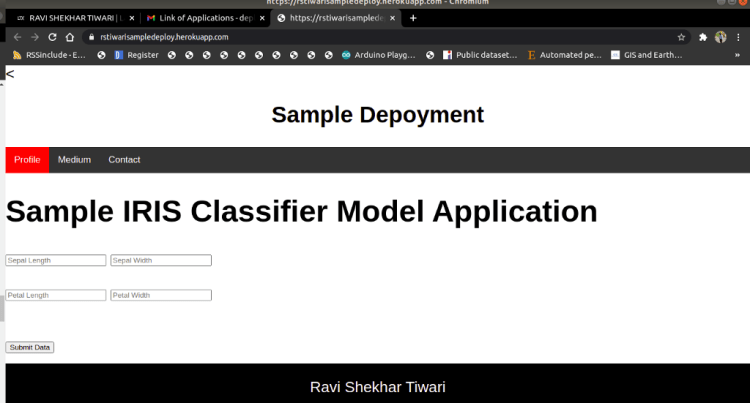
The overview of the deployed web application with Iris Application: Link is shown below.
Fig 5. Deployed Application Digit Classification
We have reached to an end to the model deployment series, hope you al have gained something from this series. Please visit this link to get list of all deployed application.
Special Thanks:
As we say “Car is useless if it doesn’t have a good engine” similarly student is useless without proper guidance and motivation. I will like to thank my Guru as well as my Idol “Dr. P. Supraja”- guided me throughout the journey, from the bottom of my heart. As a Guru, she has lighted the best available path for me, motivated me whenever I encountered failure or roadblock- without her support and motivation this was an impossible task for me.
Reference:
Extract installed packages and version :Article Link.
Notebook Link Extract installed packages and version :Notebook Link
Data Labeling — New Trends and Challenges in Data Annotation Industry
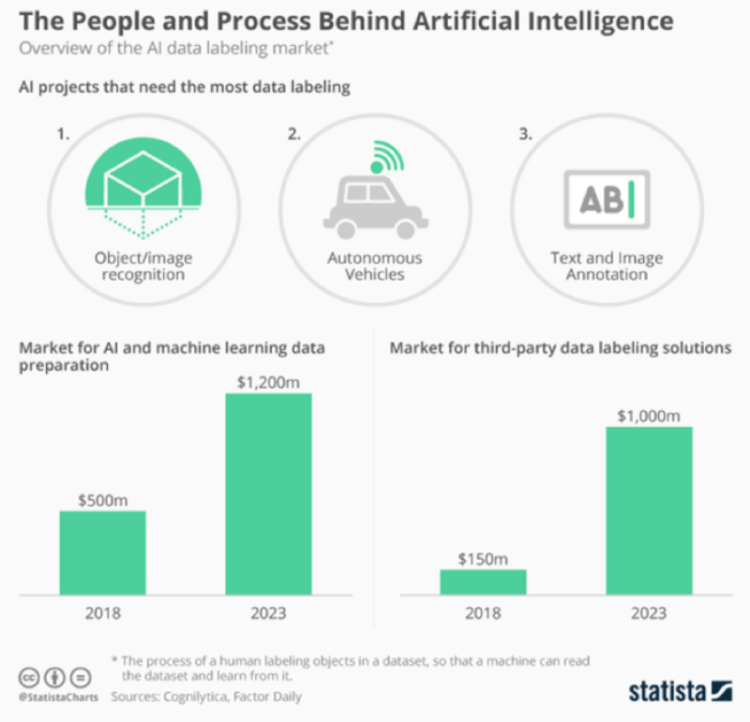
Data Annotation Market Size
The global data annotation market was valued at US$ 695.5 million in 2019 and is projected to reach US$ 6.45 billion by 2027, according to Research And Markets’ report. Expected to grow at a CAGR of 32.54% from 2020 to 2027, the booming data annotation market is witnessing tremendous growth in the forthcoming future.
The data annotation industry is driven by the increasing growth of the AI industry.
Big Data Jobs
At present, the commercialization of Artificial intelligence has reached a stage of basic maturity in terms of computing power and algorithm. In order to better meet the landing needs and solve specific pain points in the industry, scaleable annotated data for algorithm training is still indispensable.
It is said that data determines the success of AI implementation. Moreover, the forward-looking data products and highly customized data services have become the mainstream of industry development.
In the next few years, the data annotation industry will have the following trends and challenges.
Trend: Industry Reshuffles, Intensifying competition
After years of development, the data annotation industry has entered a period of rapid growth.
From the micro point of view, the continuous expansion of the market means more participants and more competition. Due to the low entry threshold and the excessive dependence on human resources, a large number of small and medium-sized data service providers are clustered in the industry.
With the improvement of the technical threshold, the demands Changement of AI enterprises, and the increase of labor costs, small and medium-sized data service providers will face the increasing cost pressure. In the next 1–2 years, the industry will likely usher in a wave of “shuffling period”.
With the speeding up of commercial landing, the AI companies also put forward new requirements for data service suppliers. The quality, refinement, customization is more and more popular on the demand side. On the supply side, technical strength, controlled management, and so on have brought a new challenge.
Challenges: the Outmoded Industry Development Under the New Demand
As mentioned, “more forward-looking data products and highly customized data services have become the mainstream of industry development”. However, the current level of industry development is far from meeting these new needs. The data annotation industry faces the following challenges:
1. Different industries and business scenarios have different requirements for data annotation. The existing annotation ability is not refined enough to support customization services.
Data annotation has a wide range of application scenarios, including autonomous driving, intelligent security, new retail, AI education, industrial robots, intelligent agriculture, and other fields.
Different scenarios have different labeling requirements, such as automatic driving industry mainly focuses on pedestrian recognition, vehicle identification, traffic lights, road recognition, etc. The security industry mainly focuses on face recognition, face detection, visual search, key points, and license plate recognition.
2. Customer points: low labeling efficiency, poor data quality, lack of human-machine cooperation.
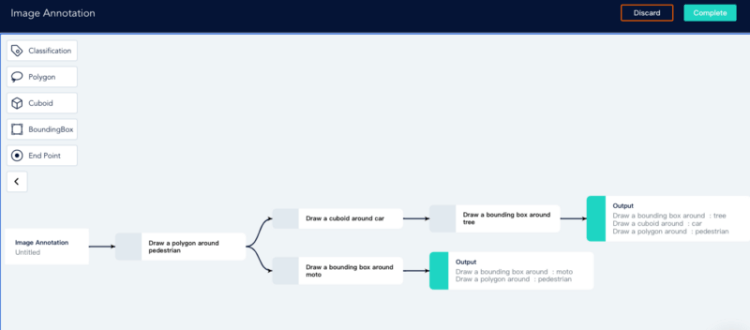
The particularity of the data annotation industry determines its high dependence on manpower. Currently, the mainstream annotation method is that the annotator completes the work such as classification, picture frame, annotation, and tag with the help of labeling tools.
Due to the uneven ability of the annotators and the imperfect functions of the annotation tools, the data service providers are deficient in annotation efficiency and data quality.
In addition, at present, many data service providers ignore or do not have human-machine cooperation capability, and do not realize the mutual effect of the AI industry on data annotation.
For instance, the AI-assisted tool can not only effectively improve efficiency but also greatly improve accuracy.
3. Data labeling service providers, who rely on crowdsourcing and subcontracting, fail to guarantee quality.
At present, data labeling mainly relies on human resources, and human resources account for the most part of the total cost. Therefore, many data service providers give up their in-house labeling teams and turn to subcontract to complete the labeling business.
Compared to the in-house labeling team, crowdsourcing and subcontracting have lower costs and become more flexible. However, the labeling loop is too long to cooperate and data quality is difficult to control. From a long-term perspective, the in-house labeling team is more in line with the needs of industrial development.
4. Data annotation tasks based on crowdsourcing and subcontracting mode will cause data security issues and encounter the risk of privacy leakage.
The demander side of some special industries, such as financial institutions and government departments, pays particular attention to data security. However, some data labeling enterprises distribute and subcontract these sensitive data to other service providers or individuals only for cost consideration, which brings huge potential data leakage risks. How to establish a perfect data security protection mechanism has become a vital factor to consider.
To sum up, thedata annotationindustry has a broad prospect, but it also faces many challenges.
In the foreseeable period of industry transformation, both medium-sized and large-sized data service providers cannot avoid the changement. Only by enhancing the self-developed technical strength and by speeding up the evolution can they be competitive in the new era.
ByteBridge.io, a Human-Powered Data Labeling SAAS Platform
ByteBridge is a human-powered data collection and labeling platform(saas) with robust tools and real-time workflow management. It provides accurate and consistent high-quality training data for the machine learning industry.
Via the ByteBridge dashboard, you can seamlessly upload your project and utilize end-to-end data labeling solutions such as visualizing labeling rules. Through the dashboard, you can also manage and monitor your project in real-time.
ByteBridge: a Human-powered Data Labeling SAAS Platform
As you can manage your project in real-time, you can initiate or terminate your task as you wish according to your own timeline.
ByteBridge: a Human-powered Data Labeling SAAS Platform
Meanwhile, the transparent pricing which eliminated the various heavy commissions apparent in the current market lets you save resources for more important investments.
For more information, please have a look at bytebridge.io, the clear pricing is available.
The full value of your deep learning models comes from enabling others to use them. Learn how to deploy your model to the web and access it as a REST API, and begin to share the power of your machine learning development with the world.
As you start your career as a Data Scientist, should you start with a Startup or an MNC, which one will give you a prosperous career? This article will help you answer this!!
If you are starting out as a beginner Data Scientist, one of the most important questions you might have is where to start your career. Startup (a relatively small company starting up) or MNC(Multi-National Company-a big company like Google)?
In this article, we will address this issue once and for in order to gain clarity as you proceed in your career.
The decision taken at the start of your career is very crucial and profound since your career growth depends on it, and as such you MUST think twice !!
We will address this conundrum (a state of confusion) based on the following 5 pillars:
Available Opportunities
Salary
Specialist Vs Generalist
Skill Development(Future growth)
Risk
Before we begin, I assume that you already have developed some level of a Data Science skill and you are in the stage of applying for a job. However, if you don’t have the relevant Data Science skills that will put your profile ahead of others and get you hired, then I personally recommend this hands-on course on Udemy which will easily equip you with the most relevant skills.
Let’s get started…!!
1. Available Opportunities
Whether you will think of starting your career in a Startup or MNC, the first thing to consider is the degree of availability of the kind of job role you are looking and whether you even going to meet their job requirement.
Now putting this in mind, let’s juxtapose(compare side by side) the two phenomenon-job availability in Startup Vs MNC
Data Science jobs are continue-sly growing in both Startups and MNCs and this trend is even expected to boom in the upcoming years.
Over the past 3 or 4 years, the most Startups that has emerged are more data driven than ever, thereby open up more opportunities for data related roles. Again, most investors are now more inclined to investing in data driven Startups as the ROI (return of investment) in such companies turns to be high. This has called for most Startups to spend large amount of their budget looking for data related talents-such as Data Scientist, Data Analyst, Business Analyst, Machine Learning engineer, etc.
Although many Data Science job descriptions and requirements can be very demanding, it is quite exacting in Startups. Most Startups gives flexibility and employ freshers or beginners and groom them over time.
Big Data Jobs
People with experience easily grab Startup data science positions, although, as I mention earlier, there is much chance for a fresher or beginner to also easily grab a data scientist job in a Startup.
Most MNCs are already data driven and know what they want if they open up a role to employ a Data Scientist. Most often, MNCs will prefer someone with a working experience to be employed as a Data Scientist, at least someone with a domain knowledge.
If you examine the job requirement for an MNC, you realise that most of the time, they will mention specifically 2+, 3+, 7+, etc years of experience with some specifically defined skills. The best bet for a fresher to enter into an MNC as a Data Scientist is through internship (highest chance) or with some strong significant relevant profile.
Therefore, if you plan to enter an MNC as a Data Scientist, take advantage of their internships(almost all MNCs have internship opportunities for student-visit the particular companies website to apply).
Hint: look for referral on Linkedin that works in that company, that makes it easier to grab the internship. Don’t forget the internships are also competitive and referrals can help.
In a nutshell, Data Science jobs are available in both Startups and MNCs. Freshers are more likely to get hired as Data Scientist in Startups than MNCs.
Word of Advice: If you are a fresher or switching roles to a Data Science domain, and you are targeting an MNC, then start from a Startup to create a strong profile for at least a year mastering specific skills(more on this later) and then start hunting for data science jobs in MNCs-you will stand a better chance.
The money is the main ish here. Working as a Data Scientist is not like watching your favourite TV show, you can stare at you computer screen for 3 days without a single smile, just to fix a bug.
And you think the salary is not important?
Passion is there, but that is behind the salary. In fact, most serious Data Scientists are socially outcast just like most software engineers, 24×7 on the laptop. I am one of them so I know the feeling.
The job is exciting when you see your results out there-for example when you build a very robust recommendation system and see it performing excellently well, it’s very fulfilling. But trust me, it takes more than just a passion to do that.
The MONEY is very important !!
Most Startups with good funding has a very awesome salary package as well as other additional packages to make your life easier. However, there are quite a number of Startups that are either self funding or has not secured enough funding or maybe has bad management system and as such, salaries become an issue when you enter into such companies.
Some Startups pay as high as you can get in MNCs or even better. However, if take into consideration the security of your salary, then be cautious. Some Startups are hardly breaking-even(neither making profit nor loss-just surviving), you wanna be a victim of their sorrows.
Word of Advice: when applying for Startups, find out if they have enough funding, at the extreme, find out their financial statement for last year, read their salary ratings on Glassdoor, reach out to at least 3 people already working in the company to make your enquiries, don’t just jump into the company to crucify yourself!!
In MNCs, money is not a problem !!
They can make turn your life in one month and make create a paradise for you if you have the skillset they require. If you entering into an MNC, don’t even worry about the salary one bit. That is sorted!!
3. Specialist Vs Generalist
Remember, a Startup is starting up and most of the time, even roles in the company are not well defined. You will find the accountant playing the role of a financial analyst and the product manager doubling as a business development specialist. That’s how things are. With a limited resource, every Startup wants to survive and therefore every employee is a doctor that is treating the company of different diseases that they have little or no knowledge of.
So what should you expect? Well, expect to be a Ninja….lol
In a Startup, you will have the title as a Data Scientist, Data Analyst, Data Engineer, Machine learning Engineer, Business Analyst or whatever, but expect to be all of them. If the Startup is not a bit organised and well funded, they won’t have the means to employ different people for diverse roles and therefore any role or work close to yours will be assign to you.
In my previous company (a Startup), my title was machine learning engineer, and my real role? well, right from framing business problems, talking to customers to understand their needs well, mining the data, building and deploying machine learning models, all the way to building dashboards to explain to business owners what is happening behind the scene.
I was more like Jack Bauer in 24 X 7…lol
Is it good or bad?
The bad side is that, it is a stressful way of life, especially at the level of salary that will come at the end.
The good side is that, when you work in such situations for say 2 years. You become a Unicorn yourself. You get to amass numerous kinds of skills that you can only imagine to have. You get to know the end-to-end of the entire data science ecosystem and therefore, as soon you see a Data Science project, you know where to start and how it will end.
NB: Most Startups these days are well funded and have defined roles and therefore, you are likely to find a Startup that will make the work easier for you.
In MNC, they know what they want and they have what it takes to hire what they want. They hire Specialist !!
They hire someone to help them solve a specific problem. For instance, Amazon will hire a Data Scientist with specialisation in say NLP(Natural Language Processing), or CV(Computer Vision) or a Data Scientist with AWS expertise but not any general Data Scientist.
MNC can hire you to work on a specific problem that demands specific set of skill, maybe for months if not years. That’s how it works. In my current position at Microsoft, I only build and validate ML models, that’s it. But the salary is 5x when I was a Jack Bauer in a Startup. However, the learning process is also half of what I was getting when I was in a Startup. In MNC, you hardly get to work in say the finance, it doesn’t really happen. There are some folks in the same company, but you will never meet even after 2 or 3 years of working in the same company and same branch. But in Startup, you will even been invited to family gatherings and naming ceremonies..lol, you will get to know the workers and their family members.
Word of Advice: it helps to gain an initial skill in a startup, then shift to an MNC
4. Skill Development(Future growth)
This really depends on your objectives. In a Startup, you will have the chance to taste every skill of the entire data science ecosystem. You will learn different tools, you will handle different business problems, work with different kinds of people, data and other things you have not even thought of. This builds you up to face any future situation as a Data Scientist.
In MNC, you will have the advantage to specialise in one thing and become a master at it.You will have the opportunity to work on a problem statement that will bring a big shift in the society. You master what you work on in an MNC and they create the environment in every way possible for you to become a specialist in what you do.
5. Risk
In a Startup, whether you will have a pay increase, or your job will be available in the next 6 months depends in whether the company will be able to survive up to that point. The vision and mission of the CEO in a Startup plays an important role in the stability of your career in a Startup. The CEO can mess-up things for you or create an amazing life for you. Salaries depend heavily on ROI (return on investment). If the company progresses, you progress (if you don’t have a greedy CEO). If the company suffers any hardship, you are likely to experience pay cut (especially if the company is not having enough funding) or at worst, lost of job.
In an MNC, you are likely to experience a more stable employment. You can face hardships such as cut in salary or even lost of job but that is very very rare.
I hope by now you have a clearer picture of the two scenarios.
So what is the Final say?
Startup is good for anyone who wants to gain an experience, especially beginners. If you want to join an MNC, it is very helpful to start from a Startup and then use your experience to grab an MNC position.
For students who want to enter MNC straight from college, it is important to keep their eye on internships that are offered by these MNC, most of which you will find on the companies website.
For experienced professionals aiming to work in MNC, it is paramount to consider your area that you have your best knowledge and use that to your advantage. Do not focus on so many skills but get down to one or two and master it back to back. You are the one MNCs are looking for.
If you want to quickly start your career and get a solid background in data science and Machine Learning, then I personally recommend the following courses:
Data Labeling — How a Human-Powered Data Labeling Platform Accelerates AI industry’s Development During COVID-19
The covid-19 epidemic in 2019 disturbs routine life across the globe. Due to the limitation of physical conditions, traditional enterprises are enhancing their strategies for digital transformation and business automation.
Data Labeling is a Simple but Difficult Task
Labeled data is the core of the AI/ML industry. The quality and quantity of data determine the performance of the AI model.
It is showed that an in-house experienced team composed of 10 labelers and 3 QA inspectors is able to complete around 10,000 automatic driving lane image labeling in 8 days.
In fact, training a model needs tens of thousands or even millions of no bias data samples, which takes a lot of time.
During the hard period, some data labeling companies were forced to switch to a work-from-home model, which has posed challenges in terms of communication, data quality, and inspection.
For example, Google Cloud has officially announced that its data labeling services are limited or unavailable until further notice. Users can only request data labeling tasks through email but cannot start new data labeling tasks through the Cloud Console, Google Cloud SDK, or the API.
Insiders say that data labeling is a simple but difficult task. On one hand, once the labeling standard is set, data labelers just need to follow the principles and rules. On the other hand, if the training data has a bias, the algorithm model cannot be well developed, AI company needs to restart the data labeling process again. Timing is important, once the company is behind the schedule, the product may be overtaken by competitors.
A majority of AI organizations said the process of training AI has been more difficult than expected, according to a report released by Alegion. data at scale and quality issues become their main obstacles in AI system R&D.
Big Data Jobs
A Human-Powered Data Labeling Platform Aims To Transform the Industry
“We want to create an automated data labeling platform that helps AI/ML companies to accelerate their data project and generate high-quality data,” said Brian Cheong, CEO, and founder of Bytebridge.
Accuracy and Efficiency
Dealing with complex tasks, the task is automatically transformed into tiny component to make the quality as high as possible/maximize the quality level as well as maintain consistency.
The real-time QA and QC are integrated into the labeling workflow as the consensus mechanism is introduced to ensure accuracy.
Consensus — Assign the same task to several workers, and the correct answer is the one that comes back from the majority output.
All work results are completely screened and inspected by the machine and human workforce.
Individually decide when to start your projects and get your results back instantly
The client can set labeling rules directly on the dashboard.
Clients can iterate data features, attributes, and workflow, scale up or down, make changes based on what they are learning about the model’s performance in each step of test and validation
ByteBridge: a Human-powered Data Labeling SAAS Platform
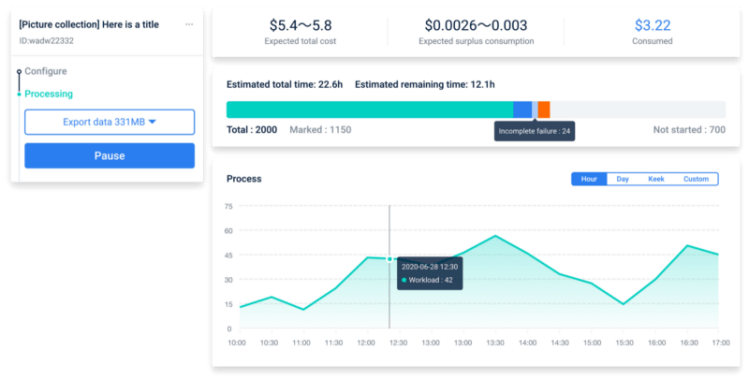
Progress preview: clients can monitor the labeling progress in real-time on the dashboard
Result preview: clients can get the results in real-time on the dashboard
ByteBridge: a Human-powered Data Labeling SAAS Platform
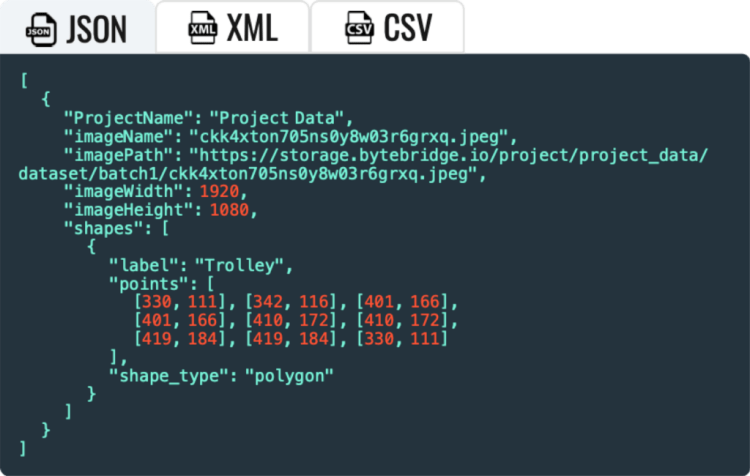
Real-time Outputs: clients can get real-time output results through API. We support JSON, XML, CSV, etc. and we can provide customizable datatype to meet your needs
ByteBridge: a Human-powered Data Labeling SAAS Platform
End
ByteBridge, a human-powered data labeling tooling platform with real-time workflow management, providing flexible data training service for the machine learning industry.
Establishing an expectation for trust around AI technologies may soon become one of the most important skills provided by Data Scientists. Significant research investments are underway in this area, and new tools are being developed, such as Shapash, an open-source Python library that helps Data Scientists make machine learning models more transparent and understandable.