What is the right approach to earning your stripes and calling yourself a successful data scientist?
Originally from KDnuggets https://ift.tt/3hj2Zzr

365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Originally from KDnuggets https://ift.tt/3hj2Zzr
Uber Artificial Intelligence & Machine Learning
Continue reading on Becoming Human: Artificial Intelligence Magazine »
Via https://becominghuman.ai/uber-michelangelo-8c8e30f2f65c?source=rss—-5e5bef33608a—4
source https://365datascience.weebly.com/the-best-data-science-blog-2020/uber-michelangelo
In this OpenCV C++ tutorial article, we will learn how to calculate approximately the surface area of a random shape using various aspects of Computer Vision with OpenCV.
OpenCV is a set of libraries that can empower the software we are using or making today. Learning OpenCV is one of a good asset to the developer to improve aspects of coding and also helps in building a software development career.
Requirements
For a better understanding of this tutorial, you will need to know the basics of C++, have an idea about OpenCV and how it works and enjoy programming ?, but it’s fine because I will provide you with a complete code ready to run.
Before we dive in, you can have a read about :
Introduction to OpenCV ( this link uses OpenCV for Python, but it provides a very good information about how OpenCV really do it’s magic. )
https://medium.com/edureka/python-opencv-tutorial-5549bd4940e3
Setup OpenCV C++ with VSCode ( yes, it’s one of the best source code editor)
https://medium.com/analytics-vidhya/vs-code-with-opencv-c-on-windows-10-explained-256418442c52
Before we begin, the idea behind this project was to automate the quality assurance of some 3D printed parts. Giving vision to the computer to automate this process made us gain enormous amount of money and time and the result was actually great, not too precise, but enough for our use case.
Okay, now that we introduced the use case, how will we achieve this ?
We will use a reference object that we know it’s surface area in advance, proportion it on the target object, and we will have the wanted surface area. Easy, right ?
This looks waaaay too simple. Let’s dive into a more detailed explanation.

So the reference object will be our “marker” which will be extracted in the first place. Using OpenCV’s tools, we will count the number of pixels that covered the marker and use them to estimate the surface using the pixel area that drew the target object.
Some key factors could change the overall result of the surface area calculator using camera photos.
Perspective angle
Represent the position of the camera used to take a photo of the target. Normally, with a hand camera, the angle of the shot is not perpendicular which results in a slightly (or extremely) distorted image. Calculate the surface area with a distorted image will affect our result badly. This is one of the most difficult issues that we faced in order to achieve a good result without the need to firmly adjust the camera position.
There’s a tone of algorithms to fix the perspective angle of the image, this process is called perspective correction. Have a read about it here :
Homography Examples using OpenCV ( Python / C ++ )
Or here
4 Point OpenCV getPerspective Transform Example – PyImageSearch
But today we will focus on our method to achieve a result which is slightly independent of perspective angle.
In this tutorial we will go through 3 main parts :
At the end of this write-up, you will learn how to calculate the surface area of a 2D object using OpenCV.
1. Microsoft Azure Machine Learning x Udacity — Lesson 4 Notes
2. Fundamentals of AI, ML and Deep Learning for Product Managers
Basically a contour is a closed curve joining all the continuous pixels having a color or an intensity. A contour represents the shape of an object found in an image. Contour detection in OpenCV is a basic set of operations that repeats itself, but needs some tweaks depend on the use case.
Here is the pipeline that we’re going to apply to successfully detect and extract our main object from the image.

As you can see, the second image looks way better for contour detection.
For the reference object detection, we will use a library which was designed to determine camera pose specifically, but make reference object detection really simple, ArUco Markers.

An ArUco marker is a synthetic square marker composed by a wide black border and an inner binary matrix which determines its identifier.
Reminder — This marker will be printed and put next to the target, identify it and use it’s known surface to calculate the target area.
… or use this link https://chev.me/arucogen/ ?
Now that we generated a marker we will need to place it besides our target object.
To detect the reference object in our image we will use ArUco library method detectMarkers() which takes a source image, a dictionary used for generation, object corners, an array of int to stores the ArUco containing identifiers.
OpenCV does provide us with a method to calculate the non-zero pixels area of a contour called cv::contourArea(). Basically, we will determine the area of one pixel using the inverse rule of three.

Here comes the tricky part. We will have to detect our object from the image to perform area evaluation. Object recognition is a vast domain where you can use different technology to successfully recognize your target, Image classification using Deep Learning, Tagging. It will depend mostly on the use case. For this tutorial, we will keep things simple and try to recognize objects from an image using their contour. You can run some test and see if this detection method will satisfy your needs or else you will have to build your own Neural network, train a model and use it with a Machine Learning library.
Take a look at Google’s Teachable Machine
Let’s get back to work. Ok, once done with our reference object recognition, and we approximately evaluate it’s surface, we will loop through the coutours found by use OpenCV’s findContours() method and evaluate each of their surfaces.
The result printed on the input image

Through this tutorial, we’ve been able to perform image processing, object recognition and use image metadata to calculate real life area surface. As mentioned in the beginning, here is a link to the code snippet, documented, where you can copy paste it and try it. First run this snippet with GENERATE_REF true, to generate the reference object, print it, put it next to the target object and then with INPUT_FILE and GENERATE_REF false rerun the code.
In this code, I used cv::im_write and cv::putText for debugging purpose.
I think we reached a good result, but steps, calibration and enhancements can be added to the process. I encourage you to play around with the recognition parameters, thresholds and different methods of edge detection and see which works the best for your case. If you make it work, I will be happy if you share your result in the comment section below, but if you didn’t or have any trouble setting up this code for running, I will be glad to help you out.
Thanks for reading. I hope you enjoyed it and learned something new.




Surface area calculator using OpenCV was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
This post is adapted from a short introductory talk on Machine Learning which I delivered in September 2020 in an accounting hackathon https://accountinghack.sg/ held in Singapore. It provides a short example of how one can train a machine learning model and the many caveats that may come along the way.

After more than 10 years in the industry, I now teach undergraduate courses on Machine Learning and Software Engineering. During the course of the instruction, I do find that some common mistakes and trends often emerge as my students train their machine learning models. I’ll try to speak about some of these mistakes in this blog post and will do so by using a simple task on object recognition. Let’s assume we have the following task:
Build a model that differentiates between a black wallet and ball
Firstly, let’s try to determine how we can train a model that differentiates between a black wallet and a ball. Probably we will require some images of a black wallet, as well as some images of a ball. We will hence require two classes and we will train the model as below.
Notice that after we have completed training the model, we encounter our first issue. When I am not holding up any object, the model defaults to Class 1, which is that of the black wallet. Although it properly detects a ball when I hold up a soccer ball, this behavior might have unintended consequences further down the road.
To solve this issue, one solution is to add a background class. In the background class which is chosen to be added, I am seen in the image standing nonchalantly and holding nothing up. You can see the entire training process in the image below.
After the addition of this background class, we are now able to properly classify the wallet class, the ball class and the background class. However at this point, we are still far from completing the task. What may be some other issues might the model suffer from?
In the next video segment, you would note that I am holding up a significantly smaller ball for the model to test. At this stage, the model incorrectly classifies the small ball as either a wallet, or as the background. As such the model is unable to generalize. This means that when I test the model with data that we are expected to see during production, it will probably fail.
1. Microsoft Azure Machine Learning x Udacity — Lesson 4 Notes
2. Fundamentals of AI, ML and Deep Learning for Product Managers
In fact the generalization of the model is probably one of the most important steps you would need to carry out. This ensures that the data used to train the model is representative of the data that the model will be seeing after it is deployed. In the video segment below, you would notice that I added photos of me holding a smaller ball which is sent to be trained in the model.
Thereafter the model that was trained was able to identify balls of different shapes, colors and sizes.
We show below two other potential pitfalls of the model, one whereby I have switched to wearing a different colored jacket and the other where I had intentionally shown the machine an empty hand.
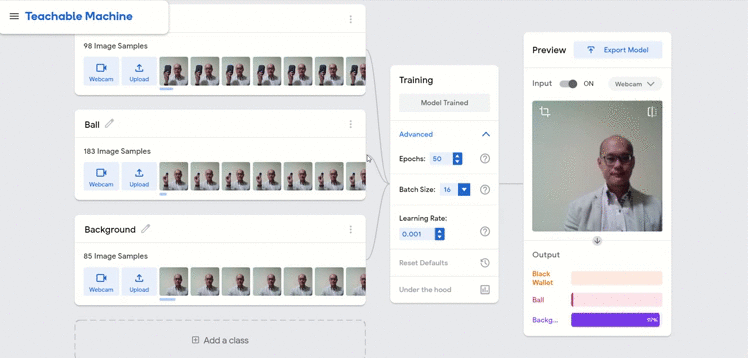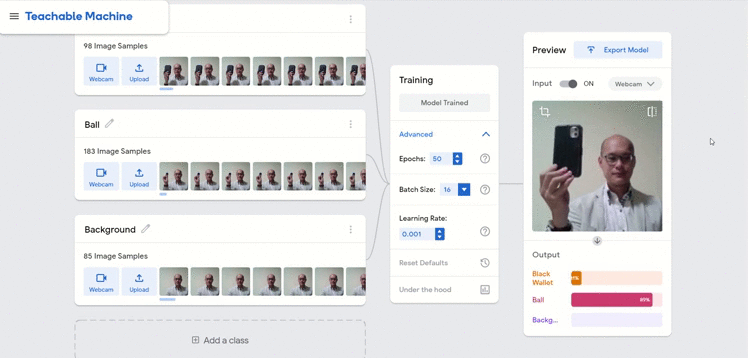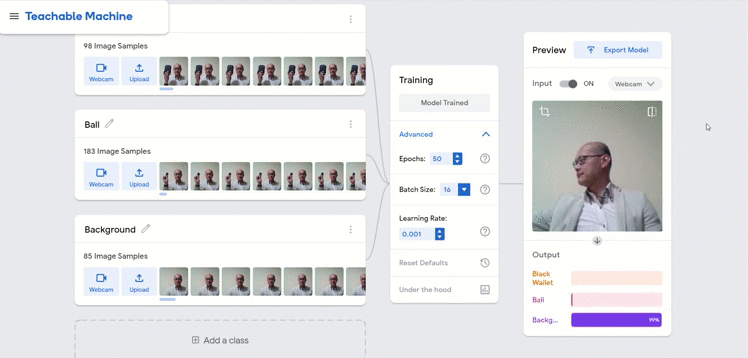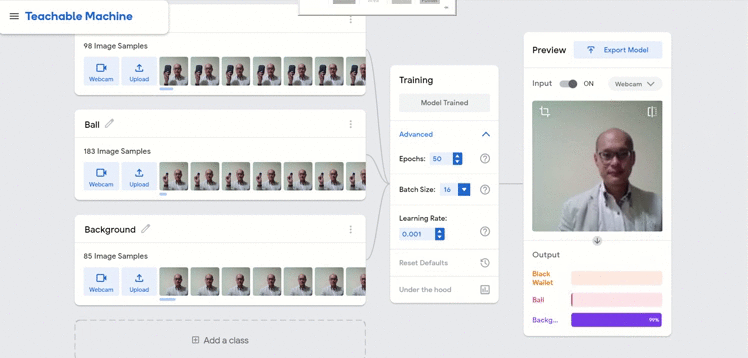
In both scenarios, the performance of the model was still acceptable but in reality, I would recommend that these different conditions be added into the training data as well.
Finally, you might consider the final bias , which is me! Recall that the original task was to be able to differentiate the photo of a black wallet and a ball. Hence the huge bias that we see in the data is myself, and I should not have been part of the machine learning model.

This simple example illustrates the issue where it is all too easy for us to introduce external influences (many times unknowingly) into the model. In the final example, notice that I used my hand to hold up the object for inference. One might still argue that the hand, or the color of my hand might be an external bias influence as well.
I hope this short post illustrates the steps one might need to take to ensure that the data used for training is sufficiently comprehensive in order to build a good model.
You can find the software demo used in this blog post at: https://teachablemachine.withgoogle.com/
How to build a good A.I. Model (Simple Pictorial Example) was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally from KDnuggets https://ift.tt/2R5wUAf
Originally from KDnuggets https://ift.tt/3hauPOf
Originally from KDnuggets https://ift.tt/2Zd8kBO
Originally from KDnuggets https://ift.tt/335buJc
Originally from KDnuggets https://ift.tt/35fxqnK
Originally from KDnuggets https://ift.tt/32YPQpK

