365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Here we look at some ways to interchangeably work with Python, PySpark and SQL using Azure Databricks, an Apache Spark-based big data analytics service designed for data science and data engineering offered by Microsoft.
Machine Learning - Handling Missing Data; The Last SQL Guide for Data Analysis You’ll Ever Need; How (not) to use #MachineLearning for time series forecasting: The sequel
Does data versioning mean what you think it means? Read this overview with use cases to see what data versioning really is, and the tools that can help you manage it.
I will be covering the basics and a generic overview of what are the basic services that you’d need to know for the certification, We will not be covering deployment in detail and a tutorial of how you might be able to use these services in this guide.
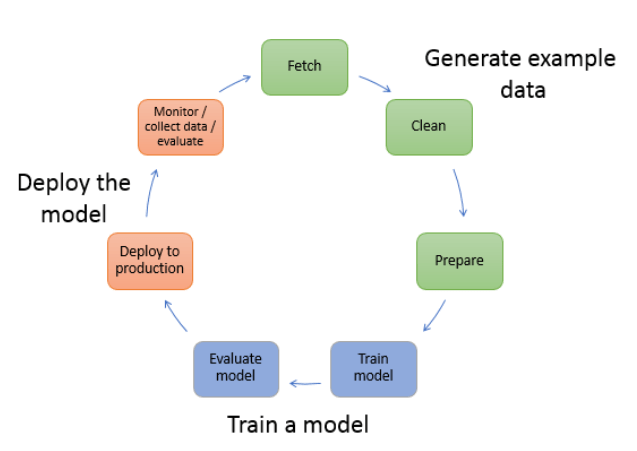
Life cycle of a Machine learning model
Now before you think about Machine Learning Specialty certification from AWS, if you haven’t done any certification from AWS before I will suggest you to complete AWS Cloud Practitioner.
Getting through the Cloud Practitioner is relatively easy and you will get perks. Perks like a free practice test of the next certification of your choice and 50 percent discount on you next certification exam.
Machine Learning Jobs
There are certain key points before you embark on your journey for the Machine Learning Specialty certification:
It is recommended that you have 1 to 2 years of experience of using AWS for ML projects and pipelines
It is recommended for people who have relative expertise over manipulating Data sets, doing EDA, extraction, tuning etc.
This exam is specifically built to weed out people who don’t have an analytics background and don’t have an in depth understanding of how Machine Learning pipelines work.
It is my personal opinion that you at least understand using shell commands, Docker containers and model deployment to fully grasp the SageMaker services and pipelines.
I will be dividing the modules into few parts and my key focus will be on the SageMaker part of the certification because that alone could get you through the examination if you are very good at it.
Understanding AWS storage
For our certification we will be sticking to S3 but it’s recommended to have a minimum idea of other storage services.
Amazon Simple Storage Service or S3 stores data as objects within buckets
You can set individual permissions(create, delete, view list of objects) for every bucket within S3
S3 has 3 different storage classes: S3 Standard — General purpose storage for any type of data, typically used for frequently accessed data, S3 Intelligent — Tiering * — Automatic cost savings for data with unknown or changing access patterns, S3 Glacier ** — For long-term backups and archives with retrieval option from 1 minute to 12 hours. S3 standard being the most expensive.
For our training purposes we can both provide them as separate channels using S3 buckets, we will get into more details later on while we go through the inbuilt algorithms.
For writing and reading data using S3 you need to use boto3 framework which is preinstalled on the sagemaker note book instances.
Jupyter notebooks: You could launch a jupyter notebook directly from an EC2 instance but you’re responsible for the following things:
Creating the AMI(Amazon machine image, in short the OS)
Launching those instances with this AMI.
Configuring the autoscaling options depending on the task.
However, it’s very straight forward, you just need the ssh key pair work and add the device IP from which you are connected to the security group of the EC2 instance you are trying to connect. If you use this service you will have to take care of the Container registry, the endpoints, distribution of Training jobs and the tuning as well. The major advantage of using Sagemaker is that it manages all these things for you.
Let’s drive straight into AWS Sagemaker, we will cover some key concepts in depth as we try to understand the various components.
Sagemaker is a fully managed service by AWS to build, train and deploy machine Learning models at scale.
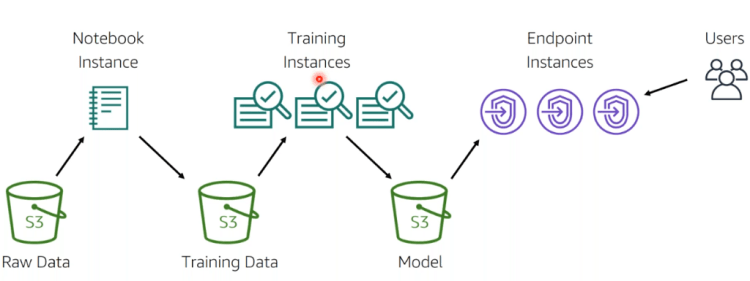
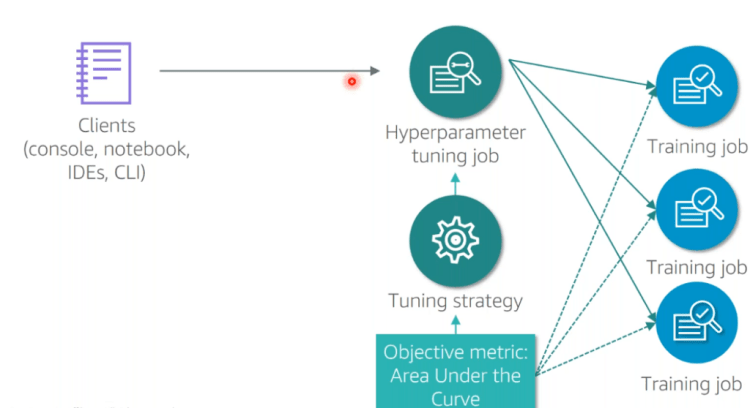
Simple Machine Learning pipeline on AWS Sagemaker
Building pipelines in Sagemaker:
You can read data from S3 in the following ways:
Directly connect to S3
Using AWS Glue to move data from Amazon RDS, Amazon DynamoDB, and Amazon Redshift into S3.
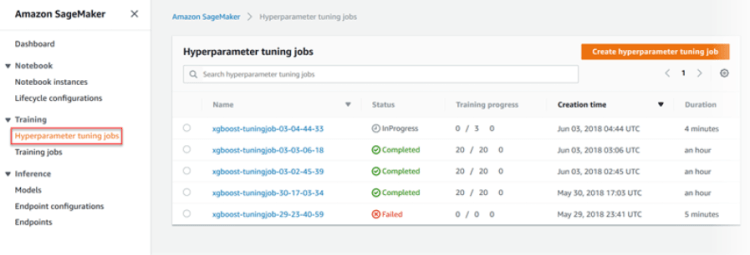
Training on AWS Sagemaker:
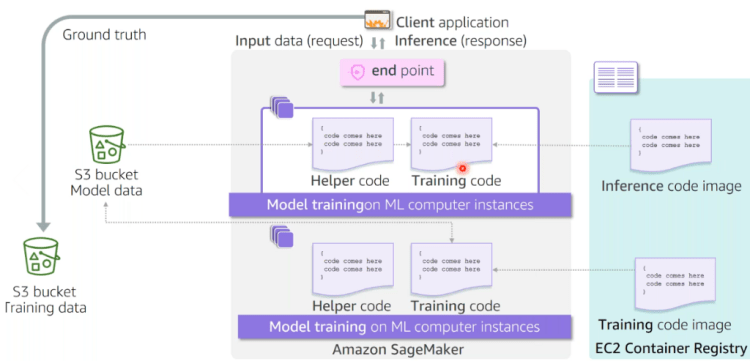
Flowchart for Training and deploying model using Sagemaker
We will be covering the inbuilt algorithms in this part.
Just as you need the ingredients to cook a dish, A Sagemaker training job needs these key components:
Training data S3 bucket URL(Remember, this must be globally unique!)
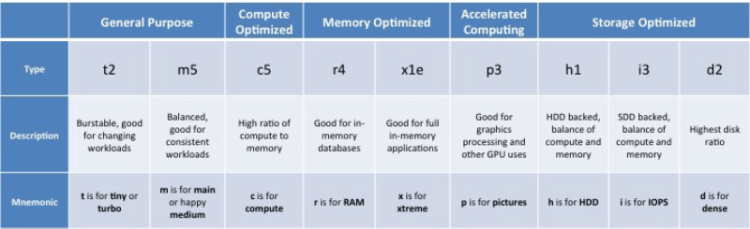
What type of ML instance do you need for this job:
ml.t2.medium — ml stands for machine learning, the next section can be defined from the following table:
Apart from these instances you also have g4dn, inf1 instances that can be used for training
eia instances can be used for only for inference.
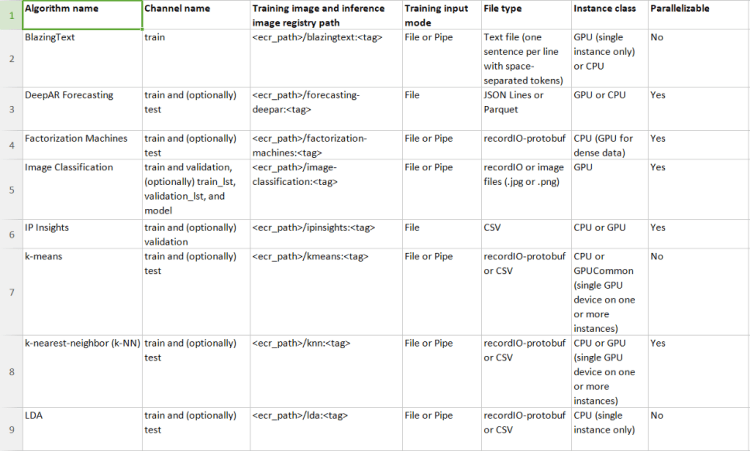
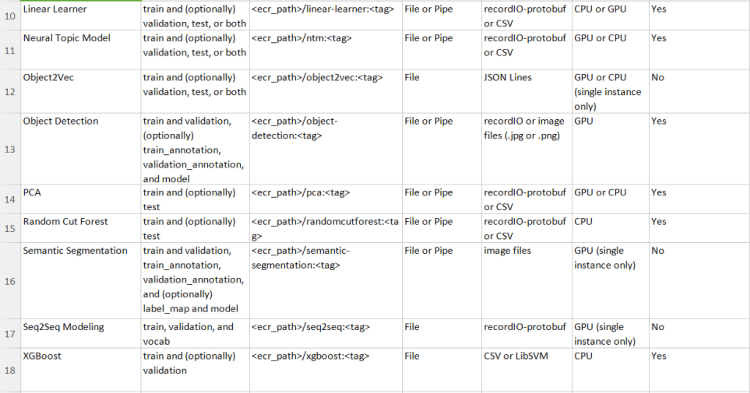
Choosing the right Training Algorithm
Once you have decided on the instance types to use for the notebook, you have the choice of following algorithms available already from AWS or use your own algorithm, we will cover that later:
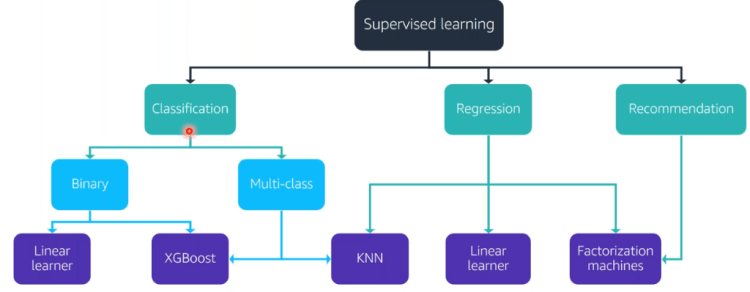
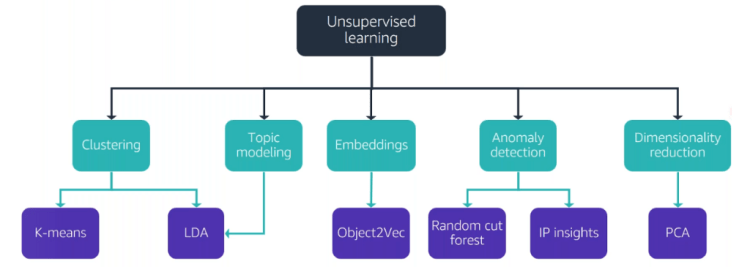
Refer these tree diagrams for an easy recall.
SuperVised Learning AWS algorithm treeUnsupervised Learning AWS algorithm treeData based AWS algorithm treeText based AWS algorithm Tree
These include the parameters that are accepted for most of these algorithms(Tip! You might want to remember them)
Transforming the Training Data
After you have launched a notebook, you need the following libraries to be imported, we’re taking the example of XGboost here:
import sagemaker import boto3 from sagemaker.predictor import csv_serializer # Converts strings for HTTP POST requests on inference
import numpy as np # For performing matrix operations and numerical processing import pandas as pd # For manipulating tabular data from time import gmtime, strftime import os
region = boto3.Session().region_name smclient = boto3.Session().client('sagemaker')
from sagemaker import get_execution_role #the IAM role that you created when you created your #notebook instance. You pass the role to the tuning job.
role = get_execution_role() print(role)
bucket = 'sagemaker-MyBucket' #replace with the name of your S3 bucket prefix = 'sagemaker/DEMO-automatic-model-tuning-xgboost-dm'
It provides full visibility into model training by monitoring, recording, analyzing, and visualizing training process tensors. Using Amazon SageMaker Debugger Python SDK we can interact with objects that will help us debug the jobs. If you are more interested in the api, you can check it out here.
After I created a model using createmodel api. Speicify S3 path where the model artifacts are stored and the Docker registry path for the image that contains the inference code.
Create an HTTPS endpoint configuration i.e: Configure the endpoint to elastically scale the deployed ML compute instances for each production variant job, for further details about the API, check CreateEndpointConfig api.
ResNet, also known as residual neural network, refers to the idea of adding residual learning to the traditional convolutional neural network, which solves the problem of gradient dispersion and accuracy degradation (training set) in deep networks, so that the network can get more and more The deeper, both the accuracy and the speed are controlled.
The problem caused by increasing depth :
The first problem brought by increasing depth is the problem of gradient explosion / dissipation . This is because as the number of layers increases, the gradient of backpropagation in the network will become unstable with continuous multiplication, and become particularly large or special. small. Among them , the problem of gradient dissipation often occurs. i.e effect of the weight decreases.
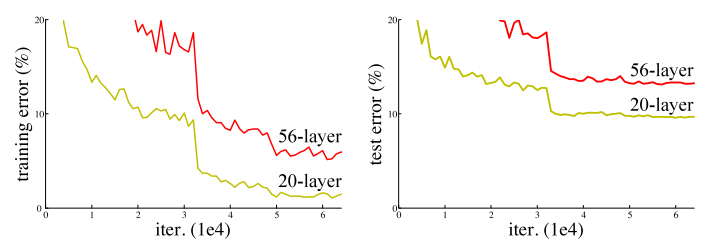
Another problem of increasing depth is the problem of network degradation, that is, as the depth increases, the performance of the network will become worse and worse, which is directly reflected in the decrease in accuracy on the training set. The residual network article solves this problem. And after this problem is solved, the depth of the network has increased by several orders of magnitude.
From above figure we can conclude that till 20th layer its ok. But if we increase the number of layers , instead of increase in accuracy it starts decreasing.Based on this problem the ResNet comes into picture.
Machine Learning Jobs
ResNet :
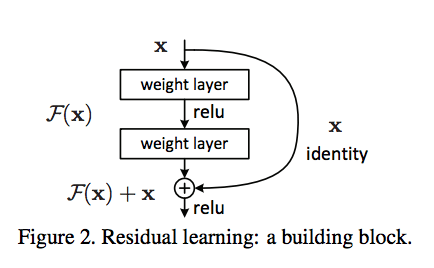
fig-2 . ResNet skipp connection diagram
The block contains two branches (i) Indentity branch that refers to own itself i.e x . (ii) F(x) referes to the network part called residual mapping .
Assume x as input .If weights over which we are training are negative just skip the input. We are passing those weights into relu activation function which not allow to pass it for further calculation.
Why we use identity blog if there is relu which chop off all negative weights ?
The main architecture contains image →convolution→ relu . For negative weights if I will able to stop is to pass in convolution layer and make unnecessary calculations and then is send to the relu , then is can be say I will able to reduce the parameters as well as calculations.
This is equivalent to reducing the amount of parameters for the same number of layers , so it can be extended to deeper models. So the author proposed ResNet with 50, 101 , and 152 layers , and not only did not have degradation problems, the error rate was greatly reduced, and the computational complexity was also kept at a very low level .
As the number of data science positions continues to grow dramatically, so does the number of data scientists in the marketplace. Follow these expert tips and examples to help make your resume and job applications stand out in an increasingly competitive field.
Despite the benefits of federated learning, there are still ways of breaching a user’s privacy, even without sharing private data. In this article, we’ll review some research papers that discuss how federated learning includes this vulnerability.
If I had to start learning Data Science again, how would I do it? Must-read NLP and Deep Learning articles for Data Scientists; These Data Science Skills will be your Superpower; Accelerated Natural Language Processing: A Free Amazon Machine Learning University Course.
Roll up your sleeves and charge up because you’re invited to an interactive, virtual Machine Learning workshop run by Amazon Web Services, Databricks, and Immuta on September 10.