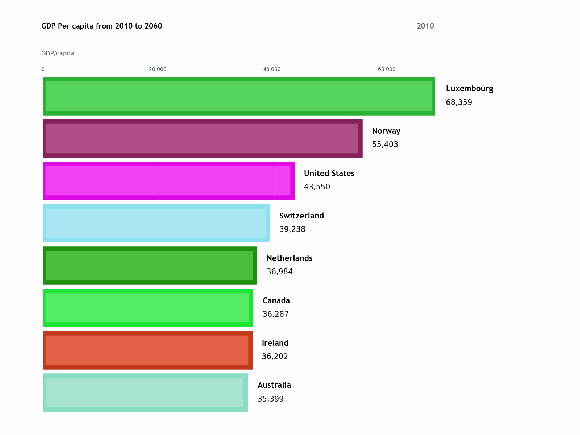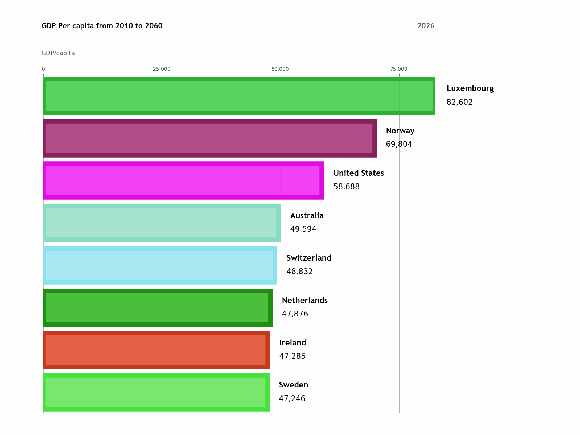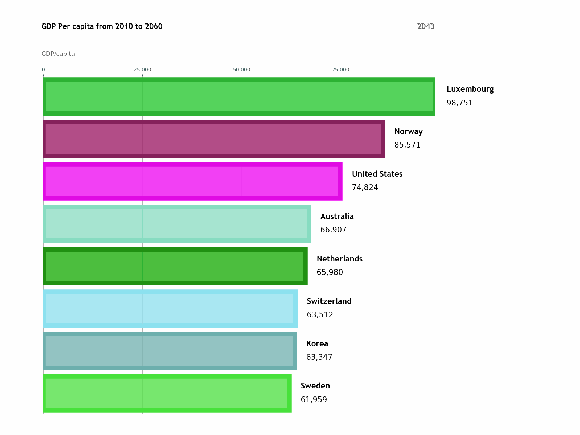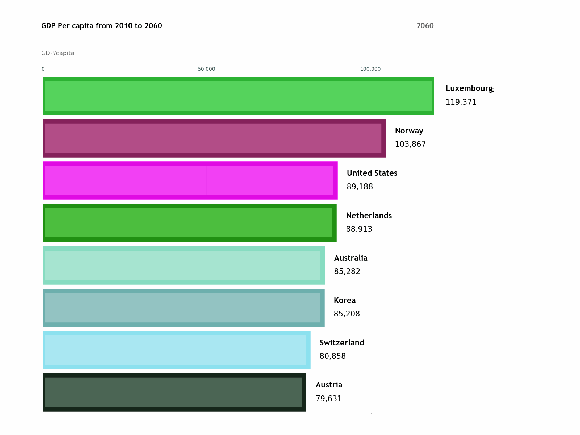
To visualize the features of different categories we use bar charts which are a very simple way of presenting the features. But when we…
Continue reading on Becoming Human: Artificial Intelligence Magazine »

365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
To visualize the features of different categories we use bar charts which are a very simple way of presenting the features. But when we…
Continue reading on Becoming Human: Artificial Intelligence Magazine »
Originally from KDnuggets https://ift.tt/31Z2ULt
source https://365datascience.weebly.com/the-best-data-science-blog-2020/how-do-neural-networks-learn
Originally from KDnuggets https://ift.tt/310c6zY
It is unarguably true that the advent of machine learning and artificial intelligence has brought a revolutionary change in various industries globally. Both these technologies have made applications and machines way smarter than our imaginations. But, have you ever wondered how AI and ML work or how they make machines act, think, and behave like human beings.
To understand this, you have to dig deeper into the technical things. It is actually the trained data sets that do the magic to create automated machines and applications. These data sets are further needed to be created and trained through a process named Data annotation.
Data annotation is the technique of labeling the data, which is present in different formats such as images, texts, and videos. Labeling the data makes objects recognizable to computer vision, which further trains the machine. In short, the process helps the machine to understand and memorize the input patterns.
To create a data set required for machine learning, different types of data annotation methods are available. The prime aim of all these types of annotations is to help a machine to recognize text, images, and videos (objects) via computer vision.
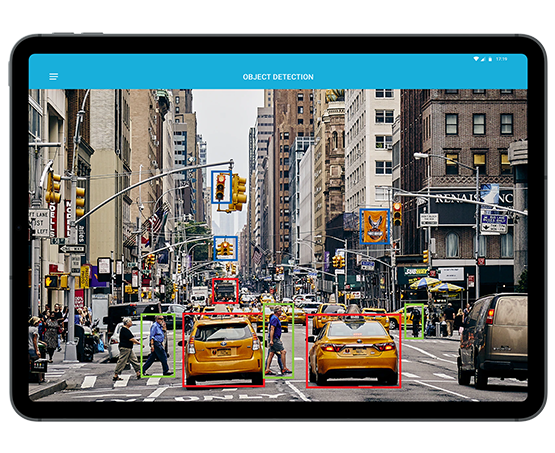

Let’s read them in detail:
The most common kind of data annotation is bounding boxes. These are the rectangular boxes used to identify the location of the object. It uses x and y-axis coordinates in both the upper-left and lower-right corners of the rectangle. The prime purpose of this type of data annotation is to detect the objects and locations.Lines and splines
This type of data annotation is created by lines and splines to detect and recognize lanes, which is required to run an autonomous vehicle.
This type of annotation finds its role in situations where environmental context is a crucial factor. It is a pixel-wise annotation that assigns every pixel of the image to a class (car, truck, road, park, pedestrian, etc.). Each pixel holds a semantic sense. Semantic segmentation is most commonly used to train models for self-driving cars.
This type of data annotation is almost like bounding boxes but it provides extra information about the depth of the object. Using 3D cuboids, a machine learning algorithm can be trained to provide a 3D representation of the image.
The image can further help in distinguishing the vital features (such as volume and position) in a 3D environment. For instance- 3D cuboids help driverless cars to utilize the depth information to find out the distance of objects from the vehicle.
1. Machine Learning Concepts Every Data Scientist Should Know
3. AI Fail: To Popularize and Scale Chatbots, We Need Better Data
Polygonal segmentation is used to identify complex polygons to determine the shape and location of the object with the utmost accuracy. This is also one of the common types of data annotations.
These two annotations are used to create dots across the image to identify the object and its shape. Landmark and key-point annotations play their role in facial recognitions, identifying body parts, postures, and facial expressions.
Entity annotation is used for labeling unstructured sentences with the relevant information understandable by a machine. It can be further categorized into named entity recognition and intent extraction.
Data annotation offers innumerable advantages to machine learning algorithms that are responsible for training predicting data. Here are some of the advantages of this process:
Enhanced user experience
Applications powered by ML-based trained models help in delivering a better experience to end-users. AI-based chatbots and virtual assistants are a perfect example of it. The technique makes these chatbots to provide the most relevant information in response to a user’s query.
Improved precision
Image annotations increase the accuracy of output by training the algorithm with huge data sets. Leveraging these data sets, the algo will learn various kinds of factors that will further assist the model to look for the suitable information in the database.
The most common annotation formats include:
By now, you must be aware of the different types of data annotations. Let’s check out the applications of the same in machine learning:
Check out below some of the common tools used for annotating images:
In this article, we have mentioned what data annotation or labeling is, and what are its types and benefits. Besides this, we have also listed the top tools used for labeling images. The process of labeling texts, images, and other objects help ML-based algorithms to improve the accuracy of the output and offer an ultimate user experience.
A reliable and experienced machine learning company holds expertise on how to utilize these data annotations for serving the purpose an ML algorithm is being designed for. You can contact such a company or hire ML developers to develop an ML-based application for your startup or enterprise.




What is Data Annotation- Types, Tools, Benefits, and Applications in Machine Learning was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.

Reusable helper function to pre-process text data. Text data frame(pandas) to be passed as a parameter to the helper function
Continue reading on Becoming Human: Artificial Intelligence Magazine »
Originally from KDnuggets https://ift.tt/2POMNKS

Applying an important lesson from Dr. Ruha Benjamin’s book, “Race After Technology” — there may be a difficult truth beneath the glitch.
Continue reading on Becoming Human: Artificial Intelligence Magazine »
Several types of industries are executing projects based on artificial intelligence and machine learning for various applications. These applications include pattern recognition, conversational systems, predictive analytics, personalization systems, and autonomous systems. All these projects execute with the machine learning models. Building and developing a machine learning model is just like developing any product but at a high level. Machine learning training will provide you with deep knowledge and understanding of the ML domain. In this blog, we will discuss the steps to develop your machine learning model.

A Machine learning model is a mathematical depiction of real-word. You have to provide data training to build machine learning models. Since data is a fundamental concept of machine learning. So, the data layer will be at the top of the development process. So let’s dive in and understand the seven key steps of machine learning model development.
There are seven steps for the development of machine learning models. You can’t ignore these key steps of machine learning development if you wish to be certified for machine learning certification.
1. Identification of the business problem
The first step of any ML-based project is to understand the requirements of the business. You need to develop an understanding of the problem before attempting to decode it. Firstly, understand the requirements and objectives of a project. Then, reshape this knowledge into a business problem definition. After that formulate an opening plan for attaining the objectives of the project.
2. Identification of data
Once you identify the business problems the next phase is to identify data. Firstly, you have to understand how the model will work on real-world data. A machine learning model is generated by learning from train data and applying that understanding to new data. The data needs to be in good shape. This step involves data identification, initial requirements, collection, quality, and data insights. The main focus of this step is to manage the quality and quantity of data.
3. Collect and prepare the data
The collection of data starts after the identification of data. This step involves the investigation of data. In this phase, you need to shape your business data so that it further can be utilized to train your business model. The quality of data will directly impact how your business model will operate. You can use web scraping to gather information from several sources. After gathering information the next step is to prepare and visualize the data. This step involves the pre-processing of data by eliminating, normalizing, error corrections, and removal of duplicacy. The preparation of data consists of data cleansing, augmentation, normalization, aggregation, transformation, and labeling of data.
1. Machine Learning Concepts Every Data Scientist Should Know
3. AI Fail: To Popularize and Scale Chatbots, We Need Better Data
4. Choose and train your machine model
At this stage, you develop an understanding of your problem which you are trying to solve. Now your data is also in its usable shape. Now it’s time to select and train your machine model. There are many models that you can select according to your business objectives. The step of selection of models includes algorithms of prediction, classification, clustering, deep learning, linear regression, and so forth. Now you will be required to train datasets to operate smoothly. The step of training your machine model involves several algorithms and techniques. The outcome machine model can be used for evaluation to check whether it meets the operational and business requirements.
5. Evaluation
This step involves the evaluation of the machine models using a model metric approach, quality measurements, datasets, and matrix calculations. This phase is the quality assurance of a machine learning approach.
6. Experiment and adjustment of the model
After evaluation, the adjustments of the machine model comes. Now, it’s time to see how it works in the real world. This stage is also known as model operationalizing. It includes the deployment and monitoring of the ML model.
7. Interference or Prediction
Now, it’s time to utilize machine learning models in real-life scenarios.
Once you get a direction and blueprint of your ML model then you can test the prototype of your solution. You should continuously look for advancements and improvements to attain success in the machine learning development model.
If you are a beginner and want to explore machine learning for beginners, then you can check out our website Global Tech Council.
The 7 Key Steps To Build Your Machine Learning Model was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Building a machine learning model or training a machine learning algorithm is a long process. You can’t just train a model once and leave it alone, because there’s a lot more to the machine learning lifecycle — data changes, preferences evolve, and competitors will emerge.
Therefore, you should keep your model up to date when it goes into production. While you don’t have to go through the same level of training that was required when creating the model, you can’t assume that it will be self-sufficient.
Also, Read — Network Security with Machine Learning.
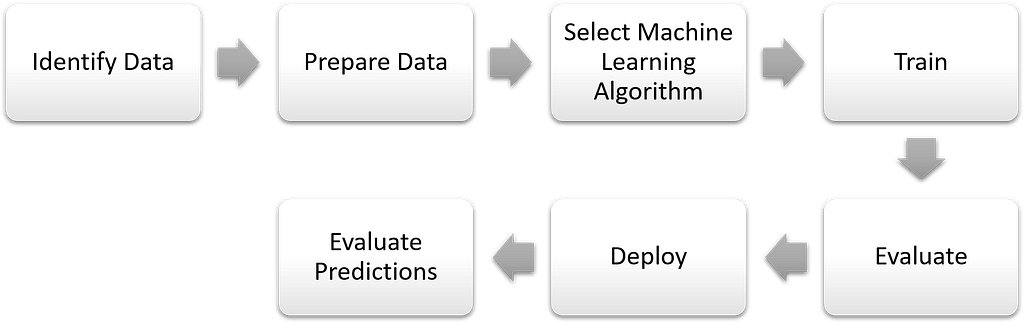
The machine learning lifecycle is continuous and choosing the right machine learning algorithm is only one step. The stages of machine learning lifecycle are as follows:
Also, Read — Sentiment Analysis with Machine Learning.
Once your model has started making predictions, start the process again by evaluating the data you are evaluating. Are all the data relevant? Are there any new datasets that could help improve forecast accuracy? By sticking to this machine learning lifecycle and continuously improving models and evaluating new approaches, you will be able to maintain the relevance of your machine learning-based applications.
1. Machine Learning Concepts Every Data Scientist Should Know
3. AI Fail: To Popularize and Scale Chatbots, We Need Better Data
Machine Learning in Finance
LSTM in Machine Learning
Translate Using Python
I hope you liked this article on Machine Learning Lifecycle. Feel free to ask your valuable questions in the comments section below. You can also follow me on Medium to learn every topic of Machine Learning.
Machine Learning Lifecycle was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Via https://becominghuman.ai/machine-learning-lifecycle-915f632b67f5?source=rss—-5e5bef33608a—4
source https://365datascience.weebly.com/the-best-data-science-blog-2020/machine-learning-lifecycle
Originally from KDnuggets https://ift.tt/3gRUUlH
