365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
With an analysis of over a thousand Data Scientist job descriptions in the USA, check out the trends for 2020 and current expectations on new positions in the field, including credentials, experience, and programming languages.
Netflix’s Polynote is a New Open Source Framework to Build Better Data Science Notebooks; Metrics to Use to Evaluate Deep Learning Object Detectors; Setting Up Your Data Science & Machine Learning Capability in Python; Which Data Science Skills are core and which are hot/emerging ones?
Natural Language Processing, or NLP for short, is broadly defined as the automatic manipulation of natural language, like speech and text, by software.
Or in rather simple terms, we may divide the term into Natural Language and Processing.
Natural language refers to the way we, humans, communicate with each other.
Namely, speech and text.
We are surrounded by text.
ML Jobs
Think about how much text you see each day:
Signs
Menus
Email
SMS
Web Pages
and so much more…
The list is endless.
And Processing, well in layman terms, one might consider that it refers to operate on the given natural language to understand, interpret, change or express it in the same or a different form.
NLP is important in computer applications because it is a go to approach for making the algorithms ‘understand’ the context behind sentences.
As Yoav Goldberg said in his book, Neural Network Methods in Natural Language Processing:-
Natural language processing (NLP) is a collective term referring to automatic computational processing of human languages. This includes both algorithms that take human-produced text as input, and algorithms that produce natural looking text as outputs.
NLP is important in computer applications because it is a go to approach for making the algorithms ‘understand’ the context behind sentences.
Where is NLP around us?
We use the term natural language processing (NLP) to refer to the field that aims to enable computers to parse human language as humans do. NLP is not a single technique; rather, it is composed of many techniques grouped together by this common aim. Two examples of NLP at an individual level are International Business Machine’s Watson™ and Apple’s Siri®. For example, Watson used NLP to convert each question on Jeopardy! into a series of queries that it could ask its databases simultaneously. Siri uses NLP to translate speech into commands to navigate the iPhone® or search the Internet.
Other examples could be chatbots that we encounter in websites. They use APIs that are programmed to ‘understand’ the context of any particular query and answer accordingly.
Chatbots and virtual assistants are perhaps the two modes where we come in contact with NLP on a regular basis
Where does NLP fit in anyway in the Healthcare industry?
The healthcare industry is fast realizing the importance of data, collecting information from EHRs(Electronic Health Records), sensors, and other sources. However, the struggle to make sense of the data collected in the process might rage on for years. Since the healthcare system has started adopting cutting-edge technologies, there is a vast amount of data collected in silos. Healthcare organizations want to digitize processes, but not unnecessarily disrupt established clinical workflows. Therefore, we now have as much as 80 percent of data unstructured and of poor quality. This brings us to a pertinent challenge of data extraction and utilization in the healthcare space through NLP in Healthcare.
This data as it is today, and given the amount of time and effort it would need for humans to read and reformat it, is unusable. Thus, we cannot yet make effective decisions in healthcare through analytics because of the form our data is in. Therefore, there is a higher need to leverage this unstructured data as we shift from fee-for-service healthcare model to value-based care.
This is where Natural Language Processing, NLP comes in. NLP based chatbots, already possess the capabilities of well and truly mimicking human behavior and executing a myriad of tasks. When it comes to implementing the same on a much larger use case, like a hospital — it can be used to parse information and extract critical strings of data, thereby offering an opportunity for us to leverage unstructured data.
NLP approaches in the healthcare industry
Driving Factors behind NLP in Healthcare.
Handle the Surge in Clinical Data
The increased use of patient health record systems and the digital transformation of medicine has led to a spike in the volume of data available with healthcare organizations. The need to make sense out of this data and draw credible insights happens to be a major driver.
Making sense out of the excessive digital data is perhaps the biggest challenge for the healthcare industry
Support Value-Based Care and Population Health Management
The shift in business models and outcome expectations is driving the need for better use of unstructured data. Traditional health information systems have been focusing on deriving value from the 20 percent of healthcare data that comes in structured formats through clinical channels.
NLP in Healthcare could solve these challenges through a number of use cases. Let’s explore a couple of them:
Improving Clinical Documentation — Electronic Health Record(EHR) solutions often have a complex structure, so that documenting data in them is a hassle. With speech-to-text dictation, data can be automatically captured at the point of care, freeing up physicians from the tedious task of documenting care delivery.
Making CAC more Efficient — Computer-assisted coding can be improved in so many ways with NLP. CAC extracts information about procedures to capture codes and maximize claims. This can truly help HCOs make the shift from fee-for-service to a value-based model, thereby improving the patient experience significantly.
Improve Patient-Provider Interactions with EHR(Electronic Health Record (EHR)
Patients in this day and age need undivided attention from their healthcare providers. This leaves doctors feeling overwhelmed and burned out as they have to offer personalized services while also managing burdensome documentation including billing services.
Already, virtual assistants such as Siri, Cortana and Alexa have made it into healthcare organizations, working as administrative aids, helping with customer service tasks and help desk responsibilities.
Soon, NLP in Healthcare might make virtual assistants cross over to the clinical side of the healthcare industry as ordering assistants or medical scribes.
EHR practices and other duties like documentation and billing that medical officers have to perform often result in overburdening them in the conventional healthcare system. Maybe automating them using NLP is the way to go.
Empower Patients with Health Literacy
With conversational AI already being a success within the healthcare space,a key use-case and benefit of implementing this technology is the ability to help patients understand their symptoms and gain more knowledge about their conditions. By becoming more aware of their health conditions, patients can make informed decisions, and keep their health on track by interacting with an intelligent chatbot.
Natural Language Processing in healthcare could boost patients’ understanding of EHR portals, opening up opportunities to make them more aware of their health.
Address the Need for Higher Quality of Healthcare
NLP can be the front-runner in assessing and improving the quality of healthcare by measuring physician performance and identifying gaps in care delivery.
Research has shown that artificial intelligence in healthcare can ease the process of physician assessment and automate patient diagnosis, reducing the time and human effort needed in carrying out routine tasks such as patient diagnosis. NLP in healthcare can also identify and mitigate potential errors in care delivery.
Identify Patients who Need Improved Care
Machine Learning and NLP tools have the capabilities needed to detect patients with complex health conditions who have a history of mental health or substance abuse and need improved care. Factors such as food insecurity and housing instability can deter the treatment protocols, thereby compelling these patients to incur more cost in their lifetime.
Since the healthcare industry generates both structured and unstructured data, it is crucial for healthcare organizations to refine both before implementing NLP in healthcare.
NLP can benefit the healthcare industry on two fronts. It may help medical businesses with administration using chatbots, and/or automating some of the works like billing and documentation which is till now manual in the conventional healthcare system. Also it may give its value in strictly medical areas where it may make it for consumers to make better decisions and help doctors understand the ailments of their patients better.
Some specific uses for NLP in Healthcare.
Summarizing lengthy blocks of narrative text, such as a clinical note or academic journal by identifying key concepts or phrases present in the source material.
Mapping data elements present in unstructured text to structured fields in an electronic health record in order to improve clinical data integrity.
Converting data in the other direction from machine-readable formats into natural language for reporting and educational purposes.
Answering unique free-text queries that require the synthesis of multiple data sources.
Engaging in optical character recognition to turn images, like PDF documents or scans of care summaries and imaging reports, into text files that can then be parsed and analyzed.
Conducting speech recognition to allow users to dictate clinical notes or other information that can then be turned into text.
A case study from McKinsey illustrating how they make use of NLP techniques for improving their accuracy metrics.
Challenges yet? Sure sir!
It’s not an easy job for both patients and physicians to get a straight clear answers from a drug-maker.
Sources of Data for Text Mining.
Patient health records, order entries, and physician notes aren’t the only sources of data in healthcare. There are other sources as well such as:-
1. The Internet of Things (think FitBit data)
2. Electronic Medical Records/Electronic Health Records (classic)
3. Insurance Providers (claims from private and government payers)
4. Other Clinical Data (including computerized physician order entries, physician notes, medical imaging records, and more)
5. Opt-In Genome and Research Registries
6. Social Media (tweets, Facebook comments, etc.)
7. Web Knowledge (emergency care data, news feeds, and medical journals)
Just how much health data is there from these sources? More than 2,314 exabytes by 2020, says BIS Research. But adding to the ocean of healthcare data doesn’t do much if you’re not actually using it. And many may agree that utilization of this data is… underwhelming.
Improving Customer Care While Reducing Medical Information Department Costs.
Every physician knows how annoying it can be to get a drug-maker to give them a straight, clear answer. Many patients know it, too. For the rest of us, here’s how it works:
You (a physician, patient or media person) call into a biotechnology or pharmaceutical company’s Medical Information Department (MID)
Your call is routed to the MID contact center
MID operators reference all available documentation to provide an answer, or punt your question to a full clinician
Hearing How People Really Talk About and Experience, ADHD.
The human brain is terribly complicated, and two people may experience the same condition in vastly different ways. This is especially true of conditions like Attention Deficit Hyperactivity Disorder (ADHD). In order to optimize treatment, physicians need to understand exactly how their individual patients experience it. But people often tell their doctor one thing, and then turn around and tell their friends and family something else entirely. Adevanced text analytics using NLP techniques are surely helping healthcare providers connect with their patients and develop personalized treatment plans.
Notice the difference between a toy car and a paper airplane? That could be an illustration of difference that patients with ADHD show which makes it difficult for physicians to understand the root of their problems.
Guiding Communications Between Pharmaceutical Companies and Patients.
Pharmaceutical marketing teams face countless challenges. These include growing market share, demonstrating product value, increasing patient adherence and improving buy-in from healthcare professionals. Previously, companies relied on basic customer surveys and some other quantitative data sources to create their recommendations. Now with the aid of NLP, companies are trying to categorize large quantities of qualitative, unstructured patient comments into “thematic maps.”
Broad classification of some top current NLP techniques in health care.
1. Mainstay NLP healthcare use cases, or those with a proven return on investment:
Speech recognition
Clinical documentation improvement
Data mining research
Computer-assisted coding
Automated registry reporting
2. Emerging NLP healthcare use cases, or those that will likely have immediate impact:
Clinical trial matching
Prior authorization
Clinical decision support
Risk adjustment and hierarchical condition categories
3. Next-generation NLP healthcare use cases, or those that are on the horizon:
Ambient virtual scribe
Computational phenotyping and biomarker discovery
Population surveillance
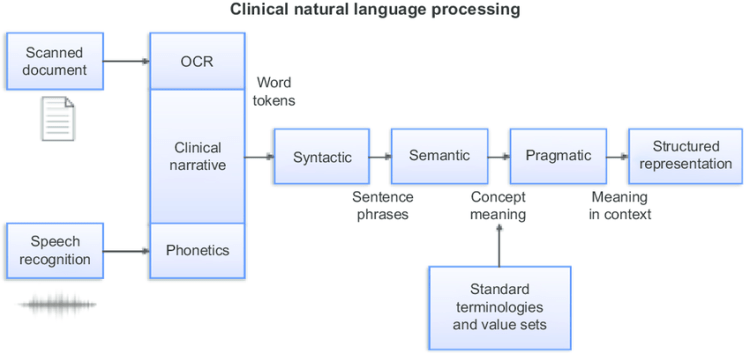
Clinical NLP?
Clinical NLP is a specialization of NLP that allows computers to understand the rich meaning that lies behind a doctor’s written analysis of a patient.
Normal NLP engines use large corpora of text, usually books or other written documents, to determine how language is structured and how grammar is formed. Taking models that were learned from this kind of writing and trying to apply it as a clinical NLP solution won’t work.
A typical example of Clinical NLP
Clinical NLP requirements:-
There are several requirements that you should expect any clinical NLP system to have:
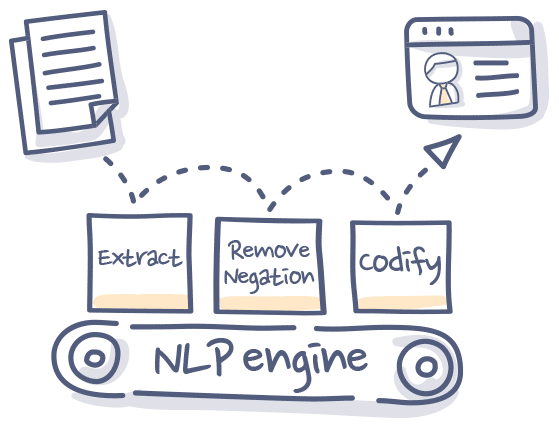
Entity extraction: to surface relevant clinical concepts from unstructured data.
Contextualization: to decipher the doctor’s meaning when they mention a concept. For example, when doctors deny a patient has a condition or talk about a patient’s history.
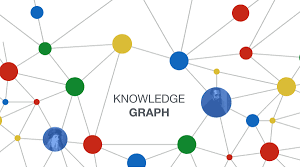
Knowledge graph: to understand how clinical concepts are interrelated, like the fact that both fentanyl and hydrocodone are opiates.
Entity Extraction
Doctors don’t write about patients like you would write a book. Clinical NLP engines need to be able to understand the shorthand, acronyms, and jargon that are medicine-specific. Different words and phrases can have exactly the same meaning in medicine, for example dyspnea, SOB, breathless, breathlessness, and shortness of breath all have the same meaning.
Contextualization
The context of what a doctor is writing about is also very important for a clinical NLP system to understand. Up to 50% of the mention of conditions and symptoms in doctor’s writing are actually instances where they are ruling out that condition or symptom for a patient. When a doctor says “the patient is negative for diabetes” your clinical NLP system has to know that the patient does not have diabetes.
Knowledge Graph
A knowledge graph encodes entities, also called concepts, and their relationship to one another. All of these relationships create a web of data that can be used in computing applications to help them “think” about medicine similarly to how a human might. Lexigram’s Knowledge Graph powers all of our software and is also available directly via our APIs.
Knowledge graph aka The web of data
Conclusion
NLP software for healthcare should center around data conclusions that have the least noise, and the strongest signal about what healthcare providers need to do.
Healthcare natural language processing offers the chance for computers to do the things that computers need to do. To do the analytics, the HCC risk adjustment coding, the back office functions, and the patient set analysis, all without obstructing physician communication.
NLP in healthcare is creating new and exciting opportunities for healthcare delivery and patient experience. It won’t be long before specialized NLP coding recognition enables physicians to spend more time with patients, while helping make insightful conclusions based on precise data. In the years to come, we’ll hear the news, and see the possibilities of this technology, as it empowers providers to positively influence health outcomes.
So, that was my take on how NLP is involved in the healthcare industry. Please free to contact for any further details/queries.
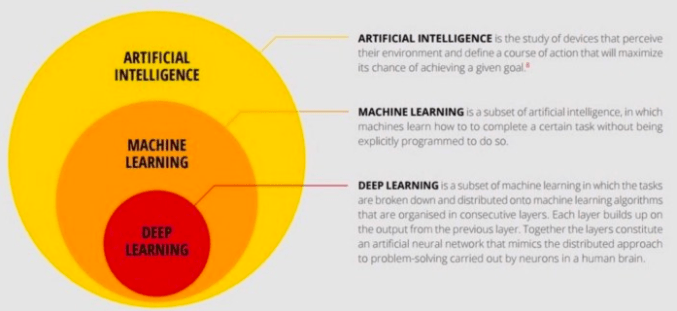
Fundamentals of AI, ML and Deep Learning for Product Managers
As promised in the previous post, we are going to describe in detail the powerful AI/ Machine-learning algorithms driving innovation at companies such as Quora, Uber, Netflix, Amazon among others.
Before that, we need to learn some basics.
This post covers those fundamental building blocks of AI.
Source: Survey CTO
What is AI?
Simply put AI is used to describe machines that mimic human-level intelligence while performing cognitive functions such as learning and Problem solving.
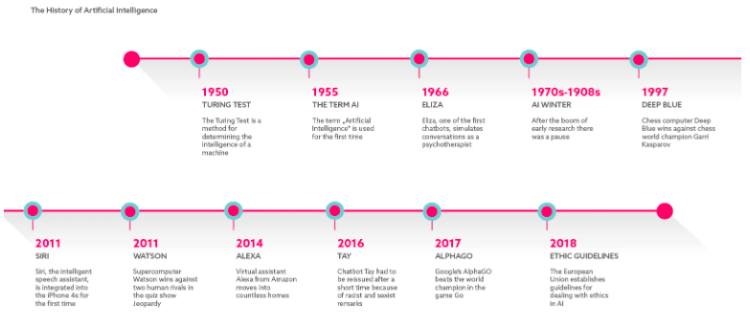
History of AI
The term is further categorised into two: “Strong AI”- the pop-culture description of AI where self-sustaining machines can perform (and even outperform) humans in cognitive functions in varied and novel tasks. This is the long-term goal, computer scientists want to achieve, which has kept visionaries like Elon Musk worried for the future.
Elon Musk on AI
This is to differentiate from “Narrow AI,’ which refers to systems designed for one specific task. All current AI tools are Narrow AI. These systems such as Alpha Go (which beat the Chinese Go master in 2017) can outperform humans, but on very narrow tasks, such as the complex game Go here.
ML Jobs
Also,Most AI systems currently available are essentially prediction tools. They help predict outcome given a certain input. The AI model takes in data and uses it to generate relevant information of past, present and future. For example: Classifying credit card transaction as fraudulent, identifying abnormalities on X-rays and MRIs or recommending what you would buy or watch or listen to in future.
Finally, AI is considered valuable because they can often produce better, faster, and cheaper predictions than humans can. Infact, now it can create its own AI software, more efficiently than human engineer can.
And How it works? Welcome Machine Learning
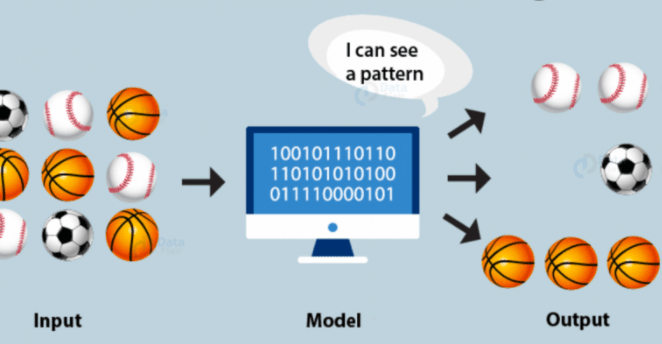
Most of the today’s powerful AI systems are powered by Machine Learning algorithms. ML is the field derived from Data Science and Computer Science which enables computers to learn and perform tasks without being explicitly programmed for every decision-rule.
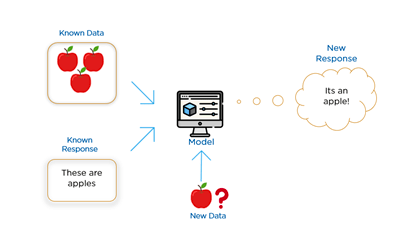
Simply put, Every ML model utilizes three types of data:
(1) training data for training the AI
(2) input data which performs real-time predictions
(3) feedback data for improving the prediction accuracy of AI.
For example, abnormality detection medical imaging AI is first trained on well-classified images of lungs categorised as having/not-having lung cancer. Once the machine learns the difference between healthy lungs and cancer-ridden lungs, the system then is put into production to predict whether an unclassified lung has cancer or not. This information is then verified by the doctor and AI then gets back feedback whether it performed the prediction accurately or not. If not, it tweaks its own set of classification rules.
Once you start reading on AI/ML, you will get confused by varied terms: Natural Language Processing (NLP), Neural Networks, Deep Learning (DL) and so on. While the demarcations is still not very clear, all these are a sub-field of Machine Learning.
The different faces of AI
But First, lets first talk about broad categories of ML:-
Supervised Learning: In this, the system is provided with clearly labelled data pairs of A-B. The ML model is then trained on this data so that it can establish causal relationship between A and B. Once perfected, the system can then predict A given B or vice-versa. It is commonly used for classification problems. One everyday application of SL is whether to classify an incoming email as spam or not spam.
Supervised Learning
2. Unsupervised Learning: As the name suggests- Here, the computer is given unlabelled data and then asked to self-identify inherent patterns and relationships, unlike SL were the training data is human-labelled in advance. It is useful because in many cases, obtaining labeled data is often difficult, costly, and/or time-consuming.
Its major application is Clustering. Cluster analysis is the process of grouping data in different segments based on similarities identified by ML model. A well-known example of clustering is in identifying fake news. The ML model examines the words used in an article and then clusters them which help determine which pieces are genuine and which are fake news.
Unsupervised Learning
3. Semi-Supervised Learning: In real world, most dataset contain noise, incorrect pairings, large number of un-labeled variables and a small set of well-labeled variables. Hence, Semi-supervised learning uses both labeled and un-labeled data to improve the accuracy of the learning model. Infact, most ML models in production environment use Semi-supervised technique. Common examples being recommendation systems, which group users on basis of their similar buying habits (items, music, movies) and prompt you with new suggestions.
Semi-Supervised Learning
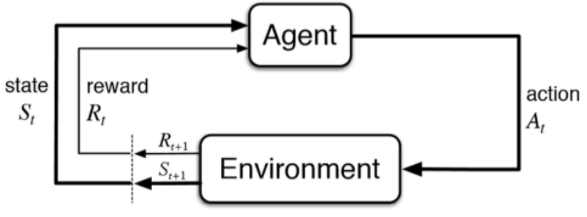
4. Reinforcement Learning: This is learning from mistakes. Here, the system uses trial and errors to achieve a well-defined goal (maximize reward) in a dynamic environment. Influenced from the field of neuroscience and psychology, this ML system is built such that it associates good behaviour with a positive rewards and bad behaviour with negative, so that we can enforce the AI model to take “good” decisions, the good being defined by the programmer.
The algorithm (agent) evaluates a current situation (state), takes an action, and receives feedback (reward) from the environment after each act.
Reinforcement Learning
Reinforcement learning is most widely used technique of Machine Learning and now mostly employs deep learning models.
A day-to-day example: News Recommendation. Unlike items and movies etc which are clearly labelled by the platform itself (Amazon, Netflix for eg.), News articles are dynamic by nature and become rapidly irrelevant. User preferences in topics change as well. Here, RL provides better accuracy than SL or USL.
News Recommendation
To understand RL better, take the case of ML-driven trading. Here, reinforcement learning models act in dynamic environment of stock market with a goal of making high profit (benchmarked against market index). The system is rewarded for every profitable trade and punished for a loss-making one. Through various trial and errors, the system learns to outperform the market and do better than human traders.
The modern day fields of Autonomous/self-driving vehicles and Robotics are powered by RL. Have you seen a Black & White movie restored in coloured format? That’s Deep Reinforcement Learning (DRL) at work for you. Infact, DRL has the capability to even generate original music.
Thats fine. But WT* is Deep Learning, Neural Networks and NLP !?
Of-course, every PM is curious to understand these hot-topics. From chatbots to Brain-computer interface, they are affecting nearly all Industries including those hitherto unaffected such as AI art gallery and drug discovery
Deep Learning is a sub-field of ML which deals with algorithms inspired by the structure and function of the brain. Hence, Artificial Neural Networks (ANN) are essentially the computing system/ architectures which help perform the act of deep learning. The neural networks are further categorised into deep neural networks, recurrent neural networks and convolution neural networks. But for our own sanity, let’s not get confused.
Deep Learning can be supervised, un-supervised or reinforced.
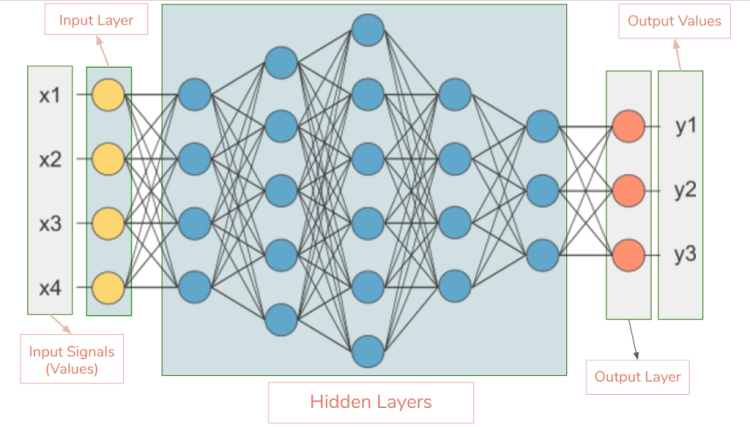
The DL models work in ANN layers. Each layer is assigned a specific portion of a task, and data might traverse the layers multiple times to refine and optimize the ultimate output. These “hidden” layers perform the algorithmic tasks that turn unlabelled, unstructured input into meaningful output.
Deep Learning: Artificial Neural Network Layers
The three layers are:-
Input layer — input data for the neural network.
Hidden layers — intermediate layer between input and output layer where all computation is performed.
Output layer — produce the result for given inputs.
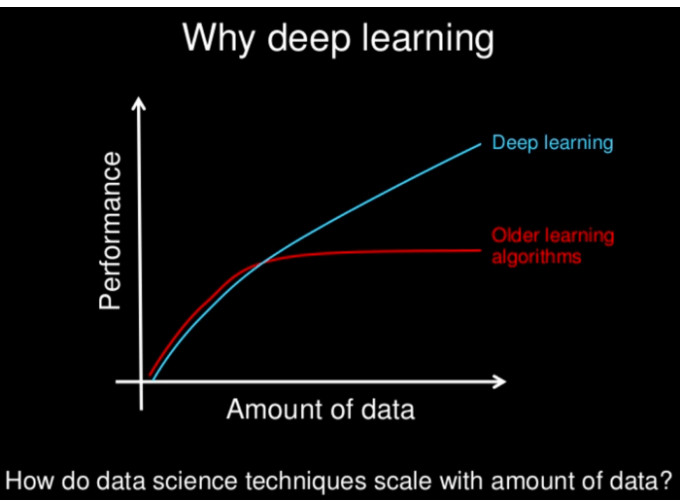
But Why Deep Learning? Simply because, DL models outperform traditional ML models in accuracy and prediction once a threshold data-input amount is reached.
Source: Andrew Ng
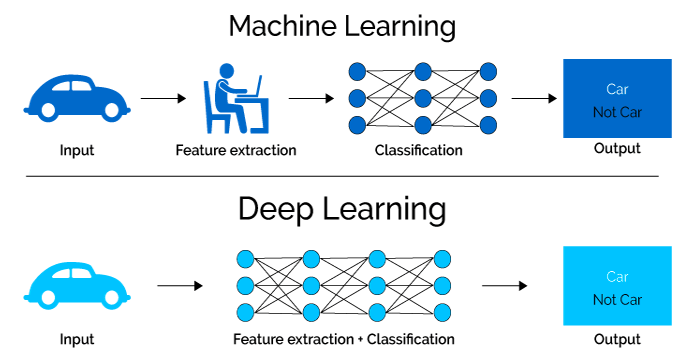
The Key Differentiator between ML and DL is the concept of feature extraction (FE), the hardest concept to teach in field of AI to a novice.
Simply put, All real-world data consists of noise or redundant features. For example a photo of car also consists of other objects such as sky, tree, road, buildings etc in the background and even foreground.
Feature Extraction
DL models reduce all set of features to determine a subset of relevant features that contain the required information, so that the desired task can be performed by using this reduced representation instead of the complete initial data. Feature extraction is done by human in machine learning whereas deep learning model figure out by itself.
While deep learning models outperform other ML techniques, there are limitations such as they require large volume of data, significant computing power and robust training of data sets.
One of the most popular usage areas of DL/NLP is voice search & voice-activated intelligent assistants. Xbox, Skype, Google Now and Apple’s Siri, are all employing DL technologies in their systems to recognize human speech and voice patterns.
Neural Networks, core component of DL, are central to NLP which helps computers to process and analyze large amount of human language data. They help improve machine translation, sentiment analysis and human retrieval. The famous example being Google Translate. They are also behind the ambitious long-term goal of chatbots– to replace humans completely and perform natural flow of human-like conversation.
Chatbots. Source: Freshdesk
Also, DL has revolutionised the field of computer vision, as DL based image recognition produce more accurate results than human contestants. It provides computer systems the ability to identify objects, places, people, writing and actions in images. The controversial example being of Face detection and surveillance.
And Predictions. DL models outperform ML in all possible kinds of predictions. From predicting earthquake to heart attack and stock prices, DL makes it possible to make quality decisions in dynamic environment.
The aim of this article was to provide a fundamental understanding of AI and the Jargon surrounding it. We intend this to be just a starting point for your long, adventurous journey in the field! Best of Luck!
If you enjoyed this post or found it helpful in any way, please feel free to applaud the article, using Medium Clap button (in left or below the post). The more you clap, farther the article reaches. To every Product Manager willing to up-skill.
Finally, in case of any questions, leave a comment.
A single source of truth provides stakeholders with a clear picture of the enterprise assets and the potential complications that can disrupt the data strategy. Find out how you can implement this single source of truth in your enterprise ecosystem.
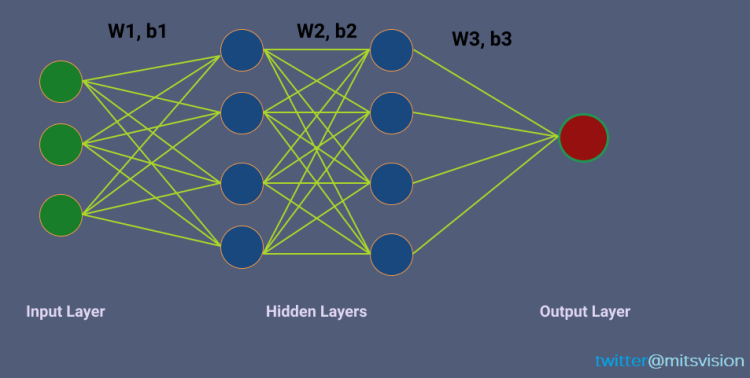
I have struggled in the past to really understand the real meaning behind the use of activation functions in the CNN architecture. I will try to make it very clear using a simple use case
Let’s take a 3 layer neural Network architecture (below figure), w1, w2, w3, b1, b2, b3 are the weight vectors and bias vectors between the layers. Assume X [x1, x2, x3] is the input to the network.
3 Layer neural network
As we know the output after a layer (neuron) is multiplication between weight and “output from the last layer” and then added bias i.e (Y = WX + b)
Let’s focus on the first row (w11,b11,w21,b21 ..)of the network.
AI Jobs
Output after neuron 1 (first neuron in row 1) and 2 (second neuron )
y1 = w11 * x1 + b11
y2 = W21 * y1+ b21 (here input is output from the last layer)
if you have deeper network then this continues. output = W * (output -1) + b
Breaking down Y2,
y2 = W21 * (W11 * x1 + b11) + b21
Y2 = (W21 * W11) * x1 + (W21 * b11) + b21
Y2 = NewConstant1 * x1 + NewConstant2
Y2 holds same linear combination with the input x1, weight (newConstant1) and bias (newConstant2) i.e W*X + b.
Even if you have very deeper network without activation functions, your networks ends-up doing nothing but simple linear classification or equivalent to one layer network.
When you add activation functions, such as Relu, Tanh, Sigmoid, ELU, They introduce non linearity inside the network which allow the network to learn/fit flexible complex polynomial behavior.
Now the formula for the Y2 becomes,
Y2 = W21 * Relu(y1) + b21
Y2 = W21 * newX + b21
If you see the Y2 now, it is no more linear combination of input x1.
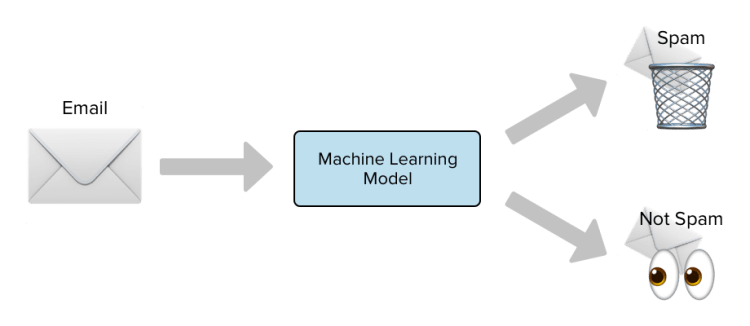
In this blog, we are going to classify emails into Spam and Anti Spam. Here I have used SVM Machine Learning Model for that.
All the source code and dataset are present in my GitHub repository. Links are available in the bottom of this blog.
So let’s understand the dataset first.
Here in the dataset, you can see there are two features.
Label — Ham or Spam
Email Text — Actual Email
So basically our model will recognize the pattern and will predict whether the mail is spam or genuine.
Algorithm used — SVM
About SVM
“Support Vector Machine” (SVM) is a supervised machine learning algorithm which can be used for both classification or regression challenges. However, it is mostly used in classification problems. In the SVM algorithm, we plot each data item as a point in n-dimensional space (where n is a number of features you have) with the value of each feature being the value of a particular coordinate. Then, we perform classification by finding the hyper-plane that differentiates the two classes very well.
AI Jobs
So, let’s jump on our coding section
Import Important Libraries
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.feature_extraction.text import CountVectorizer from sklearn.model_selection import GridSearchCV from sklearn import svm
Here we are getting around 97.66% which is a great approach. I also request to clone my repository from here and work further with this dataset and can comment me their accuracy with different classification models.
Welcome to My Week in AI! Each week this blog will have the following parts:
What I have done this week in AI
An overview of an exciting and emerging piece of AI research
Progress Update
Applying models across domains
This week I have been working on applying seq2seq models to time series forecasting. These models are typically used in NLP applications, but due to the similarity of the two tasks, they can also be used for time series forecasting. They are especially useful for multi-step forecasting.
Leveraging new resources
I have also spent time perusing Deepmind’s educational resources. They recently launched a learning resources page for people with all levels of experience in AI, from beginners to students to researchers. Some of the highlighted resources made available by Deepmind include: their podcast and Youtube channel featuring interviews and talks by AI scientists and engineers, a range of college-level lecture series and courses, and resources from global education initiatives that broaden access to AI research. In addition, they provide access to fascinating blog posts and research papers. I highly recommend browsing through the site!
AI Jobs
Emerging Research
Identifying a chemical molecule’s target proteins with deep learning
As I mentioned last week, the research I am sharing in this post involves AI in drug discovery. In ‘IVS2vec: A tool of Inverse Virtual Screening based on word2vec and deep learning techniques,’ Zhang et al. present a framework for applying the Inverse Virtual Screening (IVS) technique to chemical molecules using deep learning¹. Research has found that on average, each drug can bind to 6 target proteins — and in the early stages of drug development, it’s very useful to know what these target proteins might be. IVS is a method of identifying these target proteins.
The method presented by the authors combines Mol2vec (based on Word2vec) and a Dense Neural Network and is called IVS2vec. They described Mol2vec, which proceeds in the following manner: a chemical compound is translated into SMILES structure so that it is in the form of strings, meaning the molecule is viewed similarly to a sentence and is split into substructures or ‘words’, and then Word2vec is applied to finally encode the molecule as a 300 dimension vector.
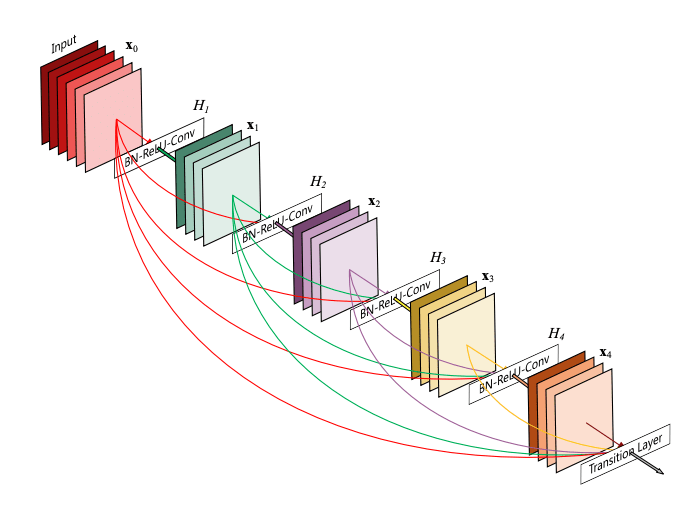
The researchers built up a dataset using Mol2vec by extracting information from the PDBbind database, encoding the molecules as described, and then matching the encoded molecules with their corresponding target proteins. This dataset was then used to train a classifier using a Dense Fully Connected Neural Network based on DenseNet². DenseNet was developed to solve the problem wherein some of the layers in many-layer networks are disused, by allowing each layer to pass its extracted information to ensuing layers. This means that each layer in the network has an aggregation of all the information that was previously extracted.
Densely Connected 5 layer block²
This framework worked very well in performing IVS on a holdout set from the PDBbind database, achieving a classification accuracy of over 91%. IVS2vec has the potential to speed up clinical trials and help researchers understand the effects and side effects of new drugs more easily. It also has applications in repurposing existing drugs for new uses, which is a much faster and less expensive process than de novo drug development.
Next week I will be presenting more of my work in AI and showcasing some cutting-edge AI research. Thanks for reading and I appreciate any comments/feedback/questions.
Finally, I have a personal update to share. It is with sadness that I am leaving Blueprint Power after this week, a company that helped me to grow, introduced me to many fantastic colleagues and taught me much about engineering and software development. At the same time, I am very excited to be starting a new role as an AI Scientist at Emergent Dynamics, where I will be applying AI to help build an intelligent drug discovery platform with the aim of increasing the rate and effectiveness of drug development.
References
[1] Zhang, H., Liao, L., Cai, Y., Hu, Y., & Wang, H. (2019). IVS2vec: A tool of Inverse Virtual Screening based on word2vec and deep learning techniques. Methods (San Diego, Calif.), 166, 57–65. https://doi.org/10.1016/j.ymeth.2019.03.012
[2] Huang, G., Liu, Z., Maaten, L. V., & Weinberger, K. Q. (2017). Densely Connected Convolutional Networks. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). doi:10.1109/cvpr.2017.243
With the job landscape in Data Science becoming hyper-competitive, there are clear strategies you can consider to find your way to snagging a position in the field.