

Natural Language Processing (NLP) is one of the oldest branches of artificial intelligence (with works starting from as early as the 1950s), which is still undergoing continuous development and commands a great deal of importance in the field of data science.
So if you want to add a new feather to your cap by learning applied NLP, you’ve come to the right spot. It doesn’t matter if you want to be a data scientist or just want to gain a new skill, this tutorial will help you get down and dirty with NLP and show you hands-on techniques on how to deal with raw data, without overwhelming you with a barrage of information.
Let us first look at how NLP came into use.
Text Mining
With the social media boom, companies have access to massive behavioral data of their customers, enabling them to use that data to fuel business processes and make informed decisions. But there’s a teeny, tiny problem.
The data is unstructured.
Raw and unstructured data is not of much use as it doesn’t give any valuable insights. Just like an uncut diamond needs to undergo polishing to reveal the flawless gem underneath, raw data need to be mined or analyzed to be of any practical use.
This is where text mining comes in. It is the process of extracting and deriving useful information, patterns, and insights from a large collection of unstructured, textual data.
This field can be divided into 4 practice areas-
- Information Extraction
- Deals with identification and extraction of relevant facts and relationships from unstructured data.
2. Document Classification and Clustering
- Aims at grouping and categorizing terms, paragraphs, docs using classification, and clustering methods.
3. Information Retrieval
- Refers to dealing with storage and retrieval of text documents.
4. Natural Language Processing (NLP)
- Different computational tasks are used to analyze and understand the underlying structure of the text data.
As you can see, NLP is an area of text mining or text analysis where the final goal is to make computers understand the unstructured text and retrieve meaningful pieces of information from it.
Top 4 Most Popular Ai Articles:
1. Natural Language Generation:
The Commercial State of the Art in 2020
4. Becoming a Data Scientist, Data Analyst, Financial Analyst and Research Analyst
Natural Language Toolkit (NLTK)
NLTK is a powerful Python package that contains several algorithms to help computer pre-process, analyze, and understand natural languages and written texts.
Common NLTK Algorithms:
- Tokenization
- Part-of-speech Tagging
- Named-entity Recognition
- Sentiment Analysis
Now, let’s download and install NLTK via terminal (Command prompt in Windows).
Note: The instructions given below are based on the assumption that you have Python and Jupyter Notebook installed. So, if you haven’t installed these, please pause here and install them before moving ahead.
- Go to the Scripts folder and copy the path

2. Open Windows command prompt and navigate to the Scripts folder
3. Enter pip3 install nltk to install NLTK
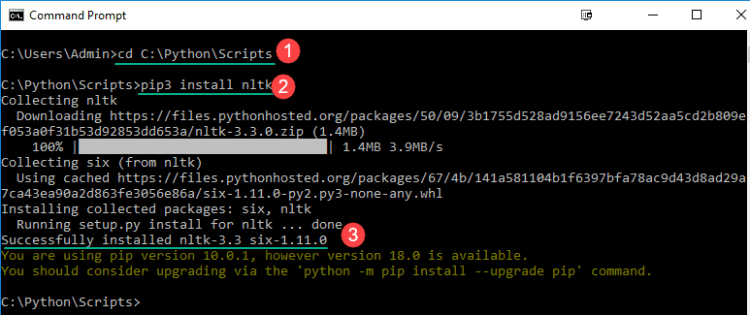
After you have successfully installed NLTK on your machine, we will explore the different modules of this package.
NLTK Corpora
A corpus (plural: corpora) is a huge collection of written texts. It is a body of written or spoken texts used for linguistic analysis and the development of NLP tools.
To download the datasets, open a Jupyter notebook and type the following code block-
import nltk
nltk.download()
A GUI will pop up, where you can click on the ‘Download’ button to download all the data packages.
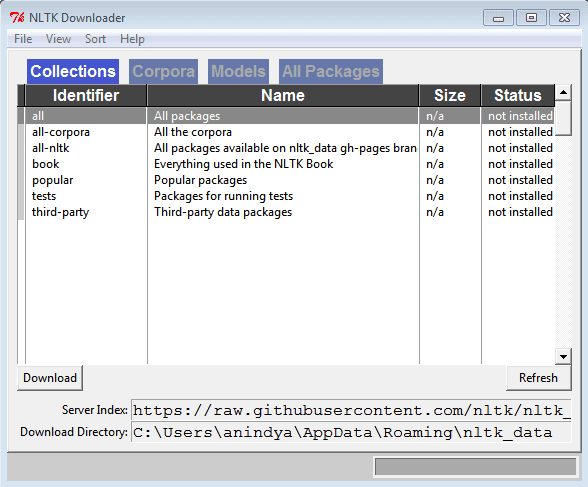
Since this consists of a large number of datasets, it might take some time to complete so make sure you have a fast internet connection before downloading them.
After you’re done, come back to the Jupyter notebook, where we will be exploring the different NLP tools.
Tokenization
The process of turning a string or a text paragraph into smaller chunks or tokens such as words, phrases, keywords, symbols, etc. Some useful tokenization methods:
- sent_tokenize
- word_tokenize
- RegexpTokenizer
- BlanklineTokenizer
sent_tokenize
This function extracts all sentences present in a text document.
First, we import sent_tokenize and then pass it a paragraph as an argument, which outputs a list that contains all the sentences as individual elements.
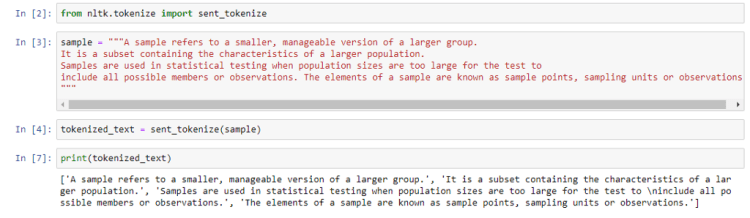
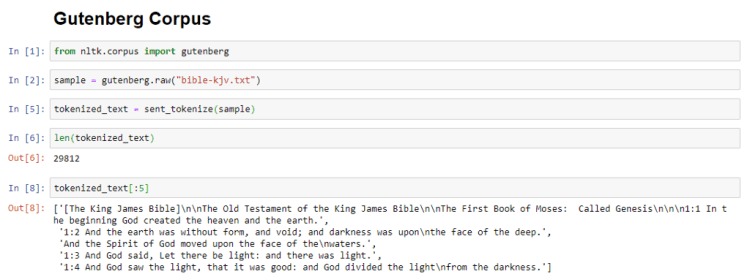
You can also make use of one of the datasets of the NLTK corpora instead of using a sample string.
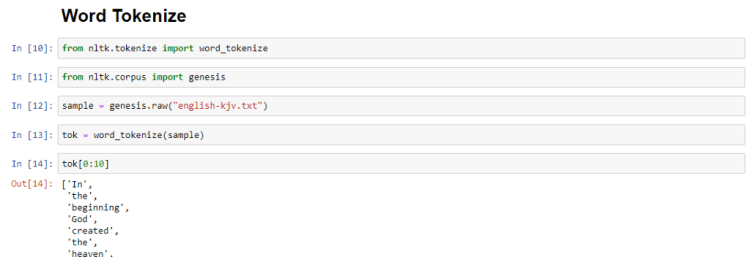
word_tokenize
This function extracts individual words from a text document.
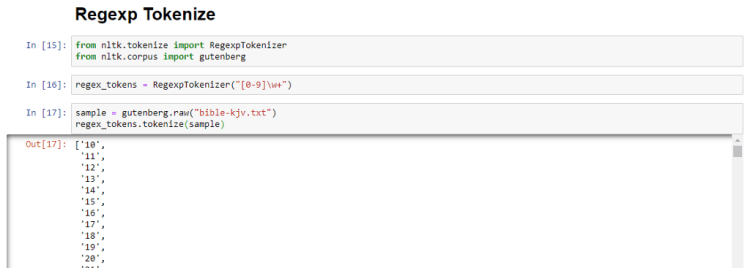
RegexpTokenizer
This is used to match patterns in a text document and only extract those which match with the regular expression (regex).
Here, we will use RegexpTokenizer to match with a regex which will give us a list of all the numbers present in the Bible.
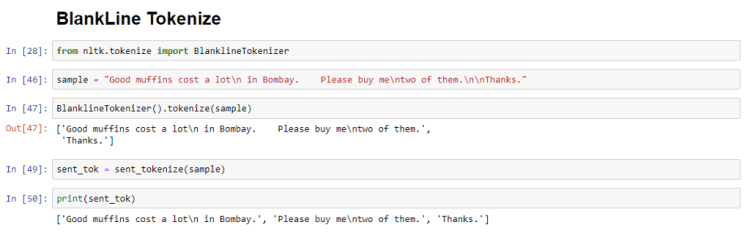
BlanklineTokenizer
This function tokenizes sentences even if they have blank lines or spaces between them.

In this example, both RegexpTokenizer and BlankLineTokenizer are used on the same sample text which will give a clear idea on both these functions.
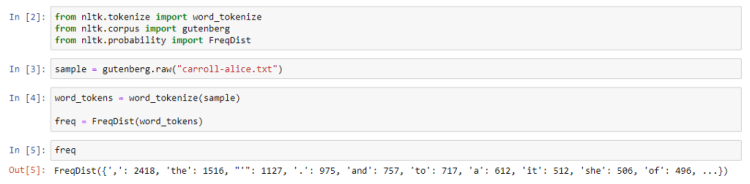
Frequency Distribution
This is used to get the word frequency in a text. It works similarly to a dictionary, where the keys are the words and the values are the counts associated with the word.
After tokenizing into words, we pass the tokens into the object declaration of the FreqDist class.
The most_common method of freq object can be used to see the most common occurrences of the words. The plot method can be used to graph a plot of the same.
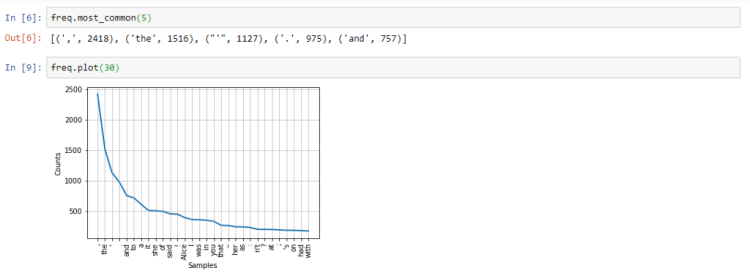
You can also iterate through the frequency distribution and find the number of occurrences of any particular word.
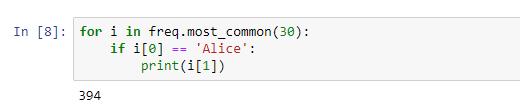
As you can see above, there are a lot of useless ‘words’ which have been tokenized, from punctuation marks like commas and spaces to particles like the, a, etc.
Stopwords
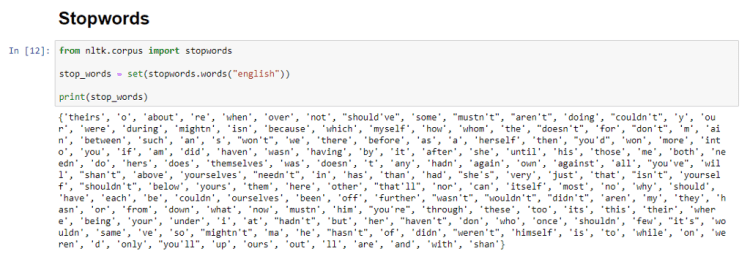
Fortunately, NLTK has a list of such useless words of 16 different languages. These are called stopwords. Using these, we can filter out the data and clean it.
We will try finding out the frequency distribution of the words but this time we will be using stopwords to get better results.

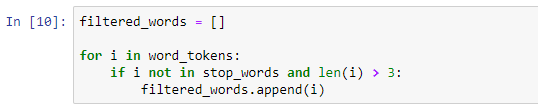
On line 17, we loop through the word tokens and then select only those words which are not present in the stopwords list and whose length is greater than 3.
If you have trouble understanding list comprehension, here is the same code, written in a more familiar way.
If we now plot the graph and look at the most common occurrences of words, we will get a much more sensible result.
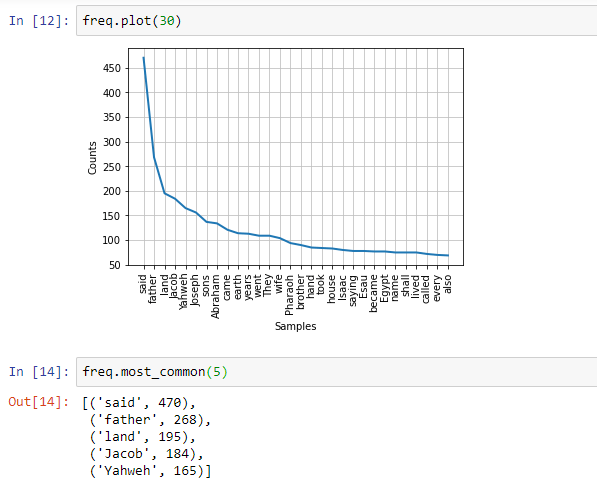
But there are many times when two or more consecutive words give us more information rather than individual words. Fortunately, NLTK provides us a way to handle that.
Bigrams, Trigrams, and Ngrams
Two consecutive words that occur in a text document are called bigrams.
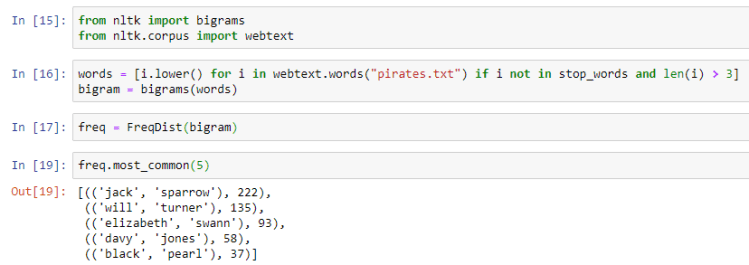
We first break the text into word tokens and then pass those tokens to the bigrams module imported from nltk to convert the word tokens into bigrams. We then pass it on to FreqDist and use the most_common method to look at the top 5 most common words.
Similarly, three consecutive words that appear in a sentence are called trigrams.
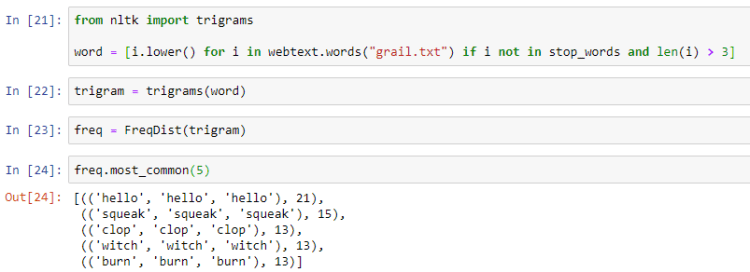
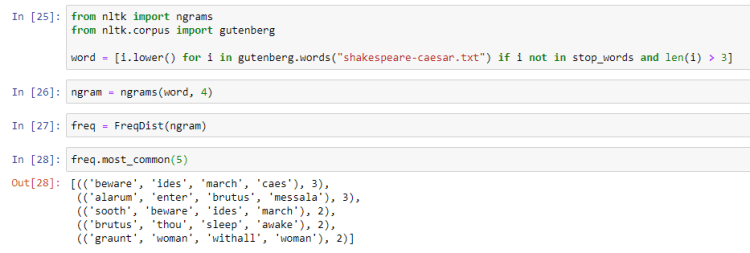
We can also look for more consecutive words by using the ngrams module.
Stemming
This is a process for text normalization which involves reducing words to their root/base words from their derived words. NLTK provides us the PorterStemmer class to perform stemming operations on word tokens.
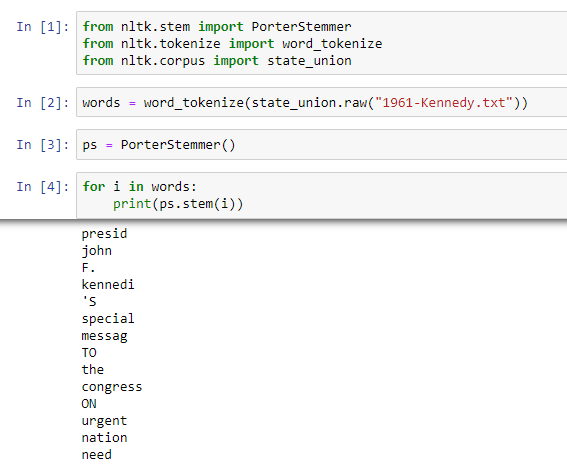
As you can see, stemming doesn’t really help much here because it reduces the actual words to such an extent that it doesn’t have any morphological sense anymore. That is why we have another process called lemmatization.
Lemmatization
This is a process that involves reducing words to their root/base words using vocabulary and morphological analysis. It brings context to the words which are not done in stemming.

After creating an instance of the WordNetLemmatizer class, we call the method lemmatize to lemmatize the words. Words are reduced to their original form while still retaining their meaning.
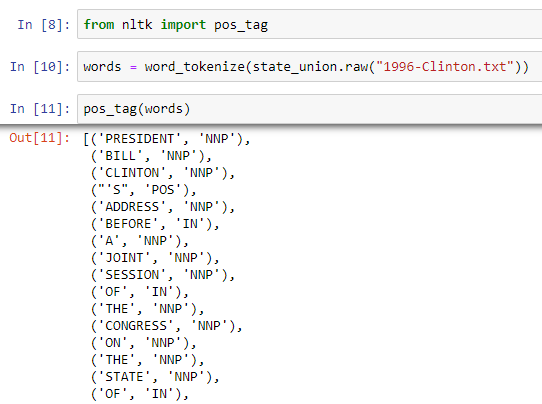
Parts-of-Speech Tagging
Here, the task is to label/tag each word in a sentence with its grammatical groups such as nouns, pronouns, adjectives, and many more. Some of the acronyms are:
CC — Coordinating Conjunction
JJ — Adjective
IN — Preposition/Subordinating Conjunction
JJR — Adjective, comparative
JJS — Adjective, superlative
NN — Noun, singular
NNP — Proper Noun, singular
PRP — Personal Pronoun
As you can see, the pos_tag function takes in word tokens as input and returns a list of tuples consisting of the word alongside the part of speech tag.
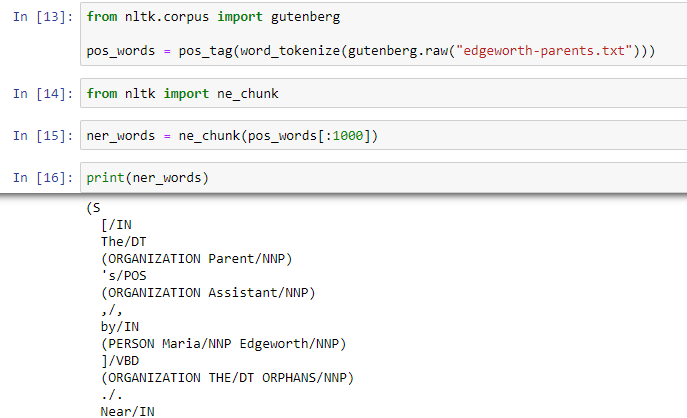
Named-Entity-Recognition
This is used to identify important named entities in a text such as people, places, locations, dates, organizations, etc. Here are a few types of entities along with their examples-
ORGANIZATION — Facebook, Alphabet, etc.
LOCATION — 22 West St, Mount Everest
GPE (Geo-Political Entity) — India, Ukraine, South East Asia
MONEY — 100 Million Dollars
PERSON — Obama, George W. Bush
DATE — July, 2019–05–2
TIME — three fourty pm, 3:12 am
FACILITY — Washington Monument, Stonehenge
In order to use this module, we have to pass in parts-of-speech tags as the argument. So we first import the necessary modules, tokenize the text into words and find out its parts-of-speech and then pass it to ne_chunk which will give us the proper results.
Congratulations! You have completed this tutorial and now you’re equipped to take on NLP projects on a beginner level.
But beware, for this tutorial is just the tip of the iceberg. NLP is a very vast field and has many more methods and modules that we haven’t gone through. However, I would encourage you to check them out on your own and build small projects to put your newly-learned skills to good use.
Github Repository link:
sthitaprajna-mishra/applied_nlp_python_tutorial
Don’t forget to give us your ? !




Applied Natural Language Processing (NLP) in Python | Exploring NLP Libraries was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.




{kind=link}