365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
This article is most suited for individuals who would like to pursue a Master’s degree with a focus on machine learning/data science and need some guidance on their decision making. It highlights the best universities, their respective programmes, my experiences regarding the admission process, and the results.
One year ago, I have decided to apply to the best universities across Europe. The first task was finding the best universities. The easiest way of doing so was through university rankings. While rankings can’t fully capture how good a university is, it is useful information for the initial screening. Based on three very different university rankings — QS university rankings, CSRankings, and Shanghai Ranking — I have made a top 10 list. The list is based on machine learning/computer science ranking.
University of Oxford
ETH in Zurich
University of Cambridge
EPFL
Imperial College London
University College London
Technical University in Munich
KTH Royal Institute of Technology
Delft University of Technology
University of Amsterdam
Many great universities didn’t make it into the list and I was therefore also researching other top universities that were recommended to me by my friends and colleagues from previous internships. Namely, Politecnico di Milano, Technical University of Denmark, and Czech Technical University in Prague.
The application was somewhat similar. Except for TUM and CTU in Prague, all universities required two letters of recommendation. Except for CTU in Prague, all universities required a motivational letter and a curriculum vitae (CV). Also, all universities required a transcript of records and proof of English proficiency.
Now the fun differences. KTH and Cambridge required a list of publications. I gladly submitted my list of one publication I had at that time. I wrote a project proposal for KTH and Cambridge, which wasn’t an easy task. Proposing something novel and interesting is never easy. Despite this, I had a very pleasant experience applying to KTH, everything was done online and the application was free. TUM required a 1000 word scientific essay, which was actually much simpler to do, than making a project proposal.
What wasn’t fun was applying to ETH. In the online application form, I had to fill out by hand every course I had taken, including grade, credits, etc. Then, I had to pay around 140 euros just to apply. Print out every document and finally send it to Switzerland by postal service. In 21st century.
As months passed by, decisions started rolling in. First came a rejection from Cambridge. That wasn’t too bad. I knew I was aiming high with Cambridge, but I am glad, I have tried. Next came rejections from Imperial and ETH. These hurt. I felt I had a real shot at getting into these institutions and the rejections affected me greatly. I didn’t know what I did wrong. I knew my grades weren’t perfect, but I thought that my extracurricular activities (like being published as a bachelor student) would play a bigger role. Maybe if I had applied to a different programme, things would have been different. After about two months I got the results from KTH. Waitlisted. Things were finally starting to turn for the better. While a waitlist is not acceptance, it meant that out of more than a thousand people that applied that year to the machine learning programme at KTH, I was better than most. Knowing how good chance you actually had felt much better than a rejection without any feedback. After a few weeks, I received acceptance letters from TUM and CTU. I was ecstatic. I got into a great university, where I can continue pursuing my passion. And that’s all that matters.
In the order the decisions arrived, here are the results:
University of Cambridge: Rejected
Imperial College London: Rejected
ETH Zurich: Rejected
KTH Royal Institute of Technology: Waitlisted
Technical University in Munich: Accepted
Czech Technical University in Prague: Accepted (based on grades)
As a true data scientist/machine learning enthusiast I offer more data. I am willing to share with you my application profile. Then, you can evaluate your own chances and apply accordingly.
I had a GPA of 1.55 (where 1.0 is the best and 4.0 is the worst), or 3.45 if 4.0 is the best. As mentioned earlier, I had one publication, more than a year of research experience including an internship at the European Space Agency. I had an exchange experience in Singapore. I also tried to highlight my achievements in competitive programming (ACM ICPC) as an extracurricular activity (together with two of my teammates we were the best team at our university and our university even sent us to train in Russia). Finally, I had two strong letters of recommendation, one from my research supervisor at CTU and the other from my former boss at ESA.
Here is my CV and one of my motivational letters. But most importantly, I selected all these 6 universities based on courses I could be taking, I felt I had a real motivation to study there.
Conclusion
Overall, I am happy I can continue pursuing my passion at a top university. That said, I am also a bit sad because I thought I would get accepted by more of these institutions. Personally, I believe that my GPA caused the rejections. Another factor might be the fact that I wasn’t applying from the best university. CTU in Prague is a great school, but most people who apply to pursue a Master’s degree at Cambridge are the bachelor students at Cambridge (and the rest are also from mostly prestigious universities).
What schools are you planning to apply? Share your thoughts below 🙂
In this tutorial, we walk through the process of using Snorkel to generate labels for an unlabelled dataset. We will provide you examples of basic Snorkel components by guiding you through a real clinical application of Snorkel.
Have you ever thought about how toxic comments get flagged automatically on platforms like Quora or Reddit? Or how mail gets marked as spam? Or what decides which online ads are shown to you?
All of the above are examples of how text classification is used in different areas. Text classification is a common task in natural language processing (NLP) which transforms a sequence of text of indefinite length into a single category.
One theme that emerges from the above examples is that all have a binary target class. For example, either the comment is toxic or not toxic, or the review is fake or not fake. In short, there are only two target classes, hence the term binary.
But this is not always the case, and some problems might have more than two target classes. These problems are conveniently termed multiclass classifications, and it is these problems we’ll focus on in this post. Some examples of multiclass classification include:
The sentiment of a review: positive, negative or neutral (three classes)
News Categorization by genre : Entertainment, education, politics, etc.
In this post, we will go through a multiclass text classification problem using various Deep Learning Methods.
Artificial Intelligence Jobs
Dataset / Problem Description
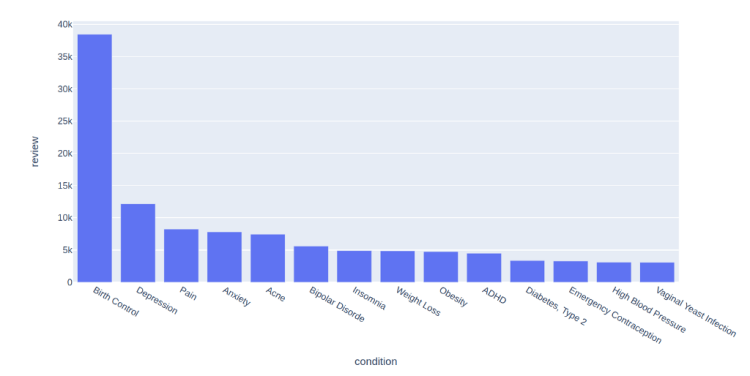
For this post I am using the UCI ML Drug Review dataset from Kaggle. It contains over 200,000 patient drug reviews, along with related conditions. The dataset has many columns, but we will be using just two of them for our NLP Task.
So, our dataset mostly looks like this:
Task: We want to classify the top disease conditions based on the drug review.
A Primer on word2vec embeddings:
Before we go any further into text classification, we need a way to represent words numerically in a vocabulary. Why? Because most of our ML models require numbers, not text.
One way to achieve this goal is by using one-hot encoding of word vectors, but this is not the right choice. Given a vast vocabulary, this representation would take a lot of space, and it cannot accurately express the similarity between different words, such as if we want to find the cosine similarity between numerical words x and y:
Given the structure of one-hot encoded vectors, the similarity is always going to be 0 between different words.
Word2Vec overcomes the above difficulties by providing us with a fixed-length (usually much smaller than the vocabulary size) vector representation of words. It also captures the similarity and analogous relationships between different words.
Word2vec vectors of words are learned in such a way that they allow us to learn different analogies. This enables us to do algebraic manipulations on words that were not possible previously.
For example: What is king — man + woman? The result is Queen.
Word2Vec vectors also help us to find the similarity between words. If we look for similar words to “good”, we will find awesome, great, etc. It is this property of word2vec that makes it invaluable for text classification. With this, our deep learning network understands that “good” and “great” are words with similar meanings.
In simple terms, word2vec creates fixed-length vectors for words, giving us a d dimensional vector for every word (and common bigrams) in a dictionary.
These word vectors are usually pre-trained, and provided by others after training on a large corpora of texts like Wikipedia, Twitter, etc. The most commonly used pre-trained word vectors are Glove and Fast text with 300-dimensional word vectors. In this post, we will use the Glove word vectors.
Data Preprocessing
In most cases, text data is not entirely clean. Data coming from different sources have different characteristics, and this makes text preprocessing one of the most critical steps in the classification pipeline. For example, Text data from Twitter is different from the text data found on Quora or other news/blogging platforms, and each needs to be treated differently. However, the techniques we’ll cover in this post are generic enough for almost any kind of data you might encounter in the jungles of NLP.
a) Cleaning Special Characters and Removing Punctuation
Our preprocessing pipeline depends heavily on the word2vec embeddings we are going to use for our classification task. In principle, our preprocessing should match the preprocessing used before training the word embedding. Since most of the embeddings don’t provide vector values for punctuation and other special characters, the first thing we want to do is get rid of the special characters in our text data.
# Some preprocesssing that will be common to all the text classification methods you will see. import re def clean_text(x): pattern = r'[^a-zA-z0-9\s]’ text = re.sub(pattern, ”, x) return x
b) Cleaning Numbers
Why do we want to replace numbers with #s? Because most embeddings, including Glove, have preprocessed their text in this way.
Small Python Trick: We use an if statement in the code below to check beforehand if a number exists in a text because an if is always faster than a re.sub command, and most of our text doesn’t contain numbers.
def clean_numbers(x): if bool(re.search(r’\d’, x)): x = re.sub(‘[0-9]{5,}’, ‘#####’, x) x = re.sub(‘[0-9]{4}’, ‘####’, x) x = re.sub(‘[0-9]{3}’, ‘###’, x) x = re.sub(‘[0-9]{2}’, ‘##’, x) return x
c) Removing Contractions
Contractions are words that we write with an apostrophe. Examples of contractions are words like “ain’t” or “aren’t”. Since we want to standardize our text, it makes sense to expand these contractions. Below we have done this using contraction mapping and regex functions.
Apart from the above techniques, you may want to do spell correction, too. But since our post is already quite long, we’ll leave that for now.
Data Representation: Sequence Creation
One thing that has made deep learning a go-to choice for NLP is the fact that we don’t have to hand-engineer features from our text data; deep learning algorithms take as input a sequence of text to learn its structure just like humans do. Since machines cannot understand words, they expect their data in numerical form. So we need to represent our text data as a series of numbers.
To understand how this is done, we need to understand a little about the Keras Tokenizer function. Other tokenizers are also viable, but the Keras Tokenizer is a good choice for me.
a) Tokenizer
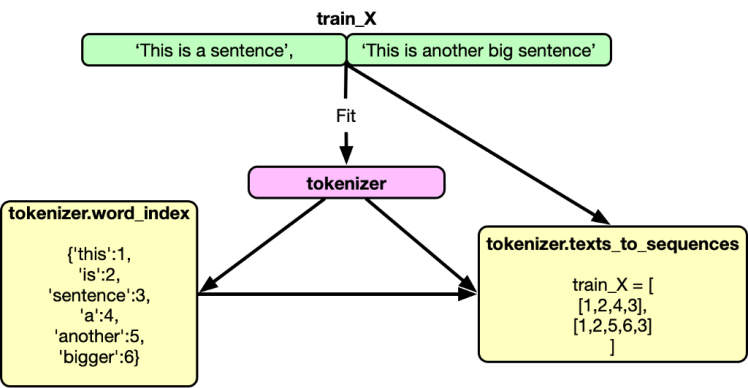
Put simply, a tokenizer is a utility function that splits a sentence into words. keras.preprocessing.text.Tokenizer tokenizes (splits) a text into tokens (words) while keeping only the words that occur the most in the text corpus.
The num_words parameter keeps only a pre-specified number of words in the text. This is helpful because we don’t want our model to get a lot of noise by considering words that occur infrequently. In real-world data, most of the words we leave using the num_words parameter are normally misspelled words. The tokenizer also filters some non-wanted tokens by default and converts the text into lowercase.
Once fitted to the data, the tokenizer also keeps an index of words (a dictionary we can use to assign unique numbers to words), which can be accessed by tokenizer.word_index. The words in the indexed dictionary are ranked in order of frequency.
So the whole code to use the tokenizer is as follows:
from keras.preprocessing.text import Tokenizer ## Tokenize the sentences tokenizer = Tokenizer(num_words=max_features) tokenizer.fit_on_texts(list(train_X)+list(test_X)) train_X = tokenizer.texts_to_sequences(train_X) test_X = tokenizer.texts_to_sequences(test_X)
where train_X and test_X are lists of documents in the corpus.
b) Pad Sequence
Normally our model expects that each text sequence (each training example) will be of the same length (the same number of words/tokens). We can control this using the maxlen parameter.
Now our training data contains a list of numbers. Each list has the same length. And we also have the word_index which is a dictionary of the words that occur most in the text corpus.
c) Label Encoding the Target Variable
The Pytorch model expects the target variable as a number and not a string. We can use Label encoder from sklearn to convert our target variable.
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() train_y = le.fit_transform(train_y.values) test_y = le.transform(test_y.values)
Load Embedding
First, we need to load the required Glove embeddings.
def load_glove(word_index): EMBEDDING_FILE = ‘data/glove.840B.300d.txt’ def get_coefs(word,*arr): return word, np.asarray(arr, dtype=’float32′)[:300] embeddings_index = dict(get_coefs(*o.split(” “)) for o in open(EMBEDDING_FILE))
nb_words = min(max_features, len(word_index)+1) embedding_matrix = np.random.normal(emb_mean, emb_std, (nb_words, embed_size)) for word, i in word_index.items(): if i >= max_features: continue embedding_vector = embeddings_index.get(word) if embedding_vector is not None: embedding_matrix[i] = embedding_vector else: embedding_vector = embeddings_index.get(word.capitalize()) if embedding_vector is not None: embedding_matrix[i] = embedding_vector return embedding_matrix
Be sure to put the path of the folder where you download these GLoVE vectors. What does the embeddings_index contain? It’s a dictionary in which the key is the word, and the value is the word vector, a np.array of length 300. The length of this dictionary is somewhere around a billion.
Since we only want the embeddings of words that are in our word_index, we will create a matrix that just contains required embeddings using the word index from our tokenizer.
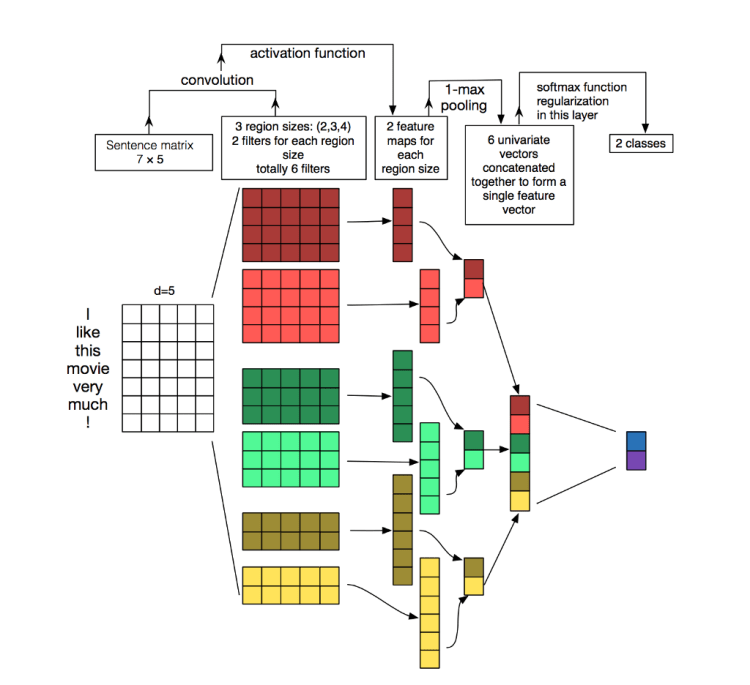
Representation: The central concept of this idea is to see our documents as images. But how? Let’s say we have a sentence, and we have maxlen = 70 and embedding size = 300. We can create a matrix of numbers with the shape 70×300 to represent this sentence. Images also have a matrix where individual elements are pixel values. But instead of image pixels, the input to the task is sentences or documents represented as a matrix. Each row of the matrix corresponds to a one-word vector.
Convolution Idea: For images, we move our conv. filter both horizontally as well as vertically, but for text we fix kernel size to filter_size x embed_size, i.e. (3,300) we are just going to move vertically down the convolution looking at three words at once, since our filter size in this case is 3. This idea seems right since our convolution filter is not splitting word embedding; it gets to look at the full embedding of each word. Also, one can think of filter sizes as unigrams, bigrams, trigrams, etc. Since we are looking at a context window of 1, 2, 3, and 5 words respectively.
Here is the text classification CNN network coded in Pytorch.
class CNN_Text(nn.Module): def __init__(self): super(CNN_Text, self).__init__() filter_sizes = [1,2,3,5] num_filters = 36 n_classes = len(le.classes_) self.embedding = nn.Embedding(max_features, embed_size) self.embedding.weight = nn.Parameter(torch.tensor(embedding_matrix, dtype=torch.float32)) self.embedding.weight.requires_grad = False self.convs1 = nn.ModuleList([nn.Conv2d(1, num_filters, (K, embed_size)) for K in filter_sizes]) self.dropout = nn.Dropout(0.1) self.fc1 = nn.Linear(len(filter_sizes)*num_filters, n_classes) def forward(self, x): x = self.embedding(x) x = x.unsqueeze(1) x = [F.relu(conv(x)).squeeze(3) for conv in self.convs1] x = [F.max_pool1d(i, i.size(2)).squeeze(2) for i in x] x = torch.cat(x, 1) x = self.dropout(x) logit = self.fc1(x) return logit
2. BiDirectional RNN (LSTM/GRU)
TextCNN works well for text classification because it takes care of words in close range. For example, it can see “new york” together. However, it still can’t take care of all the context provided in a particular text sequence. It still does not learn the sequential structure of the data, where each word is dependent on the previous word, or a word in the previous sentence.
RNNs can help us with that. They can remember previous information using hidden states and connect it to the current task.
Long Short Term Memory networks (LSTM) are a subclass of RNN, specialized in remembering information for extended periods. Moreover, a bidirectional LSTM keeps the contextual information in both directions, which is pretty useful in text classification tasks (However, it won’t work for a time series prediction task as we don’t have visibility into the future in this case).
For a simple explanation of a bidirectional RNN, think of an RNN cell as a black box taking as input a hidden state (a vector) and a word vector and giving out an output vector and the next hidden state. This box has some weights which need to be tuned using backpropagation of the losses. Also, the same cell is applied to all the words so that the weights are shared across the words in the sentence. This phenomenon is called weight-sharing.
Hidden state, Word vector ->(RNN Cell) -> Output Vector , Next Hidden state
For a sequence of length 4 like “you will never believe”, The RNN cell gives 4 output vectors, which can be concatenated and then used as part of a dense feedforward architecture.
In the bidirectional RNN, the only change is that we read the text in the usual fashion as well in reverse. So we stack two RNNs in parallel, and we get 8 output vectors to append.
Once we get the output vectors, we send them through a series of dense layers and finally, a softmax layer to build a text classifier.
In most cases, you need to understand how to stack some layers in a neural network to get the best results. We can try out multiple bidirectional GRU/LSTM layers in the network if it performs better.
Due to the limitations of RNNs, such as not remembering long term dependencies, in practice we almost always use LSTM/GRU to model long term dependencies. In this case, you can think of the RNN cell being replaced by an LSTM cell or a GRU cell in the above figure.
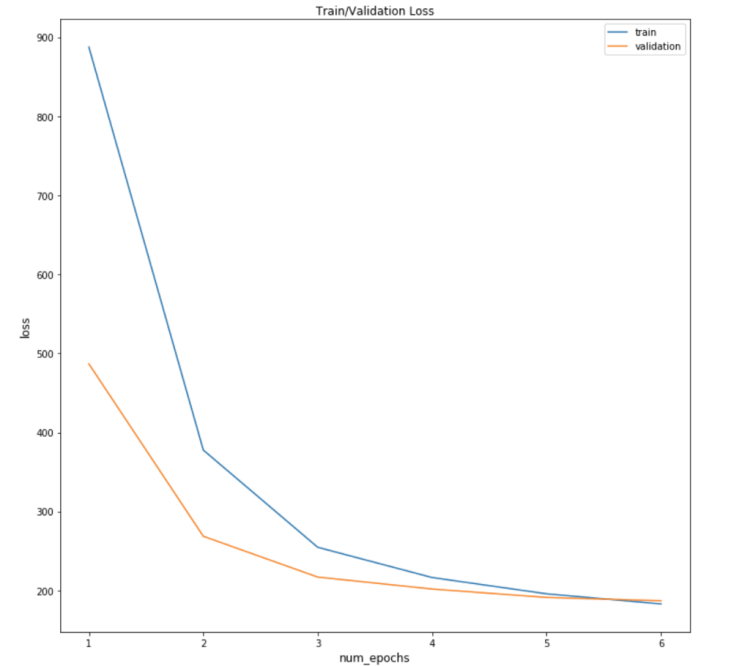
Below is the code we use to train our BiLSTM Model. The code is well commented, so please go through the code to understand it. You might also want to look at my post on Pytorch.
n_epochs = 6 model = BiLSTM() #Use CNN_Text() for CNN Model loss_fn = nn.CrossEntropyLoss(reduction=’sum’) optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=0.001) model.cuda() # Load train and test in CUDA Memory x_train = torch.tensor(train_X, dtype=torch.long).cuda() y_train = torch.tensor(train_y, dtype=torch.long).cuda() x_cv = torch.tensor(test_X, dtype=torch.long).cuda() y_cv = torch.tensor(test_y, dtype=torch.long).cuda() # Create Torch datasets train = torch.utils.data.TensorDataset(x_train, y_train) valid = torch.utils.data.TensorDataset(x_cv, y_cv) # Create Data Loaders train_loader = torch.utils.data.DataLoader(train, batch_size=batch_size, shuffle=True) valid_loader = torch.utils.data.DataLoader(valid, batch_size=batch_size, shuffle=False) train_loss = [] valid_loss = [] for epoch in range(n_epochs): start_time = time.time() # Set model to train configuration model.train() avg_loss = 0. for i, (x_batch, y_batch) in enumerate(train_loader): # Predict/Forward Pass y_pred = model(x_batch) # Compute loss loss = loss_fn(y_pred, y_batch) optimizer.zero_grad() loss.backward() optimizer.step() avg_loss += loss.item() / len(train_loader)
# Set model to validation configuration – Doesn’t get trained here model.eval() avg_val_loss = 0. val_preds = np.zeros((len(x_cv),len(le.classes_)))
for i, (x_batch, y_batch) in enumerate(valid_loader): y_pred = model(x_batch).detach() avg_val_loss += loss_fn(y_pred, y_batch).item() / len(valid_loader) # keep/store predictions val_preds[i * batch_size:(i+1) * batch_size] =F.softmax(y_pred).cpu().numpy()
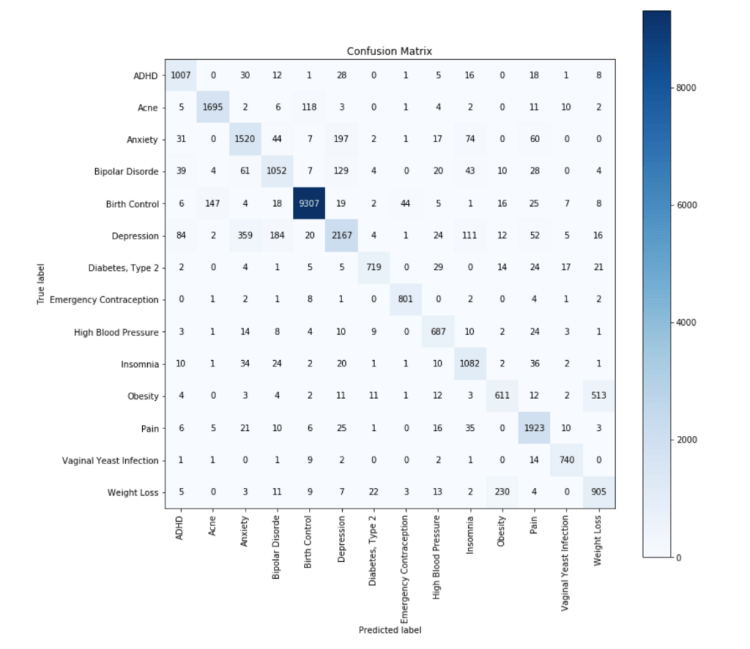
Below is the confusion matrix for the results of the BiLSTM model. We can see that our model does reasonably well, with an 87% accuracy on the validation dataset.
What’s interesting is that even at points where the model performs poorly, it is quite understandable. For example, the model gets confused between weight loss and obesity, or between depression and anxiety, or between depression and bipolar disorder. I am not an expert, but these diseases do feel quite similar.
import scikitplot as skplt y_true = [le.classes_[x] for x in test_y] y_pred = [le.classes_[x] for x in val_preds.argmax(axis=1)] skplt.metrics.plot_confusion_matrix( y_true, y_pred, figsize=(12,12),x_tick_rotation=90)
Conclusion
In this post, we covered deep learning architectures like LSTM and CNN for text classification, and explained the different steps used in deep learning for NLP.
There is still a lot that can be done to improve this model’s performance. Changing the learning rates, using learning rate schedules, using extra features, enriching embeddings, removing misspellings, etc. I hope this boilerplate code provides a go-to baseline for any text classification problem you might face.
It is undeniable that the technological advances have transformed the way various businesses use to work. However, some businesses (such as law and insurance firms) are still dealing with the cabinets jam-packed with vendor agreements, contracts, employees’ credentials, and other documents.
According to reports, workers spend approximately 11 hours in a week to deal with documents related issues, which leads to low productivity and poor quality of the customer service. By harnessing the potential of artificial intelligence and machine learning, businesses can revamp the traditional document management system.
It might seem unbelievable at this moment, but after reading this article, you would know how these two technologies can make the workflow smarter, faster, and better. Here, we have highlighted some of the ways how AI and ML are reshaping the document management system:
Data Extraction
Using an AI-powered DMS,businesses can modernize the way data is extracted. Wondering how? Well, such an advanced system can read the information accurately to understand its intent. On the basis of specific patterns, the AI-enabled DMS system analysis and retrieve only useful information to accomplish a particular job.
Like AI, machine learning can also be a powerful tool in data extraction. Using this technology, businesses can develop a way to help its employees to extra only the relevant data without creating any mess. This artificial intelligence document management and extraction helps in saving a lot of time and effort.
Document Clustering
A DMS powered by artificial intelligence and machine learning can analyze documents to group them by topics. This further facilitates in understanding the nature of a document and how it is related to some other document.
Artificial Intelligence Jobs
Automatic Classification and Processing
With the help of optical character recognition, artificial intelligence technology can make a DMS to read what’s written on a document to categorize it rightly. It further helps in automating workflows on the basis of that categorization. Just like AI, machine learning also plays a major role in data classification and processing. The technology improves the capability of a DMS to identify and process information.
Improved Data Quality
AI-powered DMS can help businesses to minimize data redundancy, prevent the occurrence of various input errors, and protect files misplacement. It can also help them to make efficient decisions and process business by offering useful insights.
One of the biggest roles of artificial intelligence in the document management system is data analytics. Analyzing the data correctly and flawlessly can contribute to your business growth. Using various techniques (data visualization and predictive analysis) involved in ML and AI, businesses can make better decisions.
Document Security
Along with document management, it is also imperative to secure documents and data, especially confidential ones. AI-powered DMS offers high-level document security by detecting the sensitive as well as personally identifiable information in documents. The technology then marks such documents so that a user can handle them carefully.
Structuring the Unstructured Data
With the advancement of technology, we can now generate data from multiple sources; however, this data needs to be processed and structured to fetch useful information out of it. It is estimated that out of all the data collected by an organization, approx. 80% of it is unstructured. An AI-enabled document management system can help businesses to make the most out of this data by automatically analyzing files, fetch technical data, and connect files with relevant information.
In fact, most of the companies are leveraging AI and ML to look into emails, messages, and other ways of communication to know semantics, words, sentiments, and more to predict information related to products and services.
Content Support and Management
The advanced DMS with the potential of AI and ML helps in supporting content as well as document management. It can also simplify document development workflow. Grammarly, a popular grammar check and proofreading software, is a sheer proof of how AI can be implemented to edit documents without the need of a human being.
Modernize Document Management
When we talk about document management machine learning and artificial intelligence, it would be no wrong to say that these technologies have brought a big revolution into this field. Industries that rely heavily on documents can make the most AI for data discovery, streamlining the workflow, increase productivity, and make more data-driven decisions.
Bottom Line
With the rapid adaption of artificial intelligence and machine learning by various businesses, it has become easier to categorize and manage documents. With AI document analysis, data extraction, machine learning in content management, and other advantages given in this article, these businesses are managing documents effectively and efficiently. Moreover, they can store, process, and extract data in seconds. . If you too want to lift your business processes by integrating AI and ML, then reach out to a reliable AI development company or hire ML developers.
Machine Learning is a Very Broad Field. If Machine Learning is a dish, then linear algebra, programming, analytical skills, statistics, and Algorithms are the primary recipes of Machine Learning. If you will go more deep inside the Machine Learning concepts, you will get confused about what to learn first or what to not focus much. So here, In this article, I will take you through the most important Machine Learning Concepts, which you need to keep as must-know concepts in machine learning.
The Most Important Concepts of Machine Learning
All Machine Learning concepts, that I have shown below are not based on the order of their rank or weightage in Machine Learning. Just keep in mind that every concept is more important than the others. So while learning Machine Learning you just can’t miss these concepts:
Pipelines
A sequence of data processing components is called a Data Pipeline. Pipelines are very common in Machine Learning systems since there is a lot of data to manipulate and many data transformations to applying.
Components typically run asynchronously. Each component pulls in a large amount of data, processes it, and splits out the result in another data store. Then, sometime later, the next component in the pipeline pulls this data and splits out its output. Each component is fairly self-contained: the interface between components is simply the data store.
This makes a system to grasp, and different teams can focus on different components. Moreover, if a component breaks down, the downstream components can often continue to run normally by just using the last output from the broken component. This makes the architecture quite robust. You can learn to create pipeline and some more machine learning concepts of creating pipelines from here.
Artificial Intelligence Jobs
Cross-Validation
One way to evaluate your machine learning model would be to use the train_test_split() function to split the training set into a smaller test set and a validation set, then train your models against the test set and evaluate them against the validation set. It’s a bit of work, but nothing too difficult, and it would work fairly well.
A great alternative is to use the cross-validation feature provided by Scikit-Learn. Cross-Validation works by splitting the training set into 10 distinct subsets called folds, then it trains and evaluates a Machine Learning model 10 times, picking a different fold for evaluation every time and training on the other 9 folds. I implement cross-validation in most of the tasks. You can learn to use cross-validation and some more machine learning concepts of it from here.
Grid Search
One option would be to fiddle with the hyperparameters manually until you find a great combination of hyperparameter values. This would be very tedious work, and you may have time to explore many combinations.
Instead, you should get Scikit-Learn’s GridSearchCV to search for you. All you need to do is tell it which hyperparameters you want it to experiment which and what values to try out, and it will use cross-validation to evaluate all the possible combinations of hyperparameter values. You can learn to use the Grid Search Algorithm and some more machine learning concepts of it from here.
Creating your Own Algorithms
If you are using Scikit-Learn, you can easily use a lot of algorithms that are already made by some famous Researchers, Data Scientists, and other Machine Learning experts. Have you ever thought of building your algorithm instead of using a module like Scikit-Learn?
All the Machine Learning Algorithms that Scikit-Learn provides are easy to use but to be a Machine Learning Expert in a brand like Google and Microsoft, you need to build your algorithms instead of using any package so that you could easily create an algorithm according to your needs. You can learn to create your own algorithms and some fore machine learning concepts about building your own algorithm from here.
Training and Deploying a Machine Learning Model in a Web Application
I have trained and developed a lot of Machine Learning models, if you are a student in Machine Learning, you must have also developed models. When you train a machine learning model, also think about how you will deploy a machine learning model to serve your trained model to the available users. You will get a lot of websites who are teaching to train a machine learning model but nobody goes beyond to deploy a machine learning model. Because training and deploying a machine learning model are very different from each other. But it’s not difficult.
Training a model is the most important part of machine learning. But deploying a model is a different art because you have to think a lot in the process of how you will make your machine learning application to your users. You can learn to Deploy a machine learning model and some more machine learning concepts of deploying a model from here.
I hope you liked this article on the Machine Learning concepts that every Data Scientist should know.
An exceptional data architect cover letter can move your job application to the top of the pile.
To boost your cover letter’s chances of success, make sure to:
include as many keywords from the job description as appropriate. This guarantees your cover letter will pass the Applicant Tracking Systems (ATS) check;
prompt the employer to get in touch with you with a clear call-to-action… or let them know that you’ll contact them in a week if you don’t hear back.
The following data architect cover letter example will help you write a cover letter that emphasizes your competencies and experience.
You can download this template easily and customize your letter in minutes!
Once you’re ready, all you have to do is pair it with your resume and submit your job application with confidence.
Just click on the button below and follow the instructions.
With 4+ years of experience as a data architect at [Current Employer], I have developed a knack for novel processes and out-of-the-box solutions, and I believe my expert skills make me an ideal prospect for the [Company Name] data architect role.
During my work at [Current Employer], I have scored some amazing wins:
Launched a project where I established a step-by-step screening process for our third-party purchased data, which decreased database errors by 29% within 1 year
Prevented security risks by calculating the possible financial loss to the company in case security was compromised when uploading franchise data to our system. This facilitated the implementation of a new plan to strengthen data security measures
Solved external data integration issues by creating a script that not only changed the external data format but also ran tests to ensure the new format was compatible with our systems.
I am looking forward to a chance to discuss more with you about how my wins at [Current Employer] can translate into equivalent success at [Company Name].
I’ve attached my resume and would be happy to provide any additional details you might need.
Thank you for your time and consideration of my application.
An impressive Data Engineer cover letter can win your job application a decisive victory. When writing a cover letter, make sure to start it in a noteworthy way:
you can open your data engineer cover letter with a prominent achievement of yours;
or directly approach an employer’s pain-point and explain how you can help solve it.
The following data engineer cover letter example will help you write a cover letter that best highlights your skillset and experience.
You can download this template easily and personalize your letter in minutes!
Once you’re ready, all you have to do is pair it with your resume and submit your job application with confidence.
Just click on the button below and follow the instructions.
Presently a Data Engineer with more than 5 years of hands-on experience in building ETL packages and engineering OLAP cubes, I recently earned a Google Professional Data Engineer Certification. I’m an expert in implementing advanced algorithms and integrating them within project architecture, as well as developing applications against various NoSQL databases. I also re-designed a critical ingestion pipeline which increased the volume of processed data by 50%. This is why I am certain I make a perfect candidate for the Data Engineer position at [Company] and I am happy to officially submit my job application.
[Company Name] commitment to [Company Mission] is widely recognized in data engineering circles. Here are a few ways I believe I fit the role:
At [Past Employer], I increased efficiency by more than 80% by developing tools to assist in capturing serial data link requirements and performing automated verification testing
At [Past Employer], I worked with vendors to successfully evaluate new products and troubleshoot complex network issues.
At [Past Employer], I maintained the highest CSAT scores by ensuring minimal downtime during customer service migration
I am positive I can match these achievements at [Company Name]. More importantly, your initiative to [current company project] is highly motivating, especially since I have previously contributed to the success of similar projects.
Can we pick a time to sit down and discuss how my accomplishments can bring the same level of success to [Company Name]?
I will call you in 5 working days to receive a follow-up on my application and discuss possible interview dates.
Having worked as a Data Analyst with [Current Employer] for over 2 years, I have managed to facilitate a 20% increase in the number of new loyalty members while maintaining customer churn below 10% per year.
That’s why I believe I possess the versatile skillset and professional experience to be a top candidate for the job.
In my current role, I have worked on various wide-ranging projects which allowed me to expand my data toolbox and hands-on expertise. That experience, together with my Business Administration and Analytics background, gives me a deep understanding of the complexities of data, including sales data tracking and analysis; product, market, and share trends analysis to evaluate competitive market strategies; and data analytics project management.
During my time at [Current Employer], my wins also included:
Identifying opportunities to activate about 10% of high-profit customers by analyzing and tracking sales
Creating a new format for reporting and presenting sales and customer engagement that shortened the number of in-person meetings by 20%.
I am proud of the results I accomplish and I will be happy to discuss the upcoming projects and initiatives of [Company Name], as well as to share with you how my past wins at [Current Employer] can easily translate to greater insight and improved predictions at [Company Name].
Sincerely,
[Your Name]
P.S. If you have time for a quick lunch, I’d love sitting down with you to discuss how I could translate my increased number of loyal customers (20%) over to [Company Name].
An exceptional BI analyst cover letter can move your job application to the top of the pile.
To boost your cover letter’s chances of success, make sure to:
include as many keywords from the job description as appropriate. This guarantees your cover letter will pass the Applicant Tracking Systems (ATS) check;
prompt the employer to get in touch with you with a clear call-to-action… or let them know that you’ll contact them in a week if you don’t hear back.
The following BI analyst cover letter example will help you write a cover letter that emphasizes your competencies and experience.
You can download this template easily and customize your letter in minutes!
Once you’re ready, all you have to do is pair it with your resume and submit your job application with confidence.
Just click on the button below and follow the instructions.
As a BI analyst for the past 4 years, I’ve worked on many small and large-scale projects within numerous industries. Recently, I was happy to collaborate with [Client’s Name] on an investor performance project. After working together for a couple of weeks, they recommended that I apply for the BI Analyst role at [Company Name]. Having 100% client satisfaction ratings, I am positive I am the ideal candidate for the BI analyst position on the team.
During my work on various projects, I’ve had some remarkable accomplishments:
Restructured the strategic approach to billing which increased revenue by 9% and reduced accounts receivables by 17%
Developed a new automation framework for a series of reports, thus reducing processing time in general by 66%
Implemented changes in an existing workflow system that decreased coordination time by 47%
I am fully dedicated to the work that I do, whether it’s generating ad-hoc reports for management and stakeholders or training various business unit teams on the effective use of processes, tools, and resources.
If given the chance to transfer my expertise to [Company Name], I will contribute to the company’s success with that same commitment and drive.
I would love the opportunity to discuss your most ambitious business goals and demonstrate how my past wins can easily translate over to [Company Name] for increased revenue and management systems improvement.
I’ll call you in one week to receive an update on my application and discuss possible interview dates.
As a Master in Computer Science and a data scientist with 3 years of experience, I have become quite skilled at predictive modeling, machine learning, and advanced analytics. I am glad to count employing advanced machine learning techniques to predict the sales of new services with a 97% accuracy rate among my numerous professional accomplishments.
I would be happy to bring my robust skillset and the highest quality of service to [Company Name] as the next Data Scientist. And I am confident that my expertise will support your need for customized machine learning solutions including data querying and knowledge extraction.
At present, I am a Data Scientist at [Current Employer], a company with an established reputation in [industry/area of service].
My wins at [Current Employer] include:
Creating and implementing data models that contributed to achieving 25% higher returns compared to previous years
Developing workflows for conducting comparative analysis among diverse data sources and generalized approaches developed both in-house and externally
I look forward to discussing with you how my skills and experience can successfully translate to higher returns at [Company Name] and achieving the company’s most ambitious data science goals.










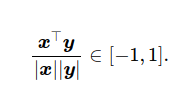




















{kind=link}