365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Preprocessing data for machine learning models is a core general skill for any Data Scientist or Machine Learning Engineer. Follow this guide using Pandas and Scikit-learn to improve your techniques and make sure your data leads to the best possible outcome.
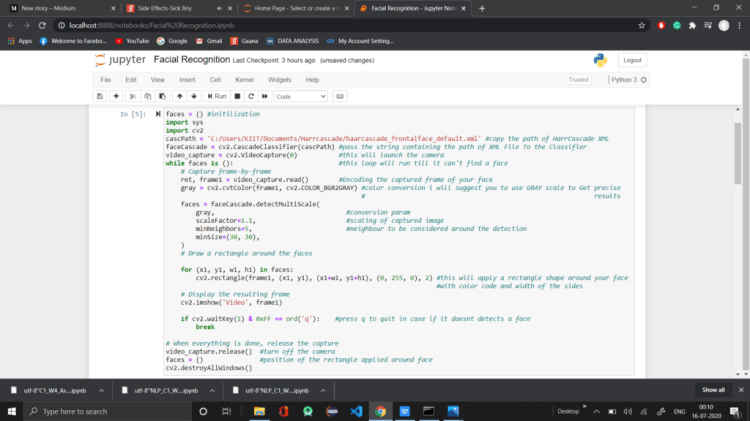
the Code below will help you to Register Your Face Which will be Compared With Scanned Faces(Functionalities of every line is explained in the comments)
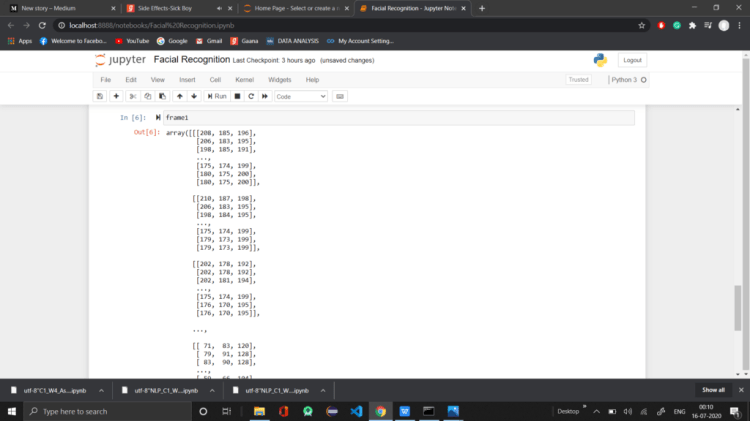
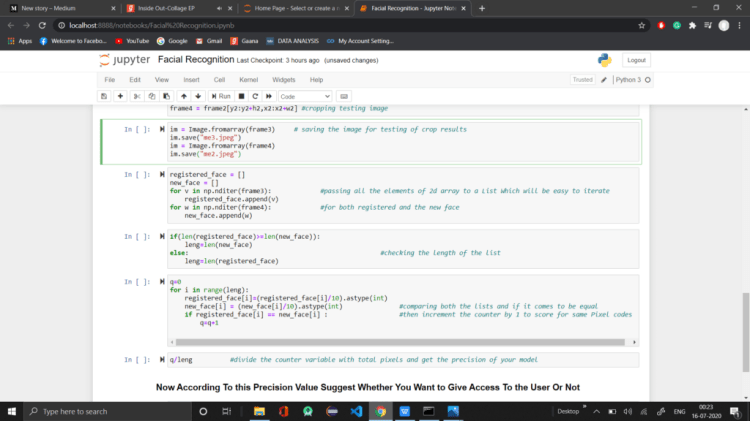
now from this Cell, we have divided the Captured Image into Small Pixels Which are further Encoded with their respective Pixel code in NumPy Array.
For Eg:- I Applied this function on my image and this is what I got:-
and from the function below we can again convert the NumPy Array To Respective Image and Save it By the Function Below:-
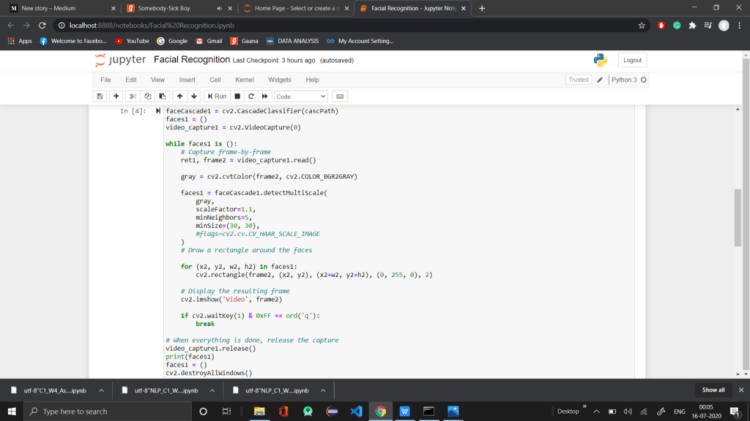
Now use the Second Instance of The faceCascade to Compare it with the Registered image and then Find the Accuracy :
this Cell Will again do the same, Capture the image and the will convert it into Its Respective NumPy Array
Now we Have Both the NumPy Array The Registered one and another to Test on.
Big Data Jobs
so now we are cropping the image of the Face only by the detected Rectangle Dimensions around the Faces ,for both Images (Registered and Testing One)
Look at the comments to know what’s every line doing
Machine Learning for Good Results:-
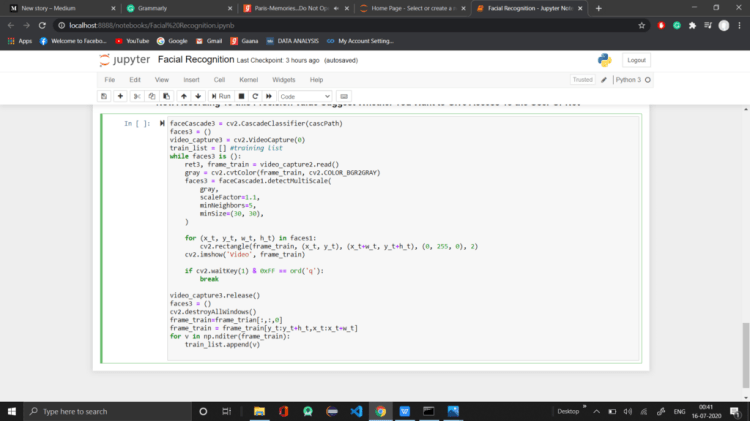
Now Coming To Train Your Model
Actually This Process Should be implemented When we Were Registering Faces, but this will become too much for now so I placed it here
So in Aspect Of Machine Learning, we are going to use a Classification Technique i.e. Logistic Regression(Sigmoid)
for This, We have to Train Our Model First
For This Run the Cell Below:-
Run this Cell for 7–8 Times and Every Time Add train_list to a 2-D Matrix Column Wise for Every iteration.
(Sometimes try to run with Different Faces and Mark Them with 0(Wrong) for Better Training.)
Suppose you run the cell for 7 times and stores the list in a 2-D Matrix You will get a Matrix Of Dimensions:-
[number of elements in the list: 7 ]
Create a respective [1:number of elements] matrix(TRAIN_Y) with Values 1 when you scanned your face and 0 when you used Different Faces.
Now Use Logistic Regression to Train You model By Iteration of Training Matrix (TRAIN_X) and The Result Matrix(TRAIN_Y) Column Wise.
Heyyyaahh !! Model Is Trained:
Now Every Time You Use This Facial Recognition Convert the Image to Respective List as we have Done Above, Then Use LogisticRegression.Predict() and Pass Your List In Predict Method.
After That If The Logistic Regression Model Shows 1 This Means Permission Granted and 0 For Permission Denied.
Face Presentation Attack Detection a.k.a Face Anti-spoofing
Face recognition is one of the most convenient biometric for access control. The wide popularity of face recognition can be attributed to ease of acquisition with cheap sensors, contact-less nature, high accuracy of algorithms, and so on. While everything is well and good there, the vulnerability to presentation attacks limits its use in safety-critical situations.
Imagine your phone locked with face recognition being unlocked by someone simply showing a photo or video of you in front of the phone. There you have it, its called a presentation attack (also known as spoofing attacks). The design of face recognition systems mostly optimizes for telling people apart, such a network may not be able to tell whether the face in front of it is real (bonafide)or an attack .
Before you take your phone to disable face recognition, there is good news. Researchers have been working on this problem for years, and there is some level of resistance built into commercial face recognition systems these days. The methods which can identify these attacks are known as presentation attack detection (PAD) methods, which is essentially classifying each image as real or spoof.
Here are a few images from publicly available attacks (Taken from [Paper]). Can you tell apart which ones are real and which ones are attacks?
As you can see it is not very easy to say whether they are real or not (Answers at the bottom of the page). It would become more and more difficult once we have better cameras and screens.
There are several publicly available datasets for doing PAD research. Most of them consider print and replay attacks.
This doesn’t mean the problem is solved. In fact, its very far from being solved. The main two challenges with PAD approaches are:
Unseen attacks
Most of the PAD methods treat the problem as a binary classification problem. But, it can be seen that the quality of attacks can evolve with the improved quality of capturing and display devices, which makes it an arms race. Also, creative attackers can come up with novel types of attacks (makeups, masks), etc to fool the PAD systems. It becomes difficult to detect attacks which has not been seen in training. In general, most of the methods fail against unseen attacks.
Cross-database performance
It can be seen that a lot of work in presentation attacks focus on cross-database performance. Methods, especially deep learning methods tend to overfit to the biases in a dataset, which might achieve good results in the intra-dataset scenario but could fail miserably when tested in a different dataset. It can be thought of as, the networks are learning some inherent biases in the datasets rather than learning the useful differences between real and spoof images. This is particularly important if we want to deploy a PAD system in real-world conditions.
Here is an implementation
Most of the recent state of the art methods are CNN based. Ideally, a frame-level PAD system should decide by just processing a single frame.
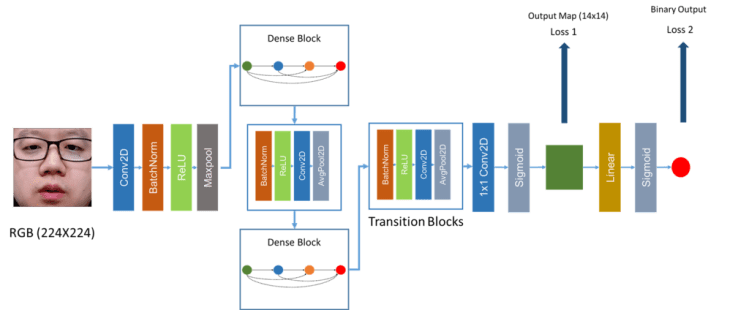
Here I introduce an introductory network for PAD. The architecture uses a densely connected neural network trained using both binary and pixel-wise binary supervision called DeepPixBiS.
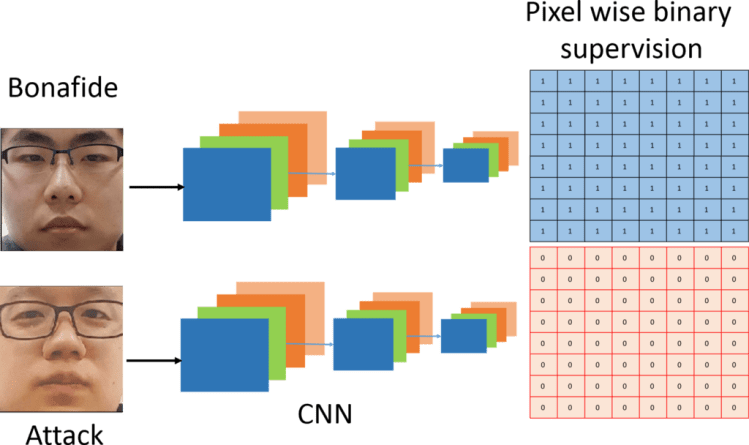
Here the idea is to predict the pixel /patch-wise labels of an image for PAD. The labels for real and attacks are shown below.
Pixel/patch wise labels for bonafide (real) and attack (spoof) samples.
For a fully convolutional network, the output feature map from the network can be considered as the scores generated from the patches in an image, depending on the receptive fields of the convolutional filters in the network. Each pixel/ patch is labeled as bonafide or attack. In a way, this framework combines the advantages of patch-based methods and holistic CNN based methods using a single network. For a 2D attack, we can consider all the patches have the same label. The advantage here is that the pixel-wise supervision forces the network to learn features that are shared, thus minimizing the number of learnable parameters significantly.
Big Data Jobs
The architecture is based on DenseNet, you can look at our open-source implementation if you would like to try it out.
The DeepPixBiS Architecture
We have seen that there are limits to what RGB only PAD can do. In the next article, we will focus on how to improve multiple channels of information to improve the results.
Answer to quiz: In each pair, the one on the left is real, and the other one is an attack.
The source codes (PyTorch) are available in the following link:
Rule-based systems and machine learning models are widely utilized to make conclusions from data. Both of these approaches have advantages and disadvantages. Several corporations are implementing and exploring tasks related to artificial intelligence to automate business processes, upgrade product improvement and to enhance market experiences. This blog provides some of the crucial points that should be considered before doing investment in any of the techniques. The correct AI strategy is very crucial for the development of the business. The emerging technologies such as machine learning and artificial intelligence contribute a lot in development and productiveness. Machine learning certification provides you a deep insight into the industry. This blog provides a guide for businesses to debate machine learning vs rule-based artificial intelligence.
What is rule-based Artificial Intelligence?
A system that accomplishes artificial intelligence through a rule-based model is known as rule-based AI systems. There is no doubt that the demand for artificial intelligence developer is increasing day by day. A rule-based artificial intelligence produces pre-defined outcomes that are based on a set of certain rules coded by humans. These systems are simple artificial intelligence models which utilize the rule of if-then coding statements. The two major components of rule-based artificial intelligence models are “a set of rules” and “a set of facts”. You can develop a basic artificial intelligence model with the help of these two components.
What is Machine learning?
A system that accomplishes artificial intelligence through machine deep learning is known as a learning model. The machine learning system defines its own set of rules that are based on data outputs. It is an alternative method to address some of the challenges of rule-based systems. ML systems only take the outputs from the data or experts. ML systems are based on a probabilistic approach. ml certification provides practical training of large datasets.
Difference between rule-based AI and machine learning
The key difference between rule-based artificial intelligence and machine learning systems are listed as below:
1. Machine learning systems are probabilistic and rule-based AI models are deterministic. Machine learning systems constantly evolve, develop and adapt its production in accordance with training information streams. Machine learning models utilize statistical rules rather than a deterministic approach.
2. The other major key difference between machine learning and rule-based systems is the project scale. Rule-based artificial intelligence developer models are not scalable. On the other hand, machine learning systems can be easily scaled.
3. Machine learning systems require more data as compared to rule-based models. Rule-based AI models can operate with simple basic information and data. However, machine learning systems require full demographic data details.
4. Rule-based artificial intelligence systems are immutable objects. On the other hand, machine learning models are mutable objects that enable enterprises to transform the data or value by utilizing mutable coding languages such as java.
Big Data Jobs
When to utilize machine learning models
Pure coding processing
Pace of change
Simple guidelines don’t apply
When to utilize rule-based models
Not planning for machine learning
Danger of error
Speedy outputs
Conclusion
Machine learning and rule-based models have their own advantages and disadvantages. It totally depends on the situation that which approach is appropriate for the development of business. Several business projects initiate with a rule or excerpt based models to understand and explore the business. On the other hand, machine learning systems are better for long terms as it is more manageable to constant improvement and enhancement through algorithm and data preparation. As the world of large datasets increases, it’s time to glance beyond binary outputs by utilizing a probabilistic rule rather than a deterministic approach.
To get instant updates about emerging technologies and explore more about ai certification, you can check out the Global Tech Council website.
Data Mechanics is developing a free monitoring UI tool for Apache Spark to replace the Spark UI with a better UX, new metrics, and automated performance recommendations. Preview these high-level feedback features, and consider trying it out to support its first release.
This article provides a glimpse into the available tools to work with CSV files and describes how kdb+ and its query language q raise CSV processing to a new level of performance and simplicity.
Also: 5 Obscure #Python Libraries Every Data Scientist Should Know; 9 Skills That Separate Beginners From Intermediate #Python Programmers; Don’t miss your copy of Learning Spark, 2nd Edition @databricks ; How Much Math do you need in Data Science?