Honestly? I don’t know. But I do think WebAssembly is a good target for ML/AI deployment (in the browser and beyond).
Originally from KDnuggets https://ift.tt/2WJVCJR

365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Originally from KDnuggets https://ift.tt/2WJVCJR

Welcome to the final part of this multiple part series where we discuss five pioneering research papers for you to get started with 3D…
Continue reading on Becoming Human: Artificial Intelligence Magazine »

Why is my dashboard working so slowly? Everyone must have faced this problem many times. People who are designing dashboards with utmost care will also face this issue.
The first approach we should try after getting to this stage is Performance Recording in Tableau BI Development.
Tableau happens to give a very nice option for the developers to see all the processes that are happening in the background when you perform an action on your dashboard.
It gives you a dashboard with all the details that you will need to understand the performance of your dashboard and when your dashboard is hitting a steep curve in performance.
1. Natural Language Generation:
The Commercial State of the Art in 2020
4. Becoming a Data Scientist, Data Analyst, Financial Analyst and Research Analyst
So to get the performance recording started for your workbook you have to follow the below steps:
1. First, make a list of actions or the worksheets which are taking more time to load.
2. Open the workbook
Go to Help -> Settings and Performance -> Start Performance Recording
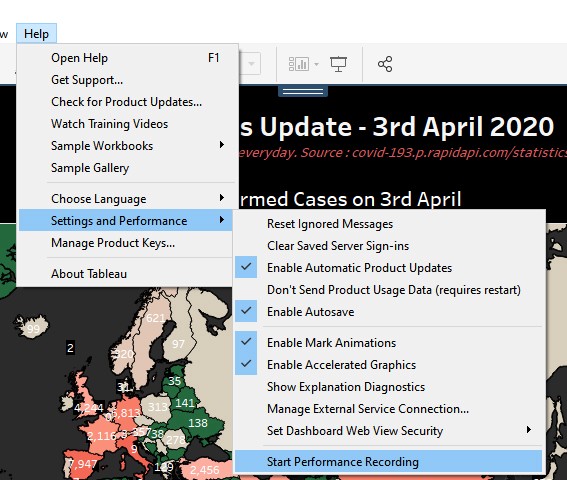
3. Perform the activities that you have listed in step 1.
4. Stop the recording
Go to Help -> Settings and Performance -> Stop Performance Recording

5. Now another workbook named ‘Performance Recording’ will open automatically with below tabs:

Now you have created a performance recording for your tableau workbook. This workbook will let us know about where our workbook is lagging in performance.

So the Performance Summary tab in this workbook will have below information and what does these KPIs mean that we will discuss:
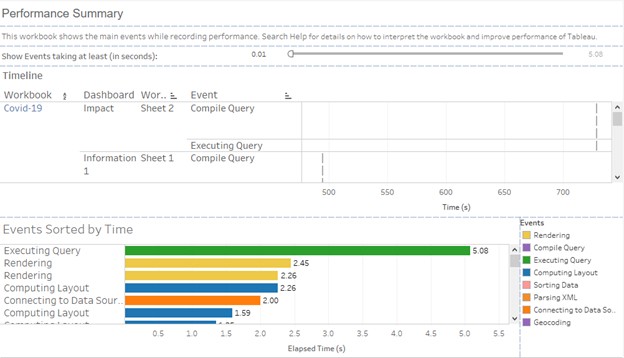
Above is the sample screenshot of a performance recording.
There are 3 sections in this dashboard.
1. Timeline: This view explains the performance for each worksheet and the event occurred for it.
It has 4 fields like Workbook, Dashboard, Worksheet, Event and time taken for the event.
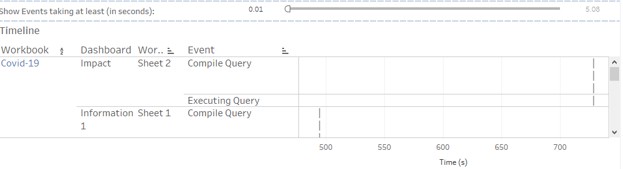
1. Events:
Below are the events that mainly describe what the workbook does in background:
a. Rendering:
Rendering tells you the time taken for the vizQL to load a particular visualization.
b. Compile Query
This is the amount of time spent by Tableau in generating the queries. It depends on the calculations that you have used. If you have many calculated fields and complex LODs or calculations, the compile query time will be high. To reduce this time, you can make your workbook simple and remove some calculated fields.
c. Execution Query
This is the time taken by the data source query to get executed. For a database connection the performance can be improved by adding some performance to your data base or by optimizing your query so that it takes less time. For an extract you might want to remove some columns that you are not using or change some joins or remove some tables which you are not using.
d. Computing Layout
Computing layout is the time taken for visualizing all the layouts. You can reduce the number of views in a particular dashboard to reduce this time.
e. Sorting Data
This is the time taken for the data in your view to get sorted. If you have nested sorting or a large number of items to be sorted or you can have some complex calculations which you are using for sorting the data.
f. Connecting to Data Source
This is the time taken by the tableau to connect to the data source. If you are using a connection to Database, you can check your network speed or you can connect with your data base admin to see if you can improve this.
g. Geocoding
Geocoding is the time taken on the geographical data from your view. If you have a huge number of items using the Geocoding, then your workbook performance will get hampered.
2. Query
IF you try to click on ‘Executing Query’ you will see a query in the Query tab on the same summary dashboard.

You can see if it possible to optimize this query so that the performance will get improved.
Detailed Tab:
Detailed tab gives you the detailed information about all the events
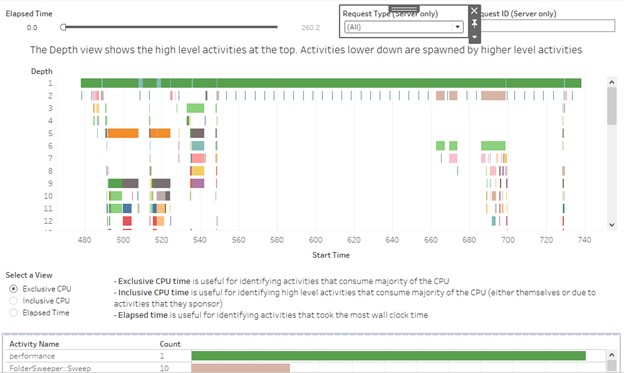
Depth gives us the information about the activities that are performed under each of the events like changing a filter or loading a visualization like Exclusive Time, Inclusive time and Elapsed Time.
Exclusive CPU time helps in understanding those activities which took major of the time.
Inclusive CPU time is time taken by the activities including CPU.
Elapsed time is the time that has been taken by small activities on normal clock.




What is Performance Recording in Tableau? was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.

No wonder, Artificial Intelligence has become the latest buzzword in the tech world today. The technology has now plunged into the…
Continue reading on Becoming Human: Artificial Intelligence Magazine »
Originally from KDnuggets https://ift.tt/2EarqRF
Originally from KDnuggets https://ift.tt/39uBW1P
source https://365datascience.weebly.com/the-best-data-science-blog-2020/apache-spark-cluster-on-docker
Originally from KDnuggets https://ift.tt/30uP1E4
Originally from KDnuggets https://ift.tt/39hf8lO
The lack of culturally reliable machine-ready datasets will prohibit us from creating AI products and services that are relevant to more than the status quo.

by Davar Ardalan and Kee Malesky
As a tech company, designing the cultural storytelling bot, Sina, we wanted to better understand the data landscape before training our AI. In early July, together with Topcoder, we launched the Women in History Data Ideation Challenge. The results confirm some of our assumptions and fears: We can’t build a robust and culturally rich chatbot without better datasets and machine-ready content.
The goal of our ideation challenge was to get public data sources of women throughout history and suggest how that data could be used to gain new insights for AI products and solutions with a focus on women. In our case, we wanted to understand how to source stories on women for our chatbot Sina. The primary deliverable was to get a well thought-out overview of what is possible, what relevant data can be found and where, and how the data should be collected.
We are grateful to our sponsors and AI advisors who have been on this journey with us every step of the way. Our team has reviewed the 7 winning submissions. The results greatly expanded our understanding of the possibilities and imperatives facing us as we proceed. Here’s what we know to be true:
Historic gender and cultural biases perpetuate in the ecology of AI;
Current classification of gender, ethnicity, and race in Wikipedia is flawed and lacking;
Improved data ecologies that account for gender, culture, and history to create better algorithms are vital for popularizing future AI products.
We know that AI systems have been designed with inherent gender and racial biases. (You can track examples of bias in AI here.) This means that as more AI products and solutions are created, more historic cultural and gender biases will continue to be mapped into those AI systems.
Reacting to the data ideation challenge, Clinton Bonner, vice president of marketing at Topcoder, says that “Greater cultural representation and understanding built into machine learning will help create more effective AI, and that stands to benefit all. It starts with the action and partnership IVOW is driving. Topcoder is proud to be an important part of how IVOW is executing on their purpose and the impact we can have together.”

Summary Findings from Seven Winning Challenge Participants:
Not surprisingly, most of the Topcoder challenge participants used Wikipedia as a source for information on women in history and fiction. This in and of itself proves the limits of content we can draw on. Wikipedia has some 6 million articles and is a viable base for data collection and training data for future NLP-Machine Learning based data exploration. Having said this, most participants acknowledged the difficulties with Wikipedia — in particular, biases, poor writing, and boring raw facts; as well as the lack of global cultural references.
1. Natural Language Generation:
The Commercial State of the Art in 2020
4. Becoming a Data Scientist, Data Analyst, Financial Analyst and Research Analyst
On Gender Bias:
Word embeddings trained on Wiki disproportionately associate male terms with science terms, and female terms with art terms, which could amplify stereotypes and lead to replicating biases. This was also shown in this 2016 report, “Semantics derived automatically from language corpora contain human-like biases.”
On Classification of Culture & Ethnicity:
The results show that even with many words joined under ontology and property in the query, the fields CulturalSource, TimePeriod, and Relations were still hard to fully populate. This suggests the necessity to use machine learning to extract values for these fields from TextualAbstract. Some applicants suggested creating categories or keywords, based on location, language, occupation, etc.
The significance of proper tagging was noted in one submission, an important consideration given the recent news about MIT’s racist, misogynistic database (more below). Another suggestion was to use machine learning to enable AI to distinguish between “important” and “unimportant” sentences in a text, as a way to write a better profile.
On Current Datasets:
A few of the applicants used other sources (Pantheon, Women in Hollywood, Fortune, etc.), which was encouraging since we know that Wikipedia is not sufficient. Pantheon datasets contain names of many historical female figures from various domains (politics, science, culture, sports, etc), with their cultural background (when and where they were born). For each person in the dataset, a short summary is collected from the corresponding Wiki article.
However, overall, in the case of “women in history,” Pantheon and Wikipedia mainly include well-known women in history, and famous people’s entities are subject to a much more intensive peer-review process, which can result in increased accuracy of information over time. But this also means that there are many cultures which are not properly documented because information about them on the web is insufficient. We want and need to collect data not just on famous women, but also on obscure figures from history, fiction, and mythology.
In addition, one of the sample women in history datasets gathered for this competition included the occupation for “pornographic actress” with 174 names included in a sample of 13,000+ famous women. This also indicates how critical it is to be clear about what emphasis we want to bring to our machine-readable AI datasets about women in history and their contributions. For context, this same dataset included the names of 7 Archeologists, 10 Anthropologists, 11 Architects, 211 Models and 3,950 Actors.
What’s next? How can we collaborate on this work?
For those of us marching into automation, we must understand that in many ways, the current data ecology is incomplete, flawed, racist, and derogatory. That lack of diverse data and the prevalence of biased data hampers innovation and causes significant setbacks for future AI products and solutions.
Most recently, MIT announced that its 80 million “tiny images” dataset would be taken down immediately. According to the authors of the dataset, “Biases, offensive and prejudicial images, and derogatory terminology alienates an important part of our community — precisely those that we are making efforts to include. It also contributes to harmful biases in AI systems trained on such data.” The statement, issued on June 29, further acknowledged that the presence of such prejudicial data hurts efforts to foster “a culture of inclusivity in the computer vision community.”
Future automated decisions cannot be made based on current data ecosystems.

Putting Women on the AI Map: Phase 1 of our data ideation challenge with Topcoder proves that we must create machine-ready datasets focused on gender and culture so that AI products and services, like ours, can be more inclusive. We are actively designing a data focus for Phase 2 and looking for sponsors. The sponsorship packets are here.
Whitepaper: We are working on a whitepaper on this ideation challenge and will share the results in more detail by the end of August.
Events: We will be speaking about early results on Wednesday, July 22, as part of our Cultural AI and Brands virtual event, and also on September 8 as part of the Women in AI Global Summit.

If you’re interested in supporting us with research in this area please be in touch Davar@ivow.ai.
IVOW AI is an early stage startup focusing on cultural intelligence in AI. We address a much-needed market: the convergence of artificial intelligence to preserve culture with the need for marketers to better understand culture. We are part of WAIAccelerate, the Women in AI accelerator program; a KiwiTech Portfolio company; and incubating at We Work Labs in DC as we build our MVP.
Relevant Resources:
Women in History Data Ideation Challenge
Teaching Machines Through Our Stories — Women in History Ideation Challenge
Bias in AI: Examples Tracker From U.C. Berkeley Haas Center for Equity, Gender and Leadership
MIT Takes Down 80 Million Tiny Images data set due to racist and offensive content
Talking about Bias in AI with your Team With Case Study
Important Types of Bias to Tackle When Building AI Tools
Venture Beat: How Google Addresses ML Fairness and Eliminates Bias in Conversational AI Algorithms
Gender Shades Intersectional Accuracy Disparities inCommercial Gender Classification
Why Everything From Transit to iPhones Is Biased Toward Men
Diversity in AI is not your problem, it’s hers
StereoSet measures racism, sexism, and other forms of bias in AI language models
Gender Shades Intersectional Accuracy Disparities inCommercial Gender Classification
Why Everything From Transit to iPhones Is Biased Toward Men
Invisible Women: Expose Data Bias In A World Designed for Men
AI Fail: To Popularize and Scale Chatbots, We Need Better Data was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
How would one grant rights to machines? The matter still can’t be consulted with those concerned. Artificial intelligence will not tell us whether or not it feels people’s existing legal system is treating it well. So we have to manage alone and decide for it.
In late July 2019, the world learned that the company Neuralink was close to integrating the human brain with a computer. The first interface hoped to enable the feat was unveiled. We may thus be in for an incredible leap in expanding our cognitive abilities. The consequences of such a leap would be varied and we would certainly not avoid having to make unprecedented legal and ethical choices. In view of such a breakthrough, the question about machine rights or humanoid becomes all the more relevant. Any human brain combined with processors will require special protection.
For transhumanists, this matter is of utmost importance. Their view is that technology deserves special respect that is in no way inferior to that given to humans. Since, as a species, we are facing an environmental disaster, we should seek to rescue ourselves by entering into a symbiosis with machines. The humanoid beings that come out of such a symbiosis (as a combination of living organisms and electronic systems) could survive civilizational catastrophes and break free from the limitations of biology. In postulating the conferral of rights on machines, transhumanists are convinced that the future will see the birth of a new kind of consciousness. The beings that will populate our planet will not only feel. They may also have their own consciousness. And can a conscious being — regardless of its kind — be destroyed with impunity? Wouldn’t that be murder?

1. Natural Language Generation:
The Commercial State of the Art in 2020
4. Becoming a Data Scientist, Data Analyst, Financial Analyst and Research Analyst
The machine rights question no longer seems absurd once we realize that we grant rights to animals, and that businesses enjoy them too. The key issue is how far-reaching such laws should be. Nobody in their right mind would demand legal protection for a vacuum cleaner or iron. Perhaps then this would only concern technological entities with a certain degree of complexity. These could be devices capable of performing the kinds of actions we see as intellectual activity. Imagine an industrial robot that suddenly breaks down. An investigation reveals that it has been damaged intentionally. Sometime later, an offender is found who had access to the machine’s software. The company sustains losses and the perpetrator is legally liable. But then there might be other considerations here that will matter in the future. Assuming the robot is a sophisticated mechanism and that its operation relies on reasoning algorithms (some of which can write their own source code even today), the damage would be an act directed against a being and, as such, would constitute a breach of certain rights that are largely analogous to human.
The fact that these considerations no longer belong in science fiction is evidenced by the resolution enacted by the European Parliament in 2017 that will grant the status of “electronic personality” to particularly advanced robots. The precept was justified by the notion that enterprises and other organizations can exercise some of the rights associated with humans and enjoy the status of corporate personality.
There is another interesting aspect to the whole affair. Since we agree that machines really deserve certain rights, they should consequently be responsible for their decisions and actions. I will use the example of self-driving vehicles. Based on machine learning, an autonomous car makes a number of independent choices on the road. These affect the driver, passengers and other road users. Anticipating a potential accident, the algorithm must decide who to protect first — the driver, the passengers or the pedestrians. To make such determinations, an autonomous vehicle needs to adopt a certain value system, and make ethical choices that apply to people, even if it is unaware of it the way a human would. Briefly put, one way or another, it becomes accountable from the human viewpoint. Another matter though is how to enforce such accountability in the case of an accident? Do we continue to hold the designers of the algorithms used to produce the car accountable? Or do we presume that the car is not only endowed with privileges for its protection but also has obligations that require it to respect the rights established by people.
We are now faced with the so-called black box dilemma. I am referring to circumstances in which people no longer understand the principles that drive intelligent technologies in the field of artificial intelligence. Such technologies grow independent causing some to believe that things are slipping out of our control. And they can get worse. We may not be able to understand why AI weapons begin to take down certain targets, why chat bots suggest certain loan solutions and not others, and why voice assistants give us one answer but not another. Will the liability of devices for their actions be a particularly pressing issue? Cynics say that machine rights are only conceived for the convenience of the creators of AI devices who themselves want to avoid responsibility for what they make and for the situations that their creations may cause.
I am aware of the sheer amount of speculation there is in our approach to this problem and how we keep asking more and more questions. I also think that the ethical implications of robots being brought to our workplaces, the army, the police and the judiciary, will get ever more complex. This means, among others, that we need to tackle such issues as our responsibility for ourselves and for the machines that for now are unable to do it themselves.
Works cited:
CNET, Stephen Shankland, Elon Musk says Neuralink plans 2020 human test of brain-computer interface. “A monkey has been able to control a computer with his brain,” Musk says of his startup’s brain-machine interface, Link, 2019.
FORBES, Sarwant Singh, Transhumanism And The Future Of Humanity: 7 Ways The World Will Change By 2030, Link, 2020.
SLATE, RACHEL WITHERS, The EU Is Trying to Decide Whether to Grant Robots Personhood, Link, 2018.
Don’t kill a humanoid: do machines deserve to have rights? was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
