Understanding the data is the first port of call.
Originally from KDnuggets https://ift.tt/3dlPnDA
source https://365datascience.weebly.com/the-best-data-science-blog-2020/deep-learning-is-becoming-overused

365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Originally from KDnuggets https://ift.tt/3dlPnDA
source https://365datascience.weebly.com/the-best-data-science-blog-2020/deep-learning-is-becoming-overused
Originally from KDnuggets https://ift.tt/3lXJSyO
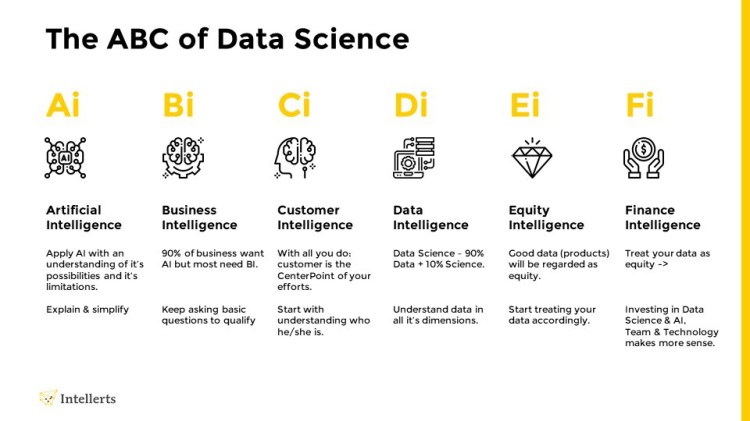
Everyone is jumping on the AI bandwagon, or is on the road to mastering machine learning. Companies want algorithms. They may not understand why, but are afraid of missing out on what everyone else is going after.
In most cases, companies need business intelligence, i.e. those data analysis strategies and technologies to extract insights from their business information. In other words: you need information to run your business. That seems like a simple request, but is, in reality, a continuous challenge.

OK, let’s assume your IT assets are well organized, and your tech teams are leading the way. But what about your customer focus? Many forget this vital consideration but every business starts with a customer and a requirement to serve them better. Make sure your customer sits at the heart of all your endeavors.
This is where most of the hard work happens. Data is regularly flouted as the new corporate oil, but our understanding of it is indeed like crude oil. Namely, it is somewhere deeply hidden. Actually, the situation is often worse than this: we don’t know how it’s structured, we don’t know where it is, how it’s connected and what the real quality of our data is.
Try asking your teams this simple question: do we have a data model for our company? You may be surprised by their answer…
1. Top 5 Open-Source Machine Learning Recommender System Projects With Resources
4. Why You Should Ditch Your In-House Training Data Tools (And Avoid Building Your Own)
The first company I worked for was a mail order company (for millennials: that was when commerce was done using paper and snail mail…in the pre-internet age). When that company was sold, the price was based on the number of customer records, i.e. the buyer just bought the customer database. To truly be a data-driven company, you must now understand that an individual customer record requires investment to acquire and to maintain, and that value is only created by capturing your relationship with those customers.
If you come this far, your investment decisions are relatively easy. You must regard your customer data base as a company asset. In doing so, this provides a sound basis for your decision making with regards to your AI, BI and (Big Data) technology investments. Because that is all that’s left for you to do… Invest in team and technology.




The ABC of Data Science was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Via https://becominghuman.ai/the-abc-of-data-science-ba410c697c23?source=rss—-5e5bef33608a—4
source https://365datascience.weebly.com/the-best-data-science-blog-2020/the-abc-of-data-science
This Part is the continuation of the Deploying AI models Part-3 , where we deployed Iris classification model using Decision Tree Classifier. You can skip the training part if you have read the Part-3 of this series. In this article, we will have a glimpse of Flask which will be used as the front end to our web application to deploy the trained model for classification on Heroku platform.
The following packages were used to create the application.
1.1.1. Numpy
1.1 .2. Flask, Request, render_template from flask
The dataset is used to train the model is of iris dataset composed of 4 predictors and 3 target variable i.e. Classes
Predictors: Sepal Length, Sepal Width, Petal Length, Petal Width
Target : Setosa [0], Versicolor[1], Verginica[2]
Dataset Shape: 150 * 5

For training the model we followed the following procedure:
Data Split up: 8:2 ie. 80% training set and 20% for the test set
Model: Ensemble- RandomForestClassifier with n_estimators=500)
Saving Model: Saved in the pickle file
Below is the code for the training the model.
import sklearnimport
sklearn.datasetsimport sklearn.ensemble
import sklearn.model_selection
import pickle
import os
#load data
data = sklearn.datasets.load_iris() #Split the data into test and
traintrain_data, test_data, train_labels, test_labels = sklearn.model_selection.train_test_split(data.data, data.target, train_size=0.80)
print(train_data,train_labels)
#Train a model using random forestmodel = sklearn.ensemble.RandomForestClassifier(n_estimators=500)model.fit(train_data, train_labels)
#test the model
result = model.score(test_data, test_labels)
print(result)
#save the model
filename = ‘iris_model.pkl’
pickle.dump(model, open(filename, ‘wb’))
For feeding the value in the trained model we need some User Interface to accept the data from the user and feed into the trained neural network for classification. As we have seen in the sectioin 1.2 Dataset where we have 4 predictors and 3 classes to classify.
File name: index.html should be placed inside templatre folder.
<h1>Sample IRIS Classifier Model Application</h1>
<form action=””method=”post”>
<input type=”text” name=”sepal_length” placeholder=”Sepal Length” required=”required” />
<input type=”text” name=”sepal_width” placeholder=”Sepal Width” required=”required” />
<br>
<br>
<input type=”text” name=”petal_length” placeholder=”Petal Length” required=”required” />
<input type=”text” name=”petal_width” placeholder=”Petal Width” required=”required” />
<br>
<br>
<br>
<button type=”submit” class=”btn btn-primary btn-block btn-large”>Submit Data</button> </form>
<br>
<br>
The above shown code is for taking the input from the user and display it in the same page. For this we have used action=”” this will call the prediction fubtion when we will submit the data with the help of this form and to render the predicted output in the same page after prediction.
1. Top 5 Open-Source Machine Learning Recommender System Projects With Resources
4. Why You Should Ditch Your In-House Training Data Tools (And Avoid Building Your Own)
File name: app.py
import numpy as np
from flask import Flask, request, jsonify, render_template
import pickle
import os
#app name
app = Flask(__name__)
#load the saved model
def load_model():
return pickle.load(open(‘iris_model.pkl’, ‘rb’)) #home
page@app.route(‘/’)
def home():
return render_template(‘index.html’)
@app.route(‘/predict’,methods=[‘POST’])
def predict():
‘’’ For rendering results on HTML GUI ‘’’
labels = [‘setosa’, ‘versicolor’, ‘virginica’]
features = [float(x) for x in request.form.values()]
values = [np.array(features)] model = load_model()
prediction = model.predict(values)
result = labels[prediction[0]]
return render_template(‘index.html’, output=’The Flower is
{}’.format(result))
if __name__ == “__main__”:
port=int(os.environ.get(‘PORT’,5000))
app.run(port=port,debug=True,use_reloader=False)
In the python script, we called the index.html page in the home() and loaded the pickle file in load_model () function.
As mention above we will be using the same index.html for user input and for rendering the result. when we will submit the form via post method the data will be send to the predict() via action=”” and predict function from the app.py file and it will be processed and the trained model which we have loaded via load_model () function will predict and it will be mapped the respective class name accordingly.
To display the data we will render the same template i.e. index.html. If you would have remember we used keyword in the index.html page we will be sending the value in this field after prediction by rendering in the index.html page by the following Flask function.
render_template(‘index.html’, output=’The Flower is
{}’.format(result))
where index.html is the template name and output=’The Flower is
{}’.format(result) is the value to be rendered after prediction.
We need to create the require.txt file which contains the name of package we used in our application along with their respective version. The process of extracting the requirement.txt file is explained in the Article: Deep Learning/Machine Learning Libraries — An overview.
For this application below is the requirement.txt file content.
Flask==1.1.2
joblib==1.0.0
numpy==1.19.3
scikit-learn==0.23.2
scipy==1.5.4
sklearn==0.0
Along with requirement.txt, you need the Proctfile which calls the main python script i.e. script which will run first. For this Webapplication the Proctfile content is below.
web: gunicorn -b :$PORT app:app
app -->is the name of the python scripy i.e. app.py
It is a PaaS platform which supports many programming languages. Initially in 2007 it was supporting only Ruby programming language but not it supports many programming language such as Java, Node.js, Scala, Clojure, Python, PHP, and Go. It is also known as polyglot platform as it features for a developer to build, run and scale applications in a simillar manner across most of the language it was acquired by Salesforce.com in 2010.
Applications that are run on Heroku typically have a unique domain used to route HTTP requests to the correct application container or dyno. Each of the dynos are spread across a “dyno grid” which consists of several servers. Heroku’s Git server handles application repository pushes from permitted users. All Heroku services are hosted on Amazon’s EC2 cloud-computing platform.
You can register on this link and can host upto 5 application with student account.
In above, section we have constructed our web application successfully and now it’s time to deploy it. For deploying we have two option Deploying via Github and Deploying via Local System. In this article we will see how we can deploy any ML/DL model using Heroku CLI.
The local repository should look like the below image:

As mentioned in the section 2, after login in the heroku platform follow the below step:
Step1: Create new app and name the application and click on create app. You will land on the below page.
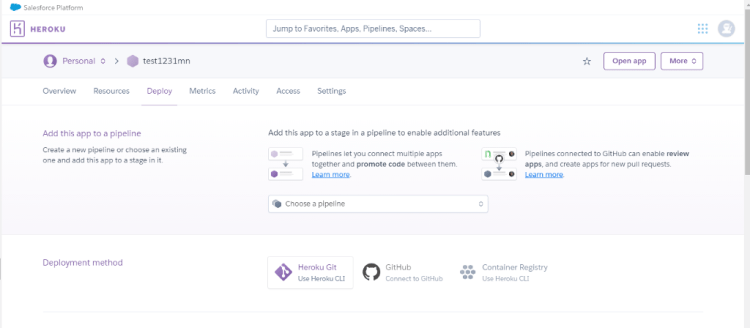
In Fig.2 you can see, we have 3 option by which we can deploy, in this article we will use the option which allows us to deploy the application directly with ourGithub repository.
Note: for Installation visit this Link.
Step2: Select heroku CLI from the available option to deploy the application to heroku.
Step3: Navigate to the directory where the project file is kept.
Command: cd “Path of the directory”
Step4: Initialise the directory with git.
Command: git init
Command: heroku git: remote -a “Name of the Application created”
The above commands will create the git reposisoty in your local system. For deployement follow tye below process:
Step5: We need to add all our filled so that it can be tracked for any changes we will do in later stages of our project.
Command: git add .
Step 6: Commit the repository.
Command: git commit -am “version 1”
Step 7: Push the repository into Heroku.
Command: git push heroku master
Congratulation!! you have sucessfully deployed an web application via Heroku CLI.
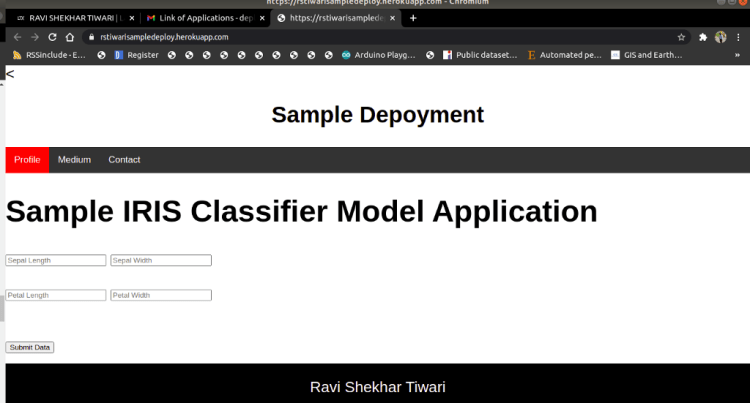
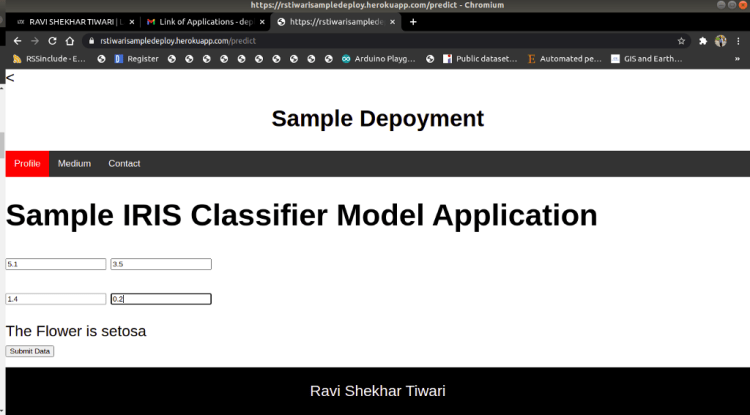
The overview of the deployed web application with Iris Application: Link is shown below.
As we say “Car is useless if it doesn’t have a good engine” similarly student is useless without proper guidance and motivation. I will like to thank my Guru as well as my Idol “Dr. P. Supraja”- guided me throughout the journey, from the bottom of my heart. As a Guru, she has lighted the best available path for me, motivated me whenever I encountered failure or roadblock- without her support and motivation this was an impossible task for me.
Extract installed packages and version : Article Link.
Notebook Link Extract installed packages and version : Notebook Link
How to Deploy AI Models? — Part 1 : Link
How to Deploy AI Models? — Part 2 Setting up the Github For Herolu and Streamlit : Link
YouTube : Link
Deployed Application: Link
Iris Application: Link
If you have any query feel free to contact me with any of the -below mentioned options:
Website: www.rstiwari.com
Medium: https://tiwari11-rst.medium.com
Google Form: https://forms.gle/mhDYQKQJKtAKP78V7
How to Deploy AI models ? Part 5- Deploying Web-application on Heroku-CLI was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Artificial intelligence is concerned with the creation of intelligent machines. It is undoubtedly one of the most important inventions of mankind, because it combines important future technologies and will accelerate them. It can also help us to master the greatest challenges of our time.
Already today, algorithms using AI are firmly integrated into our everyday life. For example in route calculation with Google Maps, in conversations with Alexa/Siri or our personalized Netflix recommendations.
However, artificial intelligence is (still) far from being a general problem solver. Its applications are currently limited to individual areas in which it is constantly improving.
“The rise of powerful AI will be either the best, or the worst thing, ever to happen to humanity.” — Stephen Hawking
The artificial intelligence known from science fiction movies such as Ex Machina, Blade Runner or Star Trek, which dominates our world, is thus far from being reality. However, anyone who only deals with the subject a little will quickly recognize the opportunities, but also the risks, of this future technology. It is the motor for perhaps the greatest change in human history …
To answer the question, when a machine is intelligent, the Turing test is used in general. Simplified: A machine is to consider as intelligent, if its behavior (e.g. in chat-answers) is not distinguishable from a human being.
A milestone in this context is the passing of the Turing Test of Google Duplex in May 2018. The further development of the Google Assistant arranged a hairdresser appointment without her counterpart noticing that she was talking to a machine on the phone. Creepy? This is just the beginning.
People make around 20,000 decisions a day. Most of them unconsciously. What we decide for depends strongly on our past experiences (the data).
But what is everyday life for us is incredibly difficult for machines. Over the past 70 years, researchers in the field of artificial intelligence have made considerable progress, opening the door to many areas. For example, computer science, with its complicated computer models, is just as much a part of AI as the neurosciences, which have brought a great deal of knowledge from the human brain — in the form of neural networks, for example — to the study of smart machines. The results are self-learning machines. But learning also involves the reception of information, which confronted scientists with questions about how we communicate with each other and generally process information. Questions upon questions.
1. Top 5 Open-Source Machine Learning Recommender System Projects With Resources
4. Why You Should Ditch Your In-House Training Data Tools (And Avoid Building Your Own)
The main areas of artificial intelligence can be summarized as follows:

In addition, a general distinction is made between weak AI and strong AI.
Weak AI (also called Narrow AI) is limited to individual application problems, whereby they are capable of self-optimization or learning within their limited problem. All AIs existing today fall into this category. Examples can be found in speech recognition via Siri & Alexa, navigation systems like Google Maps but also in the individualized control of advertising.
Strong AI (or general AI) is also called super intelligence and fulfills all the clichés of Hollywood movies. The goal is to achieve or even exceed the same intellectual abilities of people. Such artificial intelligence no longer acts only reactively, but of its own accord, intelligently and flexibly.
Artificial intelligence in the form of intelligent machines is not a specter of the future! For many people, it is already usable in the here and now — be it with Google Maps navigation, Facebook’s news feed or a Spotify playlist personalized for you.
It’s important to make a distinction here: We’re only talking about “weak” AI here. All of our artificial intelligences in 2020 are to be classified as weak. They are only applicable to individual application areas. A strong AI, on the other hand, knows everything, can do everything and acts on its own initiative. It is superior to humans in every respect. Such a thing exists (so far, fortunately) only in our imagination. After all, would you trust the same people who demonstrated against Corona security measures during the Corona pandemic to make rules for AIs? I have my doubts if we are ready for that.
“A year spent in artificial intelligence is enough to make one believe in God.”
– Alan Perlis
In this article, we’ll take a look together at some of the most important areas of our lives and how AI could disrupt them. One thing in advance: The future will be incredible — whether incredibly good or incredibly bad remains to be seen.
The ideal area of application for AI is the analysis and recognition of patterns in large amounts of data. AI systems can make predictions after recognizing the patterns — in the meantime better than humans. Among other things, this opens up the possibility of automating everyday tasks.
There are hardly any limits to the use of artificial intelligence. The first applications of simple AI are already firmly integrated into our everyday lives — often without us noticing. But what potential does the new technology offer beyond that?
As the saying goes, “You never stop learning.” Yet our current education system has changed little over the past decades, learning from the changes in our world. Most of the time, someone still stands in front and talks. The rest have to listen. On average, there are 65 students per professor in Germany. At the elementary school, there are “only” 16 students per teacher. This makes it almost impossible to promote the strengths and weaknesses of the students individually. In addition, not everyone learns in the same way (keywords: visual, auditory, kinesthetic, communicative) and not at the same time of day.

However, it has been recognized that digitization is not a passing fad. Providing funding alone is not enough, however, as the DigitalPakt’s €5 billion scope makes clear. The digitization of the education system in Germany is already failing because many of the teachers do not even have e-mail addresses. In addition, many schools in this country are still WLAN-free zones.
But leaving aside these “teething troubles,” the education system — along with its students and teachers — is poised for a never-before-seen wealth of fascinating opportunities.
Pupils/Students
Teachers
The possibilities are fabulous! Teachers are given powerful tools through artificial intelligence to infect learners with their knowledge and give them a lifetime of opportunities. That these are no longer just fantasies is shown by our research today. Startups like Knewton, Century Tech and Thinkster Math are already creating the education system of the future that learners can look forward to.
In healthcare, the three areas of diagnosis and treatment, medical imaging and health management are leading the way in the use of artificial intelligence. That our system needs support is shown by the data: By 2050, one in five Europeans will be over 65.
A lot of medical data is already available today. However, this data is hardly used and is often not accessible to patients. This applies both to the selection of doctors and to patients’ own medical records. Another problem is administration. Many appointments canceled at short notice remain vacant, while new patients have to prepare for long waiting times. There is an additional significant workforce gap in the European healthcare sector.
Artificial intelligence will be able to take over adminstrative tasks such as appointment management, make predictions about expected treatments and maintain (digital) patient records in the short term.
In addition, AI will assist physicians such as nurses with treatment. Artificial intelligence can use image recognition in combination with Deep Learning to diagnose diseases early (see freenome and PathAI) and make recommendations to physicians. In addition, AI can be used to treat diseases preventively. In biotechnology, AI is generating new compounds and testing them at speeds not previously possible. Researchers at MIT, for example, developed AI that can identify new antibiotics. But startups BenevolentAi and Insitro are also conducting research in this area.
The goal of artificial intelligence in healthcare is to create freedoms so that doctors and nurses can be brought closer to patients and their individual treatment. The tasks will undoubtedly change, but the jobs will become more important than ever.

The fact that environmental pollution is very advanced, our cities are overcrowded and thousands of traffic deaths occur every year due to human error is forcing people to rethink. Hardly any other topic has been as hyped in recent years as mobility. The field of autonomous driving in particular is very popular with the public, not least thanks to Elon Musk’s Tesla.
One future scenario could be that people will no longer want to leave their vehicle unused 95 percent of the day. They could switch to car-sharing providers whose vehicles can use machine-learning prediction models to calculate expected usage and thus autonomously meet demand in cities. The free space created by fewer and fewer vehicles could be redesigned and used more efficiently in the smart cities of the future.

In marketing & especially in e-commerce, market leaders like Amazon and Alibaba are already using smart machines and algorithms from customer contact to automated logistics. Simple artificial intelligence, as in the personalized recommendation of products, has long been used by smaller companies as well.
In the future, applications for AI are likely to be found in almost every area of online commerce.

Artificial intelligence is already an integral part of our modern industry. It enables machines to perceive their environment, make their own decisions and learn on their own. AI is driving robots, which have become an integral part of production for decades — especially in the automotive industry.
But artificial intelligence will also play an important role beyond that.
The use of artificial intelligence opens up previously unimaginable opportunities for mankind, but also risks. For all this to succeed, AI needs one thing above all: structured, detailed data from as many sources as possible.
The falsification of data by us humans is problematic, as project “Tay” shows. This chatbot AI from Microsoft was fed conversations from Twitter users. It took just one day for the bot to become both racist and anti-feminist. But the tested AI also reached the wrong conclusions in experiments conducted by the American police. Because the AI was trained with “dirty data” from decades of police misconduct, it caused officers to disproportionately patrol and sweepingly suspect African-American neighborhoods.
Another much-discussed issue is the ethics of machines. Because of the unprecedented scope of new technologies, machines will inevitably make life-and-death decisions. The example of autonomous driving raises the question of who gets to live: the child who runs a red light in front of a vehicle or the two pensioners in the vehicle who, if they swerve, will themselves be killed. The MIT Media Lab has used the Moral Machine to create scenarios to test for yourself.
Perhaps the greatest concern, however, is the fear of omnipotent (powerful) artificial intelligence overtaking humanity in the Singularity and subsequently suppressing it. Even if, according to the current state of science, such an AI is far from being in the realm of feasibility, the question remains, how can we ensure that strong AIs are good in character? Only so much: The discussion would go beyond this framework.
How will machines — e.g. autonomous cars — decide in critical situations in the future? Researchers at the Massachusetts Institute of Technology (MIT) have designed the Moral Machine. Critical situations are shown — for example: children on the roadway vs. an elderly couple in the vehicle — and you have to make a moral decision about life and death. How would you decide, and only then how should the machine judge that:
Samsungs’ NEON virtual assistants — based on artificial intelligence — give a pretty impressive taste of the future. Whether as tutors in education, customer support in retail or as a virtual friend — they seem amazingly real:
Machine learning combined with automation: Strateos Cloud Lab offers scientists the opportunity to have their tests performed autonomously in a lab automated by artificial intelligence and robotics. This involves defining the tests and then running them autonomously. Pretty cool:
Sources
What’s Artificial Intelligence? | A Beginners’ Guide was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally from KDnuggets https://ift.tt/2Prtfzc
source https://365datascience.weebly.com/the-best-data-science-blog-2020/overview-of-mlops
Originally from KDnuggets https://ift.tt/3rpG0aH
Originally from KDnuggets https://ift.tt/3lQns2g
source https://365datascience.weebly.com/the-best-data-science-blog-2020/ms-in-data-science-at-ramapo
Originally from KDnuggets https://ift.tt/39fuEQk

Give yourself a head-start by seeing the big picture.
Continue reading on Becoming Human: Artificial Intelligence Magazine »
