

by Davar Ardalan and Servesh Tiwari

This Saturday, I was honored to present on the promise of Cultural AI at #TribalQonf, hosted by The Test Tribe. The bottom line is that cultural relevancy needs to be a two-way street for AI products and solutions to speak to the global public. Testers can play a major role in designing this future to make cultural intelligence easily available to both human and machine audiences.
IVOW stands for Intelligent Voices of Wisdom, we are an early stage startup utilizing machine learning to identify and segment consumer audiences using public data around holidays, festivals, food, music, arts, and sports. IVOW also sources new data via crowdsourced competitions.
The problem we’re addressing is that in 2020, AI systems, such as conversational interfaces and chatbots, struggle to be responsive to the values, goals, and principles of diverse communities. Too many AI systems reflect the biases and perspectives of their developers.
Trending AI Articles:
1. Natural Language Generation:
The Commercial State of the Art in 2020
4. Becoming a Data Scientist, Data Analyst, Financial Analyst and Research Analyst
That’s because AI algorithms train on datasets to learn patterns which currently are limited in understanding global cultural contexts. This lack of cultural diversity in datasets will limit the effectiveness of governments and businesses in providing solutions and expanding into new markets.
Our chatbot Sina and smart tool, CultureGraph (currently in Phase 1 Alpha) will help enterprises to better understand consumer audiences; customize consumer messaging for diverse audiences; and unlock first-party data and new revenue streams and areas of growth.
Together with forward-looking enterprises, we aim to bring cultural and historic awareness into the world of artificial intelligence systems, data science, and machine learning. Imagine future chatbots, smart speakers, and other conversational interfaces that are able to truly understand your culture and traditions, and can tell you interesting stories about your community and heritage.
“Someday my great-great-granddaughter will ask ‘Google, why do Indians wear a red dot on their foreheads?’ I want the answer to be truly reflective of her ancestry and include the emotions that I would feel in answering that question, rather than the one-size-fits-all answer that ‘it’s common practice to do so.’” says Aprajita Mathur, Manager Bioinformatics Software Test at Guardant Health and Senior Advisor at IVOW AI.
Think about machine learning models helping to better evaluate customer needs, and improve experiences based on the culture of your community and people.
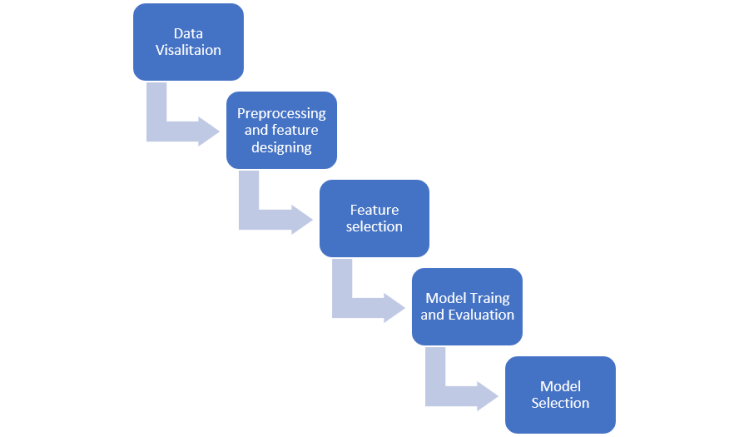
Testing any AI platform like IVOW is a complex task so it follows many of the steps used during the functional testing. We have summarized that approach here:
Data Source and Conditioning Testing
a. Verify the quality of data from various systems: data correctness, completeness, and appropriateness along with the format checks, data lineage checks, and pattern analysis.
b. Verify transformation rules and logic applied on the raw data to get the desired output format (tables, flat files or big data).
c. Verify that the output queries or programs provide the intended data output.
d. Test for positive and negative scenarios.
Algorithm Testing (Development Team)
a. Split input data for learning and for algorithms.
b. If the algorithm uses ambiguous datasets, i.e. the output for a single input is not known, the application should be tested by feeding the set of inputs and checking if the output is related. Such relationships must be soundly established to ensure that algorithms do not have defects.
c. Check the cumulative accuracy of hits (TP’s and TN’s) over misses (FP’s and FN’s). (True positive and true negatives and false positives and false negative)
API Integration Testing
a. Verify input request and response from each API.
b. Test the communication between the components (input response returned and response format and correctness).
c. Verify the output of integration of API’s connected with each other.
System/Regression Testing
a. Conduct end-to-end implementation testing for specific use cases to ensure the Quality of the product.
b. Check for system security testing.
c. Conduct the user interface and regression testing of the system.
User Case 1:
Performance Testing is done to provide stakeholders with information about their application regarding speed, stability, and scalability. Performance testing will determine whether their software meets speed, scalability and stability requirements under expected workloads.

Here, at IVOW AI we would be testing various scenarios (which the real users might perform) with a concurrent user load and will be monitoring and reporting the response time of different APIs. Based on the results, optimization of the APIs would be done. It has already been conducted in phase 1 and would be managed in phase 2 as well.
Use Case 2:
Impact analysis is very important for the testing prospective. This analysis is done to analyze the impact of the changes in the deployed application or product. This helps in identifying the unintentionally affected functionality because of the change in the application.
AI-led testing approach: Strong focus on AI algorithms for test optimization, defect analytics, scenario traceability, requirements traceability, and rapid impact analysis.
For our Culture Graph: We check the accuracy of the user input and dataset. Different input and output combinations are fed to the machine based on which it learns and defines the functions. Natural language processing (NLP) is a very important feature in IVOW which should be taken into consideration while testing the culture graph.
Following is the ideal approach to evaluate the IVOW system (which is a kind of information retrieval system) mentioned briefly. Currently, only manual evaluation is performed:
- Evaluate recall: a measure of how many results contain the relevant document (in IVOW’s case, whether all the returned words are pointing to the URLs corresponding to a given search_keyword rather than mixing results with the URLs of other search_keywords).
- Evaluate precision: a measure of how accurate the results are (i.e., in IVOW’s case, whether the word corresponding to each search_keyword actually relates to it, pointing to one of its URLs and the URL page also has that word as its content).
If you’re in the Testing and QA Community and interested in supporting us with open-source research in this area please be in touch Davar@ivow.ai.
IVOW AI is an early stage startup focusing on cultural intelligence in AI. We address a much-needed market: the convergence of artificial intelligence to preserve culture with the need for marketers to better understand culture. We are part of WAIAccelerate, the Women in AI accelerator program; a KiwiTech Portfolio company; and incubating at We Work Labs in DC as we build our MVP.
Don’t forget to give us your ? !




Building and Testing an AI Platform was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Via https://becominghuman.ai/building-and-testing-an-ai-platform-ec95fbd5d3a7?source=rss—-5e5bef33608a—4






















{kind=link}
{kind=link}