365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
As a data scientist writing code for your models, it’s quite possible that your work will make its way into a production environment to be used by the masses. But, writing code that is deployed as software is much different than writing code for exploratory data analysis. Learn about the key approaches for making your code production-ready that will save you time and future headaches.
The Credit approval is one of the critical things for a bank to handle since most of the applicants are not in the approval end or the rejection end, where borderline applicants should have to be evaluated properly. Since a pitch from the applicant or a discussion could lead to a miss judgement depending on the experience of the evaluation officer. In real-world, there are few different levels of credit cards and approving each at a given level plays a critical role in motivating the customers to spend more, and retain in with the company. The initial rejection without justification would give a bad image of the company or the bank and in the long run, it affects the name of the bank which is an intangible asset. Therefore, for this project, the credit approval data-set from UCI(cite) database has been used.
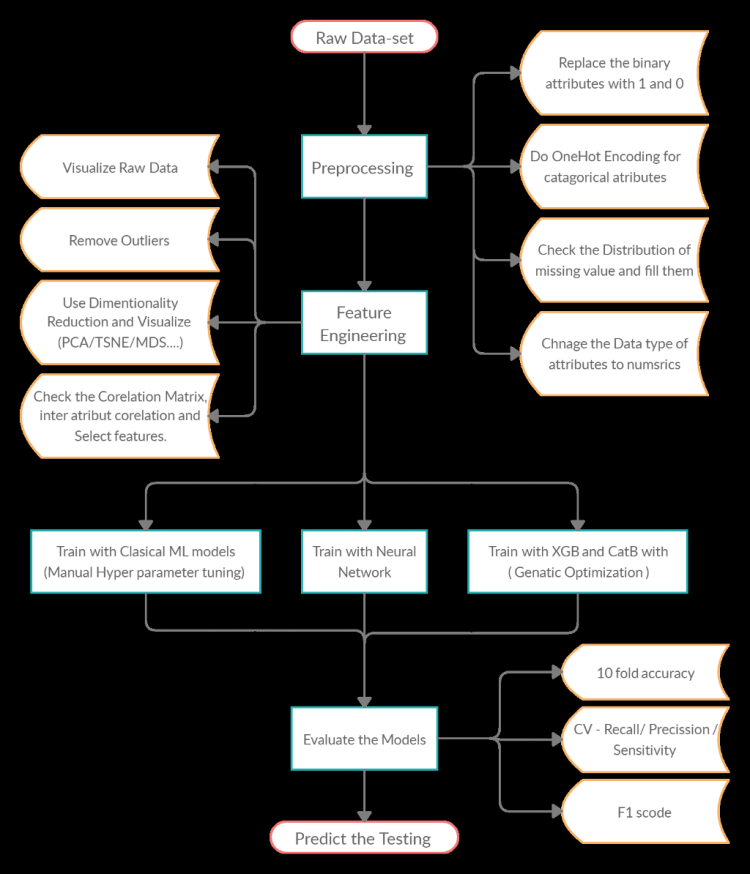
Predicting the Successful approval or not could be the final task but to achieve that from the raw data set there was a step by step approach.
Encoding Data
The attributes in a data-set have a different type of entries (Floats, Numbers, Categorical, binary data) to train them all attributes should change to numeric. Therefore, the binary attributes were encoded as (1 and 0) and multi-categorical attributes were encoded using ”ONE-HOT ENCODING”. This is where the integer encoded variable is removed and a new binary variable is added for each unique integer value.
If the integer encode uses to train then it tries to miss-lead the model and create a relationship between the variation of integers which doesn’t exist at all in some cases. After One-Hot Encoding, the 15 attributes were distributed to 38 attributes.
Ex: A4: (u, y, l, t) => A4_u, A4_y, A4_l, A4_t
Missing Value Handling
One of the most important things in prepossessing is handling the missing values, where first have to have a clear understanding about how the missing values have been spread throughout the data set. In this step, missing values have to be handled based on their distributions to achieve reasonable accuracy. Here, to confirm the randomness of missing values, Little’s MCAR test was performed. If the potential bias due to missing data depends on the mechanism causing the data to be missing, and the analytical methods applied to amend the missingness. The chi-square test of MCAR for multivariate quantitative data proposed, which tests whether there exists a significant difference between the means of different missing-value patterns.
Feature Engineering: Remove Outliers
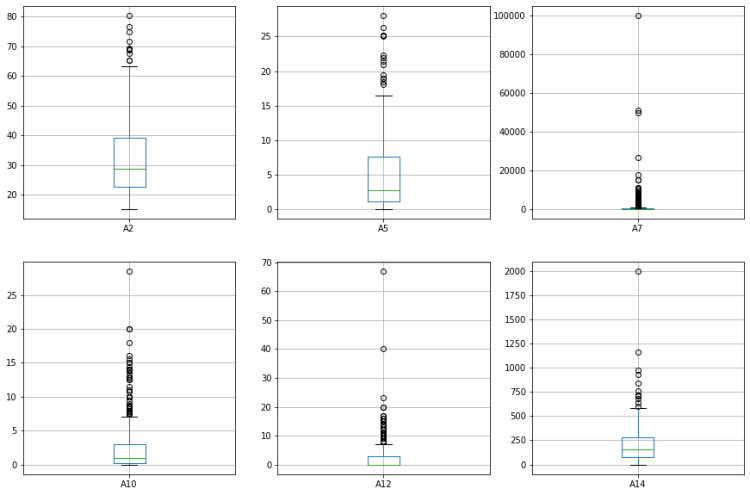
Outliers are unusual values in your data set, and they can distort statistical analyses and violate their assumptions therefor, the outliers have properly identified and removed from the data set. Since in categorical data its impossible to find outliers the continues numerical data has been used for this.
Visualization
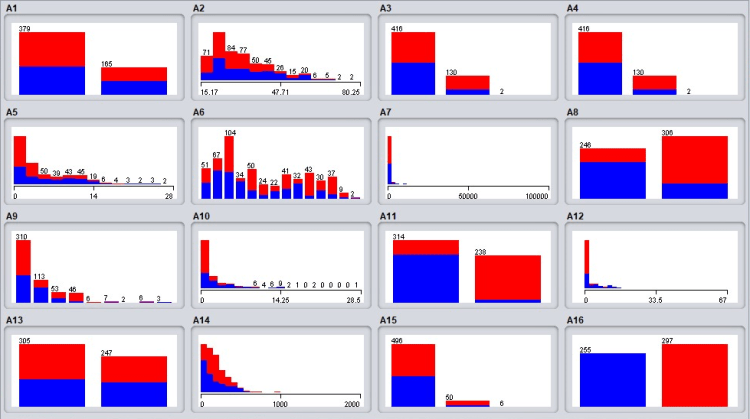
Initially, in visualization the distribution of the 15 base attributes with the Class=” A16″ has been considered. As it shows in Figure 3 most of the attributes are well distributed among 2 classes. when considering “A8” and “A11”. those attributes have a clear bias which helps a lot in classification.
Visualize with dimensional reduction
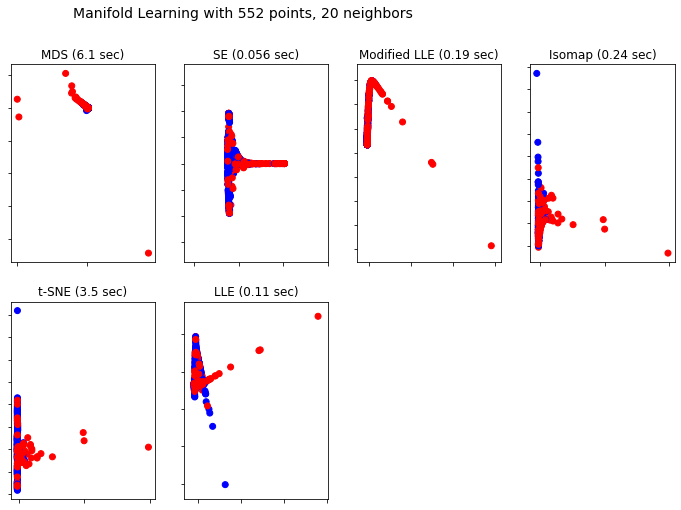
Here we have considered, Multidimensional scaling (MDS), Spectral embedding for non-linear dimensionality reduction, Locally Linear Embedding (LLE), Isomap Embedding, TSNE and PCA. Figure 4 clearly shows the distribution among the highest variant features of each manifold.
Train XGB and CatB with Genetic Optimization
The genetic algorithm is a method for solving both constrained and unconstrained optimization problems that are based on natural selection, the process that drives biological evolution. The genetic algorithm repeatedly modifies a population of individual solutions. At each step, the genetic algorithm selects individuals at random from the current population to be parents and uses them to produce the children for the next generation. Over successive generations, the population “evolves” toward an optimal solution. You can apply the genetic algorithm to solve a variety of optimization problems that are not well suited for standard optimization algorithms, including problems in which the objective function is discontinuous, non-differentiable, stochastic, or highly nonlinear. The genetic algorithm can address problems of mixed-integer programming, where some components are restricted to be integer-valued.
Data Science Jobs
The genetic algorithm uses three main types of rules at each step to create the next generation from the current population:
1. The genetic algorithm uses three main types of rules at each step to create the next generation from the current population: Selection rules select the individuals, called parents, that contribute to the population at the next generation. 2. Crossover rules combine two parents to form children for the next generation. 3. Mutation rules apply random changes to individual parents to form children.
Implementation of Genetic Algorithm
The algorithm we implemented consist of 4 different steps.
1 Initialization of hyper-parameters 2 selection hyper-parameters for each generation. 3 Crossover. 4 Mutation of generations
Initially, 6 parameters were selected to optimize which are, earning\_rate, n\_estimators, max\_depth, min\_child\_weight, colsample\_bytree, and gamma. Thereafter, those parameters were randomly initialized and set the limits which it can vary.
Then in the second step, we used 10 fold accuracy to evaluate the model and check the fitness of the model, Then based on the fitness level the parent has been selected.
There are various methods to define crossover in the case of genetic algorithms, such as single-point, k-point crossover and uniform crossover etc. In here the uniform crossover has been considered which select parameters for the child independently from the parent.
finally, in mutation, change parent parameters in random amounts and which will make it unpredictable and make perfect for the algorithm, but there will be a limit for the change of a parameter.
When applying the algorithm we have considered all the prier prepossessing steps we have considered before applying other algorithms.
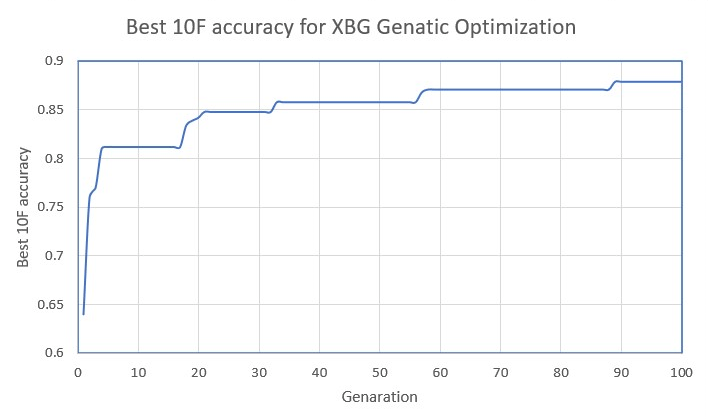
when considering the above figure 11, it shows that the best model changes and improves over generations.
Evaluation
Finally, after implementing all the algorithms and obtained the results there was an option to select the best algorithm which is suitable for this data set. For that we have considered the F1 score,10 fold accuracy, Recall and procession of each algorithm and selected the highest. Where XGB with granitic optimization and the neural network trained with full data set came hand in hand.
Conclusion
In conclusion, initially, the raw data has been taken and passed through the prepossessing which consist of encoding the categorical data and replacing the missing values. Thereafter, data has been visualized in many different ways using dimensionality reduction methods, removed outliers and checked the correlation matrix and checked the features with the domain understanding. Next, 11 different models were trained using Classical Machine Learning models, A neural network has been trained with the full data set and the PCAed data set and finally, two models (XGB classifier and CatB classifier) have trained using genetic Optimization for 100 generations. Finally based on the F1 score and accuracy the models were selected which are XGB with granitic optimization and the neural network trained with the full data set.
Please find the code and the report here at the link:
Yesterday, I attended a webinar by the Vector Institute, a Canadian not-for-profit collaboration between leading research universities, the government, and private sector dedicated to advancing AI, machine learning, and deep learning research. The topic was “Using AI to guide re-opening of workplaces in the wake of COVID-19.”
The webinar consisted of a presentation by Avi Goldfarb, professor at the Rotman School of Management at the University of Toronto (U of T), Vector Faculty Affiliate, and chief data scientist at the tech incubator Creative Destruction Lab, and a follow-up discussion with:
Arthur Berrill, head of Location Intelligence at RBC, a major Canadian bank
Gillian Hadfield, professor of law and of strategic management at the U of T, and Schwartz Reisman Chair in Technology and Society
The session was moderated by Garth Gibson, president and CEO of Vector Institute.
Professor Goldfarb’s presentation was based on his recent article in MIT Technology review (jointly with Ajay Agrawal, Joshua Gans, and Mara Lederman). It framed succinctly the problem that many CEOs are facing now or will be facing shortly as nations and economies are exiting the lockdowns: Should we reopen and, if so, how?
Tough decisions ahead
So far, managers’ decisions have been easy, said Professor Goldfarb, because they were not made by the managers but by politicians. If politicians say that your workplace is closed, it is closed. But as the economy is opening up, these decisions, he said, and the responsibility are being shifted back to the business leaders. And they will need to make some tough choices: who goes to work, when and in what sequence, what mechanisms should be put in place to protect employees and customers, etc.
More importantly, managers will need to decide what level of risk they would be willing to tolerate with people’s lives and their business reputation at stake. (Not to downplay the risk to their careers, too.)
All of this is particularly challenging because nobody knows when the pandemic will end. And managers, Professor Goldfarb said, have no control over it, while workplaces are “opportunities for infected people to infect others.” Employers, he continued, “don’t know who has the virus, who had it, and who has never had it. And this creates an economic crisis. If we did know, there would be no economic crisis.”
There is of course an option to never open up — or at least not for some time — but for many businesses, “doing nothing” is not a viable option. They are bleeding money despite all government support, and many will not last much longer.
Enter AI
An old management cliché says that every crisis has a silver lining in the form of an opportunity. And since this economic crisis is driven by the lack of information, said Professor Goldfarb, it has created an opportunity for AI (machine learning specifically), which is a technology that “enable[s] increasingly complex predictions from a wide variety of data sources.”
But before we get to AI, let’s look at other solutions. There are two, he said:
Always-on solutions, such as PPE, physical barriers, frequent sanitizing, redesigned workspaces and physical flow of people, redesigned management processes, etc.
Information-based solutions (meaning AI-based).
Data Science Jobs
Always-on solutions are a blunt instrument that is applied to everyone, said Professor Goldfarb, and the most extreme always-on solution is the lockdown which we have lived with for the past three months.
Information-based solutions are those that involve “predicting who is infectious and who is immune and then developing tools to leverage this information for contingent decision making” (his emphasis). This contingent decision making usually takes shape of an “if-then” formula: “If X is predicted to be true, then do A; otherwise, do B.”
The example he gave was of a system detecting that an employee has elevated temperature. In that case, security should be notified and either direct the employee to a nearby COVID-19 testing station or send the person home. No fever — no action.
So, where can AI help?
Some of the information-based solutions that Professor Goldfarb proposed include:
“Tests that predict whether the coronavirus is present in an individual
Contact tracing
Image analysis of people density or proximity
Symptom monitoring
Workplace monitoring of air, sewage, distancing, etc.”
Unfortunately, many of these solutions do not yet exist, and those that do are in the early experimental stages. CDL Recovery, a new program at the Creative Destruction Lab where Professor Goldfarb is chief data scientist, is focusing on developing such information-based solutions, and they hope to help about a dozen startup companies to create such solutions by the end of July, said Professor Goldfarb.
Meanwhile, the best “models” (as in machine learning models or decision-making models) we have today are the guidelines from public health authorities: wearing masks in public, frequent hand washing, maintaining a distance of two meters/six feet, staying at home as much as possible, and so on.
The challenge with AI-based solutions
Assuming that some tools will become available soon to guide business leaders in decisions concerning the reopening of their businesses (and putting aside the questionable viability of some of these tools in the context of an average organization, which is a large topic in itself), managers will face another hurdle: the probabilistic nature of AI.
When decisions are based on probabilities, a mental shift is required: from deterministic and binary thinking (yes/no) to probabilistic and less certain. For example, what does it mean that a likelihood of something is 95% or 82% or 70.4%? How would that translate into action? What actions would those be? Do decision makers understand this? Are they ready to operate with this new thought model?
“So it is with coronavirus,” writes professor Goldfarb and his coauthors: “Should your business keep operating if there is a 1% chance an infected person gets through the door? What about a 5% chance or a 0.1% chance? The answer depends on the benefits relative to the costs — on the importance of opening the physical workplace versus the risk of infection.”
We have seen some of this in action with many essential businesses — grocery stores, pharmacies, supermarkets, etc. — staying open throughout the lockdown. It would be hard for society to function and people to survive if they weren’t.
“CEOs will begin to behave like presidents and prime ministers”
During the reopening phase, “many CEOs of large enterprises will begin to behave like presidents and prime ministers,” said Professor Goldfarb. “They will report their number of cases (infections and deaths), they will explain their strategies for keeping their curves flat, and they will swing into crisis management mode when their organizations experience an outbreak.”
And they should be prepared to have their decisions to be heavily scrutinized. “Their challenge is that every decision involves a trade-off between short-term profit and safety that by design assumes some risk.” And if (when?) a tragedy strikes, he continued, “the central question will be not of a simple assignment of blame but whether the risk they took was wise.”
To make these tough decisions, managers will need to choose from a range of strategies, including a mix of general always-on solutions and probabilistic information-based solutions powered by AI.
Tough ethical questions remain to be worked out
The best part of the webinar was the discussion after Professor Goldfarb’s presentation concluded. It touched upon several topics:
Should organizations share data to support reopening? RBC’s Arthur Berrill said yes, assuming proper controls, such as data anonymization. He also spoke about huge regulatory pressures that financial institutions are under and internal frameworks, and he gave an example of using live data for just-in-time decisions (non-COVID-19 related). Imagine, he said, if we could establish such live data links for COVID-19.
There was a long discussion about data privacy. Many employees will be against contact tracing apps, and does privacy trump public good? Professor Hadfield offered her perspective from reviewing relevant law. She said the law does not say that privacy trumps all and that we need to acknowledge that information is not just a personal asset — it is a public resource as well (to be used for public safety). But boundaries are not clear, and all these debates that are taking place now are about figuring out where to draw that line.
There was a question from the audience about whether one could exclude older employees from coming back to the office, because the risk of death is higher for them. (Or what if they do not want to return to the office themselves? How should you handle that?) This question prompted a good discussion about ethics, discrimination, and the nature of risk: are we discussing the risk of employee death from COVID-19 or the risk of further transmission — of spreading the infection via the workplace — with all its consequences?
Mr. Berrill of RBC had a very strong position on this: We should not exclude or penalize older employees, he said. The risk (of getting infected) is the same for all. We need to worry about the risk of catching and spreading the disease, and we need to implement appropriate protection mechanisms in the workplace.
Another audience member asked about information-based tools to support reopening decisions. Whose responsibility is it to ensure that these tools are accurate? And should they be better than, say, government tools? The panel’s response was that the responsible thing is to do what the law requires and then to go over and above the law, because the law really tells you the minimum of what you should do. And the ultimate liability and responsibility lies with the business leaders, who should do the right thing.
Our Take
Whatever that right thing is will differ, as the multitude of opinions, actions, and behaviors — some of which are acceptable, some not, some borderline grey cases between ethical/unethical, moral/immoral, lawful/unlawful, and so on — in business, politics, and personal lives illustrate.
I think we need a series of panel discussions to sort out these thorny ethical issues around reopening businesses. For many of these questions, we do not yet have the answers, but we are reopening the economy. And we are making these decisions as we go.
We have public health guidelines to help protect ourselves, each other, and those who are vulnerable. We have similar sets of government guidelines for workplaces, such as the number of customers in a restaurant at any one time, spacing of tables, etc., just to take one example.
To support managers who are making tough decisions now, we need a forum where business leaders can discuss the ethical ramifications of the reopening, decisions and trade-offs they are making, risk frameworks they are using, and lessons they are learning. Is Vector Institute the right place to coordinate and host such a forum? A business school like Rotman? The new Schwartz Reisman Institute for Technology and Society? An NFP thinktank? An industry group such as the CIO Strategy Council?
Where are these topics being discussed in your industry? And in your state, province, and country? (Besides mass media and social media channels.) Please reach out and let us know! (Or if you want to discuss any of the topics in this note.) What kinds of questions you are grappling with? What would be most helpful to you right now?
Natural language processing has made incredible advances through advanced techniques in deep learning. Learn about these powerful models, and find how close (or far away) these approaches are to human-level understanding.
This week’s free eBook is a classic of data science, An Introduction to Statistical Learning, with Applications in R. If interested in picking up elementary statistical learning concepts, and learning how to implement them in R, this book is for you.
Also: 4 Free Math Courses to do and Level up your Data Science Skills; Exploring the Real World of Data Science; Learning by Forgetting: Deep Neural Networks and the Jennifer Aniston Neuron; A TensorFlow Modeling Pipeline Using TensorFlow Datasets and TensorBoard
Artificial Intelligence, Machine Learning, and Deep Learning Simplified.
Let’s get started right away. Would you accept if I say that people have wondered whether the machines might become intelligent, over a hundred years ago until a programmable computer was built(Lovelace, 1842)?
Today, artificial intelligence (AI) is a booming field with numerous practical applications and on-going research topics.
The whole idea of this blog is to demystify the intuition behind artificial intelligence and its sub-domains.
Photo by CommitStrip.com
First things first, artificial intelligence is not just if and else statements. You’ll understand the reason behind my statement by the end of this blog.
The way I see artificial intelligence is, Humans are good at Intelligence and machines are good at computations. So, the blend of both human intelligence with machine computation is Artificial Intelligence.
The sub-domains, including machine learning and deep learning, are the ways to teach the machine how to do a task. ?? I know it’s still confusing. I’ll walk you through a few examples to get a clear idea.
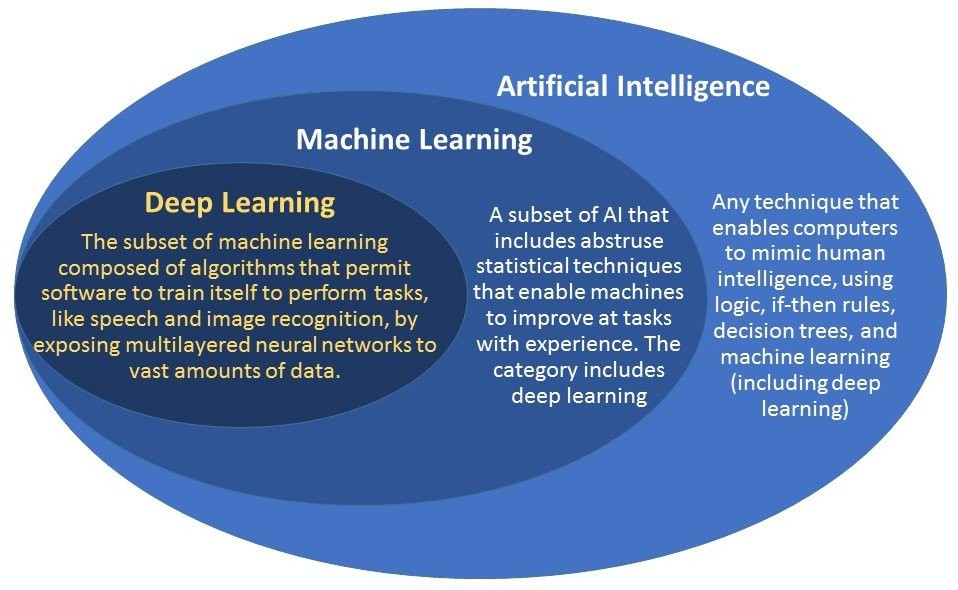
The high-level view of artificial intelligence, machine learning, and deep learning.
A high-level overview of AI, ML, DL
Let us consider the classic problem of predicting whether an employee would leave the company or not? (Also famously referred as Employee Churn Problem) Now, when you say an employee, there will be a lot of information related to him starting from employee id, age, marital status, salary, so on and so forth.
Now that we have a lot of data fields and we don’t necessarily need all of them to tell whether an employee would leave or not. For example, EmpID or Dept ID might not matter for us but the salary that he’s earning, his increments from past years, his manager might be pretty useful. Even sometimes his marital status when combined with salary has an impact. We humans, by looking at it can say that this data is not needed and this data is needed. But, for a system, it cannot decide on that when it comes to machine learning.
Big Data
In the case of machine learning, we have to hard code the important features to the system to map the representations among them and give us insights.
The moment I say “we can hard code”, I mean that we can select the features which we feel would be responsible to solve the problem. If you consider the above problem, we can choose marital status, salary, manager, number of job changes, age.
Machine Learning is the ability given to the system to learn(based on the features that we choose) and improve based on experience without being explicitly programmed.
Since we have fewer data fields we can hard code it but when we have a lot of features involved, then it becomes nearly impossible to do it.
Or suppose, we have a problem identifying cars in a photograph. We all know that cars have wheels, so we might like to use the presence of wheels as a feature. Unfortunately, it is difficult to describe exactly what a wheel looks like in terms of pixel values. A wheel has a simple geometric shape, but its image may be complicated by shadows falling on the wheel, the sun glaring off on the metal parts of the wheel, and so on.
You might wonder how machines can do that for us? Don’t you?
Let’s check out how machines can do that.
One solution to this problem is to use machine learning to discover not only the mapping from representations to output but also the representation itself. This approach is known as Representational Learning.
A representational algorithm can discover a good set of features for a simple task in minutes, or complex tasks in hours to months. Manually designing features for a complex task requires a great deal of human time and effort.
When designing features or algorithms for learning features(representational learning), our motive is to segregate the factors of variation that explain our data. Factors simply refer to separate the sources of influence which cannot be directly observed.
For instance, when analyzing an image of a car, the factors of variation would include the position of the car, the angle, it’s color, and the brightness of the sun. In real-world applications, these factors influence every single pixel of data we can observe. The individual pixels of the red color car might be very close to black at night and the shape of the car depends on the viewing angle. In such cases, it is nearly as difficult to obtain representation to solve the problem. Representation learning does not, at first glance, seem to help us.
Deep Learning solves this problem of learning representations by introducing representations that are expressed in terms of other, simpler representations. Deep learning allows machines to solve complex problems even when using a data set that is very diverse, unstructured, and inter-connected. The more deep learning algorithms learn, the better they perform.
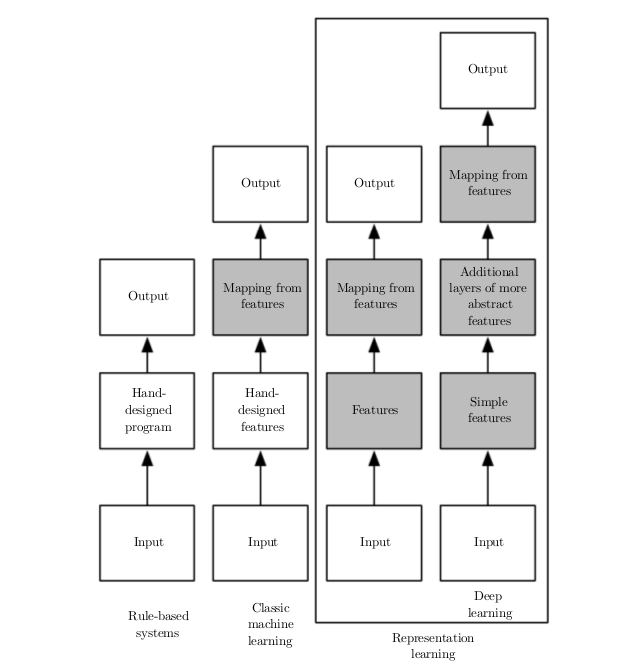
The below figure shows how a deep learning system can represent the concept of an image of a person by combining simpler concepts, such as edges, corners, etc.
Representation of complex problem as simple problems by deep learningDifferent parts of AI systems
Conclusion:
In this post, we have learned what is machine learning and the reason why we couldn’t solve more problems using machine learning, which leads us to representational learning and the problems with representational learning which leads us to deep learning.