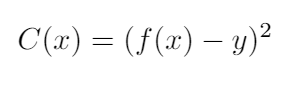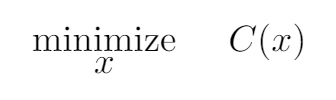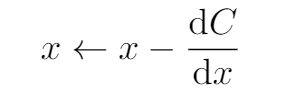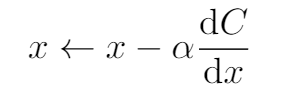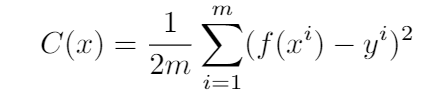365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Those interested in studying AI bias, but who lack a starting point, would do well to check out this introductory set of slides and the accompanying talk on the subject from Google researcher Margaret Mitchell.
This is the second part of the series Optimization, In this blog post, we’ll continue to discuss the Rod Balancing problem and try to solve using Gradient descent method. In Part-1 we understood what is an optimization and tried to solve the same problem using Exhaustive Search(a gradient-free method). If you haven’t read that here is the link.
Gradient-Based Algorithms are usually much faster than gradient-free methods, the whole objective here is to always try to improve over time i.e., somehow try to make the next step which results in a better solution than previous one. The Gradient Descent Algorithm is one of the most well-known gradients based algorithm. The Decision Variables used here are continuous ones since it gives more accurate gradients(slope) at any given point on the curve.
So, to solve our problem with gradient descent we’ll reframe our Objective function to a minimization problem. To do this we’ll make an assumption and define our cost function(it is also sometimes known asloss functionorerror function). We will assume that the best solution would be the one which can balance the rod for at least 10 seconds (let’s state this assumption as ‘y’). The cost function at its base is the function which returns the difference of the actual output and desired output. For our problem, the cost function would become:
the Cost function for Rod Balancing problem
Note: we squared the difference to avoid negative values or you can just take absolute value, either will work.
Jobs in Big Data
Now for every test result [f(x)]i.e., the time in seconds, the rod stayed on the finger, we can calculate our cost [C(x)]. So our Objective function would now change to minimizing C(x) instead of maximizing f(x), we can state the modified Objective function as,
Modified Objective function.
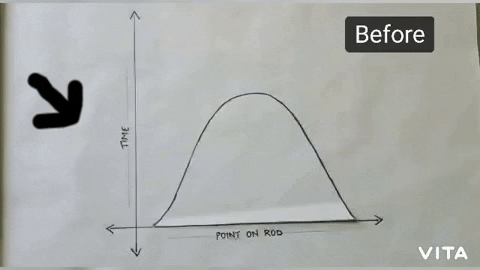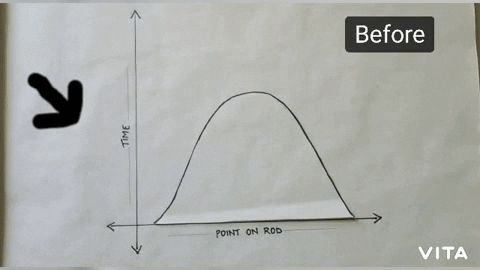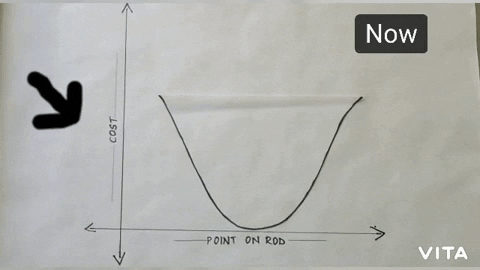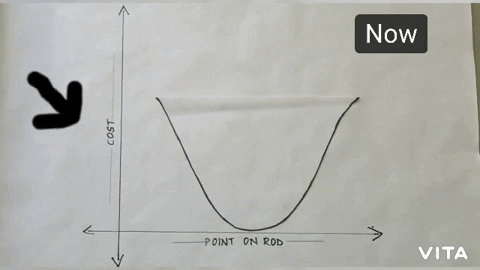
Since Objective function is changed now, our curve also gets inverse, i.e., on the y-axis instead of time we plot cost and will try to minimize it.
maximization to a minimization problem
Any Gradient descent based algorithm follows 3 step procedure: 1. Search direction. 2. Step size 3. Convergence check.
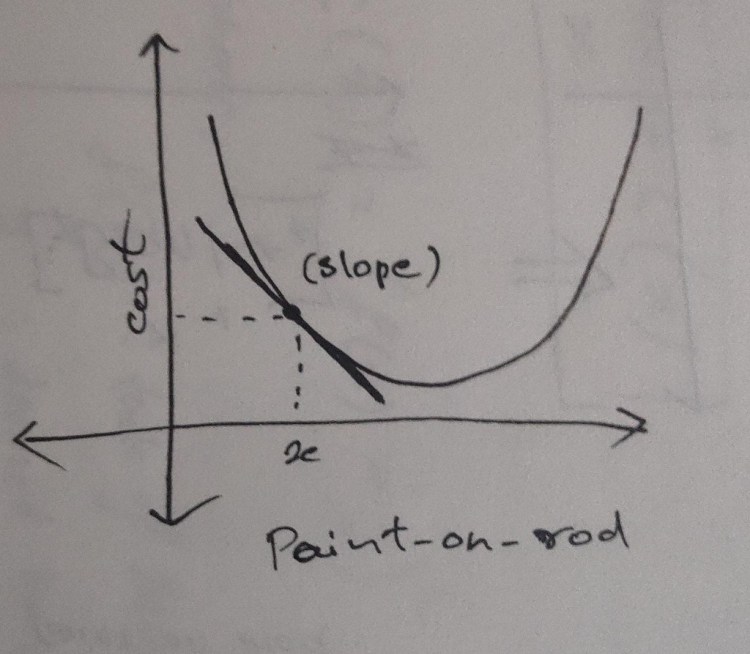
Once we know the error, we have to find the direction of where we should move our finger on the rod for a better solution. The direction is decided by taking the derivative of the cost function with respect to the decision variable(s). This simply means calculating slope(‘dC/dx’) on the curve for a specific value of the decision variable, this slope is known as the gradient. The greater the slope, the further we are from the minima(i.e., the lowest point on the curve).
For Gradient descent we apply a simple rule,
“If the slope is negative, we increase decision variable(s) and if the slope is positive, we decrease decision variable(s) with some value.”
Once we know the direction of where we want to take our variables for the next step we update them, The above rule can be easily given in mathematical term as,
Update rule
But using this update rule may overshoot the value, resulting in skipping the minima and jump to the other side of the curve. So, instead of reaching to the centre of the rod the variable may jump and go to the other corner and may introduce greater error. To avoid this we decide the step size by multiplying a very small value(usually 0.001 or 0.0001) to the gradient, this value prevents overshooting as we are not taking a very huge step. This is known as the learning rate(α), unlocks the key principle where Gradient descent shines,
“Big steps when away, small steps when closer.”
What above statement says is when the slope is greater(i.e., when the steepness is high) the variables will update with larger values and when the slope starts getting smaller(i.e., the steepness is low, reaching to the bottom) the variables will update with a very small value, This is the behaviour what we actually follow in the real world while solving this kind of problems. So our update rule now changes to,
the modified Update rule
We perform this operation of updating variable for a certain number of epochs(one complete pass to the training examples) until it converges. Below is the video of me trying to solve the rod balancing problem using the gradient descent method, you‘ll notice how fast, compare to exhaustive search we discussed in part-1, we get the point ‘x’ on the rod where it balances perfectly.
solving Rod balancing problem by Gradient descent method
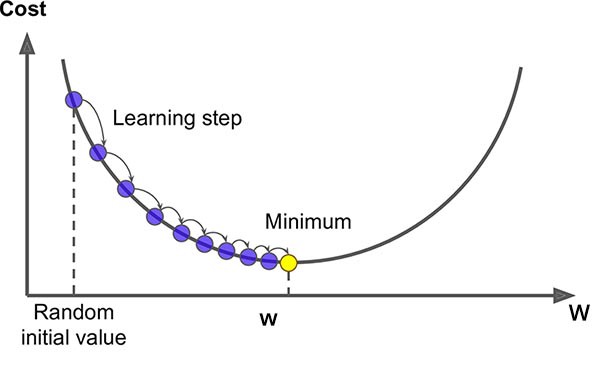
How the value of x converges to the minima, can be shown by the graph below.
‘w’ is nothing but ‘x’ in our rod balancing problem
There are different variants of Gradient descent, the one we looked at in this post is Stochastic Gradient Descent(SGD). SGD performs the update operation on variables after each example/test, just like we did in our problem. There are also other variants such as :
Batch or Mini-batch Gradient Descent: In this, the update operation is performed after each iteration of the training examples, iteration may consist of ‘m’ training examples. In batch gradient descent m is the total training examples whereas in mini-batch gradient descent total training examples are divided into batch-size(usually 32 or 64) and this batch-size will become m training examples for the update operation. An epoch will be considered complete only when all the batches have completed their update operation. For this, the most common cost function we use is Mean Squared Error(MSE), it is almost same as what we have used in our problem. The things which differ are, we add all individual errors for ‘m’ examples and divide by ‘2m’. It is given as,
Mean Squared Error
There are also different Gradients Descent Algorithms, few important ones are listed below. They do provide better performance but underlying concepts remains the same.
Momentum
Adagrad
RMSprop
Adam
Refer to this article, it explains the performance difference and how they vary from each other.
While selecting the optimization algorithm it is always advised to select based on their popularity. But, this is not always true, look at the image below and decide what suits best for your problem.
Congratulations!!! If you have made this far you must be having a comprehensive understanding of Gradient Descent Algorithm by now. Let me know if you found this 2 part series helpful by leaving response or giving a clap. I will cover more Machine Learning foundation topics in future, to get notified do follow me here.
Spoiler Alert, It’s not magic it’s machine learning
An Absurd Challenge
Today I will show you how to obtain churn predictions before your coffee is ready. Put some coffee on the machine or french press so that when you get all those churn predictions you can enjoy going through them with that hot coffee you just brewed in the meantime.
A Friendly Introduction 🙂
Let me introduce myself. I am M Ahmed Tayib working as a Data-Scientist inGauss Statistical Solutions. I am your friendly neighborhood data-scientist guy who loves coffee and loves an irrelevant challenge like making coffee vs conducting churn prediction.
Firstly, A definition
Churn is a term/label that is given to the customers who discontinue the services/subscription a company provides. For instance; if a user has not renewed Spotify subscription for 4 months then Spotify may consider that user a Churn.
Customer Churn
Similarly, this can be said for any business in this modern era. Every business has churn customers, every business has a few segments of customers, well to be precise ex-customers, that discontinued the services.
“Retaining a customer is always less expensive than acquiring a new one.”
I guess the quote speaks for itself. Of course, you need to obtain new customers to grow but that does not mean you have to lose some of them and do nothing to retain them.
Solution; Once you know which customers are likely to churn and why you can take appropriate action to retain them. However, the problem is in real life it is much much and much hard to know which customers are about to pull a stun of churn and let alone why.
How to Predict Churn?
Now that I have established what churn is and why churn prediction is important, lemme wrap it up with how to actually do it and do it really fast like never had been done before.
Jobs in Big Data
All you need is to have those sales and customer/user data. Please follow the steps below;
Go grab your coffee it should be ready by now and then we can see what these predictions are and what good they will do.
A Much Needed Explanation
Well, you must be asking what about feature engineering, model training, model testing, and all those tasks. Lemme clear that up for you. Once you upload your data to Enhencer platform what it does is;
First, it does all the necessary Feature Engineering automatically for you. We all know how pain in the a** this feature engineering is. This should save hours of coding in SQL or similar platform if not days of your time.
Enhencer uses Machine Learning Algorithms behind the curtain to train the best model for your data automatically. That should also save hours of your time, again.
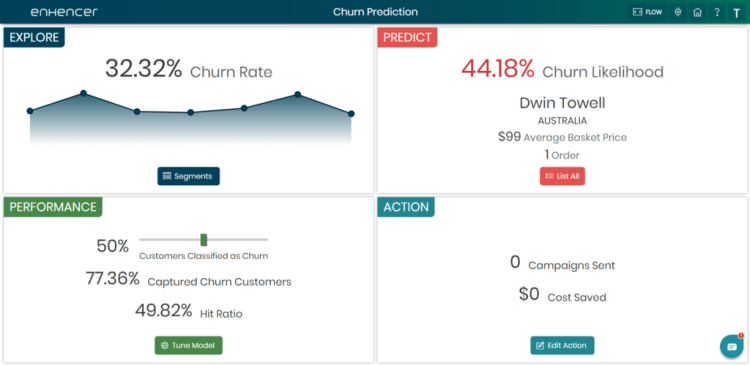
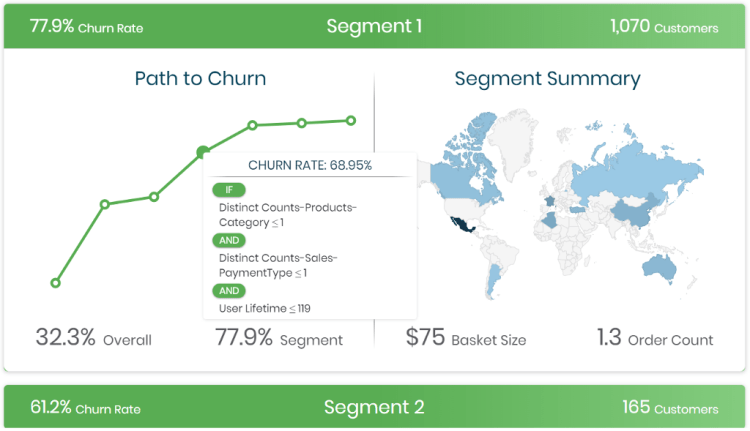
What you see in the first picture is the summary of the whole process. It gives the historical churn rate over time. Then it provides the likelihood of churn for all your customers so that you know which are customers are going to churn in the near future. Lastly most important of all in the second picture it provides the segments of customers. This shows why customers in these segments are going to churn.
Pretty neat hah… All you need you to do is look at which customers are highly likely to churn and see what is the reason behind that and take immediate appropriate action. This should be more than enough to help anyone to retain their customers and reduce the churn rate significantly.
An Unnecessary Conclusion
Definitely you can change the models and tune them later if something is not to you liking and what’s more, they have tons of algorithms as options for you, but that’s for the advanced enthusiast users.
You can’t get easier than that and from my experience in the data science field, all these would have taken days, if not weeks, in the traditional manner using R, Python, SQL, etc.
Here is a video to help you out how to upload your data in Enhencer and obtain Churn Predictions easily.
Well go ahead and try yourself and thank me later;
Trying to contribute to the fight against waste pollution with Computer Vision — Part I
An estimated 5 to 25 million tons of plastic are thrown in our oceans every year. Although we know that those devastating trashes for biodiversity and environment mainly come from rivers and beaches, it remains really tough to catch them all, especially in some poor and neglected countries.
From this observation, we decided to consider a solution using deep learning to detect rubbish with a camera.
Is it possible to generate a trash detector which would be the first step to clean up our rivers?
Such an issue is the kind we want to address at Picsell.ia.
The TACO trashes Dataset available on the Dataset Hub seemed to be really suited to begin our project. This Dataset contains 1500 pictures of everyday life trashes that we tried to annotate accurately.
As you can see the Dataset isn’t really well balanced and doesn’t have a lot of objects annotated but that’s a first try, we will allow you to contribute to this Dataset in the next few week !
Jobs in Big Data
The model
We fine tuned a Faster RCNN model pre-trained on COCO (model already available on the Model Hub) and within 2 hours, our “trash detector” model was ready to be tested on the playground with our own data.
Let’s have a look on the playground :
Here, the bottles are well detected on this picture, but to be honest, our model is not as good on every images. The reasons are of course the lack of training data, and the fact that we didn’t optimized our network so far. This leaves a lot of room for improvements.
Future enhancements
Although this project has proved itself, it can hardly be used for the moment. Our final goal is to embed our model on an edge device (eg. NVIDIA Jetson..)and run it in real time. But for that the model has to be way more accurate than it is now and also suited for near real-time inference.
But how to improve the model ?
This article is the first part of a series, here we have just made a ‘prototype’ of our algorithm but the next parts will be dedicated to :
Better algorithm choice and optimization
The influence of training data
The deployment on edge device
The different ideas we would like to implement are the following ones :
The dataset : What if we had at our disposal a TACO trashes dataset where all trashes were floating on the water ? All of our annotations are in fact very precise segmentation of the objects (we extracted the bounding-boxes in this article for prototyping purpose) but we can easily perform data augmentation and simply cut and paste the objects on another backgrounds (like sea water) or perform some advanced techniques like Neural Style Transfer to make it look more like ‘real’ data. We will also increase the volume of training data along the way.
The model : Some models are more accurate but also a lot heavier than others so we will try a bunch of them and try to find a compromise so we can achieve our goal and compare the results.
Finally, if we succeed in setting this trashes detector up, the next goal will be to find a way to pull the trashes detected out of the water. That is now out of our field, but we are sure that you will find solutions such as the first floating devices that already exist.
This is a long run project that will need a lot of iterations but after that’s what we want to facilitate at Picsell.ia ! Do not hesitate to come along and help us built the biggest Open Computer Vision Hub and share this with your relatives, also please come and ask for help if you need it, it’s always a pleasure to guide you 😉
Just as there is no Data Science without data, there’s no science in data without mathematics. Strengthening your foundational skills in math will level you up as a data scientist that will enable you to perform with greater expertise.
Also: Uber’s Ludwig is an Open Source Framework for Low-Code Machine Learning; Understanding Machine Learning: The Free eBook; Best Machine Learning Youtube Videos Under 10 Minutes; The Most Important Fundamentals of PyTorch you Should Know
Voice AI arms call centers with actionable insights on 100% of voice calls, influencing better coaching for agents, and in turn, better customer experiences for those calling in.
What is Voice AI?
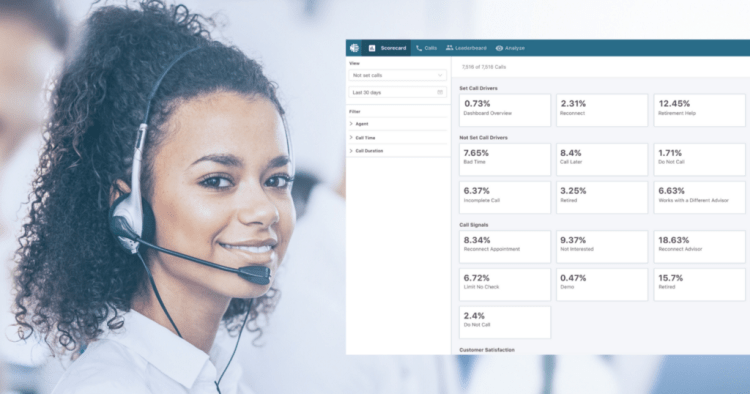
Voice AI sits at the intersection of speech analytics and quality management, using cutting edge speech technology and natural language processing to transcribe and analyze support calls at a massive scale. It enables organizations to analyze 100% of customer conversations with the ultimate goal of improving agent performance and the overall customer experience.
With Voice AI, key moments in conversation can be unearthed to provide a more accurate picture of how the contact centers as a whole, and the individual agents staffing them, are performing across key metrics. Analytics on interactions like sentiment, emotion, dead air, hold times, supervisor escalations, redaction, and more are often game-changing for businesses who previously had low QA coverage, and Voice AI is the key to identifying them.
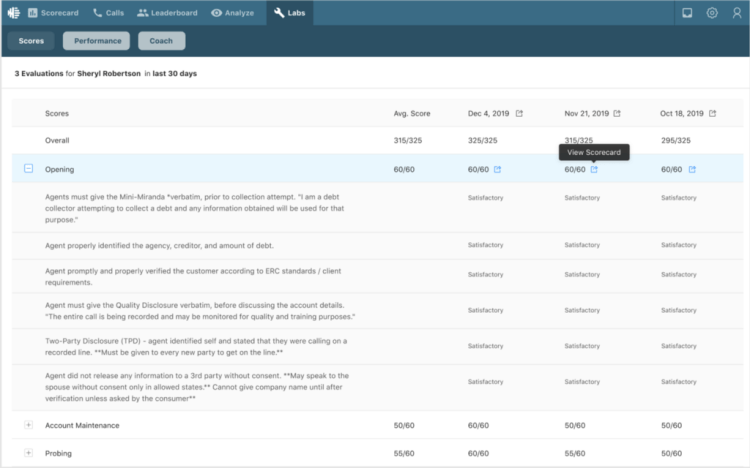
Once transcribed and analyzed, Voice AI automatically scores some parts of conversations and enables organizations to create tailored coaching programs for agents.
The Advantages of Voice AI
Voice AI emerged as a result of the inefficiencies of highly manual traditional quality management (QM) programs. Organizations struggled to fully-understand performance, monitor mission-critical KPIs and compliance, and better enable their agents with relevant training.
QA is Manual Low Call Coverage: Quality checks take 30+ minutes per call, analysts use lengthy checklists, and scoring is subjective and calls selected at random.
Transcription Inaccurate and Simple: Accents, overtalk, industry specific terms, and spotty connectivity make speech-to-text transcription challenging.
Lack of Benchmarking: Performance is assessed from a few scored calls and minimal benchmarks across the organization.
One Size Fits All Training: Blanket, one size fits all trainings might not be relevant to groups of agents. Minimal data available to create targeted, impactful coaching programs.
Low Visibility Across the Organization: Nearly impossible to monitor organization-wide performance and monitor progress.
ML Jobs
After Voice AI
⏰Automates the Tedious Parts of QA: Analyze and score 100% of calls for every agent and identify benchmarks and spot performance trends.
? Improved Transcription Accuracy: Accurate transcription (80+%) at scale delivers full view of performance and insights with confidence.
?️ Comprehensive Evaluations: Get a full view into every voice call for every agent and enable supervisors to spot trends and identify critical areas of improvement.
? More Targeted Feedback/Coaching to Agents: Provide more targeted feedback to agents and use personal scorecards as reference points for more relevant training.
? Better Performance Analytics and Trends: Operation leaders can identify inefficiencies and trends and improve key metrics with data-driven training.
Voice AI provides a wide variety of benefits to improve processes across a contact center. Next, we’ll dig into some real-world use cases of how Voice AI and quality automation is used today.
Mandatory Compliance Tracking
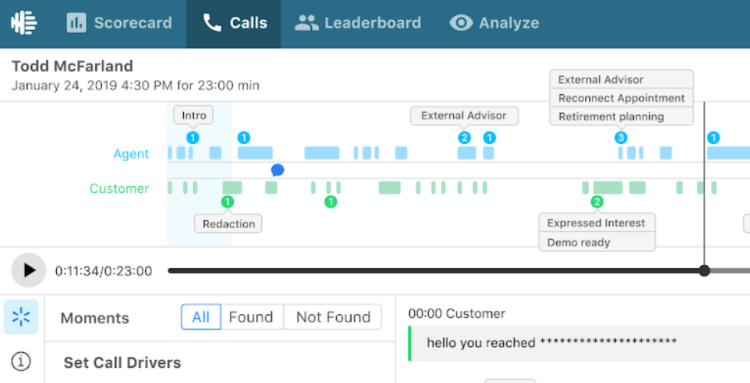
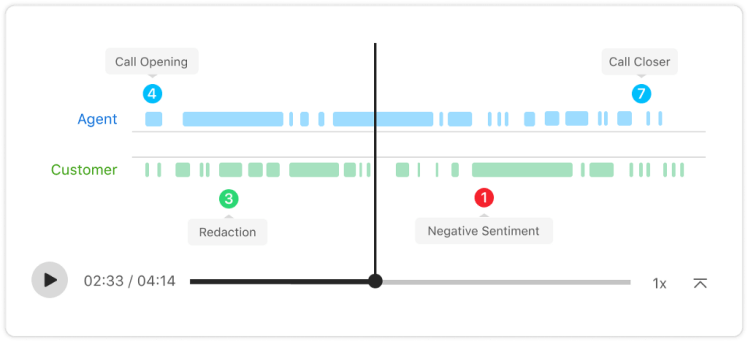
Voice AI monitors for compliance interactions, including redaction and customer verification.
Regulatory compliance is paramount across all industries, most notably financial, insurance, and healthcare. It ensures the protection of customer data, backed by strict legislation to enforce it. As a result, monitoring mandatory compliance dialogues and categorizing voice calls relevant to specific compliance regulations is mission-critical.
Voice AI gets granular with opener and closing dialogues, monitoring for important interactions for both compliance and customer satisfaction.
The beginning of a conversation is important from both a customer experience and a compliance standpoint. The end of a conversation is also important for customer experience, and it also is an opportunity to both better confirm how the call went and create next steps.
Examples
Mention company name
Self introduction
Offer assistance
Customer verification
Recorded line message
Thank customer for calling
Offer further assistance
Measurable KPIs
Increase positive sentiment
Decrease negative sentiment
NPS
Adherence to brand standards
Lower average handle time
Supervisor Escalations
Teams can hone in on exact moments that led to a supervisor escalation, like lack of agent resources, negative sentiment or hold time violations.
Supervisor escalations are a strong indicator of a negative customer experience, a metric for agent call-handling, or an organizational inefficiency. Escalations in any contact center are costly due to the amount of time and resources required to resolve them.
Customer sentiment analysis is an indicator of how people feel about a brand, its products, and its service. Simple sentiment analysis is determined based on words alone (what’s being said), while advanced sentiment analysis (tonality-based) considers tone and volume as well (what, how, and why it’s said).
Examples
Negative experience based on agent, process, or product/service
Measurable KPIs
Customer satisfaction (CSAT)
Reduced negative sentiment
Improved products and services
Sentiment analysis is a key component of Voice AI, analyzing voice calls to gauge emotion for both what is being said, and how it’s being said.
Voice AI: Big Benefits, Bigger Potential
Voice AI is transforming the contact center as we know it, uncovering deep insights across every single voice call that takes place, and providing the data needed to drive more targeted training programs for agents.
“What’s exciting about Voice AI is that we can change the way we’re coaching and re-write our quality cards. We can move away from check-boxes and focus on real skill development. Using Voice AI helps us change behavior faster.” – Dale Sturgill, VP Call Center Operations, EmployBridge