In this article, we are going to see how we can implement computer vision applications using tensorflow.js models.
Originally from KDnuggets https://ift.tt/37IbZL9

365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Originally from KDnuggets https://ift.tt/37IbZL9
Originally from KDnuggets https://ift.tt/37GdKZ4
Originally from KDnuggets https://ift.tt/3hB3dmR
Originally from KDnuggets https://ift.tt/2ANGOSt
Originally from KDnuggets https://ift.tt/2YbWRlS
source https://365datascience.weebly.com/the-best-data-science-blog-2020/tom-fawcett-in-memoriam


The data scientist is called the sexiest job of the 21st century. If you are planning to enter the field of data science, chances are that your aim is to become a data scientist as it’s the most coveted post these days. Though some may even opt for the position of a data analyst, it’s still second in the race as the most preferred position for many aspirants is still the post of a data scientist. If playing with data and finding hidden insights where others don’t see it or find it is something that you love and want to take up as your career, you may even consider being a financial analyst, or a research analyst.
Though you will come across several career choices that let you stay close to data and figures, the one that wins hands down is a data scientist.
But it shouldn’t mean that just because everyone else is aiming for this post, you too should join the bandwagon. You will need to understand what the job entails, the kind of skills and aptitude you will need, the pay package you will get, the chances of furthering your career that you will have, etc. before taking your final pick.
Let’s delve deeper to take a look at the different positions that you may consider in order to arrive at a well-informed decision.

Whether you are a student or a professional looking to shift careers, positioning yourself for a data science career could be a smart move. While students can pick up degree courses (which include programs in data science and analytics) run by several universities, professionals may pick up short-term courses conducted by reputed institutes or organizations. They may even take up bootcamps if they are ready to slog it out and don’t mind the intense learning sessions where a lot of information is packed in every session.
It’s important to note here that though a majority of data scientists have backgrounds as statisticians or data analysts, you will also find others coming from non-technical fields such as economics or business. So, just because you aren’t proficient in coding and programming or don’t have an IT background shouldn’t stop you from pursuing a career in data science.
3. Real vs Fake Tweet Detection using a BERT Transformer Model in few lines of code
If you are wondering how professionals from diverse fields like economics, mathematics, statistics, business, IT, etc. end up in the field of data science and make it work in their favor, you should look closer to find that they all have one thing in common: an ability to solve problems and communicate the well along with an unquenchable curiosity about how things work and even look for problems that others might not have even though of.
Apart from the qualities mentioned above, you’ll also need a rock-solid understanding of the fowling to become a data scientist:
Additionally, you should be able to able to work with unstructured data, which are undefined content that refuse to fit into database tables. Some examples of unstructured data include blog posts, videos, video feeds, audio, social media posts, customer reviews, etc. Since such data include heavy texts that are grouped together, sorting such data that isn’t streamlined is an extremely tough task. No wonder why unstructured data is often called ‘dark analytics’ due to its complexity.
As a data scientist, it’s mandatory for you to have the skills necessary for understanding and manipulating unstructured data gathered from diverse platforms because this way, you will be able to unravel insights, which can prove to be helpful for informed decision making.

The role of a data scientist doesn’t come with a definitive job description. Here are a few things that are you are likely to handle as a data scientist:
Data Scientist is better than Financial Analyst, Data Analyst and Research Analyst

Before you accept a data scientist position, there are a few things about the organization that you should assess:

For some organizations/companies, employing a data scientist to guide data-driven business decisions based could be a leap of faith. So, before you accept the position of a data scientist, make sure the organization/company you are going to be working for has the right attitude and is prepared to make some changes if needed.

To become a data analyst, you should have a degree in either of these fields
Additionally, you should have the following qualities:
As a data analyst, your job would include the following (though it won’t be limited to these):

Similar to the case of a data scientist, your potential employer should have a conducive work environment and be willing to accept and act upon your findings. At the same time, it shouldn’t confuse the role of a data analyst with that of a data scientist. If it does, taking up the position would mean working on aspects that you aren’t trained in, which would soon start creating problems. Even if it doesn’t, it will overburden you for sure.

You will need to have a bachelor’s degree — preferably with a major in finance, economics, or statistics, to become a financial analyst. MBA graduates with specialization in finance too can enter the field as senior financial analysts.
Apart from educational qualifications, you should be proficient in problem-solving, have strong quantitative skills, and be adept in the use of logic along with having good communication skills. Your duties will include crunching data and reporting your findings to your superiors in a concise, clear, and persuasive manner.
The Essential Skills Most Data Science Courses Won’t Teach You

To work as a research analyst, you are likely to need a master’s degree in finance or have CFA (Chartered Financial Analyst) certification in addition to some others licenses or certifications that the job may need depending on which filed you are going to be employed in. you should also have the following skills and personality traits:
Perhaps you can now see why being a data scientist is the top pick among all these positions.
Becoming a Data Scientist, Data Analyst, Financial Analyst and Research Analyst – Magnimind Academy




Becoming a Data Scientist, Data Analyst, Financial Analyst and Research Analyst was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Part-I of this blog series concluded by forming a compressed matrix for each of the features of the object to be identified. In essence, matrix so formed removed the bias stemming from magnification/reduction, rotation, and distortion of the image. Job is just half done, our algorithm still didn’t meet its core objective of classifying the objects in a given image. In this blog, we will progress to the subsequent step to build a neural network model that will learn by combining the various inputs features and successfully identify the objects in an image, with higher accuracy (Refer Pic -1)
Our compressed matrix from the previous step (Pic-2)

Each number in the above matrix (i.e) 0.33,1.0,55 etc is a neuron and forms the first layer of our neural network. The output layer will be the various objects that the model is been trained to learn and classify.
3. Real vs Fake Tweet Detection using a BERT Transformer Model in few lines of code
For time-being, the intermediate hidden layers can be regarded as a Blackbox which will cruise us towards our goal(Pic-3)

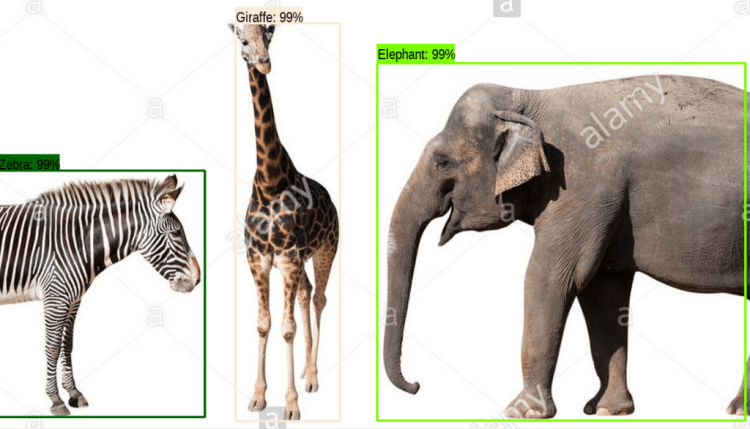
Do we need a black box? can we directly code a function that will map a given combination of input numbers to a specific output?. That’s a typical programmers mindset, but it doesn’t work in the world of Machine learning. To clarify, let’s consider the below image of a set of animal eyes(Pic-4), can you identify the animals based on it?

Few of us may do it with some degree of difficulty but for a higher-speed and greater accuracy, our brain doesn’t depend solely on one feature rather it combines a set of features to form a visual map. Neural network exactly replicate this model, it associates various features and classifies an image, this technique not only guarantees higher speed but also an improved precision
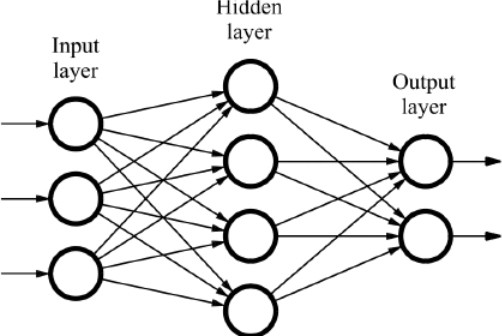
Our task is now simplified in unraveling the mystery around the so-called “Black Box”, technically this box is formed by layers of neurons (hence the name Neural Network) each layer connected to the previous one by a set of weights, a sample neural network (Pic-5)
Each of the connecting arrows has a “weight” associated with it. To start with we assign a random number as weight and we calculate the weight of a neuron in the hidden layer as the sum of all its incoming weights (Forward propagation), refer pic-6
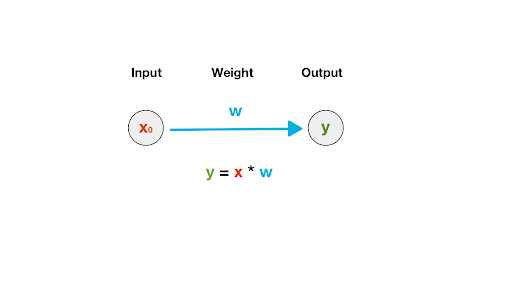
In pic-6, we had oversimplified neuron “y” having only one input so its weight is the product of W and X0, assuming we had two inputs X0 and X1 with weights W1 and W2, then we can compute the value of Y as the summation of products X0, W1, and X1, W2. Extending this technique we can keep propagating forward forming more hidden layers by combing various neurons from the previous layer. If we take a step back and observe this is essentially a permutation of all possible input features leading to an output image. Tensorflow, an open-source API from Google offers a no strings attached playground wherein you can try various combinations (Increase/Reduction of Input features, Hidden layers, weights, addition of noise, etc) of this Black box.
As we set up hidden layers and assign the weights, the model attempts to classify an input image, the first few iterations will be futile resulting in an inaccurate classification, this is part of the learning curve. Weights are continuously adjusted and tuned until the model comes closer in making better predictions. Though theoretically, it sounds easier, mathematically this step takes significant effort in the whole program.
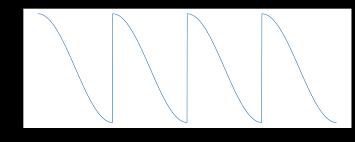
Let’s get one level deeper to understand it, following our previous example of elephant image as input, if the model classifies the output as Zebra with 80% confidence and the Elephant with 50% confidence, then we certainly know it’s incorrect and weights need to be tuned. But which direction do we tune the weight? should we increase or decrease it? and how many weights should I keep adjusting? Let’s resolve one at a time. To answer the first query of which direction should we change the weight? we embrace a concept called Gradient Descent. (Pic-7)

In the above picture, point X2 is the only location wherein the slope of the curve is zero, in simple terms, at X2 we get the most optimal result in all other points either we have a positive or negative slope. So determining X2 is the goal of gradient descent. Continuing with our previous example, so if we change weight W1 confidence limit of elephant increases from 50 to an integer greater than 50(i.e >50) than we are traveling in the right direction. Basically, we then adopt a “Trial and Error” method to reach the point of zero gradient, when we confidently know the direction but we will have no way of exactly knowing the location of X2. We keep iterating, if we take huge steps we run a risk of missing zero gradients and jumping to a positive gradient zone on the other hand if our steps are too smaller then we are risking a lot of computation intense resources (budget overshoot)and also slowing down of the whole program. Technically this is called “Learning Rate” and is a hyper-parameter.
For a CNN beginner, this will be a good start in gradient descent, as we embark on larger ML programs, the complexity increases as a curve may have more than one gradient(mini-batch, stochastic, etc) refer pic-8, which further convolutes the whole exercise and we adopt other complimenting techniques(more of it later)
Resorting to our simple elephant model, by tuning weights, by varying the number of hidden layers (a good recommendation is to keep hidden layers less than 10 as it will create over-fitting, a phenomenon where the model aligns so closely to the Training dataset and accuracy plummets with Test or the real-world dataset), the best way is to have more distinct input features and in-parallel tune the other hyperparameters until model classifies image with a higher accuracy (> 95% confidence). This in nutshell explains the broader contours of the CNN algorithm. As I mentioned earlier, no developer codes CNN from scratch rather they utilize the implementation of it by various open-source libraries (YOLO, Tensorflow, etc)
Before we conclude, let’s also know CNN is not an elixir for all the classification problems. CNN magic works with images that adhere to a spatial pattern, in simple words image that follows a predefined structure. For example, the US map always has Florida on the east coast and the image of the face has eyes above the lips. For items where spatial pattern limitation doesn’t apply, CNN is not our “go-to” algorithm.

What we have seen in this series is only at a superficial level on the nuances of CNN algorithm, to fathom the complexity and depth of it we need to work on few real-time examples ..more about it in the final/concluding part of this blog series
For a quicker grasp on CNN, Pls follow the below video
CNN Simplified for Beginners Part -II was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally from KDnuggets https://ift.tt/3hvtDGm

AI-driven, powered by AI, transforming with AI/ML, etc., are some taglines we have heard far too often from the products we are being sold every day. Everyone is chasing after the promised land of machine learning but so few fully understand it. And that is indeed the origin of most of the challenges that data scientists face today in the execution of their ML projects.
Eliezer Shlomo Yudkowsky, an American artificial intelligence researcher, says —
“By far the greatest danger of Artificial Intelligence is that people conclude too early that they understand it.”
In this blog, we will look into some of the complaints and misunderstandings that turn into these challenges when not addressed head-on from the beginning of the project.

Given how fascinated businesses are with artificial intelligence and machine learning, they are often keen on pursuing a particular problem statement with an ML solution. ML can bring in a lot of value but not everything needs its application.
3. Real vs Fake Tweet Detection using a BERT Transformer Model in few lines of code
Many problems are straightforward and can be solved with a simple exploratory data analysis. It’s important to recognize the right use cases that require the heavy artillery of ML.
With so much hype around ML, the expectations are set high. While other technologies are required to be explained in terms of their capabilities, AI and ML need to be explained in terms of their limitations.
The media and marketing promise the moon but the reality is different. AI and ML are complex technologies that take time to implement and fully leverage. They consume a lot of resources in the process of delivering ROI. It’s important for data scientists to manage the expectations from the start.
An ML model isn’t a magic crystal ball and cannot predict accurately if there is not enough data. A couple of rows in a spreadsheet won’t drive actionable insights.
To develop a model that delivers the desired business outcomes, the data science team will have to ask for more, relevant data. With enhancements like augmented data management, they can then figure out how to best leverage that data.
There is a persisting expectation for highly accurate models. But in chasing after 100 percent accuracy, businesses tend to forget other factors like simplicity and engineering costs.
The most accurate model for Netflix that won the million-dollar prize didn’t end up getting implemented. Instead, another model that had a good balance of accuracy with simplicity, stability, and interpretation was adopted.
While early machine learning algorithms were simple to explain and understand, the deep learning algorithms are different — building layers with their own understanding.
AI supervisors definitely understand how a single prediction was made but cannot explain how the entire model works at large. Ali Rahimi, an AI researcher at Google, agrees that the entire field has become a black box. Due to this, it becomes increasingly difficult to explain the recommendations made by these models to the end-users.
Creating a good ML model is a lot of work and the data scientists aren’t always capable of foreseeing how much time it would take. The projects shouldn’t have harsh timelines and milestones.
The data science team can happen to achieve it in less or more time than predicted. Businesses should be patient while continuing to provide them with the resources they need. The data science team can also explain the long, iterative process to the stakeholders and what they can miss out when rushed.
After the data scientists have put so much hard work into building and testing ML models, it’s often asked if the models have learned all that they ever need to. An ML model needs to be continually trained to ensure that it’s future-ready. Businesses must incorporate the costs of doing so when they begin an AI/ML project.
Sometimes, when the model is almost done, there comes along a request to replace the output variable. It isn’t as easy as tweaking the title of a blog you are about to publish.
To fulfill a request like this, data scientists have to often go back to the drawing board. They have to pick the right influencers for a given outcome variable and map their relationship. This is why it’s important to ensure that the project requirements and goals are well-thought-out at the beginning.
Many people are drawn to the AI/ML industry with its promise of high salaries. Still, there are very few who have enough knowledge of both machine learning and software engineering and can build functional models.
Talent has always been scarce in the AI/ML industry. In the unavailability of the right expertise, projects can get frustrating and difficult to execute. As you begin, you must make sure that you have the right experts and consultants on your team to handle the magnitude of the project.
While a framework like Python-based Django is 13 years old, employing ML models is relatively new despite the hype around it for so many years. Google’s open-source framework for ML, TensorFlow was released in February 2017.
Deploying this new technology can come with unprecedented challenges and you should be prepared for them. Given how new it is, it’s also required to help all the stakeholders understand its realistic capabilities and the investment required.
Communication is key to deal with the challenges in machine learning projects. Data scientists should empathize with the stakeholders and understand the root cause of any disconnect. They can try to explain as best as possible what to expect in the execution of the project and hence, manage expectations.
Acuvate helps organizations implement custom big data and AI/ML solutions using various Microsoft technologies. If your organization needs help in leveraging these technologies, please feel free to get in touch with one of our experts for a personalized consultation. source
10 Key Challenges Data Scientists Face In Machine Learning Projects was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally from KDnuggets https://ift.tt/2YXEwIP

{kind=link}
{kind=link}