365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Time to get back to basics. This week we have a look at a book on foundational machine learning concepts, Understanding Machine Learning: From Theory to Algorithms.
Data warehousing is one of the hottest topics both in business and in data science. But if you’re new to the field, you’re probably wondering what a data warehouse is, why we need it, and how it works. Don’t worry because, in this article, you’ll find the answers to all these questions.
First, let’s start with a definition: the meaning of the phrase: ‘Single source of truth’.
What Is the Single Source of Truth?
In information systems theory, the ‘single source of truth’ is the practice of structuring all the best quality data in one place.
Here’s a very simple example.
Surely it has happened to you to work on a file and to create many different versions of it.
How do you name such a file?
Well, once you are ready you often place the word ‘final’ at the end. This results in having a bunch of files with extensions:
‘final’
‘final, final’
‘final, final, final’
Or my favorite:
‘really final’… ‘final’
If this is you, you are not alone. It seems that even corporations never know where the most recent or most appropriate file is.
But what if you knew that there is one single place where you would always have the single source of information?
That would be quite helpful wouldn’t it?
Well, a data warehouse exists to fill that need.
So, what is a data warehouse exactly?
It is the place where companies store their valuable data assets, including customer data, sales data, employee data, and so on.
In short, a data warehouse is the de facto ‘single source of data truth’ for an organization. It is usually created and used primarily for data reporting and analysis purposes.
There are several defining features of a data warehouse.
It is:
subject-oriented
integrated
time-variant
nonvolatile
summarized
Let’s quickly go through these, one by one.
Subject-oriented means that the information in a data warehouse revolves around some subject.
Therefore, it does not contain all company data ever, but only the subject matters of interest. For instance, data on your competitors need not appear in a data warehouse, however, your own sales data will most certainly be there.
Integrated corresponds to the example from the beginning of the video.
Each database, or each team, or even each person has their own preferences when it comes to naming conventions. That is why common standards are developed to make sure that the data warehouse picks the best quality data from everywhere. This relates to ‘master data governance’, but that is a topic for another time.
Time-variant relates to the fact that a data warehouse contains historical data, too.
As said before, we mainly use a data warehouse for analysis and reporting, which implies we need to know what happened 5 or 10 years ago.
Nonvolatile implies that the data only flows in the data warehouse as is.
Once there, it cannot be changed or deleted.
Summarized once again touches upon the fact that the data is used for data analytics.
Often it is aggregated or segmented in some ways, in order to facilitate analysis and reporting.
So, that’s what a data warehouse is – a very well structured and nonvolatile, ‘de facto’, single source of truth for a company.
Ready to take the next step towards a data science career?
Check out the complete Data Science Program today. Start with the fundamentals with our Statistics, Maths, and Excel courses. Build up a step-by-step experience with SQL, Python, R, Power BI, and Tableau. And upgrade your skillset with Machine Learning, Deep Learning, Credit Risk Modeling, Time Series Analysis, and Customer Analytics in Python. Still not sure you want to turn your interest in data science into a career? You can explore the curriculum or sign up for 15 hours of beginner to advanced video content for free by clicking on the button below.
Also: Five Cognitive Biases In Data Science (And how to avoid them); Deploy a Machine Learning Pipeline to the Cloud Using a Docker Container; Naive Bayes Algorithm: Everything you need to know; The Best NLP with Deep Learning Course is Free
Nikola Pulev is a Natural Sciences graduate from the University of Cambridge, in the UK, turned Data Science practitioner and a course instructor at 365 Data Science. Nikola has a passion for Mathematics, Physics, and Programming. Over the years, he has taken part in multiple national and international competitions, where he has won numerous awards. He also holds a silver medal from the International Physics Olympiad.
Hi Nikola, could you briefly introduce yourself to our readers?
Hi, my name is Nikola and I am a Cambridge Physics graduate turned data scientist.
That’s indeed the definition of a brief introduction (and I believe it sparked interest among our readers). So, what do you do at the company and what are the projects you’ve worked on so far?
Well, I am part of the 365 Data Science Team in the role of a course creator. Course creation is, in general, a collaborative effort. There are lots of people involved in the creation of each course. Basically, my part is to do continuous in-depth research of the topic and use my expertise to write the content of the course.
So far, I have developed the Web Scraping and API Fundamentals course along with Andrew Treadway. This was a very exciting project for me, as it was my first course for the company.
The course was warmly received by our students and we couldn’t be happier about it. That said, what are you working on right now, Nikola?
Well, the project I am currently working on is a continuation on our Deep Learning course, as it delves into Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). This is an extensive topic, though, and the project is still in development.
While working on this awesome new addition to the 365 Data Science program, how do you help your students through the Web Scraping learning process?
Although our courses are online, the students have the opportunity to ask all the questions they have in the Q&A Hub. I do my best to answer those questions as thoroughly as possible. However, in my opinion, a good teacher should aim to answer the question a student may have before the student themselves asks it. So, in my courses, I constantly try to detect the stuff that may be confusing and clarify them in more detail.
Speaking of details, can you tell us a bit more about your academic background and experience?
So, I have graduated from the University of Cambridge as a Natural Scientist, although I mainly specialized in Physics. I have always had a passion for mathematics and science in general, as well as coding. Not necessarily as a programmer, but I do like to create little programs to solve problems – whether it would be to automate some tasks or to create simulations.
How do you apply these skills in your position now?
The years in university and Physics in general, have taught me to think analytically and to research topics extensively. Also, I have a circle of friends that are into science as well, and we frequently exchange knowledge. So, in that regard, I am practicing both my analytical and my teaching skills.
Nikola, you have an impressive academic background. How did you choose data science and why did you choose 365 Data Science?
When I graduated, I wanted to do something that would include mathematics and coding and that can be applied in practice. Data science seems to provide a good mixture of those. But that was not the only factor in my decision
365 Data Science was the main factor – they provided me with the opportunity to contribute to society in a positive manner. And teaching makes me feel accomplished in so many ways!
As for the team itself, they are very professional and great group of people!
I couldn’t agree with you more on that! In fact, your teammates were eager to ask you some questions themselves, so the next few questions come directly from them. Do you accept the challenge of answering those?
Absolutely. Shoot!
Which one do you prefer: 80% or 200% difficulty?
80% is for the weak.
Alright! If you had to battle 100 duck-sized whales or 1 whale-sized duck which would you choose?
Obviously the 100 duck-sized whales – they don’t have teeth or beaks and they are only in water.
I can definitely see you surviving the Apocalypse with this answer, Nikola! So, if you suddenly became the ruler of the world what would be the first thing you would do?
I would ban alarm clocks and make it so that there is no need to wake up early (I have to take care of my fellow night owls after all). Then, I would wake up to the sound of my alarm and realize it was all just a dream – too good to be true…
I think you just scored some major points with all night owls on the 365 Team (which is about 90%). Now, before I leave you to your students’ Q&A, let’s wrap things up with our signature final question: Is there a nerdy thing you’d like to share with the world?
Recently, a friend of mine dropped the bombshell that vectors can be considered as a generalization of tensors and not the opposite, which is mindboggling. Normally, I wouldn’t go around scaring people with this info, but since you asked…
Oh, wow, I believe our readers will demand a dedicated blog post on this one! Thanks for taking the time for this interview, Nikola. We wish you tons of success with your new course and all upcoming 365 Data Science projects!
At the time of developing the AI models through machine learning (ML) first and most important thing you need, relevant training data sets, which can only help the algorithms understand the scenario through new data or seeing the objects and predict when used in real-life making various tasks autonomous.
In the visual perception based AI model, you need images, containing the objects that we see in our real life. And to make the object of interest recognizable to such models the images need to be annotated with the right techniques.
And image annotation is the process, used to create such annotated images. The applications of image annotation in machine learning and AI is substantial in terms of model success.
Jobs in ML
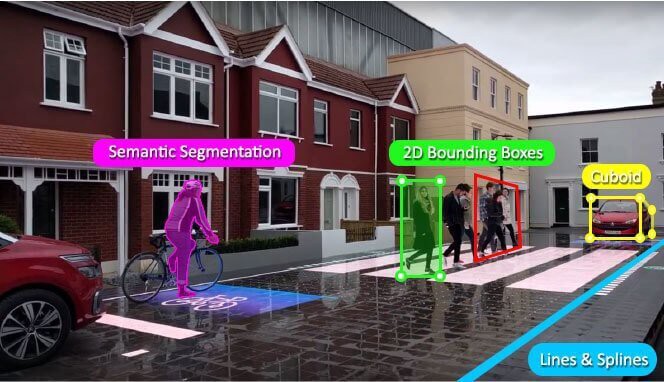
What is Image Annotation?
So, right here we will discuss about the applications of the image annotation, but before we proceed, we need to review the definition of image annotation and its use in AI industry. Image annotation is the process of making the object of interest detectable and recognizable to machines.
And to make such objects recognizable in the images, they are annotated with added metadata for the description of the object. And when a huge amount of similar data is feed into the model, it becomes trained enough to recognize the objects when new data is presented in real-life situations.
5 APPLICATIONS OF IMAGE ANNOTATION
Annotated images are mainly used to make the machine learn how to detect the different types of objects. But as per the AI model functions, ML algorithms compatibility and use in the various industries, image annotation applications also differ that all about we will discuss here below with the annotation types.
Detect the Object of Interest
The most important application of image annotation is detecting the objects in the images. In an image, there are multiple things, or you can say objects, but every object would be not required to get noticed by the machines. But the object of interest need to be get detected, and the image annotation technique is applied to annotate and make such objects detectable through computer vision technology.
Recognize the Types of Objects
After detecting the object, it is also important to recognize what types of objects it is, humans, animals or non-living objects like vehicles, street poles and other man made objects visible in the natural environment. Here again image annotation helps to recognize the objects in the images.
Though, object detection and recognition runs simultaneously, and while annotating the objects in various cases, the notes or metadata is added to describe the attributes and nature of the object, so that machine can easily recognize such things and store the information for the future references.
Classifying the Different Objects
It is not necessary all objects in an image belong to the same category, if a dog is visible with man, it needs to be classified or categorized to differentiate both of them. Classification of the objects in the images is another important application of image annotation used in machine learning training.
Along with image classification, the localization of objects is also done through image annotation practice. In image annotation, there are multiple techniques, used to annotate the objects and classified into the different categories helping the visual perception based AI model detect and categorize the objects.
Object Segmentation of Single Class
Just like object classification, objects in the single class need to be segmented to make it more clear about the object, its category, position and its attributes. Semantic segmentation image annotation is used to annotate the objects with each pixel in the image belongs to a single class.
The main applications of image annotation is to make the AI model or machine learning algorithm learn with more accuracy about objects in the images. For semantic segmentation, image annotation is basically applied for deep learning-based AI models to give precise results in various scenarios.
Recognizing the Humans Faces
AI cameras in smartphones or security surveillance, are now able to recognize the face of humans. And do you how it became possible in AI world? Thanks to image annotation, that makes the humans faces recognizable through computer vision with the ability to identify the person from the database and discriminate them among the huge crowd from the security surveillance system perspective.
In image annotation for face recognition algorithms, the faces of humans are annotated from one point to another point measuring the dimension of the face and its various points like chin, ears eyes, nose and mouth. And these facial landmarks are annotated and provided to the image classification system. Hence, image annotation is playing another important role in recognizing the people from their faces.
TYPES OF IMAGE ANNOTATION
I hope you got to know the applications of image annotation in the world of AI and machine learning. Now you should know what are the types of image annotations used to create the machine learning training datasets for deep learning based AI models? And we will also discuss here the application of different types of image annotation into various industries, fields and sectors with uses cases of AI-based models.
Bounding Box Annotation to Easily Detect the Objects
Bounding box annotation is one of the most popular techniques used to detect the objects in the images. The object of interest are annotated either in a rectangular or square shape to make the object recognizable to machines through computer vision. All types of AI models like self-driving cars, robots, autonomous flying objects and AI security cameras relying on data created by bounding box annotation.
Semantic Segmentation to Localize Objects in Single Class
To recognize, classify and segment the objects in the single class, semantic image segmentation is used to annotate the objects for more accurate detection by machines. It is actually, the process of diving the images into multiple segments of an object having the different semantic definitions. Autonomous vehicles and drones, need such training data to improve the performance of the AI model.
3D Point Cloud Annotation to Detect the Minor Objects
The image annotation applications not only include object detection or recognition, even can also measure or estimate the types and dimensions of the object. 3D point cloud annotation is the technique helps to make such objects detectable to machines through computer vision. Self-driving cars are the use case, where training data sets is created through 3D point cloud annotation. This image annotation helps to detect the object with additional attributes including lane and sideways path detection.
Landmark Annotation to Detect Human Faces & Gestures
Landmark annotation is another type of image annotation techniques used to detect human faces. The AI models like in security surveillance, smartphones and other devices can detect the human faces and recognize the gestures and various human possess. Landmarking is also used in sports analytics to analyze the human possess performed while playing outdoor games. Cogito provides the landmark point annotation with the next-level of accuracy for precise detection of human faces or their poses.
3D Cuboid Annotation to Detect the Object with Dimension
Detecting the dimensions of the object is also important for AI models to get a more accurate measurement of various objects. The 2D images are annotated with capturing all the dimensions visible in the image to build a ground truth dataset for 3D perception on the objects of interest. Again autonomous vehicles, and visual perception models used to detect the indoor objects like carton boxes with the dimension need such annotated images, created through 3D cuboid annotation.
Polygon Annotation to Detect Asymmetrical Shaped Objects
Similarly, polygon annotation is used to annotate the objects that are in irregular shapes. Coarse or asymmetrical objects can be made recognizable through the polygon image annotation technique. Mainly road marking or other objects are annotated for the self-driving cars. And autonomous flying objects like drones, viewing the objects from ariel view can detect or recognize such things when trained with training data sets created through polygon annotation for precise object detection.
Polyline/Splines/Line Annotation for Lane or Path Detection
Lines, Polylines and Splines are all similar types of image annotations used to create the training data sets allowing computer vision systems to consider about the divisions between important regions of an image.
The boundaries, annotating lines or splines is useful to detect lanes for self-driving cars. Road surface marking that are indicating the instructions of driving on the road need to also make understandable to autonomous cars. Polyline annotation that divides one region from another region.
The right applications of image annotation is possible when you use the right tools and techniques to create high-quality training data sets for machine learning.
Cogito is the industry leader in human-powered image annotation services with the best level of accuracy for different AI models or use cases. Working with a team of well-trained and experienced annotators, can produce the machine learning training data sets for healthcare, agriculture, , automotive, drones and .
In this tutorial, we will use a previously-built machine learning pipeline and Flask app to demonstrate how to deploy a machine learning pipeline as a web app using the Microsoft Azure Web App Service.