365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
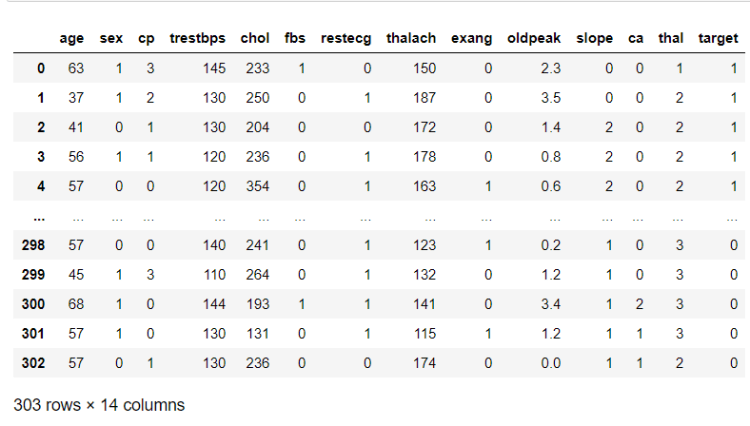
restecg: Resting electrocardiographic measurement (0 = normal, 1 = having ST-T wave abnormality, 2 = showing probable or definite left ventricular hypertrophy by Estes’ criteria)
thalach: The person’s maximum heart rate achieved
exang: Exercise induced angina (1 = yes; 0 = no)
oldpeak: ST depression induced by exercise relative to rest (‘ST’ relates to positions on the ECG plot. See more here)
slope: the slope of the peak exercise ST segment (Value 1: upsloping, Value 2: flat, Value 3: downsloping)
ca: The number of major vessels (0–3)
thal: A blood disorder called thalassemia (3 = normal; 6 = fixed defect; 7 = reversable defect)
target: Heart disease (0 = no, 1 = yes)
Steps to be followed while creating a Heart Disease Model are: —
AI Jobs
Load the necessary libraries.
import numpy as np import pandas as pd import matplotlib.pyplot as plt from matplotlib.cm import rainbow from matplotlib import rcParams %matplotlib inline import warnings warnings.filterwarnings(‘ignore’) import seaborn as sns from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.model_selection import cross_val_score from sklearn.metrics import confusion_matrix
#importing 3 different classifiers KNeighborsClassifier, DecisionTreeClassifier, RandomForestClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import RandomForestClassifier
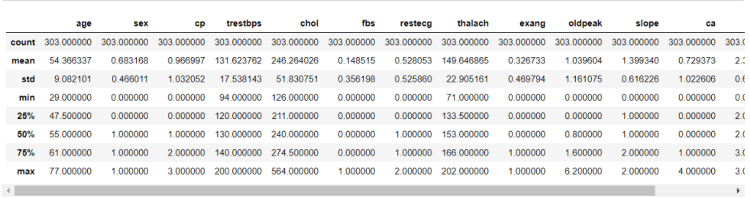
2. Get the dataset description
df.describe()
3. Get the dataset information
df.info()
4. Perform some Data Preprocessing and StandardScaler
There is still a long way to go before machine agents match overall human gaming prowess, but Deepmind’s gaming research focus has shown a clear progression of substantial progress.
Also: Python For Everybody: The Free eBook; Complex logic at breakneck speed: Try Julia for data science; An easy guide to choose the right Machine Learning algorithm; Dataset Splitting Best Practices in Python; Appropriately Handling Missing Values for Statistical Modelling and Prediction
To help you truly rock your next virtual data interview, we’ve pulled together a few tips that we recommend when conducting our online interviews for The Data Incubator’s Data Science Fellowship Program.
If you are splitting your dataset into training and testing data you need to keep some things in mind. This discussion of 3 best practices to keep in mind when doing so includes demonstration of how to implement these particular considerations in Python.
In this article, I will try to predict the locations of deforestation in Amazon Forests using Ridge, Decision Tree, Random Forest and XGBoost regression models.
Deforestation is a clearing, destroying, or removing trees due to farming, mostly cattle, logging, for materials and development, mining, and drilling. All of this combined responsible for more than half of all deforestation. Over the past 50 years, nearly 17 percent of the Amazon rain forest has been lost and losses have recently been on the rise.
Exploring the domain
While exploring and analyzing the data I noticed a tendency that most of the deforestation happen not far from places where it occurred in the past. Mostly it is connected with farms, where more space needed for the cattle to grow, logging to produce more paper or wood materials and other work.
Check myweb appfor more visual analysis & a little demonstration.
Jobs in Big Data
Dataset
I took the dataset from terrabrasilis.dpi.inpe.br/en where records quantified deforested areas larger than 6.25 hectares from 2008 to 2018 discretized per year.
The dataset includes columns: gid — unique identifier of each feature; origin_id — unique identifier for traceability of the feature in the origin for geo data; geo data — feature composed of one or more polygons — geometry obtained by visual interpretation of satellite image; uf — state abbreviation; pathrow — scene code formed by line of the satellite (the land is is divided in squares as in 2d space); mainclass— name of the main class assigned to the feature; class_name — name of the specific class assigned to the feature; dsfnv — indicates if there was a cloud in the previous year about the feature; julday— julian day; view_date — date of the scene used to obtain the feature; year — year of deforestation, used to facilitate queries to the areakm database; areakm— area calculated for the feature in km²; scene_id — identifier of the scene in the database, used for publish_year queries; publish_year — used to allow the publication of data on the GeoServer with temporal dimension.
Wrangling and Cleaning the Data
I used pandas profiling to look at my data and features closely and see the distribution, check for cardinality, zeros and nulls. Most of the features didn’t make sense to me in predicting the locations of the deforested area except for the states and view_date, also I took into consideration area in kilometres squared (areakm_squared), some states have more deforested areas than others. Geo data had the longitude and latitude, the centroid of the deforested area, which I decided to be the targets for my predictions.
clean-up data
Visualizing the data
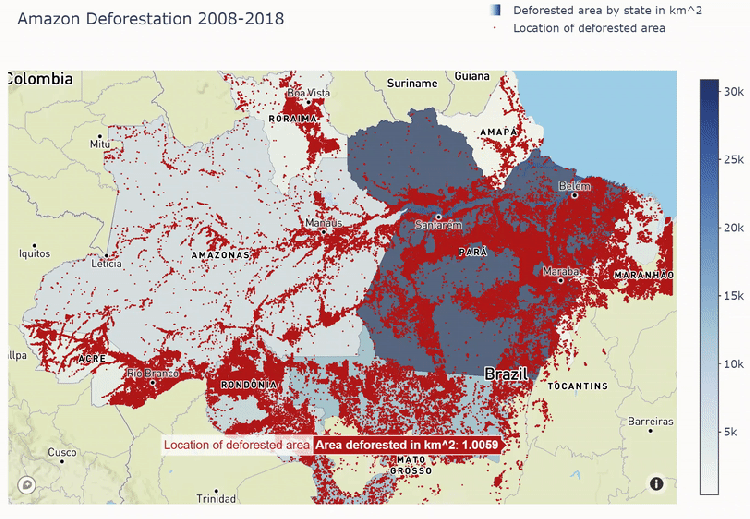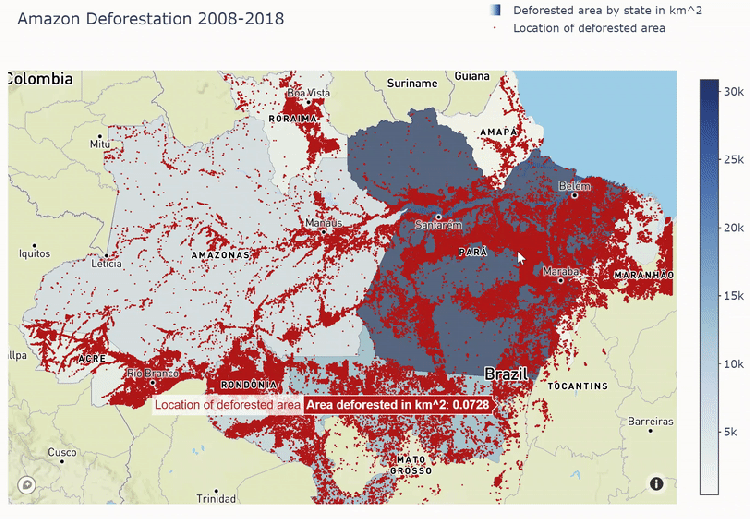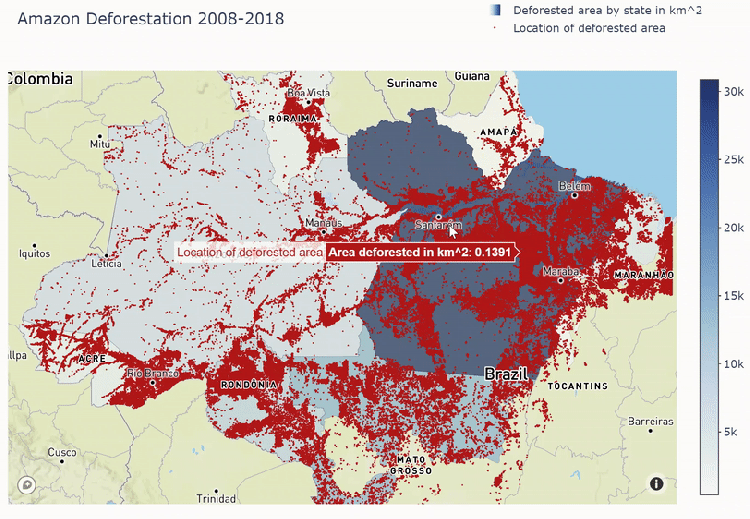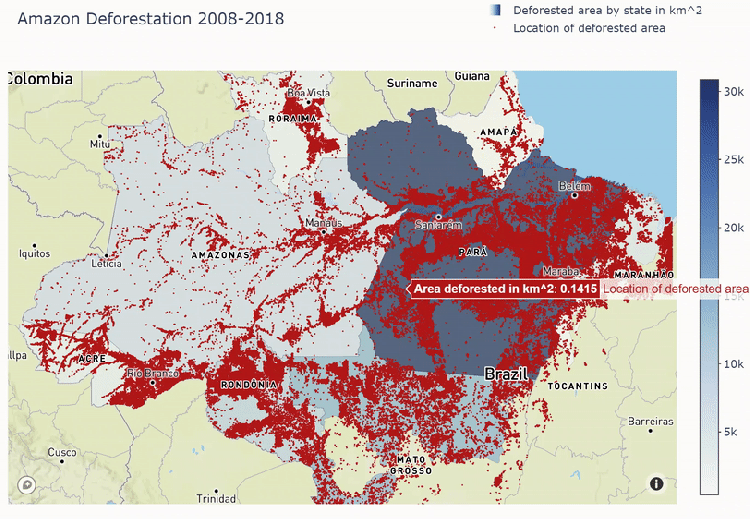
Mapbox plot below shows deforestation areas spread out through all Amazon states. We see that most of the deforestation comes to Para state and least goes to Amapa.
Mapbox plot with areas of deforestation in Amazon states
The Process
The aim is to predict the location of an area (centroid)where deforestation most likely to occur. I decided to try different models for my predictions and see which performs better. Since it is a spatial data, for the sake of simplicity I decided to treat the location as it is in 2D space and not the sphere and predict latitude and longitude as two separate values using two different models.
I made a time-based split of the data – train, validation and test. Train data 2008–2015, validation 2016, and test 2017–2018. After cleaning up and feature engineering, I ended up with only five features: [‘areakm_squared’, ‘day’, ‘month’, ‘year’, ‘states’].
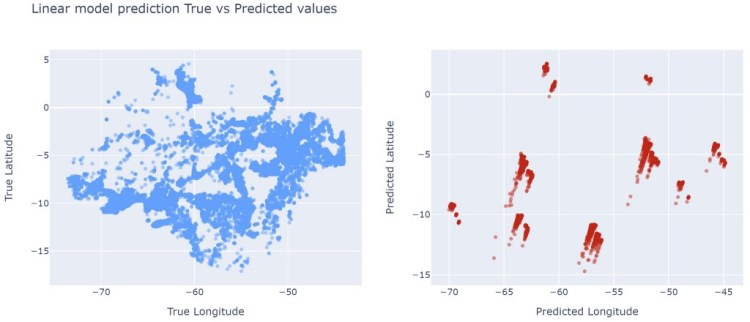
Ridge Model
The first model I tried is Ridge model, which of course is not so good at predicting coordinates, but at least I wanted to see where I stood. For the encoding I chose TargetEncoder, also I scaled values with StandardScaler, and used SelectKBest for the features.
For metrics on validation set, I chose MAE (mean absolute error), RMSE (root mean absolute error)and R² score (r-squared).
Ridge model validation MAE: 1.3207 lat Ridge model validation MAE: 1.8468 lon Ridge model Validation RMSE: 2.8329 lat Ridge model Validation RMSE: 5.4658 lon Ridge model Validation R^2 coefficient: 0.7949 lat Ridge model Validation R^2 coefficient: 0.8801 lon
The plot below shows the predictions on validation set, and as I expected, it performed poorly, even though the metrics look good.
Ridge model true values vs predicted values
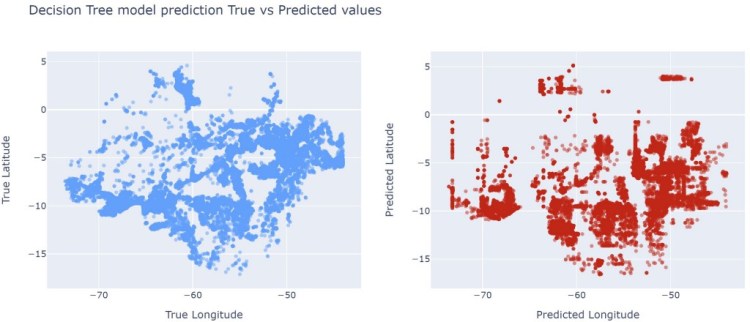
Decision Tree Model
The next model I tried is DecisionTreeRegressor model. I used TargetEncoder and default hyperparameters. For validation data I used the same metrics:
Decision Tree validation MAE: 2.1791 lat Decision Tree validation MAE: 3.3861 lon Decision Tree Validation RMSE: 7.4978 lat Decision Tree Validation RMSE: 19.2732 lon Decision Tree Validation R^2 coefficient: 0.4571 lat Decision Tree Validation R^2 coefficient: 0.5773 lon
DecisionTreeRegressor performed a little better than Ridge model, we can see predictions are closer to true coordinates, however, it is still far from true values.
Decision Tree model true values vs predicted values
Random Forest Model
For the RandomForestRegressor model, I used hyperparameter tuning. I applied RandomizedSearchCV to choose the best hyperparameters. The best hyperparameters for latitude are:
With the RandomForestRegressor model and hyperparameter tuning I got much better scores:
Random Forest Validation MAE: 1.6633 lat Random Forest Validation MAE: 2.9025 lon Random Forest Validation RMSE: 4.3909 lat Random Forest Validation RMSE: 11.7841 lon Random Forest Validation R^2 coefficient: 0.6821 lat Random Forest Validation R^2 coefficient: 0.7415 lon
And the graph looks better:
Random Forest model true values vs predicted values
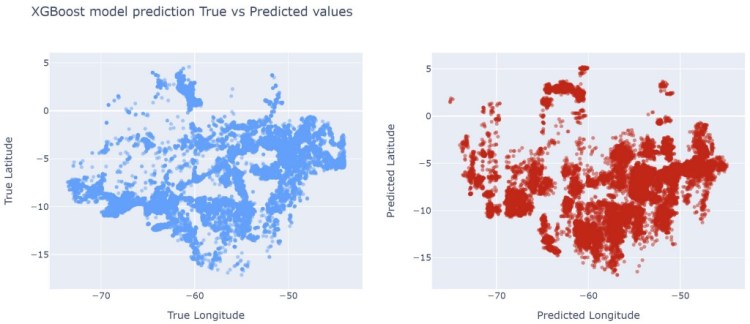
RandomForestRegressor made the best predictions so far. The last model I tried is XGBoostRegressor model. I picked OrdinalEncoder this time to transform the data and applied early_stopping to see what are the best n-estimators to use.
The MAE in XGBoostRegressor is higher and R²-score is lower than in the Random Forestmodel:
Let’s see how XGBoostRegressor model looks like on the graph:
XGBoost model true values vs predicted values
The best model out of all I tried was RandomForestRegressor, I got less MAE, RMSE loss was less, and R²-score was higher, so I decided to use this model for predictions on my test set.
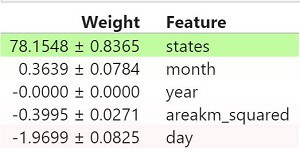
Before applying my model on the test set, I wanted to see an overall contribution of features in RandomForestRegressor model. I ran Permutation Importance from library eli5.sklearn. It showed only one feature that contributed the most in predicting coordinates which is ‘states’, and some of the features contributed even negatively, like ‘areakm_squared’ and ‘day’ in case of longitude values.
Permutation Importance only gives general information about feature contribution. Let’s break down how the model works for an individual prediction. I used SHAP Values to break down a prediction to show the impact of each feature and it’s positive or negative impact. As an example, let’s take a random row from our validation set:
# take a random row from val set row = X_val.iloc[[200]] row
random row from validation set
We got nice interpretation for latitude and longitude and how much each feature contributed:
latitude value
In predicting latitude value ‘states’, ‘month’, ‘day’, and ‘year’ features contributed in a negative direction from the mean, while ‘areakm_squared’ and contributed in a positive direction towards the mean.
In the case with longitude, we can see that ‘states’, ‘areakm_squared’ and ‘day’ features contributed negatively, however ‘month’ and ‘year’ contributed in positively.
Applying the best model to test set
Final predictions with RandomForestRegressor model on my test set didn’t perform that good for latitude values, however, did better for longitude comparing to validation set scores. There is a big difference in R² score.
Random Forest MAE: 1.9317 lat Random Forest MAE: 2.6541 lon Random Forest RMSE loss: 5.9613 lat Random Forest RMSE loss: 11.3523 lon Random Forest R^2 coefficient: 0.5621 lat Random Forest R^2 coefficient: 0.7733 lon
Let’s look at the final predictions on the scatter plot and compare to true ones. In some places it did okay, but mostly it didn’t do very well.
True vs Predicted values on test set.
Conclusion
In my opinion, to predict coordinates of locations is not so easy, because they are two values representing 3D space. Even that I treated coordinates as in 2D plane and used several models to see which ones perform better I didn’t have very good results. Also, my dataset didn’t have many features to use for predictions and I ended up with only five. It would be nice if dataset would have some features like population density, distance from a big city to a place of deforestation, causes of deforestation, and maybe some others could help to identify future locations of deforestation.
Note:
This project was done for Lambda School as an optional part of the Data Science curriculum.
An engineer’s work life mainly consist of research projects, therefore, an engineer is often in need of effective iterative research processes to guide a product redesign. Here are some tips.
Let’s assume that we’d like to develop a video streaming platform, here are basic challenges and some potential solutions.
Challenge: Super broad scope
Solution: Define goals → develop criteria to match goals → map measures and methods to criteria
Define Goals
The first challenge of the project is to determine what it means to be “intentional.” To do that, I first went to the core people problems identified from last half’s research:
People have unclear mental models around the product..
People lack a “sense of control” over their user experiences on a platform — this lack of agency contributes to people feeling worse about themselves.
Jobs in Big Data
Generate criteria
Next, you should identify the criteria to determine whether the effort addressed the two people problems.
Develop a clear mental model on:
Are people able to differentiate the purposes between feed and player?
To what extent does the player provides an immersive consumption experience?
Give people more control over their video experience:
How easy is it for people to choose videos that are related to their interests?
How easy is it for choose a chained video to watch next?
You then map the criteria to methods and timeline based on the product development progress. There are two main phases — before and after public testing.
Explore & define what to build: The focus of this phase is for design and research to determine what to build.
Validate & refine what you build: This phase starts once the Eng team starts to publicly test the new features.
On-platform, quantitative validation: Surveys to evaluate overall experience, rapid feedback surveys to test sentiment towards specific features, on-platform usability to ensure clarity and ease of use
Off-platform, qualitative refinement: Qualitative sessions with people in the experiment groups to gain deep understanding of their experience using the new features.
Challenge: So. Much. To. Test.
Solution: An iterative, phased approach.
Here are some steps to make the evaluation process actionable:
Can anything be tested live? First, a team can decide that concepts that don’t require Engineering to build new elements (e.g. a click-to-play channel player) could be easily evaluated with public testing. That leaves you with fewer concepts for qualitative research.
Dive deep & iterate. You can take an incremental, iterative approach to evaluate concepts deemed required qualitative feedback. In all prototypes, we always incorporate concepts that have never been tested as well as refined versions previously tested concepts. We are able to effectively determine the best designs, refine them gradually, and form opinions early regarding the final end-to-end flow.
Diversify testing flows. A helpful and easy way to test more prototypes is to create different groups and flows, and rotate them across participants. Rotation also helps eliminate the biases from effects such as ordering, where people tend to prefer the first variant presented to them.
Set limits and prioritize
Throughout the process, be clear about the max amount of roughly 4* prototypes you could present during a 60-minute session to ensure you got rich insights. You can also prioritize the prototypes and the questions to present.
*Number could vary based on prototype complexity.
Challenge: Tight Timeline
Solution: Create small deadlines and think ahead.
Identify small deadlines
With the deadline in mind, you can map the session dates for all phases on the calendar and these session dates became small deadlines to plan early.
Plan & act super early
Sending requests and planning logistics early allows you to focus on conducting research and generating insights once the sessions start.
Leave room & time buffer to ensure quality
Buffers were crucial to ensure quality. Examples include: leads review and feedback, prototype pre-tests and bug fixes, etc.
Challenge: The Risk to Loose Quality
Solution: Set up a standard process with template. Level up your vendors.
Use templates
Using templates ( screener, SQL code to pull participant recruitment lists, research plan, etc.) saves so much time because you didn’t need to think about the framework as much — all you need is to fill in the blanks.
Challenge: All Eyes on the Project
Solution: Frequent and immediate engagements with leads.
Daily immediate team syncs
Daily syncs keeps team members close and aligned as a unit even through those changes.
Engaging leads early for alignment
Having bi-weekly leads reviews would ensure that the time is carved out.
Moreover, to protect the quality of the work, you might often feel in the mode to “cross things off your list”. You would be grateful when your manager would remind you to feel free to take more time to produce insights. Quality is easily sacrificed in a situation like this and as an engineer you should do my best to protect that.
Last, but not least, never say “No”, get into the habit of saying “Yes, and…” and propose an alternative. With clear alternative plans and communication of leads’ priority, people are receptive and understanding of re-prioritization.
We have probably all came across the saying or statement that Machine Learning and Artificial Intelligence are a big part of technological advancement and the future. Opportunities in Machine Learning and AI are definitely going to be big for the next decades since they are the main driver of emerging technologies.
If you are interested in technology or a career in tech, you have definitely come across Machine Learning. You have probably asked yourself about what it takes to become a Machine Learning Engineer and whether it is worth it especially with emerging careers in data science.
Jobs in Big Data
One thing you have to think about whenever you are presented with this question is that the adoption of Machine Learning and Artificial Intelligence in various verticals is continuing to grow and the demand for these professionals is also skyrocketing. Therefore this makes this career a hot field that will be a big part of the future and technology.
So what does it take to become a Machine Learning engineer?
You don’t have to have a solid tech background before getting started with Machine Learning.
The number one and most important thing you would need is the enthusiasm and will to learn!
You would need to have a good understanding of the pre-requisites especially in calculus, Linear Algebra and the python programming language because it is the language commonly used in Machine Learning
After learning Machine Learning concepts make sure to work on projects and build your portfolio. Projects always go a long way in helping you strengthen your skills as well as they help a lot when it comes to job interviews.
After doing all these you have definitely prepared yourself to get into the Machine Learning field and feel free to apply for those opportunities be it a job or whatever opening that would see you advance your career in Machine Learning. If you have made it is far am certain you will definitely make it and all the best!
And that’s just what it takes to get started with Machine Learning! Always remember that it only takes the will and desire to do something to actually get to work on and do it. Anyone can do this!
Dive into experimenting with machine learning techniques using this open-source collection of interactive demos built on multilayer perceptrons, convolutional neural networks, and recurrent neural networks. Each package consists of ready-to-try web browser interfaces and fully-developed notebooks for you to fine tune the training for better performance.
Microsoft is bringing the latest research in responsible AI to Azure (both Azure Machine Learning and their open source toolkits), to empower data scientists and developers to understand machine learning models, protect people and their data, and control the end-to-end machine learning process.