365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
With so many pioneering online resources for open education, check out this organized collection of courses you can follow to become a well-rounded machine learning and AI engineer.
This article details an automated machine-learned approach to predict customer churn and its results across selected communication service providers around the globe.
Also: The Elements of Statistical Learning: The Free eBook; Explaining “Blackbox” Machine Learning Models: Practical Application of SHAP; What You Need to Know About Deep Reinforcement Learning; 5 Concepts You Should Know About Gradient Descent and Cost Function; Hyperparameter Optimization for Machine Learning Models
Image processing is one of the predominant needs in Deep Learning and metaphorically we can term CNN (Convolutional Neural Networks) as the king of this segment. With a plethora of documents and videos on this topic, through this blog series, we will approach CNN from the standpoint of a beginner.
A thorough understanding of the nuts and bolts of this algorithm certainly will bolster your confidence but pragmatically it’s not fully required, to give a simple metaphor its equivalent of learning to drive a car. An in-depth understanding of the working of the combustion engine doesn’t hurt but it’s not essential to drive or even to get a license !!. In the Deep learning world, a data scientist is expected to know a) When to use an algorithm. (b) How to use it
Carrying on our Car driving metaphor, a driver needs to know on available controls such as brake, accelerator, etc, and its application, such as brake will slow down /stop a vehicle whereas accelerator will do the reverse (a misunderstanding will be fatal !!) In deep learning such controls are technically coined as “Hyperparameters” and its imperative for us to know what controls are available and its application (an incorrect or a hazy understanding will lead to inaccurate results along with significant cash/effort burn)
With that context being set, let’s get on to CNN. Identifying animals in below picture wouldn’t be a tough ask for any of us
Within a fraction of a second, we will easily identify Zebra, Giraffe, and elephant (left to right). How about the below pictures?
We still can identify it as elephant, irrespective of angle(side or front pose), distortion, or how much the image is zoomed in/out we don’t really experience a difficulty in recognizing. Let’s try to comprehend the logic behind this simple task, the human brain doesn’t store a few fixed images of an object and try to do a pixel-to-pixel comparison between the stored image and image captured by the eyes, rather it tries to classify an object based on its features.
For example, in the case of an elephant, we understand it has wider ears, long trunk, columnar legs, etc. So whenever we see a picture containing the image of an elephant, our brain recognizes the features and classifies it as an elephant. Since all this computation happens so fast, we don’t get to recognize the complexity behind the whole process. Just imagine a picture of an object with wider ears, columnar legs, but with black and white stripes, our subconscious recognition will error out promoting us to take a closer look, that is because black and white stripes are not part of the features what we have recorded for an elephant.
CNN is an earnest attempt to replicate the human way of recognizing an object, it doesn’t do a pixel-to-pixel mapping rather tries to learn from the features. Covering CNN in one single blog will be an invitation for a deep slumber so to keep it engaging will break it into 3 parts
Part 1 and 2 will deal with the logic behind CNN — The bare thread algorithm final part will cover the implementation of it
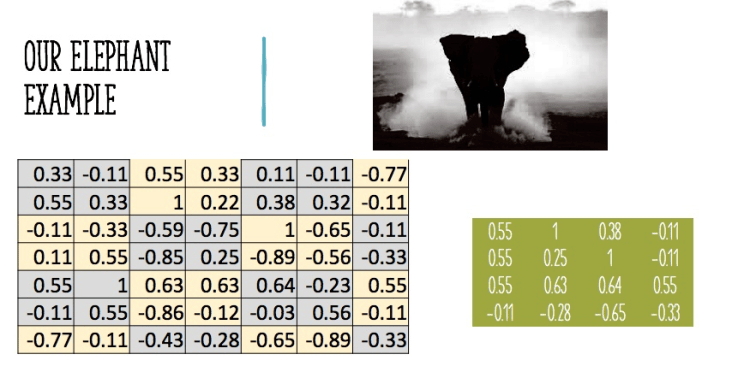
Let’s get back to our familiar example of identifying an elephant, I had converted the image into monochrome so that we can keep the calculation as simple as possible (in the real world it can be a colored high definition image)
Very first thing CNN does in image classification is “Feature mapping”. In this example, we can take any number of features such as Wider ear, Trunk, legs, etc
In our example, we will consider the wider ear of the elephant as a sample feature. To do a Feature mapping lets translate the sample image and sample feature into a grid as shown below
Image fitted into a 8*8 grid
The monochrome image of the elephant is now fitted into an 8 * 8 grid. Below figure captures the Feature(wider ear ) into a 3 * 3 Grid
Feature — Ear (3*3 Grid)
Next step is to digitize the image, so whichever cell has the image of an elephant will be assigned a +1 and other cells as -1, the resultant matrix is given below
Digitizing our 8*8 GridFeature mapped as +/- 1 grid
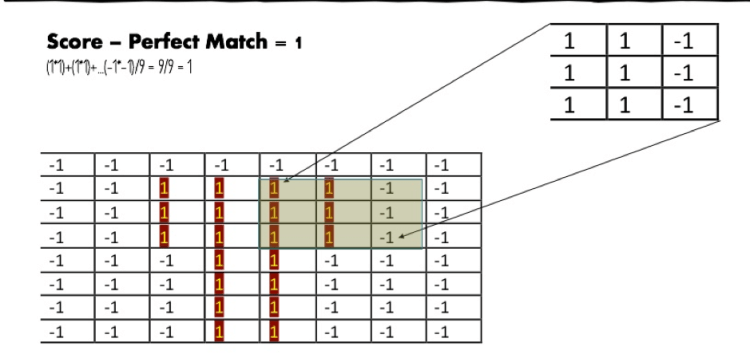
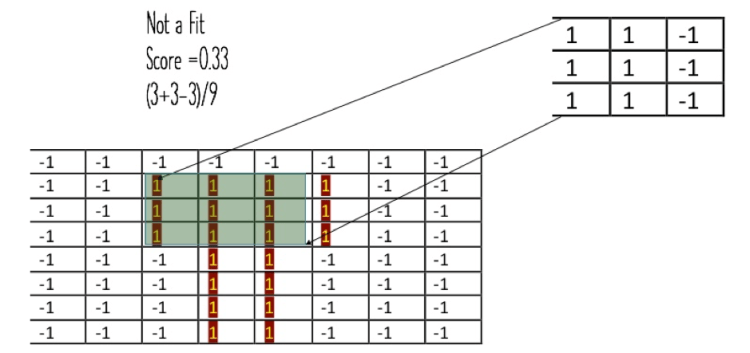
With image translated into numbers, feature mapping becomes easier, we traverse each and every cell of the base image with 3*3 grid to identify similarities. Consider below, In figure -1, its a perfect fit so we get to assign 1 to the cell, in figure -2 its only a partial fit as we are mapping ear to the head of an elephant.
Figure — 1
Partial fit
Figure-2: Partial Fit
We need to repeat the above exercise for each cell of the grid and for the number of features that we had selected for this exercise. Technically these 2 elements (Number of features, the Grid size of each feature) are the Hyperparametrs for “Feature mapping”, so when we get into the implementation mode, you will not actually code logic behind feature mapping rather you will specify the hyperparameter (remember the car metaphor !!)
AI Jobs
So at end of Feature mapping, we will be getting a layer of grids filtered by the features, this layer is our first level of Convolution, refer a sample grid in Figure-3( By increasing number of features and grid size you can have a better layer for each iteration)
Figure -3
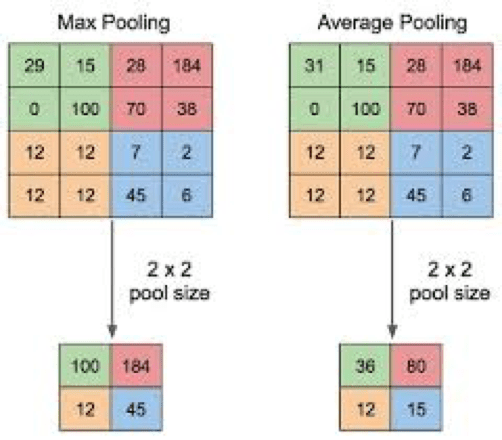
The second phase of CNN is called Pooling, this is done to shrink the resultant grid/parameters so that we have a manageable chunk for processing without compromising on information loss. Few popular pooling algorithms as Max pooling, min pooling, average pooling, etc. In the below figure, we see an example of max pooling
Max Pooling
Applying max pooling to our grid we get a compressed matrix as shown below
Applying Pooling
Hyperparameters for pooling is the size of the pool (in our case its 2*2) and strides it takes (in our example its 2*2)
The last phase of this blog is “Normalization” this is similar to what we would have experienced in a conventional work setup wherein appraisal rating will be normalized at a portfolio/org level to remove the bias.
If you are wondering how this applies to our example, consider a model which was trained to classify elephants, if the model was built fully on Asian elephants and then we apply it for an African elephant, it will try to relearn as there are minor differences between both this category. Technically this differences doesn’t really matter as we are still solving the problem of “Classifying elephants” so to avoid this minor biases impacting our model we apply normalization
In our example, we will apply ReLU(Rectified Linear Unit), for beginners lets keep it simple, ReLU retains all positive values and any negative value is converted as zero (more on ReLU in a different blog)
Applying, ReLU to our example grid
Are we done? very close… we can iteratively apply concepts we learned, Filtering,(F) Normalization(N), and Pooling(P) until we get a really compressed version, metamorphically this will be like a grand sandwich with multiple layers
This concludes Part-I of this blog, in Part-2 we will get into more interesting part in using this grid to determine the object and how neurons fire to accomplish our objective, for ease of following you can also refer to my video on the same topic
About: Data-Driven Science (DDS) provides training for people building a career in Artificial Intelligence.
Data Science is a new and exciting field which has made the lives and careers of many people very fruitful. However, this growth was caused by the struggle and hard work of several people. In this article, we will talk about some of these individuals, along with how they’re contributing to our field.
Demis Hassabis
Demis Hassabis. Photo: Souvid Datta/Backchannel
Demis is a British AI researcher and neuroscientist, most popular for being the founder and CEO of Deepmind, an Alphabet subsidiary which made headlines after beating the Go world champion, Lee Sedol, in a five-match game.
A child prodigy, Demis was adept at chess since childhood, and reached the master standard by the age of 13. He studied Computer Science at the University of Cambridge, and represented the college for varsity chess matches. He worked closely with the famous games designer Peter Molyneux at Bullfrog Productions and Lionhead Studios, where he worked as the lead AI programmer. He went on to form his own game studio afterwards, Elixir Studios, which was specialized in publishing strategy games.
While games are the perfect platform for developing and testing AI algorithms quickly and efficiently, ultimately we want to apply these techniques to important real world problems, because the methods we’ve used are general purpose, our hope is that one day they could be extended to help us address some of society’s toughest and most pressing problems — from medical diagnostics, to climate modeling to smart phone assistance. We’re excited to see what we can use this technology to tackle next.
After his career in the video games industry, he went back to academia to obtain a PhD in cognitive neuroscience from University College London, where he co-authored severalinfluential papers on neuroscience and did groundbreaking research on the human brain.
While he was doing his Postdoctoral Research at UCL, he met Shane Legg, who, along with Mustafa Suleyman, would be his cofounders for Deepmind.
Deepmind started with the mission of combining neuroscience with machine learning to form general-purpose algorithms which would work towards building an Artificial General Intelligence (AGI).
Deepmind’s main breakthrough was when they managed to train a computer to play Atari games, using the raw pixels on the screen as an input. Soon after this achievement, Google purchased the company for £400 million. After the Google acquisition, the company made several more achievements, like building AlphaGo, a program that defeated world champion Lee Sedol at the complex game of Go. In fact, this victory was so unlikely that the Go grandmaster, Lee Sedol, was wondering whether he’d beat AlphaGo by 5–0 or 4–1, before being defeated 4–1 by AlphaGo himself.
Currently, Deepmind is focussed on using its AI capabilities to solve the difficult problem of protein-folding. The tool they’re using to do this is called AlphaFold, which has already won prizes in the field.
Currently, Demis continues to work as the CEO of Deepmind, solving complex problems through AI and discussing complex issues like ethics in Artificial Intelligence.
Geoffrey Hinton
Geoffrey Hinton. Photo: phys.org
Geoffrey Everest Hinton is a Canadian cognitive psychologist and computer scientist, most noted for his historic work on artificial neural networks. One of his innovations is the popularization of using backpropagation in Neural Networks. He is known for making disruptive innovations like these in the field of Deep Learning. Backpropogation helps in optimizing the internal weights of neural networks by propogating the error at each layer backwards.
According to an interview he did with Andrew Ng, his interest in AI started with an interesting incident. One day in high school, his friend came up to him and told him that the brain uses holograms. This got him thinking about how the human brain would actually work. Coming from a family of scientists, which includes George Boole, Geoffrey himself did a BA in experimental psychology from the University of Cambridge, where he studied physiology, physics, philosophy and psychology.
In science, you can say things that seem crazy, but in the long run they can turn out to be right. We can get really good evidence, and in the end the community will come around.
After his interest in AI peaked, he decided to pursue a PhD in AI at the University of Edinburgh under the guidance of Christopher Longuet-Higgins. Although Geoffrey was very interested to work on neural networks, his ideas were disregarded by the community in the UK.
Geoffrey later moved to the US, in pursuit of a career in the field of AI. It was while working as a Professor in Carnegie Mellon University that he did his seminal research on the application of backpropagation algorithm to multi-layer neural networks.
Another innovation that Hinton is known for, is Boltzmann Machines. It’s a learning algorithm applied to big, densely connected nets, where only a few nodes are visible to the “outside world”. It’s one of the algorithms used to learn hidden representations from data.
AI Jobs
In 2001, he was made a Fellow of the Royal Society for his work in Artificial Neural Networks, because of his research in comparing the effects of brain damage to that of losses in neural networks. In 2018, he was given the order of Canada for contributions in the field of AI, and also made a Fellow of the Canadian Royal Society.
In 2012, he decided to create an AI startup with two of his students while working at the University of Toronto, called DNNresearch Inc. This startup was quickly picked up by Google, cementing and boosting Hinton’s research in AI through funding support.
Since 2013 he divides his time working for Google (Google Brain) and the University of Toronto. In 2017, he cofounded and became the Chief Scientific Advisor of the Vector Institute in Toronto.
Hinton was awarded the 2018 Turing Prizealongside Yoshua Bengio and Yann LeCun for their work on deep learning. Hinton — together with Yoshua Bengio and Yann LeCun — are referred to as the “Godfathers of AI” and “Godfathers of Deep Learning”.
Yann LeCun
Yann LeCun | Image: Facebook
Yann LeCun is a French-American computer scientist working primarily in the fields of computer vision, deep learning, and computational neuroscience. He is most famous for having invented Convolutional Neural Networks, and his immense contributions in the field of Computer Vision. He was also one of the contributors, along with Geoffrey Hinton, responsible for building the widely used backpropagation algorithm.
Born in Paris in the 60’s, Yann was always interested in learning about intelligence. While completing his engineering diploma in ESIEE Paris, he read an article on perceptrons, which piqued his curiosity and made him more eager to learn about them.
He did a PhD in Computer Science from Université Pierre et Marie Curie in 1987 during which he proposed an early form of the backpropagation learning algorithm for neural networks. This paper was read by Geoffrey Hinton, and so, Yann got a chance to work with him in a postdoc position at the University of Toronto.
Our intelligence is what makes us human, and AI is an extension of that quality.
While at UToronto, he was starting with to think of the basics of how Neural Networks can be applied on images, which would lead to the basics of Convolutional Neural Networks. In 1988, he joined the Adaptive Systems Research Department at AT&T Bell Laboratories. After joining, his first task was to design a new Optical Character Recognition system. He used his ideas to design an algorithm which would provide better results than existing ones. This was the first version of a Convolutional Neural Network (CNN).
Since there were no standardized programming environments or work stations in the 80’s, LeCun, along with his friend Leon Bottou started writing a software system called SN to experiment with machine learning and neural networks. It was built around a home-grown Lisp interpreter that eventually morphed into the Lush language. Most of his Neural Network experiments, including the ones at AT&T, were done on this system.
The bank check recognition system that he helped develop at AT&T was widely deployed by NCR and other companies, reading over 10% of all the checks in the US in the late 1990s and early 2000s.
In 1996, after the breakup of AT&T into 3 companies, he joined AT&T Labs-Research as head of the Image Processing Research Department. Foreseeing the sudden availability of a large amount of document/image information with the spread of internet, LeCun worked on building an image & document compression algorithm, called the DjVu. This algorithm is used by many websites, notably the Internet Archive, to distribute scanned documents.
He is the Silver Professor of the Courant Institute of Mathematical Sciences at New York University, and Vice President, Chief AI Scientist at Facebook. LeCun — together with Geoffrey Hinton and Yoshua Bengio — are referred to by some as the “Godfathers of AI” and “Godfathers of Deep Learning”.
Stuart Russell
Stuart Russell | Image: TED
Stuart Jonathan Russell is a computer scientist known for his contributions to Artificial Intelligence (AI). Russell is the co-author of one of the most popular textbook in the field: Artificial Intelligence: A Modern Approach used in more than 1,400 universities in 128 countries. He founded and leads the Center for Human-Compatible Artificial Intelligence (CHAI) at UC Berkeley.
Stuart Russell was born in Portsmouth, England. He was in boarding school in London, at St. Paul’s, and had the opportunity to avoid compulsory rugby by doing a computer science course at a nearby college. He made several projects and became unpopular for using up the college’s computer for hours. He wrote a chess program, during the programming of which he learned some of the stuff he would teach in his book.
His academic interest being Physics, he received his Bachelor of Arts degree with first-class honors in Physics from the University of Oxford. For graduate school, he applied to do theoretical physics at Oxford and Cambridge, and to do computer science at MIT, Carnegie Mellon and Stanford, not realizing that he’d missed the deadlines for applications to the U.S. Fortunately Stanford waived the deadline, so he went to Stanford and his PhD in Computer Science.
During his PhD, Stuart focussed on trying to solve the problem of decision-making in AI, through research on inductive reasoning and analogical reasoning. Stuart is drawing on how the human brain makes decisions, by having a rich store of abstract, high-level actions, and applying these learnings to improve decision-making in AI.
The robot is not going to want to be switched off because you’ve given it a goal to achieve and being switched off is a way of failing — so it will do its best not to be switched off. That’s a story that isn’t made clear in most movies but it I think is a real issue.
He actively campaigns on preventing the risks which can come from building too advanced an AI. According to him, some of the ways AI can go wrong are:
A super-optimizer function, which ends up harming humanity in performance of that function, à la the book Superintelligence.
Humanity ends up building optimized killing machines (autonomous weapons), which was portrayed in Slaughterbots, a film he helped make.
Overuse of AI may turn something like Wall-E into a reality, where humanity just focussed on consuming entertainment while the machines take over all the other tasks.
Apart from working for ethical AI, he is a Professor of Computer Science at the University of California, Berkeley and Adjunct Professor of Neurological Surgery at the University of California, San Francisco. He founded and leads the Center for Human-Compatible Artificial Intelligence (CHAI) at UC Berkeley.
We hope that this article was useful for you in learning about the major people working in the field of Data Science and about their journey.
Subscribe to read more articles related to Data Science & AI! We will be writing about more people who’ve done great work in the field of data science. If there is anyone that you think we missed or if you want us to include a specific person in the next article, be sure to reach out to us.
How does deep learning solve the challenges of scale and complexity in reinforcement learning? Learn how combining these approaches will make more progress toward the notion of Artificial General Intelligence.