The new typed feature schema streamlined the reusability of features across thousands of machine learning models.
Originally from KDnuggets https://ift.tt/2Wn2RaU

365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Originally from KDnuggets https://ift.tt/2Wn2RaU

What are the skills you need to become a data scientist in 2020?
‘Data Scientist’ has been one of the fastest-growing jobs in recent years. It’s an exciting and highly paid career, that presents you with tons of opportunities for development. What’s more, there’s still an abundance of positions as the supply of qualified data scientists is yet to catch up to the huge business demand.
We’ve been doing this research for 3 years now. And in this article, we’ll share the top skills that will make you successful in this super-competitive field.
We’ve also created a very cool and interactive PowerBI dashboard, so if you prefer to analyze the data yourself, follow this link. And we’ve got another article where we make a comparison between the last 3 years. Here, we focus on the year 2020.
In 2020, our study portrays a data scientist’s collective image as a male (71%), who is bilingual, has been in the workforce for 8.5 years (3.5 years of which has worked as a data scientist). He or she works with Python and/or R and has a Master’s degree.
You can’t become a data scientist without a strong programming skillset. And in 2020, general-purpose languages are used more extensively by data scientists than ever before.
According to our own annual research, 74% of current data scientists are proficient in Python, 56% use R, and 51% – SQL.
To say that Python’s popularity is rising, would be an understatement. Python is hands-down the preferred language for statistical modeling by data scientists. No wonder IEEE – the world’s largest technical professional organization for the advancement of technology deemed Python “the big Kahuna” of programming languages!
Well, Python is more than just a fan favorite. In fact, it seems to be very close to dominance in terms of what employers are searching for, as it is the language associated with the highest salaries worldwide. The demand for Python as a preferred skill by employers is soaring sky-high. Numbers don’t lie – 70% of F500 data scientists employ Python. Both Python and R have increased in popularity over the years and F500 companies are reflecting that in their organizations. Moreover, Python is the number 1 programming language in numerous industries that use advanced analytics for their business and product development.
SQL’s popularity is growing fast and it almost catches up to the runner-up R. Today’s businesses create quintillion bytes of data on a daily basis. That makes SQL a super-important tool in a data scientist’s toolbox since it is critical in accessing, updating, inserting, manipulating, and modifying large volumes of data. It also integrates smoothly with other scripting languages like R and Python. Besides, BI tools such as Tableau and Power BI are heavily dependent on it, thus increasing its adoption.
So, if you’re looking for great career opportunities across numerous industries, you literally can’t go wrong with Python, R, and SQL. And if you’re a beginner eager to make the first steps in your data scientist career, the only thing left to do is start learning!
A few years ago, as data science had just emerged, companies were recruiting professionals with different backgrounds and training them in-house. As a result, in some cases, relatively junior candidates were hired for senior data scientist roles. Our numbers show that as more people gain experience in the field, first-year data scientists account for a smaller portion of the total.
The idea that experience plays a bigger role in recruiting is reinforced by the finding that the average data scientist professional in 2020 has been in the workforce for 8.5 years.
Therefore, in today’s job market one needs to accumulate the necessary working experience in an analytical position before they are ready for a data scientist job title.
Our study examined data scientists’ previous job occupation and title 1 and 2 jobs ago. Two positions prior to their current role, the average data scientist in our sample was either already a Data Scientist (29%); an Analyst (17%); or worked in Academia (12%). The figures change when we look at the positions our cohort occupied immediately before entering their current role: data scientist (52%); analyst (11%); a researcher in academia (8%).
The large majority (95%) of current data scientists have a Bachelor’s degree or higher. Out of those, 53% hold a Master’s degree, and 26% – a Ph.D. We can say that a person needs to aim at a second-cycle academic degree. However, it is also true that a Bachelor’s can get you the job as long as you have the technical skills and preparation required.
In general, 19 out of 20 data scientists have a university degree.
Considering our study, 55% of the data scientists in the cohort come from one of three university backgrounds. These are Data Science and Analysis (21%); Computer Science (18%); and Statistics and Mathematics (16%). There are fewer representatives of Economics and Social Sciences (12%), Engineering (11%), and Natural Sciences (11%). All of these are technical courses that prepare graduates for the quantitative and analytical aspects of the job.
They say that ‘if you don’t know where you are going, any road will take you there’. In this case, things are a bit different. If you know that you want to become a data scientist, it will be beneficial to study the career path of others who have taken the data scientist career path… And learn from their experience. We hope that this article was useful and will guide you in the right direction if you decide to pursue a data scientist career path!
Check out the complete Data Science Program today. Start with the fundamentals with our Statistics, Maths, and Excel courses. Build up a step-by-step experience with SQL, Python, R, Power BI, and Tableau. And upgrade your skillset with Machine Learning, Deep Learning, Credit Risk Modeling, Time Series Analysis, and Customer Analytics in Python. Still not sure you want to turn your interest in data science into a career? You can explore the curriculum or sign up 12 hours of beginner to advanced video content for free by clicking on the button below.
The post What are the Skills You Need to Become a Data Scientist in 2020? appeared first on 365 Data Science.
from 365 Data Science https://ift.tt/2Lo1NwN
Originally from KDnuggets https://ift.tt/2xLTA2x
Originally from KDnuggets https://ift.tt/2yE4W99

1. Project Overview:
In this project, we will try to predict the possibility of a booking for a hotel based on different factors and also try to predict if they need special requests based on different features. The data set contains booking information for a city hotel and a resort hotel, and includes information such as when the booking was made, the number of adults, children, and/or babies, and the number of available parking spaces, among other things. From it, we can understand the customer’s’ behavior and it might help us make better decisions.
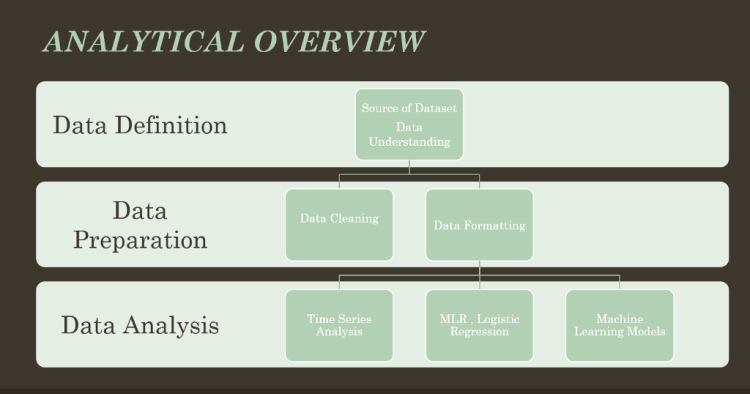
The process of our analysis will be by the following step: Define our Business question, understanding the Datasets, Data preparation and wrangling, analyze the data, model the data and conclusion.

My goal for this project is predicting which kind of customers need special request and predicting the possibility of a booking for a hotel by knowing different features. This will help the hotel booking company to make better decisions.
R library used: fun Modeling, tidyverse, Hmisc, DataExplorer, dplyr, caret, lattice, magrittr, ggplot2, scales, gridExtra, psych, plotly and many more.
The data set contains 119390 rows and 32 columns.
4. Machine Learning using Logistic Regression in Python with Code

4.Data preparation / Wrangling:
We are replacing missing values in Children column from the corresponding Babies column. We are also replacing undefined as SC. Both means no meal package. Replacing Undefined with mode in the market segment column. Replacing Undefined with mode in the distribution channel column.
5. Analyzing the data:
•Categorical Data and Continuous Data analyzed. Uni variant, Bi variant and multi variant analysis performed.


MAJOR OBSERVATIONS FROM EDA
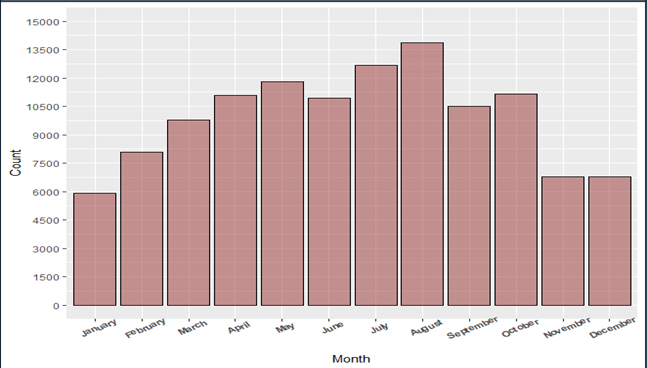
1.Number of bookings made were highest in the month of July and August and lowest in January.
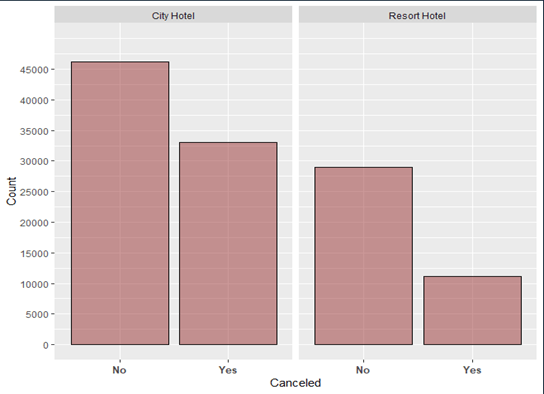
2.Bookings were more for the City hotel than the Resort hotel.
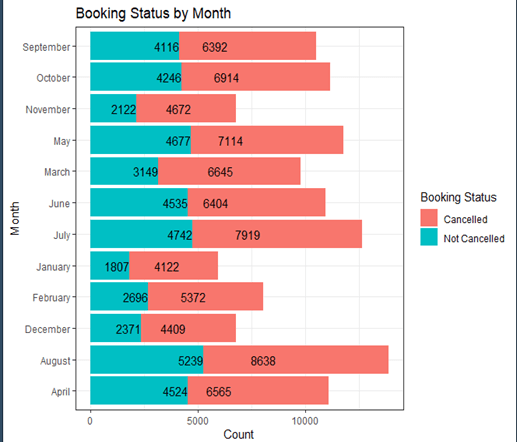
3.41.7% of the total bookings were cancelled for City hotel and 21.7% for the Resort hotel.
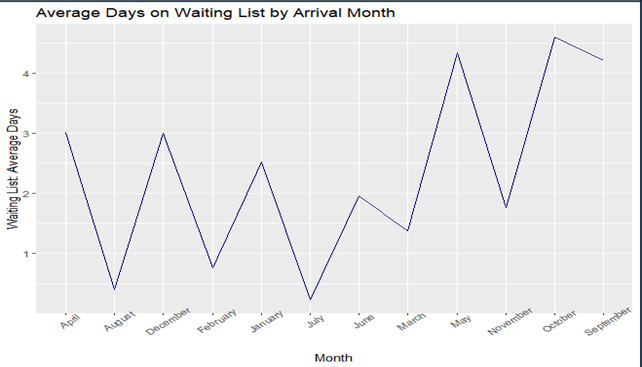
4.Number of days that elapsed between the entering date of the booking and the arrival date is less for the people who cancelled.
5.As the hotels are in Portugal Europe, the bookings are mostly with European countries, Highest is Portugal with 48.59k bookings.
6.77% of the bookings are made with bed and breakfast.
7.Only 3% are repeated guests.
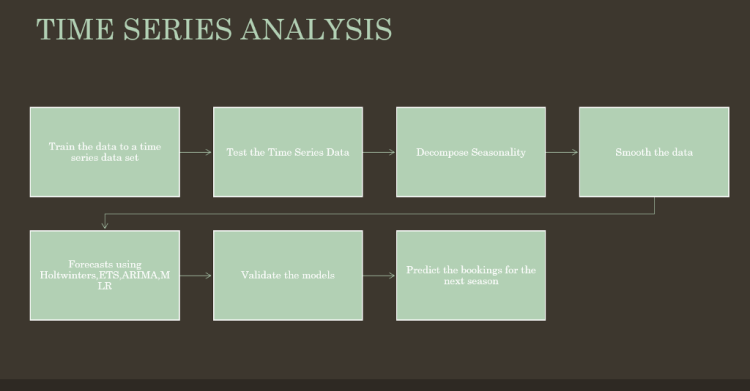

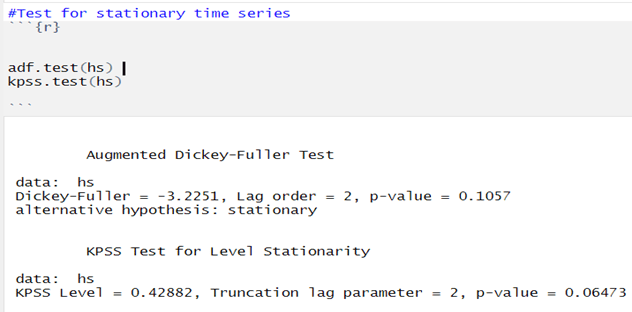
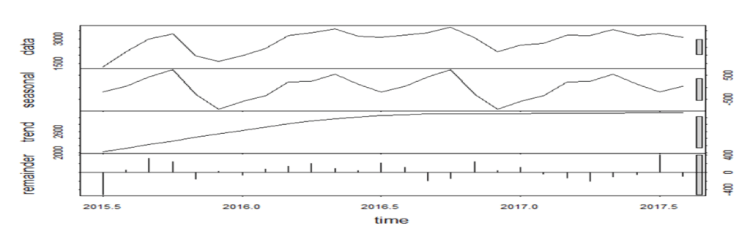
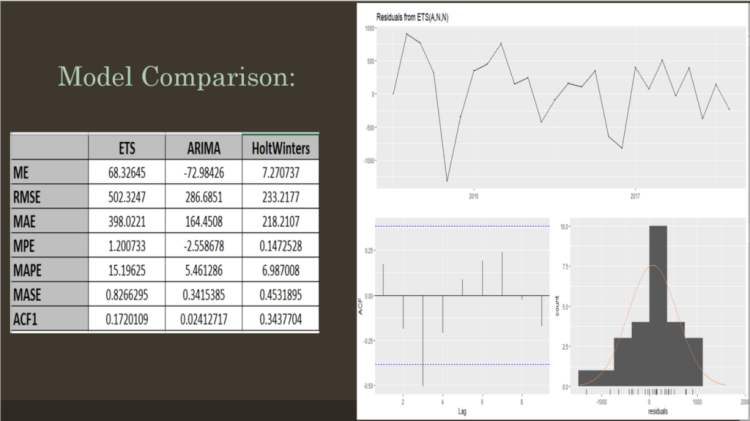
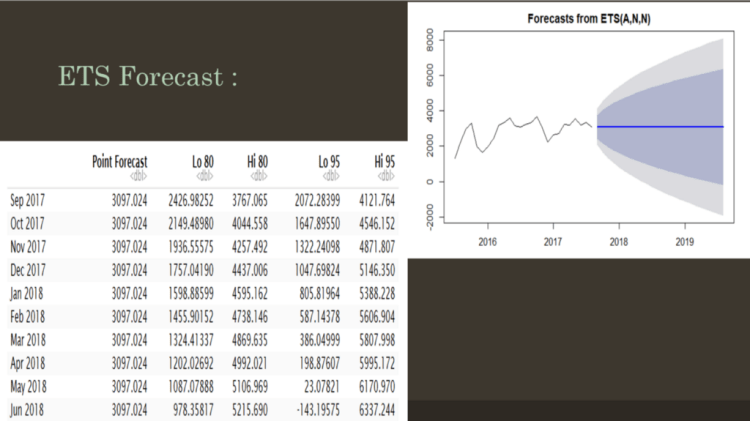
6.MODEL BUILDING –FOR BOOKING CANCELLATIONS :
1)USING MULTIPLE LOGISTIC REGRESSION
•Build the model using some variables from the dataset as independent variables to predict booking cancellations.
•80.4% accuracy in predicting the model with testing dataset.
LIMITATIONS
•Execution time is high with large datasets.

RIDGE REGRESSION
•Model was build using all the independent variables except for the reservation status and date column to predict the booking cancellations.
•Performed k-fold cross validation.
•80.9% accuracy in predicting the model with testing dataset.
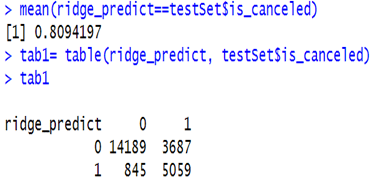
LASSO REGRESSION
80.57% accuracy in predicting the model with testing dataset.
Prepared the confusion matrix.

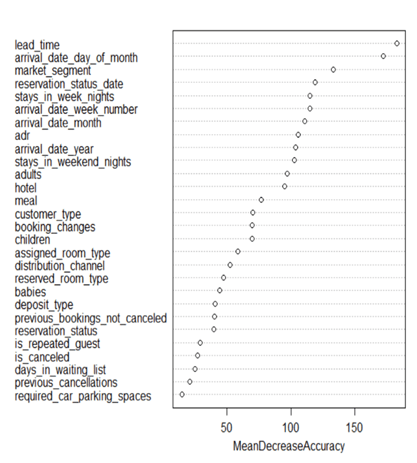
3)USING RANDOM FOREST :
•Model was build using all the independent variables except for the reservation status and date column to predict the booking cancellations.
•80% of the data as training data and 20% as testing.
•93.9% accuracy in predicting the model with testing dataset.
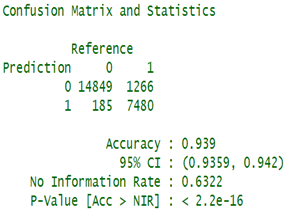
7.MODEL BUILDING- FOR SPECIAL REQUEST :
•Model was build using all the independent variables to predict the booking cancellations.
•Number of decision trees are 500 and the variable at each split is 5.
•83% accuracy in predicting the model with testing data set.
•Tuning the model by increasing mtry.
8. Conclusion:
•Booking cancellation model will help to Identify the likelihood of bookings being cancelled and makes it possible for hotel managers to take measures to avoid these potential cancellations, such as offering services, discounts, or other perks.
•The prediction model enable hotel managers to mitigate revenue loss derived from booking cancellations and to mitigate the risks associated with overbooking (reallocation costs, cash or service compensations).




Hotel Booking Demand Project Using Different Models was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.

Even the initial concerns about Artificial Intelligence (AI) have not slowed its adoption. Experts say that some companies are already taking advantage and that companies that do not adopt new technology cannot compete over time. However, AI adoption seems to be slowing down despite early successful case studies.

Why are AI services so slow in manufacturing?
AI is growing, but getting accurate numbers is difficult because the definition of machine learning, AI, machine vision, and other technologies is often obscure. For example, the use of a robotic arm and camera to inspect parts may be advertised as a machine learning or AI device.
Although the device works well, it can only compare images taken to others that have been added manually to the library. Some would argue that this is not a machine learning device because it is a pre-program decision, not a “learned” from the machine’s experience.
Going forward, this article uses generic terms when referring to Artificial Intelligence technology. When deciding on a design or product, make sure you understand the differences like buzzwords versus unsupervised and other buzzwords that are obscured by sales and marketing efforts.
According to a report by Global Market Insights published in February this year, the market size of AI in manufacturing is projected to exceed $ 1 billion in 2018 and is expected to grow at a CAGR of more than 40% from 2019 to 2025. Sources say the AI is moving slowly.
Some resources often compare AI case studies to the overall size of the manufacturing market, talk about investing in individual companies or, in particular, AI. From this prospect, AI growth is slow and it is for some reason other than the above.
AI is still a new technology. Most success is in the form of testbeds, not full-scale projects. In large companies, a small adjustment can affect billions of dollars, so managers are reluctant to test full-scale projects until they find the best solution. Also, companies of any size need to justify or guarantee the return on investment (ROI). This can lead to smaller projects, focusing on low-hanging fruit, or projects that can be separated into a testbed.
To know more- AI In Manufacturing — 10 AI Manufacturing Use Cases
Small or isolated projects may work well as a test, but in theory, AI should provide greater benefits when operating at larger scales. This usually requires greater connectivity and data to maintain accuracy. This is the next reason for AI to move slowly: scale and connectivity.
Most companies have legacy devices that do not provide data or have the means to send data to another location. New technology is working on retrofitting legacy equipment, but there may be infrastructure issues for design engineers. For example, some factories do not have easy access to smart sensors or data that provides greater access to the IT network.
4. Machine Learning using Logistic Regression in Python with Code
As AI grows and continues through all resources, maturity, confidence, ROI, scaling and connectivity can slow down mass adoption.
What AI can do for manufacturing and design?
This section may be difficult because it relates to the previously mentioned blurred lines and buzzwords. Designers and manufacturers have used CAD tools, machine vision, and maintenance attendee management before. AI technology is taking these technologies to new heights, but personal devices can be discussed wherever the AI is on the spectrum.
AI CAD tools
Design engineers have features they need to achieve when developing new components and equipment. To do this, it is important to understand the information about the end user’s applications and needs, from materials and processing. CAD programs with theoretical data include tools such as finite element analysis (FEA), and the design engineer must add data manually or select from the library.
A new tool in CAD technology is using AI to create product design. It takes the necessary features and inputs for the design and also generates all possible materials, geometries, and costs. If the new features are user friendly, the technology is just as good as the user.
Not only do you need knowledge of what to add to the specification and input, but the user still needs to review the possibilities to choose the best solution. This type of AI CAD technology helps to increase the capabilities of design engineers and saves time because the design engineer does not have to create multiple iterations manually.
How to Fit Artificial Intelligence into Manufacturing was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.

The domain of data science has been at the focal point of discussion for quite a few years now and there are no signs of it slowing down. As more and more businesses, organizations, and companies are waking up to the importance of extracting important insights from the pile of data that they are sitting on, the demand for data scientists, data engineers, and other experts in the field has increased significantly.
No wonder that while there’s an increased focus on bringing such data science talent onboard, a whole new set of data science titles and roles too have been created to address the needs of the market.
Recently, a lot has been discussed and written about the differences between various roles in the domain of data science.
Among others, the ones that have got the spotlight on them are those that discuss and debate the differences between data scientists and data engineers.
If you are wondering what triggers this tremendous interest in these roles, a change in perspective that has been felt over the years could be the driving factor.
If you step back a couple of years ago, you will find that the predominant focus was on retrieving precious insights from data. As companies and organizations started making data-based and data-driven decisions, which brought several benefits their way, the significance of data management started to sink in the industry — slowly but surely. This also made the interested parties realize that the quality of data was important to derive useful insights because it’s the principle of “Garbage In, Garbage Out” that works in the domain of data science too. Even if you are capable of creating the best models, your results are likely to be weak and ineffective in case your data isn’t qualitative. And this was what brought the role of the data engineer under the spotlight.
According to Gartner, merely 15% of big data projects ever make their way into production. According to domain experts, one of the chief reasons behind such failures is due to the inability to build a production pipeline, which is one of the principal tasks of a data engineer.
In the modern age of analytics, data scientists get most of the spotlight and attention.
However, the roles played by data engineers are equally important, though they are often overlooked. It’s important to realize that data science (and even data analytics) would fail to flourish if no data engineering workbench exists. If you don’t believe it, you can consider what Glassdoor’s records say.
According to Glassdoor’s data in 2018, the number of job openings earmarked for data engineers was almost five times more than that for data scientists. Elsewhere, one may find data scientist jobs exceeding the number of data engineer jobs though some say it could be because numerous organizations don’t always (or are unable to) draw a distinct line between a data scientist and a data engineer. Thus, they end up posting jobs for the former whereas in reality, the jobs should have been seeking data engineers instead. Such actions on the part of organizations are perhaps triggered by their ignorance of the significant differences between data scientists and data engineers.
4. Machine Learning using Logistic Regression in Python with Code
Many reports have revealed that the majority of organizations require more data engineers than data scientists on their team. So, the question comes to this — what exactly is data engineering and how’s the role played by a data engineer different from that played by a data scientist.
Let’s dig a little deeper to answer the questions and find out the differences between data scientists and data engineers.
What would be the future jobs for data science in terms of artificial intelligence and machine…

S/He is a professional with specialized skills in creating software solutions around Big Data.
Another way of defining a data engineer is that s/he is an inquisitive, skilled problem-solver, who loves both data and creating things that are useful to others. Thus, along with data scientists and business analysts, data engineers form an integral part of the team effort that converts raw data in ways which offer organizations useful insights and provides them with the much need competitive edge.
To understand what the role of a data engineer is, it can be said that this professional is someone who builds, develops, evaluates and maintains architectures like databases and large-scale processing systems. In contrast, a data scientist is someone who cleans, organizes, and acts upon (Big) data.
It’s the job of data engineers to suggest and at times, even implement ways to improve data quality, efficiency, and reliability. To handle such tasks, they need to utilize a range of tools and languages to blend systems together or try to track down opportunities to get hold of new data from other systems, which can help system-specific codes, for example, to act as the basic information in advanced processing by data scientists.
A data engineer will also need to make sure that the architecture that’s in place is capable of supporting the needs of the data scientists as well as the business/organization and its stakeholders.
In order to deliver the required data to the data science team, it will be the responsibility of the data engineers to develop data set processes for data mining, modeling, and production.

With respect to skills and responsibilities, you’ll find considerable overlapping between data scientists and data engineers. One of the key differences between data scientists and data engineers is the area of focus. For data engineers, the emphasis is on creating architecture and infrastructure for data generation. On the contrary, the focus of data scientists is on advanced statistical and mathematics analysis on that generated data.
Though the role of data scientists demands a constant interaction with the data infrastructure that the data engineers have created and maintained, the former isn’t responsible for that infrastructure’s creation and maintenance. Rather, they can be called the internal clients, whose job is to perform high-level business and market operation research to spot trends and relations, which in turn need them to use an array of sophisticated methods and machines to interact with the data and act upon it.
It’s the job of data engineers to provide the necessary tools and infrastructure to support data analysts and data scientists so that these professionals can deliver end-to-end solutions for business problems. Data engineers are tasked with creating high performance, scalable infrastructure that helps deliver business insights with clarity from raw data sources in addition to implementing complex analytical projects where the emphasis is on gathering, evaluating, managing, and visualizing data along with developing real-time and batch analytical solutions.
Perhaps you now understand that despite some key differences between data scientists and data engineers, the formers depend on the latter. While data scientists deal with advanced analysis tools like Hadoop, R, advanced statistical modeling, and SPSS, the focus of data engineers remain on the products that support such tools. Thus, a data engineer may deal with NoSQL, MySQL, SQL, Cassandra, etc.
In a way, you can say that in the data value-production chain, the role of data engineers is akin to the plumbers since they facilitate the job of data scientists, data analysts and other professionals working on the fed of data science. As with any infrastructure, plumbers don’t get the limelight, and yet, they are irreplaceable since nobody can get any work done without them. The same applies to data engineers as well.
7 Tools to Create A Rockstar Data Science Portfolio

Due to the difference in their skill sets, differences between data scientists and data engineers translate into the use of different tools, languages, and software use.
For data scientists, common languages in use are Python, R, SPSS, Stata, SAS, and Julia to construct models.
However, Python and R are the most popular tools without a doubt.
When these data science professionals are working with Python and R, they often resort to packages like ggplot2 to make remarkable data visualizations in R or opt for the Pandas (Python data manipulation library). There are several other packages that can come for them, which include NumPy, Scikit-Learn, Statsmodels, Matplotlib, etc. The data scientist’s toolbox is also likely to have other tools like Matlab, Rapidminer, Gephi, Excel, etc.
The tools that data engineers often work with include Oracle, SAP, Redis, Cassandra, MongoDB, MySQL, PostgreSQL, Riak, neo4j, Sqoop, and Hive.
Languages, tools, and software that both the parties have in common are Java, Scala, and C#.
One of the key differences between data scientists and data engineers emerges from the emphasis given on data visualization and storytelling, which gets reflected in the tools these professionals put to use, some of which are mentioned above.
The Netflix Data Scientist Interview

As mentioned before, several organizations fail to distinguish the key differences between data scientists and data engineers and often task the former with the job that the later is specialized to do. For example, asking data scientists to create a data pipeline, which is the job of a data engineer, would mean making the former function at just 20–30% of their actual efficiency. So, it becomes important to know the differences between data scientists and data engineers and hire each for roles specifically designed to match their skill sets.
What are the differences between data scientist and data engineer? – Magnimind Academy
What are the differences between data scientist and data engineer? was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally from KDnuggets https://ift.tt/2yDvgjL
Originally from KDnuggets https://ift.tt/2zoxtzK
Originally from KDnuggets https://ift.tt/2WBKFsL
