365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Data Labeling — Nine Questions to Ask before Selecting a Data Annotation Company
ByteBridge: a Human-powered Data Labeling SAAS Platform
Data Annotation Service
Data annotation technique is applied to make the objects recognizable and understandable for AI models. It is critical for the application of machine learning in security, autonomous driving, aerial drones, and many other industries.
Data Annotation Outsourcing Service and Its Current Situation
There is no doubt that the performance of an AI system depends more on the training data than the code.
ByteBridge: a Human-powered Data Labeling SAAS Platform
However, data annotation is a repetitive, time-consuming, and laborious processing regarding the tremendous volumes of raw data required for machine learning algorithms.
Therefore, many ML companies prefer outsourcing services so that they can focus on technology development, which in turn helps them get a competitive advantage in the AI industry.
Big Data Jobs
There are a variety of outsourcing companies available in the data annotation market, and the traditional data annotation outsourcing workflow goes in this way:
a. Defining the work and outlining the project’s requirement
b. Looking for a trustworthy service provider and signing contracts on the project
c. The outsource company screening and training the skilled annotators
d. Project launch
e. Data quality verification and inspection
As you can see from the process, it usually takes at least one week on project analysis and project team building before the data annotation starts, which lowers the efficiency.
Moreover, the pricing is not always transparent. Usually, they charge per hour. For computer vision data this is usually around $5-$10 per hour per worker.
How to Select a Data Annotation Outsourcing Company?
Here are some questions you may take into account while choosing the partner.
1 What datatypes do you support?
2 How about the data quality control?/How to ensure high-quality data?
3 Is the data labeled manually?/How is the data labeled, manually or semi-automatic labeled?
4 Do I need to form my own in-house team?
5 Tell me more about our data security process
6 How you ensure project scalability
7 Compared to other platforms, why yours is better?
8 Do you have a free trial?
9 Pricing
ByteBridge.io, a Human-Powered Data Labeling Platform(SAAS)
ByteBridge is a human-powered data collection and labeling platform(saas) with robust tools and real-time workflow management. It provides accurate and consistent high-quality training data for the machine learning industry.
Via the ByteBridge dashboard, you can seamlessly upload your project and utilize end-to-end data labeling solutions such as visualizing labeling rules. Through the dashboard, you can also manage and monitor your project in real-time.
ByteBridge: a Human-powered Data Labeling SAAS Platform
As you can manage your project in real-time, you can initiate or terminate your task as you wish according to your own timeline.
ByteBridge: a Human-powered Data Labeling SAAS Platform
Meanwhile, the transparent pricing which eliminated the various heavy commissions apparent in the current market lets you save resources for more important investments.
End
“High-quality data is the fuel that keeps the AI engine running smoothly. The more accurate annotation is, the better algorithm performance will be,” said Brian Cheong, founder, and CEO of ByteBridge.
Designed to empower AI and ML industry, ByteBridge.io promises to usher in a new era for data labeling and accelerates the advent of the smart AI future.
Machine learning success depends on the human workforce.
Machine learning success depends on the human workforce.
Data Annotation Service Market is Booming
“The global data collection and labeling market size was valued at USD 1.0 billion in 2019 and is expected to witness a CAGR of 26.0% from 2020 to 2027,” quote from a market analysis report by grand view research. At present, the application scenarios of artificial intelligence are constantly extended.
AI Data Annotators are Called “the People Behind Artificial Intelligence”
Behind the rapid growth of the AI industry, the new profession of data annotator is also expanding. There is a popular saying in the data annotation industry, “more intelligent, more labors”. The human workforce plays an important role in the data annotation industry.
These annotation labelers could work at home as freelancers. They can be trained to categorize and annotate data on various platforms, labeling companies such as Cloudfactory, Labelbox, allow work remotely.
ByteBridge: a Human-powered Data Labeling SAAS Platform
As labor cost takes up the most part of annotation service, most of the data companies follow similar principles such as outsourcing to countries with a cheaper labor cost.
Different data types require different skill sets. Some require professional background. For medical data, the image segmentation and tumor areas annotation needs to be completed by annotators who have a medical background.
Big Data Jobs
AI-Assisted Capabilities VS Human Workforce
Nowadays, some AI-assisted tools come to practice, standing out in 2 factors.
Cost reducing: With the help of AI-assisted capabilities, clients can save more money as the labor cost goes down.
Time reducing: Make the large-scale requirement of training data done in a short time. Using AI-assisted tool can improve efficiency multiple times
Can we get rid of the human workforce?
The answer is no.
In fact, manually labeled data is less prone to errors. The human workforce cannot be replaced by some tools leading with an AI-based automation feature, especially dealing with exceptions, edge cases, complex data labeling scenarios, etc.
In conclusion, the human workforce cannot be replaced by some tools leading with an AI-based automation feature, regarding quality assurance and data exception.
ByteBridge.io, a Human-Powered Data Annotation Platform
ByteBridge, a human-powered data labeling tooling platform with real-time workflow management, providing flexible data training service for the machine learning industry.
Accuracy Guarantee
All work results are completely screened and inspected by the human workforce.
Moreover, the real-time QA and QC are integrated into the labeling workflow as the consensus mechanism is introduced to ensure accuracy.
Consensus — Assign the same task to several workers, and the correct answer is the one that comes back from the majority output.
While dealing with complex tasks, the task is automatically transformed into tiny components to maximize the quality level as well as maintain consistency, further reducing human error.
Flexibility
On ByteBridge’s dashboard, developers can define and start the data labeling projects and get the results back instantly. Clients can set labeling rules directly on the dashboard.
ByteBridge: a Human-powered Data Labeling SAAS Platform
In addition, clients can iterate data features, attributes, and workflow, scale up or down, make changes based on what they are learning about the model’s performance in each step of test and validation.
As a fully-managed platform, it enables developers to manage and monitor the overall data labeling process and provides API for data transfer. The platform also allows users to get involved in the QC process.
ByteBridge: a Human-powered Data Labeling SAAS Platform
End
“High-quality data is the fuel that keeps the AI engine running smoothly. The more accurate annotation is, the better algorithm performance will be” said Brian Cheong, founder, and CEO of ByteBridge.
Designed to empower AI and ML industry, ByteBridge promises to usher in a new era for data labeling and accelerates the advent of the smart AI future.
Can AI algorithms help us find love? Can they go a step further and replace a human being as a partner in a relationship? Here, we analyze how far technology has come in helping us meet “our” people, find love, and feel less lonely.
At Wrangle Summit 2021, Apr 7-9, you’ll get access to all the best people, ideas, and technology in data engineering, all in one place. Learn how to refine raw data and engineer unique data products, and gain insights from your data that can catalyze real, measurable business success.
It’s time again to look at some data science cheatsheets. Here you can find a short selection of such resources which can cater to different existing levels of knowledge and breadth of topics of interest.
Today our goal is to help you classify the kind of ML use case you are developing in terms of how it will interact with humans. Knowing and following this classification will help you and your company in all steps of a ML model cycle.
Here are the five ways an ML algorithm (also referred to below as “AI”) can interact with people [1].
1. AI decides and implements (“automator” scheme) — In this particular form of interaction, the assumption is that involving humans would only slow down the process; as a result, the ML algorithms do almost all of the work. They must have access to all the data and context. Two examples for which this approach may be appropriate, both applicable to grocery store management, are clearance pricing for unsold and soon-expiring inventory, and personalized customer discounts.
2. AI decides, Human implements (“decider” scheme) — Here AI captures the context and makes the decisions, then Humans will implement the retained solution. In online grocery shopping, if a customer selects out-of-stock products, an ML algorithm can use historical data to suggest alternatives. Humans can check the quality of the suggestions before delivery. As another example, an AI algorithm can identify failures in production facilities, then a human runs the repair. This category can be called a Decider.
3. AI recommends, Human decides (“recommender” scheme) — With Google Maps, an AI algorithm recommends multiple options to reach a destination, then a human chooses one. As another example, an AI algorithm can suggest what products to buy to replenish the stock of a grocery store; if it does not have access to the supply chain, the store manager will make the final ordering decision.
4. AI generates insights, Human does decision making (“illuminator” scheme) — Here insights from AI support the creative side of humans. An AI algorithm for a grocery chain could for example identify shopping patterns unique to geographical locations and use them to produce recommendations for merchants on possible location-specific features. As another example, an AI algorithm can shed light on future workforce needs, on which HR professionals can rely to gain a competitive edge.
5. Human generates, AI evaluates (“evaluator” scheme) — In all previous cases the flow went from AI to humans. Here we reverse it: humans generate hypotheses, AI tests them. The most important example is “digital twins” technology, whereby people at a company produce many scenarios based on a digital model of some asset (such as a manufacturing plant); then AI serves to simulate and assess those scenarios. Other examples of the evaluator scheme involve the testing of rare scenarios: for online stores, assessing the impact of a pandemic such as Covid-19; for disaster relief agencies, assessing the impact of hurricanes using historical data.
Organizations that successfully use ML to drive growth are incorporating all five modes described above in their business processes. For effective user testing and for successful integration of the machine-learning processes into the business operations, it is essential that ML practitioners know in each case which of the five schemes is being applied.
This article will, I hope, help you in this identification process. To acquire an in-depth practical understanding of how to apply data science in industry, join one of our data programs:AI for Managers,Data ScienceandMachine Learning.
How to Deploy AI models ? Part 4- Deploying Web-application on Heroku via Github
This Part is the continuation of the Deploying AI models Part-3 , where we deployed Iris classification model using Decision Tree Classifier. You can skip the training part if you have read the Part-3 of this series. In this article, we will have a glimpse of Flask which will be used as the front end to our web application to deploy the trained model for classification on Heroku platform.
1.Iris Model Web application using Flask.
1.1. Packages
The following packages were used to create the application.
1.1.1. Numpy
1.1 .2. Flask, Request, render_template from flask
1.3. Dataset, Ensemble, Model Selection from sklearn
1.2. Dataset
The dataset is used to train the model is of iris dataset composed of 4 predictors and 3 target variable i.e. Classes
#Train a model using random forestmodel = sklearn.ensemble.RandomForestClassifier(n_estimators=500)model.fit(train_data, train_labels)
#test the model result = model.score(test_data, test_labels) print(result)
#save the model filename = ‘iris_model.pkl’ pickle.dump(model, open(filename, ‘wb’))
1.4. Frontend using Flask
For feeding the value in the trained model we need some User Interface to accept the data from the user and feed into the trained neural network for classification. As we have seen in the sectioin 1.2 Dataset where we have 4 predictors and 3 classes to classify.
File name: index.html should be placed inside templatre folder.
The above shown code is for taking the input from the user and display it in the same page. For this we have used action=”” this will call the prediction fubtion when we will submit the data with the help of this form and to render the predicted output in the same page after prediction.
File name: app.py
import numpy as np from flask import Flask, request, jsonify, render_template import pickle import os
#app name app = Flask(__name__) #load the saved model
features = [float(x) for x in request.form.values()]
values = [np.array(features)] model = load_model() prediction = model.predict(values) result = labels[prediction[0]] return render_template(‘index.html’, output=’The Flower is {}’.format(result))
if __name__ == “__main__”: port=int(os.environ.get(‘PORT’,5000)) app.run(port=port,debug=True,use_reloader=False)
In the python script, we called the index.html page in the home() and loaded the pickle file in load_model () function.
As mention above we will be using the same index.html for user input and for rendering the result. when we will submit the form via post method the data will be send to the predict() via action=”” and predict function from the app.py file and it will be processed and the trained model which we have loaded via load_model () function will predict and it will be mapped the respective class name accordingly.
To display the data we will render the same template i.e. index.html. If you would have remember we used keyword in the index.html page we will be sending the value in this field after prediction by rendering in the index.html page by the following Flask function.
render_template(‘index.html’, output=’The Flower is {}’.format(result))
where index.html is the template name and output=’The Flower is {}’.format(result) is the value to be rendered after prediction.
1.5. Extracting Packages and their respective versions
We need to create the require.txt file which contains the name of package we used in our application along with their respective version. The process of extracting the requirement.txt file is explained in the Article:Deep Learning/Machine Learning Libraries — An overview.
For this application below is the requirement.txt file content.
Along with requirement.txt, you need the Proctfile which calls the main python script i.e. script which will run first. For this Webapplication the Proctfile content is below.
web: gunicorn -b :$PORT app:app
app -->is the name of the python scripy i.e. app.py
It is a PaaS platform which supports many programming languages. Initially in 2007 it was supporting only Ruby programming language but not it supports many programming language such as Java, Node.js, Scala, Clojure, Python, PHP, and Go. It is also known as polyglot platform as it features for a developer to build, run and scale applications in a simillar manner across most of the language it was acquired by Salesforce.com in 2010.
pplications that are run on Heroku typically have a unique domain used to route HTTP requests to the correct application container or dyno. Each of the dynos are spread across a “dyno grid” which consists of several servers. Heroku’s Git server handles application repository pushes from permitted users. All Heroku services are hosted on Amazon’s EC2 cloud-computing platform.
You can register on this link and can host upto 5 application with student account.
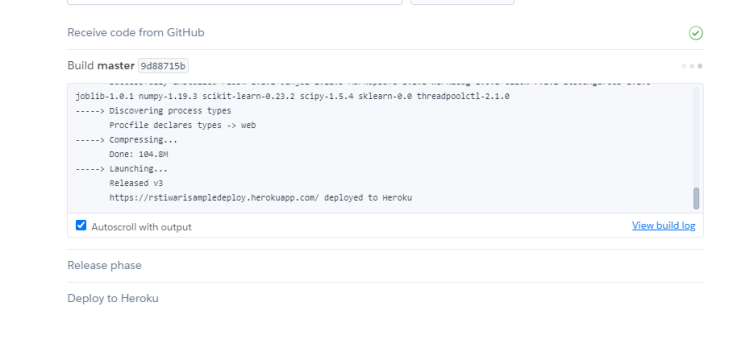
cccccStep2: Add the repository and select the branch you want to deploy and click on the deploy branch.
Fig 4. Deploying Branch via GithubFig 5. Deploying the branch
Congratulation!!! we have successfully deployed an Iris classifier web application.
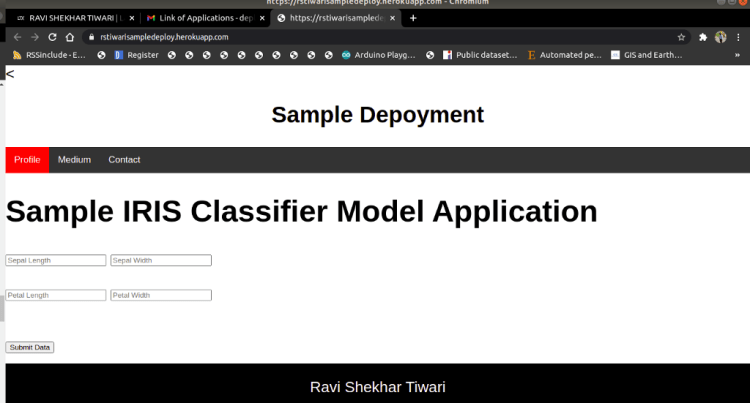
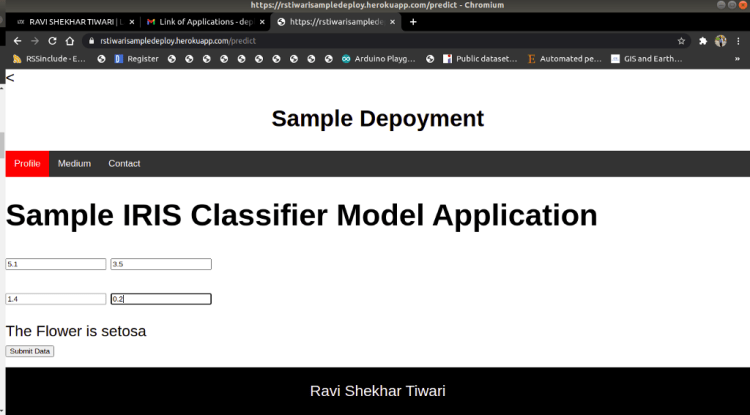
4. Deployed Web Application
The overview of the deployed web application with Iris Application: Link is shown below.
Fig 4. Landing Page of deployed Iris ClassificationFig 5. Predicted Class
Special Thanks:
As we say “Car is useless if it doesn’t have a good engine” similarly student is useless without proper guidance and motivation. I will like to thank my Guru as well as my Idol “Dr. P. Supraja”- guided me throughout the journey, from the bottom of my heart. As a Guru, she has lighted the best available path for me, motivated me whenever I encountered failure or roadblock- without her support and motivation this was an impossible task for me.
Reference:
Extract installed packages and version :Article Link.
Notebook Link Extract installed packages and version :Notebook Link
Understanding your data first is a key step before going too far into any data science project. But, you can’t fully understand your data until you know the right questions to ask of it.