365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
At Uber, where ML is fundamental to most products, a mechanism to manage offline experiments easily is needed to improve developer velocity. To solve for this, Uber AI was looking for a solution that will potentially complement and extend its in-house experiment management and collaboration capabilities.
Learn how to implement an API based on FastAPI and spaCy for Named Entity Recognition (NER), and see why the author used FastAPI to quickly build a fast and robust machine learning API.
The success of your Intelligent Automation strategy depends on your ability to extract necessary data from paper-based documents such as contracts, manuscripts, books, invoices, receipts, etc., and convert it into machine-readable text. Unless you want a manual data entry bottleneck in front of your whole automation process, step one of your automation strategy should include the automation of that data extraction process.
For years this has been done by a technology called Optical Character Recognition (OCR). OCR has been used to help automate business processes such as Procure-to-Pay in enterprises throughout the world. While OCR has improved over the years, it’s still not perfect. And guess what? That means even with OCR you probably still have that manual data entry bottleneck in front of your automation process as humans make manual corrections where OCR fails.
Big Data Jobs
OCR has some inherent weaknesses, and one of the most significant is its dependence on templates. Fortunately, Artificial Intelligence (AI) technology can solve this problem by using a completely different approach that’s a powerful alternative to conventional template-based OCR conversion.
Let’s take a look at why template-based conversion creates some operational challenges and how a native AI-based technology can solve them.
What are Templates in OCR Conversion?
Have you ever played those hidden picture games where you have to find an object hidden somewhere in a giant image filled with tons of random things? It’s easier when you get a hint, like “The hidden turtle is somewhere in the lower-left quadrant just below the bookshelf near the chair.”
OCR needs hints like those to do its job better. If you tell it where to look, OCR can more accurately extract the data you want, and that’s what templates do for OCR.
Templates specify the location of information that needs to be extracted from the document that is being converted. The user marks coordinates and the software tool extracts text located at that specific location in the scanned image. This method of using coordinates is called zone OCR, and this helps OCR extract the right data so it can be stored in a structured database.
Zone OCR is effective when documents *reliably* have a structure similar to the template. As long as there is little or no variation among documents, your good to go.
But if something changes or there’s too much variation, watch out.
For example, even if we set up a template for a standard invoice format, the total amount payable may appear in different positions because the number of items in the invoice varies and the total at the bottom gets pushed up or down. This variation causes all kinds of problems for your template. It’s as though that hidden turtle is crawling around and its location no longer matches the hint.
The Problem with OCR Templates
In fact, templates have a lot of limitations that impact accuracy and eat away at both your ROI and your ability to increase process automation. Just for fun, we made a list. See how many of these OCR template issues wreak havoc on your business processes:
Artificial Intelligence (AI) Finds Meaning in Text and Extracts it
As AI capabilities evolved and developed, a new approach to OCR emerged. Using AI takes an extraction solution well beyond what OCR is capable of.
Machine learning has enabled us to create algorithms trained on large volumes of data, that can extract data more efficiently. Now you can document variations with ease.
Natural language processing methods can be applied to understand the text and its context. Text analytics allow you to turn raw data into information.
Computer Vision (Deep Learning) systems are able to extract data from non-textual information such as stamps, diagrams, images, or tables.
A Bank Moves Beyond OCR
A large global bank offers a business loan service to companies in 15 countries. As part of the debt servicing process, the bank analyzes financial data and statements provided by the borrower. The analysis ensures that the borrower can repay the loan and is not at risk of default.
The bank used manual processing of the documents by skilled staff because of the documents:
Varied from the borrower to borrower.
Varied over time. One year’s annual report may be laid out differently than the next year’s report.
Had important context within the documents that needed to be maintained. Footnotes, for example, make materially important changes to the figures in a table.
Had data that was presented in a table and, sometimes, in nested tables.
This manual process worked, but it was slow, expensive, and often had accuracy problems.
An OCR, no matter how smart, could not handle the extraction job. The bank needed to move beyond OCR.
We worked with the bank to develop an AI-based solution that could extract all the data and context, and account for variations and changes.
(We also built an intelligent application for this bank that used natural language generation to generate a summary report from the extracted data.)
The outcome reduced operating expenses, decreased processing time, and improved accuracy. And the staff used for document extraction could be assigned to higher-value tasks such as analysis of the data.
Next-Gen OCR
Data extraction solutions now exist that are beyond OCR and beyond OCR templates.
These Intelligent Data Processing solutions now process what only humans could process a short time ago. And these solutions can do what OCR could never do: process unstructured, complex documents.
AI Transforms Mortgage Industry — Automate Document Processing
A decade ago the volume-heavy, error-prone and sluggish business processes of mortgage companies that take up considerable human labor were still struggling to find a direction with the technological transformation. Automation has finally kicked in for the Industry. Not only have the mortgage companies become more efficient, but the decision-making logic has also evolved with the application of robotics and AI. The focus is now fixated on automating tasks, minimizing errors & improving customer experience.
Big Data Jobs
With the introduction of AI technologies like machine learning, mortgage professionals have been meeting their targets while achieving better customer satisfaction. Most of the work which was reliant on manpower is now being done by computers. As a result, professionals can shift their attention to more strategic aspects of the job like managing problems and processing exceptions. Infrrd’s AI-led automation is enabling mortgage companies to replicate human reasoning via machine learning, predictive modeling, and NLP.
A few of the processes that Infrrd has been automating for mortgage companies are:
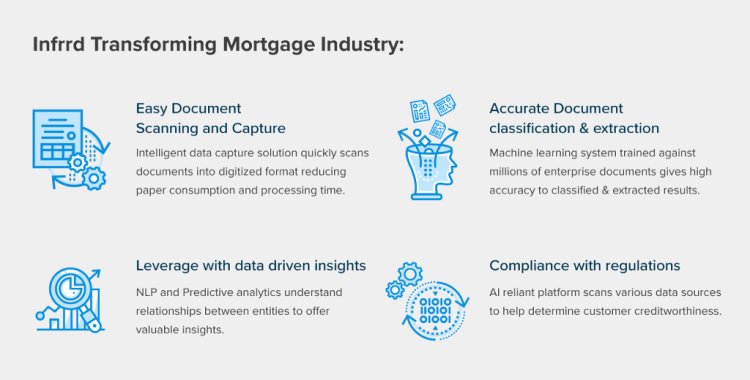
Infrrd’s intelligent document capture based on AI & machine learning classifies, separates, extracts & validates documents regardless of the source or format. Here’s how Infrrd is transforming the mortgage industry:
1. Easy Document Scanning and Capture
Assessing large creditworthy documents is often a tedious task. With our intelligent data capture solution, mortgage-related documents can be scanned into digitized format reducing paper consumption as well as overall processing time. Be it applications, credit reports, employment verification forms or legal files, all of them can be quickly scanned via Infrrd’s web or mobile applications.
2. Accurate Document classification & extraction
The paper-intensive consumer lending mortgage processes get laden with many variants of documents. Going through all of them for individual clients is labor-intensive and will take a lot of hours. Our deep learning-based IDC platform classifies, identifies, separates, and organizes these lengthy documents in one go. Our machine learning system is trained against millions of enterprise documents giving a high accuracy to the extracted results. It’s not a template-reliant solution, which makes it different from the ones available in the market today. Machine learning allows the software to continuously learn from any manual validation to improve system accuracy as well as reduce time spent on manual correction over time.
Data extraction isn’t the end of our solution. We go a step ahead to do much more than that. Our NLP and Predictive analytics algorithms understand relationships between entities, learns from the historical data, and offer valuable insights in the form of financial reports or customer engagement that aid business decisions. We can predict trends and help address issues that are likely to affect the business. With this kind of insight, mortgage professionals will be able to offer their customers better service and customized products.
4. Compliance with regulations
Even with the right customer information, the complex task of determining creditworthiness might pose a grave challenge. Our AI-reliant platform helps scan various data sources to offer companies the entire digital footprint of their potential borrowers, hence allowing adherence to regulations. At the end of the day, our technology will make tasks streamlined and help businesses expand their horizons. Adopting and adapting to it will definitely give your company an edge in this cut-throat industry where mortgage lenders are fighting commoditization. We are helping mortgage companies differentiate with our AI and ML solutions and create a seamless customer experience. Chat with us to schedule a meeting to discuss further.
Optical Character Recognition (OCR) tools have come a long way since their introduction in the early 1990s. The ability to convert different types of documents such as PDFs, files, or images into editable and easy-to-store formats has made corporate tasks effortless. Not only this, it’s the ability to decipher a variety of languages and symbols that gives Infrrd OCR Scanner an edge over ordinary scanners.
However, building technology like this isn’t a cakewalk. It requires an understanding of machine learning and computer vision algorithms. The main challenge one can face is identifying each character and word. So in order to tackle this problem we’re listing some of the steps through which building an OCR scanner will become much more clearer. Here we go:
START WITH OPTICAL SCANNING:
Let’s get simple things out of the way first.
IDC stands for Intelligent Data Capture, while OCR stands for well… Optical Character Recognition.
As the name suggests, OCR mostly deals with image pre-processing, identifying characters, and putting together words, blocks, and sentences. The field of OCR revolves around digitizing what’s on paper or a scan or a photograph from a physical document. Online OCR plays a critical role in scenarios with a large number of scanned documents and images which need to be converted to text.
Big Data Jobs
Intelligent Data Capture technology, on the other hand, is the broader and more general field of information collection and analytics. It provides meaning to text extracted from many forms of digital assets such as documents, emails, text files, and scanned images.
It’s a method above and beyond OCR software. In IDC, words and sentences get business meaning and become much more relevant. Let’s walk through an example;
An OCR system scanning dates may output ‘12-May-2018’. A 100% accurate result but eventually it is just a sequence of characters and pixels appearing together on a picture. On the other hand, with the help of Intelligent Data Capture solutions, this sequence of characters will take one of the following meaning:
‘PAYMENT DUE DATE’ for credit card statements, ‘CHECK-IN DATE’ or a ‘CHECK-OUT date’ for hotel invoices ‘RENEWAL DATE’ on a contract Or some other such business interpretation is driven from the context of the document.
WHERE IS THE INTELLIGENT DATA CAPTURE SYSTEM APPLICABLE?
Any place where meaningful snippets of information are hidden deep inside digital documents and images. This can be most common in industries such as Finance, Legal, Insurance, Auditing, etc.
These industries generate millions of documents every month as a byproduct of their business processes. The challenge originates when these documents flow through the business workflow and reach the consumers of the document. In most cases, they are far removed from the document producers. They will have no access to digital data embedded in these documents.
In short, the far removed downstream stakeholders and consumers of these documents will have to force themselves to rely on manual labor for information extraction. Examples of such information are dates from contracts, ticker symbols from stock market reports, or the name and address of the fund manager from a fund prospectus.
HOW DO ENTERPRISE AI AND MACHINE LEARNING ALGORITHMS HELP?
Technology has reached the state where it is possible today for computer programs to read and understand digital documents as humans do. We can train Intelligent algorithms to look for specific entities such as dates, contract numbers, purchase order numbers in different documents. These trained systems regularly produce accuracy levels of more than 90%. Hence, one can efficiently analyze 100s and 1000s of documents per minute.
Although one of the most obvious advantages of these systems is the reduction of humans in the loop. But, the REAL WIN is the capability of automation and efficient integration of otherwise manual workflow with other business workflows. This characteristic of the IDC system makes it one of the most essential building blocks for your robotic process automation (RPA) program and architecture. More on this later.
We are investing heavily in building a scalable universal trained model capable of extracting common entities from common business documents such as trade notes, shipping labels, contracts, invoices, receipts, etc.
Want to understand how we can customize for your needs? Chat with us to schedule a meeting to discuss further.
Statistics is a building block of data science. If you are working or plan to work in this field, then you will encounter the fundamental concepts reviewed for you here. Certainly, there is much more to learn in statistics, but once you understand these basics, then you can steadily build your way up to advanced topics.
PyCaret is an alternate low-code library that can be used to replace hundreds of lines of code with few lines only. See how to use PyCaret’s Regression Module for Time Series Forecasting.
The Most In-Demand Skills for Data Scientists in 2021; How to organize your data science project; You may have heard about Simpson’s paradox, but do you know the other 2? Read Top 3 Statistical Paradoxes in Data Science; ETL in the Cloud; Data Profession Job Satisfaction: Beware Of The Drop; and more.
Whether you are getting started with Data Science / Machine Learning or are an experienced professional looking to learn something new, check out these top 10 data science courses for 2021.