365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
As per the trend, everyone is talking about Natural language processing, speech recognition, text generation etc. In this article, we will discuss on how can we get text from the video or audio files.
Pre-requisites: >> Python 3.7 >> ffmpeg >> Libraries: os and speech_recognition
Step 1: Prepare directory Create a new folder and add some video files. For instance, I have created a folder ‘SpeechConversion’ and in this folder I have one video song (in .mp4 format).
Big Data Jobs
Step 2: Import libraries Import the required libraries, refer below code: import os import speech_recognition as sr
Step 3: Command for video conversion I am using ffmpeg to convert the video file to audio. First, I will convert this to mp3 format and then will transform it to the wav format, as wav format allows you to extract better features. Here, my video file name is Bolna.mp4, I convert this to Bolna.mp3 then to Bolna.wav. Below are the commands for the conversion process. Let’s save them in variables as below. command2mp3 = “ffmpeg -i Bolna.mp4 Bolna.mp3” command2wav = “ffmpeg -i Bolna.mp3 Bolna.wav”
Step 4: Execute video conversion commands Let us now execute these commands using the ‘os’ library as below os.system(command2mp3) os.system(command2wav)
Step 5: Load the wav file Now, let us load the wav file that was created in the above step. The below code can be used for the same. r = sr.Recognizer() audio = sr.AudioFile(‘Bolna.wav’)
Step 6: Process the wav file Lastly, as per the required, set the duration of the audio you want for further processing. I am keeping this as 100 seconds duration for test purposes. You can change the same as per your convenience. with audio as source: audio = r.record(source, duration=100) print(r.recognize_google(audio))
Voila, you can get the text for the first 100 seconds of the video or audio file.
Further enhancements: The text generated can be later used for Natural language understanding and Natural language generation processes.
KubeFlow is an open-source MLtoolkit for Kubernetes. It is a convenient tool for making Machine Learning Workflows Simple, Portable and Scalable. As, it runs on top of Kubernetes it can run on-prem Servers, GKE (Google Kubernetes Engine) and Amazon Elastic Kubernetes Service (EKS) or any other Kubernetes Service.
There are many ways of Installing Kubernetes Locally in your System:
When we check for Local KuberFlow options we are having MiniKF, in the official documentation of KubeFlow, they are using Vagrant and VirtualBox to install MiniKf. I avoided this installation as i wanted to avoid VirtualBox.
Big Data Jobs
Another option is first Installing MiniKube and then Installing Kubeflow on that. I encountered some bugs where it did not install few of the services.
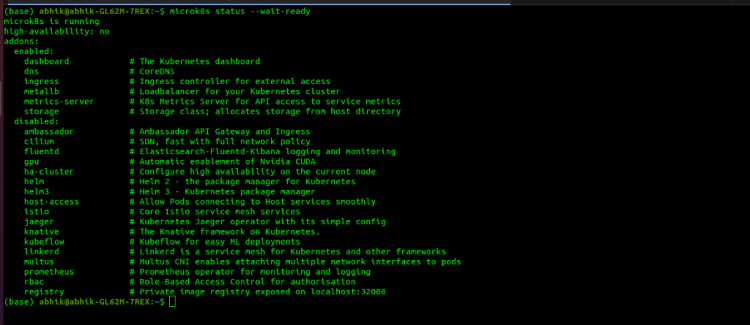
The Easiest Option which I found was using MicroK8s. Following are the commands which I used to install this.
3. We have to enable Services which have will be used by KubeFlow.
microk8s.enable dns dashboard storage
4. For Deploying KubeFlow
microk8s.enable kubeflow
After Deploying Kubeflow we will access the KubeFlow Dashboard. We will the dashboard IP in the command line. We will also get Username and Password which we will require to access the KubeFlow Dashboard. After entering the credentials we will access the Dashboard which will look like this.
KubeFlow Dashboard
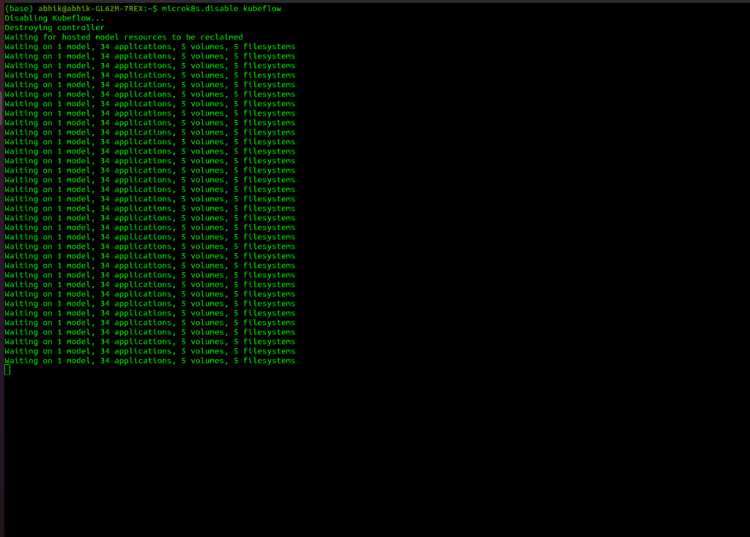
5. Stopping After Deployment
microk8s.disable kubeflow
Congrats! Hope You are Enjoying KubeFlow in your Local!
Different Algorithm Stage, Differentiated Demand for Training Data
ByteBridge: a Human-powered Data Labeling SAAS Platform
Three Basic Elements in AI
The algorithm, computing power, and data are the three basic elements of the development of artificial intelligence. Just as a triangle needs three sides to stabilize its shape, artificial intelligence will also need all three elements to perfect itself.
Among them, data is the foundation, which provides the underlying support for the algorithm. If you compare an algorithm to a car, data is the fuel that drives the car forward.
Data is the Key
ByteBridge: a Human-powered Data Labeling SAAS Platform
At present, AI enterprises have to go through three stages: research and development, training, and implementation, and each stage requires the support of massive basic data sets.
In machine learning, with each round of testing, engineers would discover new possibilities to perfect the model performance, therefore, the workflow changes constantly. There are uncertainty and variability in data labeling. The clients need workers who can respond quickly and make changes in workflow, based on the model testing and validation phase.
Therefore, High-quality labeled data for machine learning algorithms training has become the core part of artificial intelligence development in recent years.
Big Data Jobs
The requirement at Research and Development Stage
The research and development phase is the starting point of training a new algorithm. At this stage, the algorithm has been through a process from 0 to 1 and has a large demand for data. In the initial stage, standard data set products are mostly used for training, and later in the middle and late stages, data customization and professional labeling services are required.
For data service providers, in order to better meet the needs of AI algorithms in the research and development stage, they need to not only improve their own labeling and delivery capacity but also improve their own customized data output capacity, so as to achieve a seamless fit between service and demand.
The requirement at Training Stage
At the training stage, AI enterprises aim to optimize the performance and other abilities of the existing algorithm with annotated data. At this stage, the demand for data quantity decreases, and AI enterprises focus mainly on data accuracy.
For data service providers, in order to better meet the needs of AI algorithms in the training stage, it is necessary to guarantee data quality. The data accuracy rate to 95% or even higher can be realized by using advanced annotation tools and establishing tight internal management.
ByteBridge: a Human-powered Data Labeling SAAS Platform
The requirement at the Application Stage
After the research and development and training process, the algorithm is mature enough to move from the laboratory to the market. In this stage, the demand for data volume is further reduced, and the requirements for scenario-based data sets with consistency are much higher.
For example, in the field of autonomous driving, data scenarios include lane changing and overtaking, crossing intersections, unprotected left turns and right turns without traffic light control, as well as some complex long-tail scenarios such as vehicles running red lights, pedestrians crossing the road, and vehicles parked illegally on the side of the road, etc.
For data service providers, in order to better meet the requirements in the landing stage, apart from improving the output capacity of customized data sets, meanwhile, they need to improve their customer service, so as to put forward professional opinions and suggestions for algorithm landing.
The above three stages cover the whole process from scratch, in which data plays an indispensable role.
The booming data annotation market has also stimulated the players to secure a niche position in the competition. Only by constantly guarantee data quality and provide flexible service for different stages can the data provider take the lead in the fierce competition.
ByteBridge, a human-powered data labeling tooling platform with real-time workflow management, providing high-quality data with efficiency:
The real-time QA and QC are integrated into the labeling workflow as the consensus mechanism is introduced to ensure accuracy.
All work results are completely screened and inspected by the machine and human workforce.
Clients can set labeling rules, iterate data features, attributes, and task flows, scale up or down, make changes.
ByteBridge: a Human-powered Data Labeling SAAS Platform
Clients can monitor the labeling progress and get the results in real-time on the dashboard.
ByteBridge: a Human-powered Data Labeling SAAS Platform
For further information, please visit our website site:ByteBridge.io
You have many options when choosing metrics for evaluating your machine learning models. Select the right one for your situation with this guide that considers metrics for classification models.
In this article, we will understand the difference between data verification and data validation, two terms which are often used interchangeably when we talk about data quality. However, these two terms are distinct.
See the progress the author has made since last time, after setting themselves the challenge of solving Sudoku puzzles using an optimized inference engine, along with a few other advanced features of FICO® Blaze Advisor®.
The latest KDnuggets survey is looking to determine the job satisfaction levels of the data community. Take a few moments to contribute your answer and help paint a picture of the current situation.
Tldr: CorporateAI failures can be ascribed to poor Intuition, Process, Systems, People
The promise of AI is real. We are at the crossroads of the next industrial revolution where AI is automating industrial processes and technologies that were hitherto considered state-of-the-art. AI is expected to create global commercial value of nearly USD 13 Trillion by 2030 (McKinsey Global Institute). Given the immense commercial value that AI can unlock, it is no surprise that businesses of all kinds and sizes have jumped on the AI bandwagon and are repositioning themselves as ‘AI-first’ or ‘AI-enabled.
However, the groundbreaking progress and transformation that AI has brought across industry belies the stark reality of an increasing number of failed AI projects, products and companies (e.g. IBM Watson, and many more). How can startups and large enterprises battle these tough odds to drive innovation and digital transformation across the organization? In this blog, I will examine from first principles common themes that typically underlie failed AI projects in corporations, and questions business leaders and teams should address when embarking on AI projects.
Big Data Jobs
I have classified these under four broad areas and will tackle each of these themes individually in future blog posts:
Intuition (Why)
Process/Culture (How)
People (Who)
Systems (What)
Part 1: Intuition (Why) Commercial AI projects often fail due to a lack of organizational understanding of the utility of AI vis-a-vis the business problem(s) to be solved. More often than not, throwing a complex AI-based solution at a problem is not the right approach, where a simpler analytical or rule-based solution is sufficient to have things up and running. It is therefore paramount to decode the business problem first and ask whether an AI approach is the only and best way forward.
Unlike software engineering projects, the fundamental unit of AI is not lines of code, but code and data. In an enterprise, data typically belongs to a particular business domain, and is generated by the interaction of customers with specific business products or services.
Here, a customer-centric approach is critical to understand the context in which this data is generated so that AI models may be developed to predict or influence user behavior to meet well-defined business objectives with clear success criteria. Wherever possible, the data scientists should themselves use and experiment with their company’s products/services by donning a ‘customer’s hat’ to decode the customer mindset. It’s hard to understand the nuances of training data if you don’t intimately understand the customer ‘persona’ to begin with.
Data reflects more than just mere numbers. Making sense of data requires a holistic cross-functional understanding from a business, product, customer as well as technical perspective. Typically, these functional roles are played by different teams within a company, necessitating a strong collaborative effort to demystify the business problem, question the existing solutions and come up with new hypotheses, test and prove or disprove these hypotheses quickly via iterative experiments to hone in on a feasible solution and strategy.
Here, the importance of domain knowledge or subject matter expertise cannot be stressed enough. It takes years to gain deep domain expertise which enables practitioners to develop better intuition for the business problem and the underlying data to propose feasible solutions or strategies. As data scientists typically lack expertise in business domains, it is imperative they complement their algorithmic data science skills with expert knowledge from those who work closely with the customer and understand the business problem intimately.
Tldr (Part 1/4): Ask why is AI needed for your business problem? Is it the only way to solve the problem? And if yes, build and test hypotheses by leveraging the collective organizational knowledge and intuition across cross-functional teams that specialize in data science, business, product, operations.
Sundeep is a leader in AI and Neuroscience with professional experience in 4 countries (USA, UK, France, India) across Big Tech (Conversational AI at Amazon Alexa AI), unicorn Startup (Applied AI at Swiggy), and R&D (Neuroscience at Oxford University and University College London). He has built and deployed AI for consumer AI products; published 40+ papers on Neuroscience and AI; consults deep tech startups on AI/ML, product roadmap, team strategy; and conducts due diligence of early-stage tech startups for angel investing platforms. (https://sundeepteki.org)
Data Labeling — How Data Annotation Service Helps Build a Smarter Finance Industry?
ByteBridge: a Human-powered Data Labeling SAAS Platform
Smart Finance
With the large-scale commercial application of deep learning and computer vision technology, the combination of the financial industry and artificial intelligence has become more closely, and the wave of intelligent finance has begun to sweep the whole financial industry.
From product design to customer service, From external management to internal monitor, artificial intelligence technology has a clear landing scenario in each of the financial industry value chains, effectively reducing the operating cost and financial risk.
Big Data Jobs
Behind the ecological reshaping is the breakthrough in AI technology. Computer vision, voice interaction, and natural language processing are more closely integrated into the financial industry, and the application of these technologies cannot be apart from the data annotation industry.
Computer Vision
In the financial industry, computer vision is mainly used in the field of internal process optimization, customer interaction service, face recognition, object detection.
ByteBridge: a Human-powered Data Labeling SAAS Platform
Such technology provides simplicity and convenience, for example, face swiping for fast payment. The previous method is that the user enters the password before paying. The process is relatively complicated, and there is a password leak problem. This interactive mode not only simplifies the payment process and improves the degree of automation, but also greatly improves the user’s payment experience.
This kind of computer vision technology requires different annotation types, such as key points, 2D boxing, etc. As it involves sensitive information such as the human face image, people are concerned about data security. Therefore, it is an important capacity for data annotation service providers.
Voice Interaction
In the financial industry, especially in bank institutions, the staff always communicate with clients. There are a variety of scenarios, such as business consulting, customer service, and electronic marketing.
At present, many financial institutions are equipped with voice interaction technology. And customer service robots are the most typical ones.
For example, a question answering system (QA) is a kind of chatbot that can automatically answer human questions in natural language. Understanding voice is an only half process, and the other is giving responses and answers. The competitive advantages of chatbots are communication simplification and labor cost reduction.
Due to the great differences in terms and expressions in different scenes, and the language in different places, there are high requirements for the scenario-based and customized data annotation capabilities of data annotation service providers.
ByteBridge: a Human-powered Data Labeling SAAS Platform
Natural Language Processing
Applications of natural language processing include semantic analysis, information extraction, text analysis, machine translation, and so on. In the financial industry, the main application scenarios are text checks, information search, language robots, etc.
For example, through semantic analysis of the text content, the intention is analyzed, and the response is finally formed through text synthesis. The main data annotation types are sentiment analysis, Text &Speech classification, OCR.
The integration of artificial intelligence has profoundly changed the traditional financial industry and reshaped the new ecology. In the future, with the development of artificial intelligence technology, there will be more vertical applications in finance.
Data Labeling Service
Just as a triangle needs three sides to stabilize its shape, artificial intelligence will also need all three elements to perfect itself. In fact, getting high-quality labeled data is the toughest part of building a machine learning model.
ByteBridge, a human-powered data labeling tooling platform with real-time workflow management, providing high-quality data with efficiency.
Individually decide when to start your projects and get your results back instantly
Clients can set labeling rules, iterate data features, attributes, and task flows, scale up or down, make changes.
Clients can monitor the labeling progress and get the results in real-time on our dashboard.
ByteBridge: a Human-powered Data Labeling SAAS Platform
These labeling tools are available on the dashboard :
Image Classification, 2D boxing, Polygon, Cuboid
For further information, please visit the website:ByteBridge.io
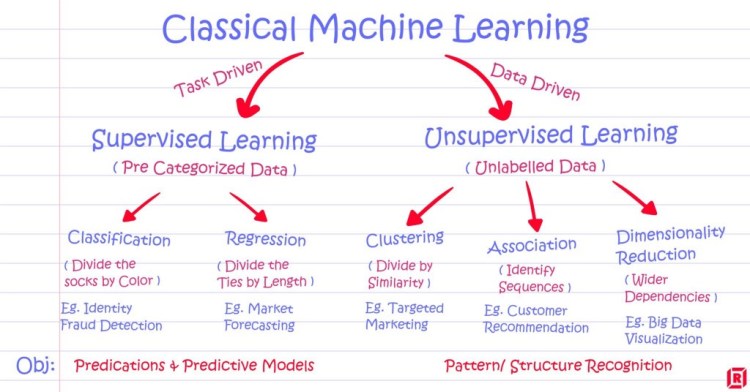
What is Machine Learning? Machine Learning is the process of letting your machine use the data to learn the relationship between predictor variables and the target variable. It is one of the first steps toward becoming a data scientist.
There are two kinds of Machine Learning; supervised, and unsupervised learning. In supervised learning, there are two types; Regression and Classification. In this blog, I will be focusing on the Regression model.
In weeks 3 and 4 of my general assembly data science immersive program, we learn about the sklearn library and using machine learning on the regression. While using the regression model, we cannot use string datatypes in a model. So, to deal with data that are not numeric, we use feature engineering or create a dummy variable. By using feature engineering, we can convert an object(string) into a numerical value. By creating a dummy variable; creates a binary column of 1s and 0s for the column.
To showcase the new skills learned from the sklearn library. Our class had a little Kaggle competition to see who had the best model. The project is:
Big Data Jobs
AMES HOUSING DATA SALE PRICE PREDICTION:
My project’s problem statement was
“A Realtor is looking to renovate and build houses in Ames, Iowa. They want me to look at the data to see what to invest in to get the best R.O.I. Which features will raise the price of the house value?”
Nominal: used for labeling variables(m- male and f- female)
Ordinal: used for measuring non-numeric with an order of the values(1-unhappy, 2-ok, 3- happy)
Data Cleaning: In this data set, there are 2051 rows with 80 columns. So, there were a lot of missing and null values to be clean. By reading the data dictionary provided on the Kaggle website, I cleaned the data using the pandas’ library. For discrete or ordinal features, I added the mode in order not to input a float number. I imputed the null values with the mean of the continuous column.
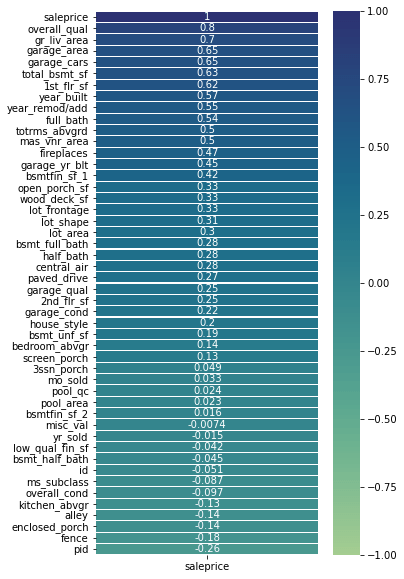
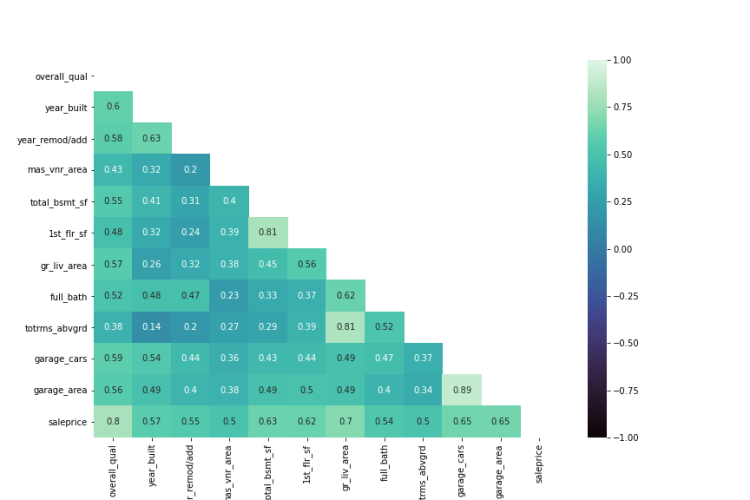
Exploratory Data Analysis: The best correlation between the sale price and features was the overall quality of the house.
Features that have the best correlation to the Sale Price
FEATURE ENGINEERING: In order to predict the outcome variable(y variable) you need to turn all the objects type column into numeric in order to predict the Sale Price. So first, I converted all the ordinal columns into numeric by assigning them by numbers, and for all the other features I created a dummy variable.
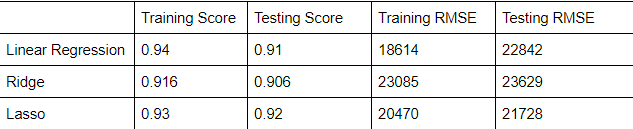
MODELING: After creating all the features to predict the sale prices, using sklearn, we train-test-split the training data. In Regression, there is a lot of models you can choose from to get the best performing model. In this model, I ran the model in Linear Regression, Ridge, and Lasso Model.
Training Score: How the model fitted the training data
Testing Score: How the model generalized to new data
RMSE: Shows how far predictions fall from measured true values using Euclidean distance.
The baseline model had an RMSE of $80,000. A baseline measures how effective your model is. So all of the models perform extremely better than the baseline; telling us that our model is working.
Lasso performs the best out of the Linear Regression and ridge, as it gives a score of 92 on the test and 21728 on the RMSE. I choose Lasso because the model had a lot of features and the lasso model shrinks and removes the coefficients, reduce variance without a substantial increase of the bias
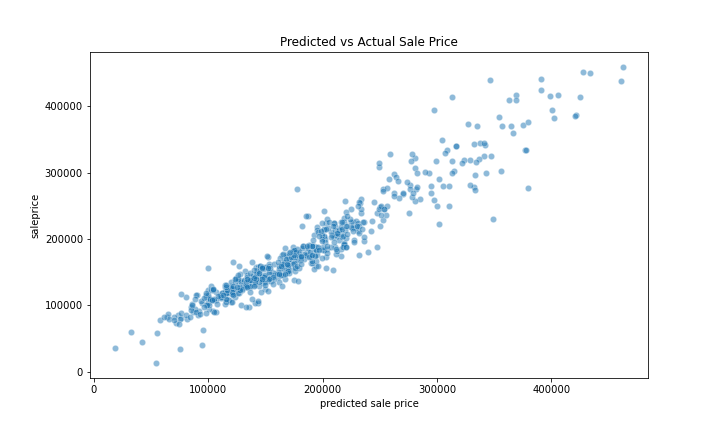
This shows the relationship between predicted and actual sale price, as you can see it is pretty linear. It means that our model performs well.
Below is the link for GitHub for the project if you want to check it out.