365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Facebook recently introduced and open-sourced their new framework for self-supervised learning of representations from raw audio data called Wav2Vec 2.0. Learn more about it and how to use it here.
“There is no finish line. There are only mile markers.”-Michael Ventura
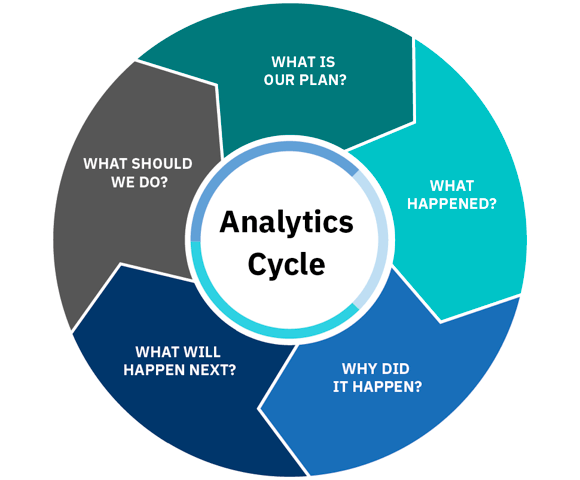
courtesy: simplilearn
A business can be simply understood as organized efforts put by a team to reach some preset targets, one of the most common one is getting profits. People do a lot of things to make their business grow and try new things just to ensure if any of this could click and make their entity a hit. There are multiple challenges when you start your business like financial crunch, inefficient team and blurred vision. Not all get out of the blues and many land up in shutting down their beloved ventures. Most of them don’t give a second try and get back to their old jobs and monotonous routines. Getting a right track, finding a good team, getting funding for their projects are some of the unfulfilled wishes which most of these business/startup owners will acknowledge.
There are some who will retry, this time equipped with past experience and still could face the same fate. Sustainable growth is the most sought attribute of any business irrespective of its size. No business is small or big at inception and almost all businesses start as a small venture. The only thing these small entities have in common is scarcity of resources but quite a few get on these challenges and rest stay where they were in their starting days.
Big Data Jobs
“A small business is an amazing way to serve and leave an impact on the world you live in.” -Nicole Snow
Technology has most of the answers which these businesses were always searching for. Data Analytics can be a great boon to these companies and can help in taking data-driven decisions. Decisions based on data can be very effective and can even help in getting the right strategic track. A business should always utilize its resources for sustainable growth. Data is the most precious and prime resource for any business but sometimes ignored. Ignoring business data and its vast potential can land you into a puzzle which is not easy to solve.
business challenges
It is found that most of the small business don’t care much about their business data. They actually don’t know what all information should be stored and so they miss out most of their operational information. This accounts to grey or black data. These businesses rely on their owners and workers experience, if anyone leave the job, the whole system gets hit. It is a very dangerous situation, when a person is more important than rest of the system. Such situations lead to unwanted bargains or huge losses.
It is time to realign !!!
Business is done by a team so each one should get his/her due share and respect. It is the people who make a business and are one of the most valuable resources but even then a business should not be too reliant on anyone and it should be able to sustain with ease, incase somebody leaves the team. The effort should be done to make a business data dependent instead of being person dependent.
Data analytics is sometimes used in conjunction with AI because these two terms collectively boost a business. AI boosts the capabilities of analytics to give better and deeper insights and thus should be used together for getting better outcomes.
“The price of light is less than the cost of darkness.” — Arthur C. Nielsen
The amount spent on analytics and AI is overshadowed by the amount of benefits received by any business. The spent amount can be easily returned to the business by using data driven decisions and proper strategy planning. Here again the business should use this boon with its full potential otherwise they could miss a lot of hidden benefits. Organize and store your maximum business information.
data collection
Most of the small business focus on their business and leave their data collection process in lurch. some business don’t even start collecting their business data and max they save is customer contact details. This is sheer under-utilization of a business. Storing data could be a great advantage and could be the biggest help in increasing the business or to start a new business. Thus it should never be ignored.
Some of the tips and benefits of using data analytics andAIin a business are:
It saves huge amount of time and money
Using the saved information, a business can refer to it in future and infer to the process done. It helps in improving the work quality and maintain the work standards. The data can give answers to some of the big issues at current times like selecting the best vendor or finding the potential customer. It save a decent amount of time and thus saves the manhours spent.
It helps in better understanding your customers
Analytics can help in knowing the customers and their purchase behavior. It helps a business to understand the customer pattern and doing the right product positioning. Business can identify its top customers and can put extra efforts to serve them better. It even helps in saving time spent on irrelevant customers and thus save your resources.
“Your most unhappy customers are your greatest source of learning.” — Bill Gates
courtesy: pymnts
It helps in product enrichment and improvement
Data Analytics and AI can help in getting product reviews, the issues faced by customers and thus they can be removed or taken care of. It helps in making the product better and improve the services. A small entity don’t have huge customer base so every customer has great importance. Missing out a couple of them could be a big thing.
It help in taking big business decisions
Properly done analysis of business data give a better insight about its current position, opportunities and issues. It help the stake holders to take the necessary steps like merger, launch or say quit before its too late. Data insight solidify the business decision taken and help in getting sure about it. Proper knowledge of business status helps in saving the money and time which could be utilized for some other projects and jobs.
business decision
It helps in retargeting and customer retention
Knowing where the product lag (by assessing the feedback), allow a company to improve it in due time and represent to its potential customers. It helps in customer retention as an entity could reach out to its customer before the issue arise. Like you can pitch your customer about car service which might be due next month or servicing an air conditioner before summers.
It gives answers to many questions
Data analytics when used with AI provide deep insights and help the stakeholders to understand what actually is going on in the company. What should be done, how we should move further. These kind of decision give strategic direction to a startup or business. All these decision become easy after having a deep analyzed report of the company.
“A ‘startup’ is a company that is confused about: 1. What it’s product is; 2. Who it’s customers are. 3. How to make money”. — Dave McClure
It helps in sustaining in the market
Overall the information collected help a startup or an entity to survive in the market and to deal with its scarce resources. The organization after seeing the insight can even work to improve its resources and services like infrastructure or after sale support service. Surviving is the key for any startup and it leads to sustainability.
Big Data is changing human resource management for good. We explore 4 major ways data analytics is upending & expanding the role of human resource departments for organizations.
The world is facing a re-skilling emergency. World Economic Forum highlights that over 54% of people will need to re-skill and up-skill themselves in the next 3 years.
Technological Advances are Upending How Work is Done
As the world of work changes, the role of the human resource department will no longer be limited to hiring and firing. HRs will need to be better at:
Value 1: Minimize the costs associated with a bad hire.
A bad hire is a costly mistake for HR professionals and the organization. It nullifies HRs effort of recruiting and onboarding a new staff member; training or hand holding time spent by the team they join in; and not to mention the costs of finding their replacement and impact on operations.
Big Data can help HRs in minimizing the bad hires they make, and the costs that come with a bad hire. HR managers are taking to big data analytics to choose the right candidate. Data is being used to match the company’s and teams’ requirements with that of the candidates.
As the war for talent becomes stiffer, it’s imperative for talent managers to make the right decisions during the recruitment and optimize their efforts.
Value 2: Up the organization’s rate of employee retention.
Retaining old staff is always preferred over hiring new ones on a regular basis. This, however, necessitates for the HR managers to put in place the right training modules, and skills assessment checks from time to time.
Big data analytics can help HRs make the best use of their hires by retaining them for long and helping organization reinvent their staff as per the needs of the time.
This will also enable HRs to leverage the benefits of internal mobility.
Big Data can help HRs to spot the employees:
Who is likely to walk out;
Who may need more training; and
Who can be transferred to other departments based on other skills; among other things?
And make it easy for talent managers to take appropriate action. They can choose to find and retain high-value employees by offering them challenging roles or offering other incentives.
Value 3: Predict employees’ performance even before you hire them.
This wasn’t possible before. Big Data makes it possible for HR professionals to forecast how an employee will perform even before they hire the person. They can do that by determining if a prospective hire would fit into the company culture and give satisfactory output.
It’s not always easy to manually compare a person’s attributes and work performance with your top-performers. Gut mostly informs these decisions. Analytics removes the ambiguity from the equation and uses the profile of your high performers to scan the right target profiles for your company.
Many platforms already use this model to offer freelancing help to companies in their assignments. Big data can make strong and nearly accurate predictions for you. HR may use this data for a variety of purposes:
evaluating layoffs,
promotions, and
optimizing recruitment across the profiles in a company.
Value 4: Provide better targeted-benefit packages.
Many human resource departments don’t realize the importance of extra benefits for people. Surveys, time and again, have revealed their role in incentivizing people to stay on.
Big Data can help them gather information about their staff and prospective candidates and plan better targeted extra benefits for them. This can offer a great way to attract and retain your people.
Value 5: Combat legal and ethical risks associated with data.
Data privacy is a huge issue for large organizations and institutions — from both a legal and ethical standpoint. This is one area where the value of Big Data is improved and legalized.
HR managers must step up their efforts in ensuring the privacy of data early on. The fears around misuse of information provided in the public, and even to the employers are rising. HR departments can assuage these by putting in place the checks and the right IT infrastructure.
It is worth exploring the advantages of Big Data for your organization. According to a survey by Gartner, about 23% of the companies are already piloting the use case of Big Data and AI in HR. Are you one of them?
The Symbolic World: Raising A Turing’s Child Machine (1/2)
Should one teach AI the same way one would teach a child?
“Instead of trying to produce a programme to simulate the adult mind, why not rather try to produce one which simulates the child’s? If this were then subjected to an appropriate course of education one would obtain the adult brain.” — Alan Turing, 1950
From the age of 3, most young children start to speak. Not just uttering random words but actually forming complete sentences. They start to ask questions. From simple “what” and “where” to those annoying “how” and “why” questions. But you should be amazed. Because behind these pure and unbiased questions, the child is slowly constructing its own knowledge base — a mental library of symbolic representations of the world. From forming and storing mental images of objects to recalling and replicating. The prime ingredient of creativity and imagination, logic and reasoning. Piaget named these sub-stages Symbolic Function phase (forming mental images/pictorial symbols) and Intuitive Thought phase(asking questions/knowledge construction). He uses the term “intuitive” because children at this phase are unaware of how they obtained this knowledge and tend to be very certain that they are correct.
Big Data Jobs
Do note that at this stage, children also developed very little of the concept of Conservation (certain physical characteristics of an object remains the same regardless of the changes of their appearance) and Transformation (the actual changes in physical characteristic), such that they may think that changing to a cup of a different shape also changes the amount of liquid within that cup (taller glass means more water), or if you squish a clay ball right in front of them from round to flat, they are likely think that the ball is two different objects.
A child continues this “preoperational period” until they reach the age of 7 where they reach middle childhood (age 7–12). By this stage, they should already have quite a large (common) knowledge base, with a very active imagination. They should already know common concepts such as time, location, numbers, etc. Now. Mark this phase, because this will be the key point of this article.
In middle childhood, logic and reasoning start to take place. This is called TheConcrete Operational Stage. Children begin to understand the concept of “right” and “wrong”. They start to see themselves as more autonomous beings and will try to solve problems on their own. They will start to infer other’s people thoughts and opinions. They are now able to use inductive logic (inferring certain rule based on the cause and effect of the past experience) and manipulate simple mathematical and symbolic knowledge (such as they will know that if you take away 2 cookies from a jar of 5, there will be 3 left, without having to see the actual cookies being taken away). However, their mental operation is “concrete”, that is, limited to tangible and touchable objects only. They cannot reason abstractly (if not memorising from some youtube video), such as, what will happen to their family if their dad dies, or what is the meaning of freedom or free will. Their knowledge representation is limited to things they have only touch or seen.
Now, let’s stop here for a second before we move on to the more complex realm of abstract reasoning and formal logic, and think for a bit about the current state of today’s artificial intelligence. Can it rival a 7-year-old child?
Ever since the breakthrough of AlexNet (Convolutional Neural Network) and Google Deepmind’s Alpha Go, the term “AI” and “machine learning” have been coined around a great deal. Then comes another big advancement in natural language processing (NLP) in 2017, when the paper “Attention is All You Need” by a team of Google Brain and University of Toronto researchers was published. They introduced the “transformer”, an architecture that allows the creation of much deeper neural networks that can have billions of parameters. The idea is very interesting as it focuses on “attention”, which means the model knows what to select and what to discard. This is exactly what we do. I have mentioned the importance of attention before in the earlier series. It also learns in an unsupervised manner, meaning that the model does not need hand-generated labels and can learn the generate any text. These works are indeed, very impressive, and I am actually very amazed at how far we have come and how fast the field is progressing
Using the same model, GPT-3 by Open AI, the third generation language prediction model of its kind, uses up to 175 billion parameters. This is 10-times bigger than its previous version, GPT-2. It is able to do exquisite things like summarising text, more accurate translation, or generate a blueprint for an application, Again. Amazing (and also very computationally expensive to run). This wowed the whole tech world, and for sure, wowed many of my geek friends.
But if we were to ask if this model really “intelligent”, the answer would be “no”. Even compared to a 3-year-old. Why?
Just like many other expert systems that do exceptionally well in a very specific and narrow task (Alpha Go – play Go, GPT-3 — text prediction, AlexNet — image classification), they did what they did base on a specific task assigned to them. They rely on the extremely large dataset as well. At this point, according to Pearl, they are still statistical software simply doing a curve-fitting exercise, giving no intuition about the higher-order intelligence. It’s a constant competition of who can fit the curve better, and increase the accuracy, even by just 1%. Most of my time these days that are spent on machine learning, is actually less on the model architecture itself, but on the data-preprocessing step.
from the point of view of the mathematical hierarchy, no matter how skillfully you manipulate the data and what you read into the data when you manipulate it, it’s still a curve–fitting exercise, albeit complex and nontrivial.” — Judea Pearl
If you were to ask today’s CNN why they chose to label a certain dataset as a cat and not a dog, it won’t be able to answer you, nor can you trace back their trains of thought (again, to both answer and to classify an image, it is another complicated topic of a visuo-linguistic model). Can it tell you what is the difference between a cat and a dog? No. Because they have no idea the concept of a dog, or a cat, or an animal. Or anything. On the other hand, children have an ability to form new concepts, unsupervised, based on can seeing the same entities a couple of times. Does an AI know the concept of conservation and transformation? I have not come across a computer vision paper that aims to implement such a concept into a model. This is because we can barely solve a normal object recognition task without relying on absurdly large datasets. You just feed in loads of data and hoping that the model does whatever it should do to achieve the best accuracy.
Visualisation of feature maps in CNN
Injecting Common Sense
Let us illustrate an example in which a DNN was assigned to the task of food container recognition (below). It is logically obvious to us that, based on its functionality, the food container should not be hanging from the ceiling, nor it should be upside down since this violates the physical rules we know of. It should always be placed on a solid surface. However, this knowledge is unknown to the network, thus, the network can be seen as learning ‘blindly’ and ‘freely’ without any knowledge of the real world. A commonsense so basic that even a young child would know, is still lacking in today’s model.
A language predictor like GPT-3 is tricky and it seems like it has already mastered this linguistic game. It already appears intelligent, giving you meaningful answers. But the true intelligence is a lot more than mastering a language game. This is the case of the real-world as well. It’s actually very easy to trick people into believing that you are intelligent. You can simply read smart facts from somewhere and put them into your own word. You can use someone else’s work as your template of speech. But did the model actually know about the poem it just wrote or did it simply just based it on a certain original piece and then predict a similar choice of word and style? Does it really have its own creativity, or is it just like a guy plagiarising someone else’s work without knowing what he’s really doing?
This applies to us humans as well because not all of us are considered to be intelligent either.
So, many predictors/classifiers today solely focuses on the accuracy of the predictions, seeking answers to “what” and “where”, neglecting the “why” and “how”, which require transparency to the reasoning process leading to a decision. AI researchers are very well-aware of this “black box” issue. This is why recently, there has been a major shift towards transparent/explainable AI, which attempts to bring back the dated symbolic AI approach and integrate it into today’s deep learning model so that the decision making process can be traced. This is known as “Neuro-Symbolic AI”. In simple words, researchers are attempting to inject logic so that the model can start to reason.
Although the definition of intelligent is extremely broad and subjective. But in the sense of symbolic reasoning and common sense, with transparent and traceable decision-making processes, the logical intelligence of the model can definitely be proven the same way you can ask a 7-year-old about how he/she arrives at a certain conclusion.
My point is, before today, it seems like we all just want to create a magical machine that is already at its prime adulthood the moment it was born. We want it to become an expert “from the start”, forgetting what it really is to be intelligent. To be logical. To know the cause and effect. To reason about the dynamic world around us without being constantly fed a hideous amount of the dataset. We ask ourselves questions. We can arrive at new conclusions without being handheld. And we forget that all of us were not intelligent from birth, and our intelligence and behavior stemmed from millions of years of evolution, coded in our genes. Having a machine to do just one task with no knowledge of the physical world is no different than teaching any man to do repetitive factory work. He doesn’t even have to think. In this sense, some people are no different than a machine. The main difference is that the machine’s computational speed and accuracy far exceed that of a human, which is why it does so well in this curve-fitting task. But in the end, it is still just statistical software, but an extremely powerful one, and with no sense of intelligence.
I will definitely write more about Neuro-symbolic AI in the future. But for now, I just want to introduce Turing’s idea of a child machine (which happens to align with my ideology of artificial general intelligence) and for the reader to sit and think about what artificial intelligence today is really capable of doing compared to that of a young child. Would you call them intelligent?
Part 2 of this article will focus on abstraction and formal logic. The cognitive characteristics found in older children and how the same concept can be applied to AI
===========================
Small Notes:
But what I find very interesting from GPT-3 is how it learns how to learn. Not in a human sense, with purpose, but it seems to arrive at a conclusion that it must learn or figure out certain things in order to obtain the best accuracy. I find the process of learning as a side-product to obtain the optimal results is very special and I cannot disagree that this is a major step towards a very powerful AI. I would like to emphasise on these “side products” in my future series about AI safety.
Machine learning and data science are founded on important mathematics in statistics and probability. A few interesting mathematical laws you should understand will especially help you perform better as a Data Scientist, including Benford’s Law, the Law of Large Numbers, and Zipf’s Law.
Also: Powerful Exploratory Data Analysis in just two lines of code; Machine Learning Systems Design: A Free Stanford Course; Telling a Great Data Story: A Visualization Decision Tree
Last week, I took Google’s Tensorflow Certification exam, a grueling 5-hour endeavor where the tester is required to build highly accurate models pertaining to image classification, text classification, and time-series predictors.
I ended up passing the exam, but it definitely was a beast and required incremental accumulation of subject matter knowledge over several years along with a very structured study schedule and hands-on practice.
I wanted to quickly share what I’ve learned since then about Tensorflow and about neural networks in general.
Artificial Intelligence Is Probabilities
Artificial Intelligence (AI) is all about probabilities at the most basic level, but we can sum it up in once sentence:
Artificial Intelligence is about arriving at the probability distribution of the truth.
You aren’t seeing this at the surface level because API’s like Keras extract the higher level math away, but ultimately its good to understand exactly what machine learning is doing under the hood so that we know when to put faith into what the model is telling us, and when not to.
So how are neural networks using probability distributions? Let’s take an example of using an AI model to predict heart disease.
Big Data Jobs
Let’s say I have a training dataset of 1000 patients, 980 are labeled to not have heart disease and 20 are labeled as having heart disease. As far as the model is concerned, this dataset represents the ground truth, the maximum amount of information present to be learned by a machine learning model to equate the real world.
What a neural network is doing internally is that it’s shifting its weights around to arrive at the expected distribution of the original training dataset. In other words, when you feed data into a neural network, what you’re saying to the network is this:
“Okay, neural network, I’m going to feed you some data where 980 of the inputs have class “0″ (“do not have heart disease”), and 20 have class “1″ (“have heart disease”). Please shift your network weights around when evaluating the input data so that your predictions will typically match around 20 class “1’s” for every 980 class “0’s””.
“Okay Neural Network, given all these X’s, give me the function for a red line that best fits the data distribution so I can predict future Y’s”
That’s all that’s happening under the hood. The neural network is converging in on a probability distribution for predictions that will most closely match the probability distribution of the original ground truth you fed into it.
This is an important thing to understand because if you’re feeding datasets into a machine learning model where the distribution of classifiers do not approximate the true distribution of those classifiers in nature, then your machine learning model will be pretty “untruthful” (useless) when you try to predict on new data.
This is the ultimate challenge of data science and artificial intelligence is that it’s not just about building efficient models, it’s actually more about what you’re feeding into them.
This is analogous to diet and exercise for people: if you’re training hard in the gym, but eating fattening and unhealthy foods, it doesn’t matter how great your training program is, you’re ultimately not going to get the results you’re looking for.
The hardest part about machine learning is understanding whether the distribution of your data matches that which occurs naturally in the physical world.
If I went out and sampled 1000 people for heart disease using their age, BMI, blood pressure, and other feature inputs to predict whether they have heart disease, how many of them would truly have heart disease?
But here’s the twist:
What if I sampled those 1,000 people standing outside my local gym? How might that affect the number of people in the dataset I record as truly having heart disease?
Conversely, what if I sampled the entire dataset standing outside of a McDonald’s?
Depending on how I collect the dataset, that is going to affect the ground truth distribution of “doesn’t have heart disease” versus “has heart disease” for training data. I may encounter far less people who truly have heart disease standing outside my local gym versus people who are regular diners at McDonald’s.
If I fed either of these datasets into a machine learning model, the model is going to converge in on the same probability distribution as the dataset that I fed into it. The model cannot learn any more information that what I originally gave it. It won’t tell me whether I am biasing it or not.
Neural networks cannot learn any more information than what you give them. They cannot tell you whether your dataset represents actual reality or not.
If my dataset is biased towards not having heart disease, the model will move its internal probability distribution to put a heavier emphasis on predicting someone to not have heart disease, which could yield a lot of false negatives if I started using that model in a clinical setting for cardiology patients.
This is fundamentally how artificial intelligence works: arrive at the probability distribution that would yield all these “y’s” for all these “x’s”. It’s an important concept to understand not just from a results perspective in machine learning, but also from an ethical standpoint.
Ultimately, artificial intelligence will give back to us only what we feed into them, they are merely a mirror for our own cognitive biases. It’s important that we realize that as we progress into the future.
AI is ready to change the business landscape especially in developing nations
courtesy lek
Artificial Intelligence is one of the most debatable topics today. It has enabled us to create the smart machines and reduce human efforts in complex and highly iterative processes. Latest developments in the field of technology have empowered the designers, all over the globe, to create much-improved machine learning.
Machine learning and artificial intelligence have paved the way for improved bots who are now ready to replace human efforts in many new industries.
According to a study by Oxford, 47% of jobs will disappear in next 25 years. We have already lost much more in the recent past. Many things which were earlier done by humans are either vanished from the market or are done by machines now. These losses have led to populist movements in many foreign countries and people are debating over the fears of losing further jobs from the markets.
Big Data JobsJob loss due to AI
People are very much concerned about many jobs which will be replenished by bots like models, sports umpires, telemarketers, paralegals etc. Many supporters of AI says that only jobs which don’t need high skills will be replaced. Highly skilled population do not need to worry much about jobs eradication. Almost all organizations do some or the other kind of upgrades to keep sync with the technology updates.
India is a country having a huge tech base and numbers are adding up in this industry. We have a huge population who does not read codes and understand technology. Here opportunities are immense. People who have worked abroad are coming back to India as they are seeing opportunities here.
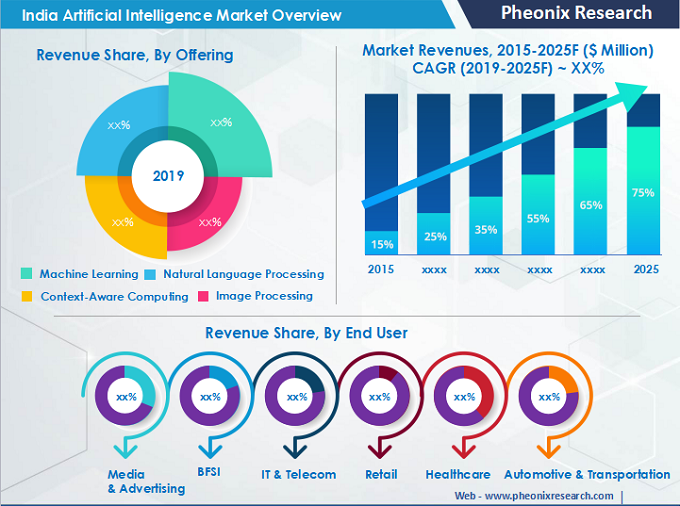
courtesy Phoenix research
A large number of jobs have vanished from international markets and a few are adding up. But here in India, there is enormous potential for jobs and the nation can create a myriad of job opportunities. Rising trends of online transactions, improving penetration of Internet to rural markets have shown promising signs to the service industries.
There are many services to be given and much more to deliver to a common man. It can surely surpass the early fears of AI in the global markets. Indian markets because of its huge potential can stay aloof from the global vulnerability.
Many new jobs are introduced in the markets which never existed. Perhaps, the recent growth of Artificial Intelligence market is driven by the improved IT infrastructure and mobile phones penetration in India. Companies are investing heavily because they are seeing promising users for AI in Indian service sector. AI can help in creating the services at a rate compatible with the demand.
According to a recent survey, almost 4000 machine learning and AI programmers are needed in Banglore alone. Even the government is giving the required push, it wants AI to transform the public sector and it’s functioning.
The promising aspects of machine learning and artificial intelligence are higher in developing countries like India, who are looking at it as a boon for serving their large population. The major sectors in India which could be affected by AI are manufacturing, agriculture and IT. The number of jobs eroded by AI will be easily replenished by the new jobs created here if not instantly then in the longer run.
The launching of Make in India movement is focusing on improving all these prominent sectors of Indian economy. Skill India is another ambitious campaign launched by the current government. This movement will strengthen the existing sectors and will open further ways to create jobs. People in India are being skilled for other jobs too. The movement is focused on improving the employability as well as the skill set of the current workforce.
“Stay Informed and connect to Saavy Relations for the latest updates.”
Your Feedback is Highly Appreciated! We really appreciate the time you took to help us improve.