Artificial Intelligence (AI) is getting integrated into vital fields making human life more efficient and productive. Similarly, AI in agriculture is making agriculture and farming easier with computer vision-based crop monitoring and production system.
AI Robots, drones and automated machines are playing a big role in harvesting, ripping, health monitoring and improving the productivity of the crops. But do you know how these AI-enabled machines help in precise agriculture and farming?
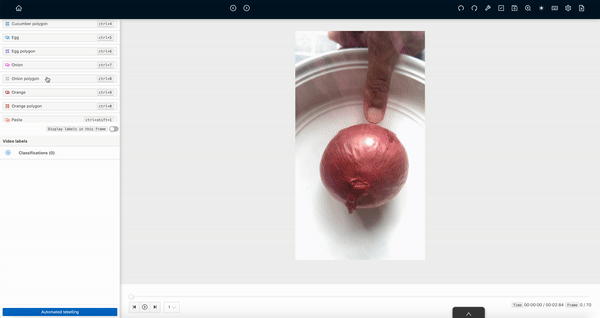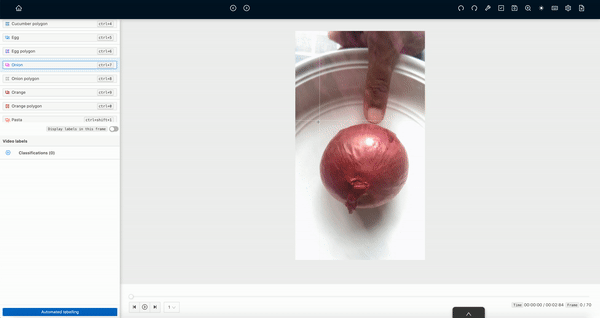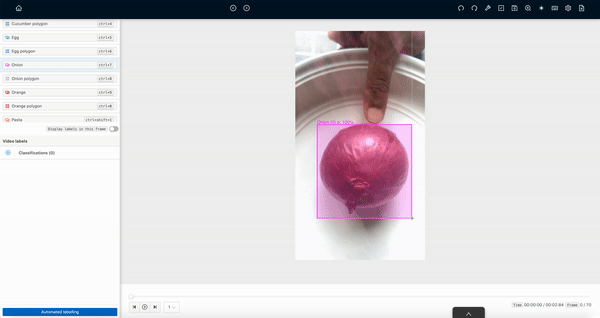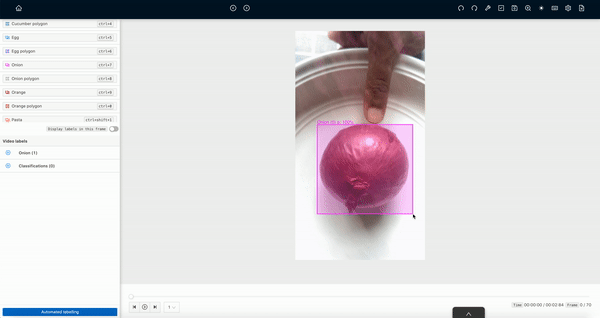
Actually, these AI machines work on computer vision technology and AI models are trained through annotated images fed using the right machine learning algorithms. Image annotation is the process that helps machines to detect or recognize various objects or things in the agricultural fields, so that machine can easily identify and take the right action.
Also Read: How To Select Suitable Machine Learning Algorithm For A Problem Statement

IMAGE ANNOTATION FOR MACHINE LEARNING IN AGRICULTURE
Image annotation in agriculture helps to detect and perform various actions like detecting the crops, weeds, fruits and vegetables. And when a huge amount of such annotated data is feed into the deep learning algorithm, the AI model becomes enough to recognize similar things like picking the plants, checking the health of the crops.

Also Read: How To Improve Machine Learning Model Performance: Five Ways
Image annotation is playing a crucial role in applying machine learning to agricultural data created through the data labeling process. Let’s find out how and what are the applications of machine learning in agriculture possible through image annotation services.
Robots for Precision Agriculture
Robots are nowadays widely in use across the fields. In the agriculture sector, it is performing various actions with the help of machine vision algorithms to operate successfully. It can perform actions like plowing, seeds planting, weeds handling, monitoring of productivity growth, fruits, and vegetable picking, packaging, sorting and grading, etc.

Robots can also detect weeds, check the fructify level of fruits or vegetables, and monitor the health condition of plants. Apart from that, using the computer vision camera, robots can classify the various fruits at high speed with better accuracy.
Also Read: Applying Artificial Intelligence and Machine Learning in Robotics with Right Training Data
And deep learning algorithms can identify defects from any angle with large color and geometric variation. The algorithms are set to perform the first object detection
Trending AI Articles:
2. Generating neural speech synthesis voice acting using xVASynth
4. Why You’re Using Spotify Wrong to locate the fruits and, after that, the classification is done accordingly.
To train robots annotated images of such plants, crops and floras are feed into the algorithms. Bounding box annotation is one of the most popular image annotation techniques used to make the crops, weeds, fruits and vegetables recognizable to robots.
Sorting of Fruits and Vegetables
After collecting the fruits and vegetables at the time of packing at processing plants, a sorting task is performed by the robots to separate the healthy and rotten fruits or vegetables from each other send them to the right place. These robots can also detect existing features and defects, to predict which items will last longer to ship away and which items can be retained for the local market.

Sorting and grading tasks can be performed based on deep learning using the huge quantity of training data of annotated images. Making the sorting and grading process accurate is possible when precisely annotated images are used to train the robots.
Similarly, robots can sort the flowers, buds, and stems of different breeds, sizes and shapes, making them usable as per the strict standards and rules in use in the international flower markets. And with the help of first-class image annotation techniques, AI-enabled machines save time and reduce wastage promising more precise agriculture and farming.
Anolytics provide the data annotation service to help robots detect the different types of fruits and vegetables with the right accuracy. And as much as similar data will be used, the robots will become more efficient to detect such things agro field.
Also Read: Why Data Annotation is Important for Machine Learning and AI
Monitoring the Health of Soil, Animals & Crops
Using Geosensing technology, drones and other autonomous flying objects can monitor the health condition or soils and crops. This helps farmers to make sure what is the right time for sowing and what action should be taken to save the crops. Right soil conditions and timely insecticides are very important for better production and high crop yield.

Similarly, AI-enabled technology makes it possible to detect the health of animals. Yes, Body Condition Score for bovines is the technique that helps to accurately measure the body of the cow, buffalo and other similar animals. Such a score is actually given by the veterinarian. As the body condition of such animals affects reproductive health, milk production, and feeding efficiency, and AI-based knowing the score helps the animal husbandry business more profitable.
Crop Yield Prediction Using Deep Learning
AI in agriculture is possible with deep learning datasets that help to predict the crop yield through portable devices like smartphones and tablets. Collecting and developing deep learning platforms requires expert knowledge for their training in order to provide reliable yield forecasts using the ample amount of training data used to train such models.
AI in Forest Management
Using aerial images taken by drones, planes, or satellites, AI in forest management is possible. Yes, images that are taken from such sources help to detect illegal activities like cutting trees that leads to deforestation affecting the biodiversity of our planet.
Also Read: How Satellite Imagery Dataset Used in Artificial Intelligence: AI Applications for Satellite Imagery
Actually, aerial images taken by drone, plane or satellite, in the field of forestry is automating the process of forest management through huge amounts of data to produce accurate measures, assessing the health and the growth of trees and enabling forest management professionals to make more accurate decisions while controlling the deforestation.
Other Projects in Precise Agriculture
Apart from the above-discussed use cases, image annotation offers various other object detection efficiencies in agricultural sub-fields irrigation, weed detection, soil management, maturity evaluation, detection of foreign substances, fruit density, soil management, yield forecasting, canopy measurement, land mapping, and various others.
Anolytics for Image Annotation in Deep Learning for Agriculture
Acquiring high-quality machine learning training data for computer vision-based AI models is a challenging task for the companies working on such projects. But dedicated data annotation companies like Anolytics are providing the right solution for AI companies to get the computer vision training data in large volumes at the lowest cost with the best accuracy.
Also Read: Top Data Labeling Challenges Faced by the Data Annotation Companies
Anolytics is known for providing training datasets for various fields like Healthcare, Agriculture, Retail, Self-driving cars, Autonomous Flying, AI Security Cameras, Robotics and Satellite Imagery. Working with world-class annotators, Anolytics ensure the precision levels of data labeling at every stage making sure the machine learning project can get the right data for giving accurate results by AI models especially when it is used in the real life.
Don’t forget to give us your ? !




Role of Image Annotation in Applying Machine Learning for Precision Agriculture was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.