365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Thanks to the diversity of the dataset used in the training process, we can obtain adequate text generation for text from a variety of domains. GPT-2 is 10x the parameters and 10x the data of its predecessor GPT.
“AI is likely to be either the best or worst thing to happen to humanity — Stephen Hawking”
Iron Man | A.I | Marvel
Artificial Intelligence is the one of the most popular term in 21st century. It has carved new ways to work and progress and even learn. It has enabled computers to show some intelligence somewhat similar to humans. It has transformed the working style in organizations, the decisions are data-driven and customers are niche. AI is becoming one of the most demanded skill in the job market and is being considered as a great replacement for many repetitive jobs. One need to upgrade to avoid getting wiped out by technology replacement. For more info you can read: will machines replace us in future
There are many jobs which have repetitive work and thus they are being replaced by machines. 50-75 million Jobs worldwide that will be affected due to the advent of AI. With machine learning, computers are claiming to be a good replacement for many other jobs too.
As many as 30 per cent of jobs could be replaced by AI by 2030, according to a report by PricewaterhouseCoopers.
Big Data Jobs
The prime impact could be on sectors like healthcare, finance, manufacturing, hospitality, games, tourism and even education. There are huge possibilities in other domains too and so people in these industries need to upgrade and get ready for newer roles and responsibilities.
Soon we will be surrounded by machines in our job. Someday you will notice that the new employee who have recently joined your firm is a bot and not a human. As of now machines are learning how to work with humans and trying to learn our ways. They are being made to look like us and work like us. Bots are even trained to react to some of our jokes so that they can get a better acceptability among the human workforce.
courtesy digital trends
Soon we have to make some space for these smart beings in our workplace and learn how to work with them. Bots are learning to react and interact same as humans and some day this difference will almost disappear. We have to start accepting to this new normal and learn how to cope up with such situations. We will either work with machines or will work on the machines. In either case, we need to understand these bots and learn maximum about them.
“By far, the greatest danger of Artificial Intelligence is that people conclude too early that they understand it.” — Eliezer Yudkowsky
Learning AI will have impact on a child’s learning phase and will shape up their skills for future jobs too. It will open their ways to make a livelihood as well as become an entrepreneur. It can change their thought process and make them much more productive.
Get Future ready:
We need to train our kids for the future jobs which will be in market in coming years and it is the real meaning of education. In most part of the world, education system is not upgraded and still in its primitive stage. The kids who are studying might miss some of the crucial concepts in their prime learning phase. It will create a huge skill gap which is already haunting the organizations. Kids should learn about AI in their early years as they have huge affinity for new concepts in early years and it can shape up their interests and careers.
Learn problem solving skills:
Creating something which can be as good as humans for doing any job is an interesting problem and solving a problem needs a kid to think and ideate. It helps them to use resources judiciously to achieve their goals. kids learn to manage things and handle situations and it helps them in building confidence and develop social skills by working in a team.
Hone coding skills:
Computers understand only codes and communicate with codes only. Coding is a way to interact with machines and use their skills for solving a problem and getting solutions to the problems. Learn coding will prepare kids for many future jobs and create better solutions using machines.
Ignite curiosity:
Solving an AI problem is fun and kids enjoy working on it and simultaneously they learn many aspects of AI technology. It enhances their creativity and innovation. Starting in early years is always beneficial as humans are creative and can find better solutions when young. A newly curated curriculum having latest technologies embedded will keep kids on their toes and someday they could even craft their dreams to reality.
Stay relevant:
A person can’t say that he doesn’t know how to shop from an online store or use a android phone just because he doesn’t have a science background. Soon market will have driverless cars and one can’t say that he is not a science graduate so he will not use it. We have to upgrade ourselves and learn about new things. AI is transforming our ambience and we have to keep pace with it.
AI is “A core, transformative way by which we’re rethinking how we’re doing everything.” — Sundar Pichai
Welcome back to our blog series about machine learning projects. Are you involved in planning an AI project? Then you’re in the right place. We explain all the project phases in a series of blog posts.
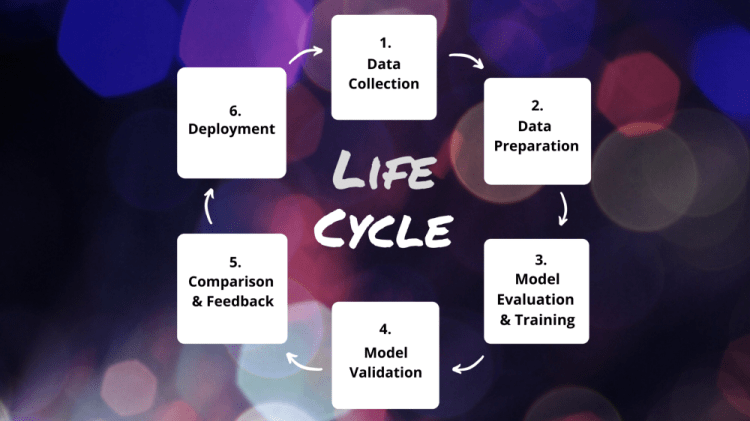
The six phases of our machine learning life cycle.
Today, we’re going to dive into the actual model training and finish phase 3 of our machine learning life cycle.
Our goal is to build the best possible model for our image classification task where we have to classify images as aesthetic or unaesthetic. These images are about dance and should be appropriate for a dance federation’s marketing.
Hyperparameter Tuning
In our previous article about model evaluation, we have chosen our initial machine learning model. Now, we want to train this model with our 5,550 images.
Big Data Jobs
Hyperparameters are used to control the training process, consequently they have to be set before the training starts. The process of finding the optimal hyperparameters to maximize model performance is called hyperparameter tuning.
Hyperparameters can be tuned manually or automatically using algorithms like Grid Search or Random Search. These algorithms test different parameters using a certain strategy, train several models and try to find the best hyperparameters. If we train a model from scratch this is very expensive for computer vision tasks, since huge amounts of data is required. Although in our example we can benefit from transfer-learning and therefore only need some thousands images, we want to focus on manual hyperparameter tuning in this blogpost.
Different models have different hyperparameters. Let’s have a look at the most common hyperparameters we use in our projects.
1. Optimization algorithm
During training the optimization algorithm calculates the needed changes to the model weights in order to minimize the loss gradient (the loss is an indicator for the faultiness of the model predictions).
Three examples of finding a local minimum loss
The most common optimization algorithm is the stochastic gradient descent, SGD in short. It calculates the needed changes to model weights based on some random samples of the training set (hence the name stochastic) to find a local minimum. Since SGD involves only some samples we can reduce the calculations enormously and speed up training.
There’s another optimization algorithm called Adam which has a striking advantage: Adam automatically adapts the learning rate (the most important hyperparameter, see below) resulting in better training with fewer experiments. For our current classification task we choose Adam.
The batch size defines the number of training samples propagated to the neural network before updating its model weights using the chosen optimization algorithm.
We can’t pass all our training samples into the neural network at once. Therefore, we divide it into batches. In our example project we have 5,550 training samples and we set up a batch size of 50. That means 50 samples are propagated to the neural network and after that the model updates its weights based on the loss gradients of these 50 samples.
Then it takes the next 50 samples (from the 51th to the 100th) and trains the network again. This is repeated until all samples have been propagated to the network. The smaller the batch size, the more frequently the model weights are updated. The larger the batch size, the less frequently the model weights are updated.
If the batch size is very large, this can reduce the quality of the model, measured by its generalization ability. In addition, a lot of memory is needed.
The advantage of a small batch size is that the network usually trains faster and it also requires less memory.
3. Learning rate
The learning rate defines how much the model weights will be adjusted after each batch with respect to the loss gradient.
Usually we use an inital learning rate of 0.01 or 0.001. There is no perfect learning rate and also no perfect value to start with. In general, if the learning rate is too low or too high, the model will not learn at all.
Additionally, the learning rate can be changed over time using a decay rate. This means that the model adapts very strongly at the beginning and the longer it has learned, the less it adapts.
4. Regularization
We do not want our model to overfit or underfit. If the model is not complex enough for the learning problem it underfits and we need to choose a more complex model.
If the model is too complex it overfits the training data leading to a poor ability to generalize on unseen data. In this scenario we can apply regularization techniques to force the learning algorithm to build a less complex model.
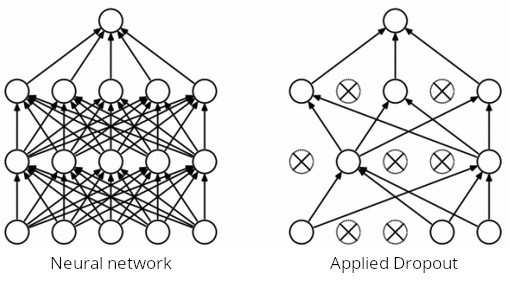
The dropout regularizer temporarily excludes some random units of the network while training. This helps to prevent the model to just memorize the training data which leads to overfitting.
There are other neural network specific regularizers like early-stopping and batch-normalization.
Model Training
After setting the hyperparameters as described above we start training the model. The model accuracy we’ve reached after just some epochs is 86% which is already pretty good and signals that the model is complex enough and does not underfit.
Result Evaluation on Unseen Data
Now, it’s time to test how well the model generalizes. We do this by comparing the training accuracy to the accuracy on unseen data, the validation set.
Both accuracies should be close to each other. Then, the model is good at transferring what it has learned from the training data to unknown data. If the validation accuracy far below the training accuracy, it means the model overfits and cannot generalize well. Since our validation accuracy is only 60% our model overfits and we have to tune hyperparameter accordingly.
In our case we introduce dropout as regularizer to avoid overfitting. Then we train again and measure the evaluate the results.
What’s Next?
In the next article we’ll face the reality check: Is our model already good enough to go into productive use? We’ll try to understand the behavior of our model, which aspects are already very well solved and which are not, and most importantly: why? Stay tuned!
With traditional home security devices, the system can be programmed to trigger a predetermined response based on certain events. For example, if the system is armed, the countdown begins when the door is opened. If you fail to enter the code on the keypad in time, it alerts the police or an offsite security professional to a potential intruder.
Although this system is prone to success, many problems arise. The biggest problem is that it can lead to a problem with false alarms. False alarms are obviously uncomfortable but insufficient, and they can lead to a lack of response when a real security problem occurs. If the police or security services receive too many false alarms in a short period of time, they may decide that future events do not require the same urgency of response.
The same may be true of CCTV cameras. Your standard security camera is the most passive measurement. It acts as a deterrent, but in the event of a crime, they only serve to record evidence; They do nothing to prevent crime. Thanks to AI programming, this has begun to change.
With the security system of the future, every aspect of your home care system will be connected through IoT. Everything from CCTV cameras, door locks, lights, and audio sensors can collect data and then be analyzed using machine learning.
Big Data Jobs
By analyzing this data, the system can learn about the habits and activities common to the property. Once the system has a profile of regular functionality, it can use what it has learned to manage the home security process more effectively.
You start to see things like locks, which come together with cameras to detect different visitors, not just knowing the normal times that different people come and go. It allows information program access decisions to be made.
The system may also notice that you have forgotten to lock your doors when you leave home and send a reminder to your smartphone. After you receive the notification, you can use the linked smartphone app to lock the door without returning home.
Security cameras are widely recognized as one of the most effective exploit resistors. When a thief sees the cameras, they are likely to pick up another target. The impact of these cameras has made them more common in home security. Their popularity is also growing thanks to the recent progress we have made in CCTV technology.
Features such as HD recording, cloud storage, and remote monitoring are common in modern security cameras. In addition, some new systems have begun to use AI programming, making CCTV more effective. With machine learning, the security system can be learned to detect people at home. This helps the system when it needs to decide whether to trigger an alarm.
Beyond facial recognition, security cameras can also be programmed to detect objects. It is used to help the system tell the difference between a dangerous stranger and a homeowner delivering the package.
Smart Locks
The old lock and key represent traditional ways to maintain access control at home. If a person has the key, they can come and go as they please. If they don’t, they need someone with a key to providing access.
With the development of smart locks, these are all set to change. With SmartLock, the physical key is related to the past. Instead, people can gain access by using zip codes and smartphone apps. With SmartLock, you can manage different levels of access for different people and the system goes on as long as the access record is maintained.
Many of these systems also come with features intended to increase their flexibility. Smart locks are connected to your home’s Wi-Fi, so you can program them to unlock when you get to the front door. With some smart locks, you can also use a digital personal assistant to unlock the door using voice commands. When a guest arrives, you can tell your digital assistant to unlock the front door.
The problem with traditional security systems comes down to programming. Although they can be set up to respond to event-based triggers, they still need humans to do the most important things. With the development of AI, there is less need for human security professionals. The smart system can monitor themselves and perform tasks such as contacting emergency services.
SEO Executive and a Content Writer interested to write on Artificial Intelligence, Mobile App development, Machine Learning, Deep Learning, HRM & tech Blogs
Many resources exist for the self-study of data science. In our modern age of information technology, an enormous amount of free learning resources are available to anyone, and with effort and dedication, you can master the fundamentals of data science.
In this article, we explore how to build a pipeline and process real-time video with Deep Learning to apply this approach to business use cases overviewed in our research.
Do we need more data engineers than data scientists? Data Science vs Business Intelligence, Explained; Telling a Great Data Story: A Visualization Decision Tree; Essential Math for Data Science: Scalars and Vectors; 7 most recommended skills for a Data Scientist.
Hands-On Machine Learning Training from UChicago: 5-week remote Machine Learning for Cybersecurity certificate, Mar 30 – Apr 27. Learn from & network with leading faculty/industry leaders, learn data-driven prevention strategies. Group discounts, tuition support.
To trigger an alert when data breaks, data teams can leverage a tried and true tactic from our friends in software engineering: monitoring and observability. In this article, we walk through how you can create your own data quality monitors for freshness and distribution from scratch using SQL.
Every project in data science begins with discovering the correct features. The issue is that there is not a unique, centralized place to browse for the most part; features are hosted everywhere. First and foremost, therefore, a feature store offers a single glass pane to share all the features available. When a new project is launched by a data scientist, he or she can go to this catalog and quickly locate the characteristics they are searching for. But not only is a data layer a function store, but it is also a data transformation provision that allows users to access raw data and organize it as features that are ready for any machine learning algorithms to use. Candidly, the future of ai will look like those who build it, likewise, the race is still on to be the prime architect.
Most of today’s artificial intelligence can be labeled as either historical or streamed and is stored in libraries, data lakes, and warehouses of data. All are on-site, in the cloud, and at the edge of the premises. Plenty or even hundreds of networks handle critical data about clients, patients, supply chains, etc. This fragmentation makes it exceedingly difficult to conduct enterprise-wide real-time simulations.
Big Data Jobs
Imagine an executive who needs to know how many patients have visited three or more health centers in the last five years, broken down by geographic area and result, as an incredibly simplistic example of how data is usually accessed for research. Traditionally, a researcher writes the necessary queries and pushes them down to the individual database to return information, or a centralized copy of the data is compiled in the case of data lakes or feature store for ML systems. An operation such as this can take hours or days to plan, at best. Real-time performance cannot help the query duration alone.
The global AI software market is projected to grow by around 54 percent year-on-year in 2020, hitting a forecast size of US$ 22.6 billion. AI is a term used to describe a range of technologies that are capable of learning and solving problems by producing sophisticated software or hardware.
Maybe that manager doesn’t mind waiting hours or days, but what if he or she wants to see a constantly updated hospital bed efficiency prediction to make critical strategic decisions? Conventional methods can easily transform into a big organizational undertaking to satisfy a forecasting, real-time necessity like this.
Benefits:
Rapid advancement
Preferably, data scientists will concentrate on what they have been learning to do and what building models are effective. They still indeed, find themselves having to spend much of their time in architectures for data engineering. Some functions are costly to compute and require consolidation of structures, whereas others are transparent.
Smooth model implementation
One of the key challenges in the implementation of machine learning in manufacturing emerges from the reality that the features used in the development environment for training a model are not the same as the features in the production feeding layer Consequently, it allows a smoother implementation phase to enable a compatible form factor between the training and delivering layer, ensuring that the trained model actually represents the way things will function in production.
The feature store holds added metadata for each feature, in addition to the original features. For instance, a statistic that measures the effect of the function on the model with which it is affiliated. When choosing features for a new model, this knowledge will benefit data scientists immensely, enabling them to concentrate on those that will have a better effect on similar existing models.
Better cooperation in the performance
Communication is trusting, the fact today is that almost every new business service is focused on machine learning, so there is an exponential increase in the number of project activities and features. This decreases our ability, because there are just too many, to provide a good detailed overview of the features available. Instead of creating in processing facilities, the feature store enables us to share with our colleagues our features alongside their metadata. In large organizations, it is becoming a frequent issue that multiple teams end up creating similar solutions and they’re not aware of the duties of each other. Feature stores connect the distance and allow anybody to share their job and prevent redundancy.
Track lineage and discuss compliance with regulations
It is important to monitor the lineage of algorithms being developed to comply with guidelines and regulations, particularly in cases where the AI models being produced serve industries such as medicine, finance, and defense. To achieve this, insight into the overall start to end data flow is needed to better understand how the model produces its outcomes. There is a need to monitor the flow of the feature generation process as characteristics are generated as part of the process. We can preserve the data lineage of a component in a feature store. This provides the required tracking information that collects how the role was produced and provides the required insight and reports for compliance with the rules.
Features store and MLOps
MLOps is a DevOps extension where the idea is to apply the concepts of DevOps to machine learning channels. Designing a machine learning pipeline, primarily because of the data element, is different from developing apps. The model’s quality is not just dependent on the code performance. It is also dependent on the quality of the information that is used for running the simulation from raw data.
In ML pipelines, the Features Store solves the major issues:
· By sharing features between teams/projects hence reuse of feature store.
· Enables web applications to serve functionality at scale and with low latency.
· Ensures the continuity of functionality between training and operation. Features are created once and can be stored in online and offline feature stores.
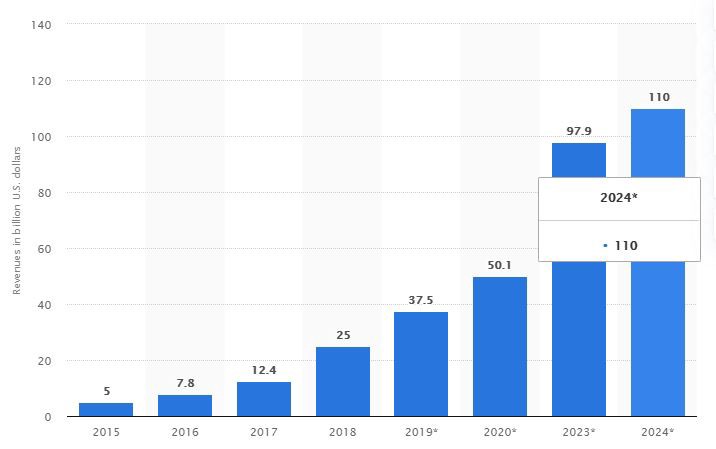
· When a prediction has been made and a result comes later, we need to be able to question the values of various features at a given moment in the past. It ensures point-in-time accuracy for the feature store. Revenues from both the intellectual and AI systems industry are projected to hit 50.1 billion U.S. dollars in 2020.
· The estimated value of the proportion of AI contributions to GDP reached its peak, theoretically contributing to around 26.1% of its GDP. This was by North America, which contributed to about 14.5% of GDP.
Conclusion
Data scientists can now scan for functions and conveniently use them with API software to build models with complete data engineering. In addition, other models will store and recreate features, minimizing model training time and expense of facilities. Features in the Company are now a regulated, controlled commodity. The API for the Feature Store is used to read/write features from/to the feature store. There are two modules in the feature store; one interface to write tailored content into the feature store and another functionality to read information from the feature store for training or operation.
It becomes easier and quicker to build new designs as the feature store is designed with more features, while the new models will recycle features that reside in the feature store. For the AI tech to advance in its domain, the feature store initiative will be a supercharger. This in turn will reduce the cost of training the models repeatedly. Based on the AI/ML revenue numbers, it is promising for the feature store to be a strong substratum for all the AI/ML models.