Data Labeling Industry Needs to Take the Lead in Reform as AI is Difficult to Break the Ground

AI landing has become a difficulty
Two years ago, the investment and financing enthusiasm of the artificial intelligence field has been greatly reduced, and a considerable number of AI enterprises have completely disappeared. “The cold wave of artificial intelligence has arrived” has even become the industry’s hot word in 2019.
Compared with the boom a few years ago when entrepreneurship and investment enthusiasm went forward together, the AI industry has suffered a lot recently.
The reason is that “AI landing has become a difficulty”.
From the age of automation to the age of AI, the value created by artificial intelligence is constantly increasing. Meanwhile, the refinement and complexity of business scenarios are also constantly improving, bringing a series of challenges for AI landing.
When it comes to specific business industries, autonomous driving is the most important commercial field. Although the investment is a lot in unmanned driving/autonomous driving, the product is still far from large-scale commercial application.
At present, the main application scenarios are nothing more serious than road tests, exhibitions, and test drives in parks. However, these obviously cannot bring any substantial income to a profit-oriented enterprise.
Enterprises require profit, and AI enterprises are no exception. The most urgent issue is how to break the “AI landing difficulty” dilemma.

The key to breaking the difficulty of AI is to find out what factors lead to this result.
In the field of artificial intelligence, algorithms, processing, and data are three important basic elements of the industry. For a long time, AI enterprises mainly focus on the field of algorithms and processing, generally pay less attention to the training data.
In fact, as the basement of the AI industry, data plays an important role in AI implementation. To apply AI to specific business scenarios, data quality and accuracy can not be neglected.
There is a simple but important consensus in the AI industry
The quality of the data set directly determines the quality of the final model.
In the early stage, the focus of the AI industry is mainly on the theory and technology itself. At this time, a cutting-edge technology concept is likely to bring huge external investment to the enterprise.
At the relatively mature stage, investors and AI enterprises turn their attention to the commercialization part. After all, investors care about most is the profits.
Trending AI Articles:
2. How AI Will Power the Next Wave of Healthcare Innovation?
Specific commercial landing scenario showing up
However, the combination of theory and practice is not always smooth as imagined. In the process of commercial implementation, AI enterprises have found a problem: although the quality of annotated data sets can meet the basic needs of laboratories, it cannot support the development of AI implementation.
We take examples as evidence:
In single-point scenes such as face recognition, the related data types are generally simple. But in a more complete business scenario, the data becomes more complex.

In an industrial scenario, it would involve more refined data labeling, such as industrial scene image annotation, processing text data, and equipment running data.
In the medical scene, the annotation of medical images and texts requires personnel with medical professional knowledge.
In the past, only a small amount of datasets with high quality can meet the requirements in the laboratory. However, in the specific commercial landing scenario, there are many new requirements for annotated datasets:
Large scale, high-quality, scenario-based, customized.
In such a new situation, the key to breaking the ice is the reform of the data annotation industry.
In the trend of AI commercialization, the data annotation industry should not fall behind but should take the step forward.
ByteBridge, a human-powered data labeling tooling platform
On ByteBridge’s dashboard, developers can define and start the data labeling projects and get the results back instantly. Clients can set labeling rules directly on the dashboard. In addition, clients can iterate data features, attributes, and workflow, scale up or down, make changes based on what they are learning about the model’s performance in each step of test and validation.
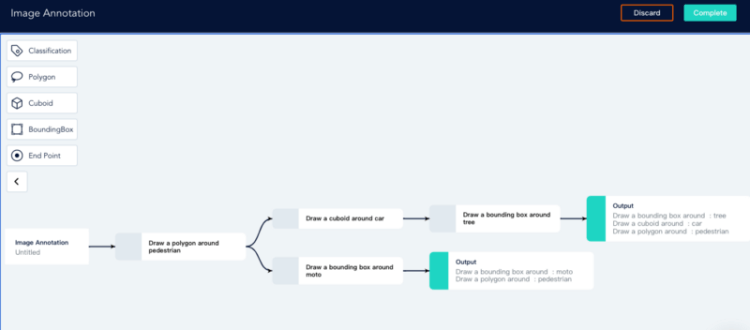
As a fully managed platform, it enables developers to manage and monitor the overall data labeling process and provides API for data transfer. The platform also allows users to get involved in the QC process.
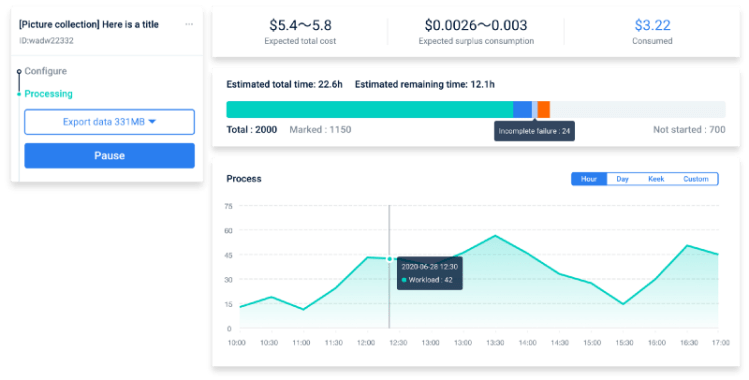
These labeling tools are available: Image Classification, 2D Boxing, Polygon, Cuboid.
We can provide personalized annotation tools and services according to customer requirements.
End
If you need data labeling and collection services, please have a look at bytebridge.io, the clear pricing is available.
Please feel free to contact us: support@bytebridge.io
Don’t forget to give us your ? !




Data Labeling and Annotation for ML Projects in 2021 was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.