Check out these seven Python libraries to make your first data science MVP application.
Originally from KDnuggets https://ift.tt/2MwZ20o

365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Originally from KDnuggets https://ift.tt/2MwZ20o
As the world moves towards more automation, the ethical debate about the role of AI in health care is becoming more relevant. In this article, we will explore some of the ethics involved in AI in health care and how they affect health professionals.
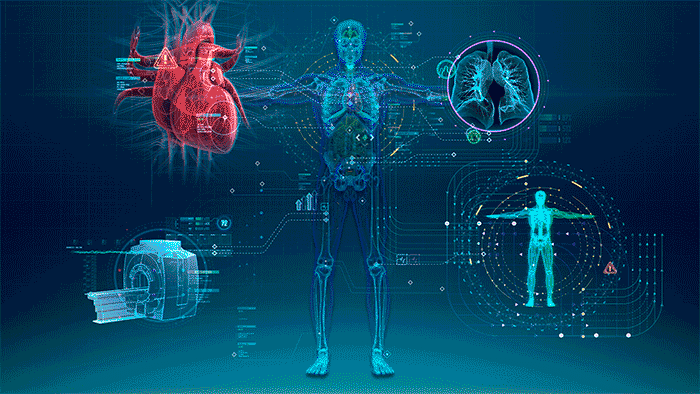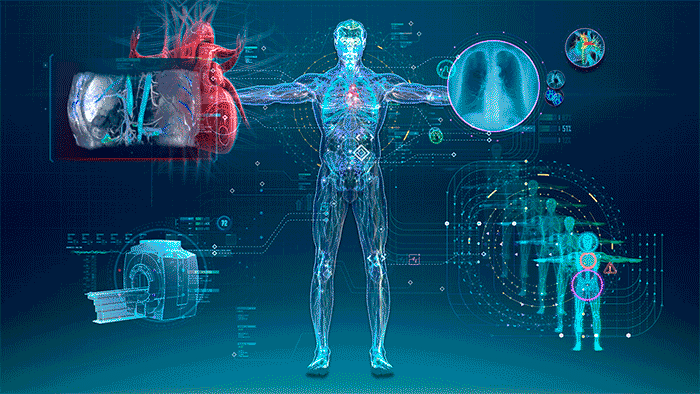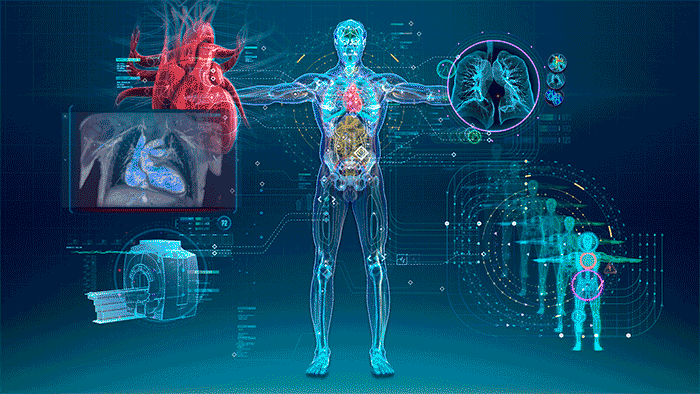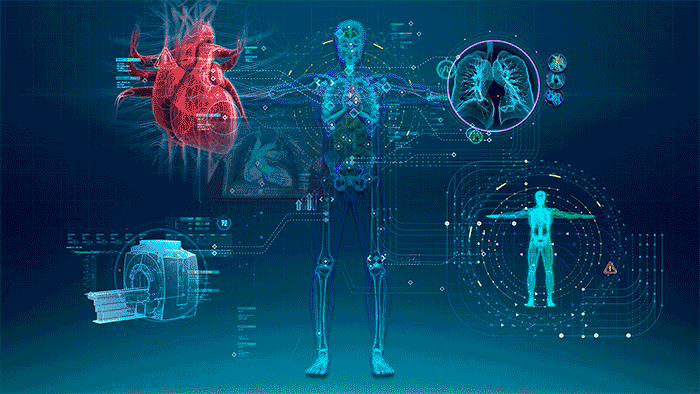
Ethics of AI in Healthcare
A variety of ethics apply with AI in health care. The ethics body deals with medical consent. As AI becomes more and more a part of daily life, medical compliance becomes an issue. This is because it is unclear who is responsible for the patient’s medical consent when making human decisions or doing things without human input.
Another set of ethics is what information is collected and used by AI. In this case, it is important to think about what is being collected and where that information is going. There are also ethics on who has access to the information collected by AI. Who has access, discrimination based on race, gender, or other factors?

Ethical implications of AI in healthcare
Computer ethics is an important branch of ethics that began in the late 1950s and early 1960s. It arose in response to the introduction of computers and the ethical implications they presented.
The field of computer ethics deals with the ethical and ethical implications of the existence and use of computers.
AI has a variety of ethical implications in health care. The first moral complication is the moral responsibility associated with AI. Moral responsibility is the duty to take responsibility for their actions.
Some would argue that because AI is sentimental, they have no moral obligation. However, it is important to note that AI can have moral responsibility.
As an example, the computer program used for medical diagnosis is not sentimental, but the program has a moral obligation associated with that diagnosis.
The second moral dilemma is the responsibility associated with the developer of AI. It is responsible for ensuring that AI can meet the needs of the people.
The third moral complication is the liability associated with the user of AI. It is our responsibility to ensure that AI is not used for unethical purposes.
The fourth moral complication is the responsibility associated with people affected by AI. AI is responsible for ensuring that it does not adversely affect a group of people or society.
The fifth moral implication is the liability associated with the use of AI. It is our responsibility to ensure that AI is not used in ways that infringe on the rights of others.
The sixth ethical riddle is the responsibility associated with the ethical principles used to guide the design of AI. These principles are used to assist developers of AI to ensure that AI does not violate any ethical principles.
2. Generating neural speech synthesis voice acting using xVASynth
Impact on Healthcare Professionals
The impact of health professionals is significant as more work is undertaken by AI. Patients need to change their role from decision-makers to educators and navigators, guiding them through their care journey. There are other effects as well. One potential impact is that patients will rely on AI instead of health care professionals, which will reduce their need for care. Similarly, some may resort to AI as a reliable source of information on a variety of conditions, which can lead to a loss of confidence in scientists or physicians for accurate information.
As more and more artificial intelligence is being used in health care, there are many implications for professionals in this field. One effect is that it changes the way they train to do their job. As AI becomes more integrated into the health care system, they need to understand how AI works and what it can do. In addition, professionals need to learn how to work with AI systems.
Another effect on professionals is that they become less autonomous than before due to greater reliance on automation. This distances them from certain areas of medicine, as those fields rely heavily on human judgment or intelligence for success (e.g. psychiatry).
In health care, many ethical dilemmas arise when a machine is doing what a normal human being does. For example, if the robot makes an error in its calculations and indicates the wrong dose of medicine, it can cause serious injury or death. These kinds of dilemmas have led some to argue for the formulation of rules and regulations for AI in health care.
While people disagree on whether the use of AI in health care is acceptable, we know that it is not always as accurate as the human being doing the work. Some argue that any errors made by AI can lead to a slippery slope in the direction of making mistakes even with humans because robots are not really responsible for their actions. Others say that the cost savings associated with using machines can outweigh those risks and enable us to provide better care at a lower cost, which is what we desperately need in our health system today.
It would be unethical for people to use AI to determine who should be treated before their turn because a person who waits longer will not receive treatment even if he or she is more qualified than another person who is treated immediately upon entering the emergency room.
Some other ethical dilemmas that arise with AI in health care include the privacy of the robot. If the robot does not want to know their medical history and the robot needs that medical history to perform its function, can it access that data? Do robots seeking medical information from a person need permission from that person before proceeding?
Another problem with the use of AI in medicine is that its misuse by health insurance companies and pharmaceutical companies can lead to biased or unethical practices towards people with disabilities or the underprivileged. This lack of ethics surrounding the implementation of AI in health care has prompted many, including Elon Musk, Steve Wozniak, Bill Gates, Stephen Hawking, and dozens of others, to talk about their problems with its use.
Many ethical questions arise when Artificial Intelligence (AI) is prevalent in industries including healthcare, as it poses new risks such as increased automation that leads to less work for physicians in hospitals, while at the same time threatening care standards for patients in need of medical assistance.
This concern can be addressed through the control that requires accountability from all parties involved in the use of an individual’s data when implementing technology in the business model against patient care ethics and bias or unethical security measures. Practices towards disabled or marginalized groups
Ethical discussion in AI is important not only for health care professionals but for society as a whole. It shapes how automated systems are used in all fields and what our expectations are when interacting with them.
In conclusion, we want our technology to improve society so that we can take care of how it is implemented so that it does not harm in ways that we cannot or cannot prevent.
USM Provides High-end Technology services from medium to Large scale Industries. Our Services include AI services, Ml Services, etc…
To know more about our services visit USM Systems.
What are your thoughts on the ethics of AI in health care? Let us know in the comments section below!




The Ethics of Artificial Intelligence in Healthcare was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
The usage of recommendation engines has become a critical aspect of developing an online store or business. AI-based recommendation engines are everywhere — Facebook, Amazon, Netflix, Spotify, and the list goes on.
But what is a recommendation engine, and why is it getting so much buzz? Let’s discuss why you should work with an AI development company and implement a recommendation engine in your business.
AI-Based Recommendation Engine Explained
A recommendation engine in the AI environment is a system that suggests content, products, and services to users by collecting and analyzing data. Some common data types a recommendation engine uses are the user’s behavior history, the behavior of similar users, etc.
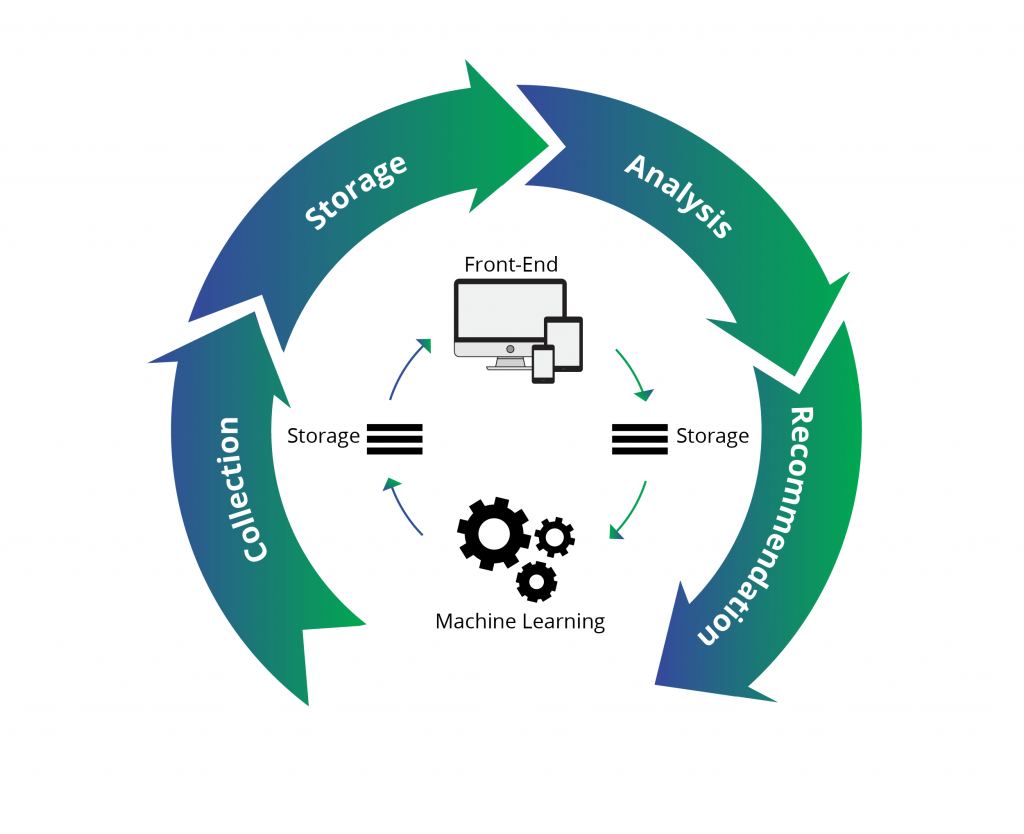
The rise of personalization and relevance in marketing has boosted the rise of AI recommendation engines. Consumers want to look at the world through their lens of interests, behaviors, preferences, and experiences. Since the internet has become a hub of product and information overload, a recommendation engine enables companies to deliver targeted, personalized solutions to their users.
Amazon has been using recommendation systems for years to showcase relevant products to its customers. But in recent years, these systems have expanded to other industries as well.
Take Netflix, for example. It uses AI solution to suggest movies and TV shows based on the user’s preferences.
Some business benefits of working with an AI development company and implementing a recommendation engine are:
How Does AI-Based Recommendation Engine Boost User Experience?
Using a recommendation engine in your online business can offer various benefits. Here’s why you should work with an AI solution provider and implement an AI-based recommendation engine.
2. Generating neural speech synthesis voice acting using xVASynth
Enable Personalized Interactions
80% of consumers would prefer purchasing from a brand that provides personalized experiences, showed an Epsilon research report. In this age of information overload, adding an element of personalization to your offering can go a long way in engaging your customers. A recommendation engine helps you deliver personalized customer experiences.
Provide a Consistent Experience Across All Channels
Omnichannel marketing has gained a lot of popularity in recent years. 35% of customers expect to obtain customer service on multiple channels, according to Zendesk. However, providing omnichannel experiences comes with a major hurdle — lack of consistency.
Brands need to be consistent across all channels, including social media, website, mobile app, etc. An AI-based recommendation engine ensures that users get a similar experience across all channels. For example, if a customer searches for a product on your website, the recommendation engine collects and utilizes that data to send personalized emails with relevant product suggestions.
Deliver Relevant Content
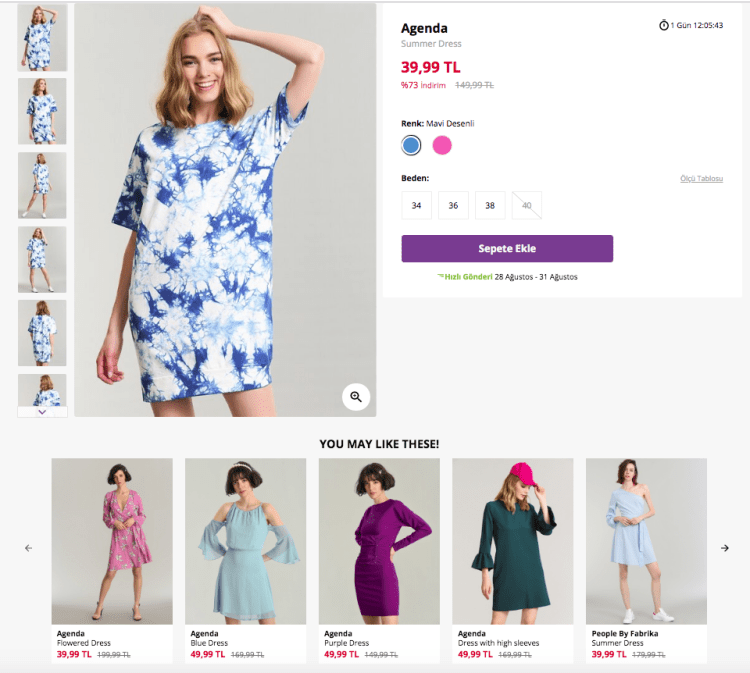
Providing relevant and helpful content can go a long way in creating brand awareness and increasing customer trust. Recommendation engines enable you to show customized and relevant content to your consumers.
Let’s take Medium, for example. The online publishing platform displays content based on your preferences and history. You can select the topics you’re interested in, and based on your reading behavior, it creates customized content lists for you.
Avoid Customer Frustration
According to Oracle, the average human attention span has plunged to eight seconds. Hence, the battle for customer attention has become more fierce. Showcasing irrelevant content or product recommendations to your customers will turn them off and create a terrible customer experience.
An AI-enabled recommendation engine filters and shows the items guaranteed to generate customer interest and engagement. This results in increased relevance, better experience, and more sales and revenue.
Meet Customer Experience Expectations
Marketing has drastically changed over the past decade or so. And when you introspect these changes, you’ll find that customer expectations have constantly been increasing.
They now expect superior, personalized experiences. In fact, 96% of customers consider customer service and experience as a key determinant of brand loyalty, showed a report by Microsoft.
A product recommendation engine helps you anticipate and fulfill customer requirements, thereby enabling you to meet customer experience expectations.
Increase Sales, Average Order Value, and Revenue
In the end, it’s all about the bottom line. When you show relevant product recommendations, customers are more likely to purchase. Besides, an AI recommendation engine can ignite your up-selling and cross-selling efforts.
Doing so can make the buying journey shorter for the customer and thus increase sales and average order value. Therefore, working with an AI solutions provider and implementing a recommendation engine can help boost your revenue.
Conclusion
It goes without saying that recommendation engines play a vital role in this digital era. Customers want to see what matters to them, and brands need to adapt. An AI-based recommendation engine enables you to identify, anticipate, and fulfill customers’ expectations, hence providing them with a superior experience. Besides, it won’t affect the infrastructure of your existing app. It is easy to integrate and is available as a plug-and-play solution.
Do you want to implement an AI recommendation engine in your business? Get in touch with Quytech, an AI solution development company today.
How AI-Based Recommendation Engine Helps Transform User Experience? was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
In the last four months, I have been working on understanding the intersection of the learning process in the human brain and that shown…
Continue reading on Becoming Human: Artificial Intelligence Magazine »
Originally from KDnuggets https://ift.tt/2Lh7ZKG
Originally from KDnuggets https://ift.tt/3toD5Bn
Originally from KDnuggets https://ift.tt/36Db6Er

There’s so much hype about data and data related jobs. With the amount of learning material available online and the variety and depth of topics in data science and data engineering, it’s easy for a newcomer to get confused about what exactly to learn and how to go about getting a job in a data related field. Because learning data related skills like machine learning and getting a job in a related field are very different things, I decided to take a look at Kaggle’s 2020 data science survey. Kaggle is an online platform that hosts data science competitions, discussions , datasets and kernels. The platform has over a million users from all over the world. The survey was live for 3.5 weeks and had questions about almost everything related to data science from demographics of the practitioners to daily activities of data professionals.
I’m sure that most people trying to break into data related fields have these questions . So without further ado, I’ll list the questions I’m going to explore here
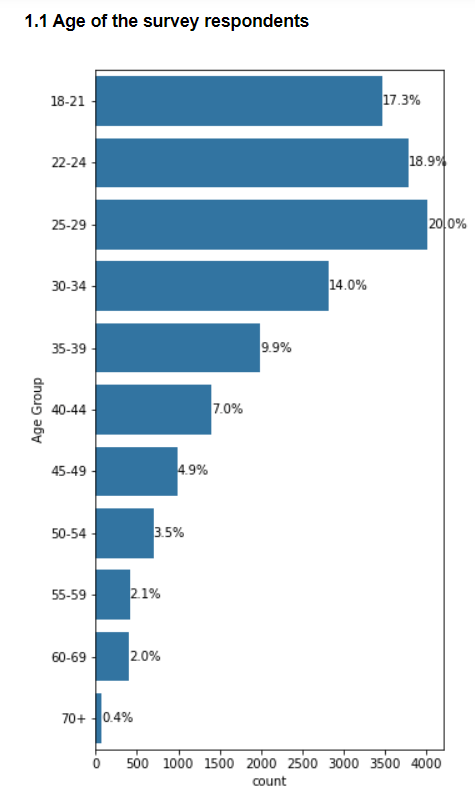
1.1 Age
Here 69% of the respondents are below 35 years of age and 55% are below 30 years of age. This is inline with the fact that most data professions came into the spotlight very recently
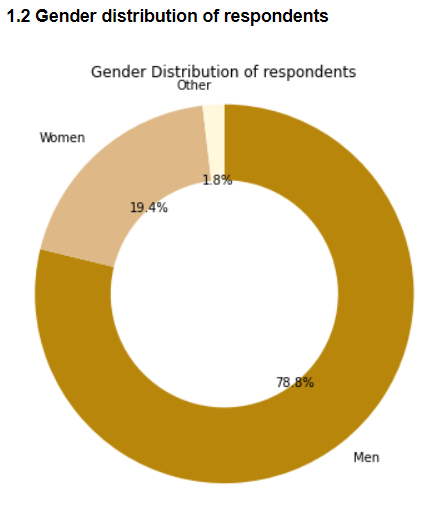
1.2 Gender Distribution
Roughly 78% of the respondents were men, 19.4% were women and 1.8% were other genders, This is a trend commonly seen in other technical fields as well
1.3 Country of Residence
Most of the participants were from India and U.S. followed by Brazil, Japan and U.K.

For the purpose of this analysis, I’ll consider anyone who has described their work in some form in the survey. There were a few people who seem to be employed, but did not describe their role. So I have omitted these people. The question to describe one’s job had the following options
After applying the above criteria, there were roughly 9142 data professionals among 20,000 respondents
2. Generating neural speech synthesis voice acting using xVASynth
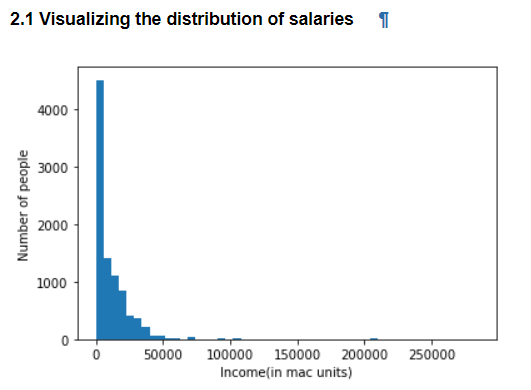
2.1 Salary Distribution
For comparing salaries across different countries, I have converted salaries in USDto purchasing power parity using the Big Mac index since the value of a given amount of money, say $100 varies in different regions across the world. Henceforth, salary will be in number of mac units. Salary distribution for the entire sample is shown below. As expected, it is a right skewed distribution with a long tail. Majority of the people earn less than 50,000 units while there are extremely high earning individuals, earning as high as >300,000 units
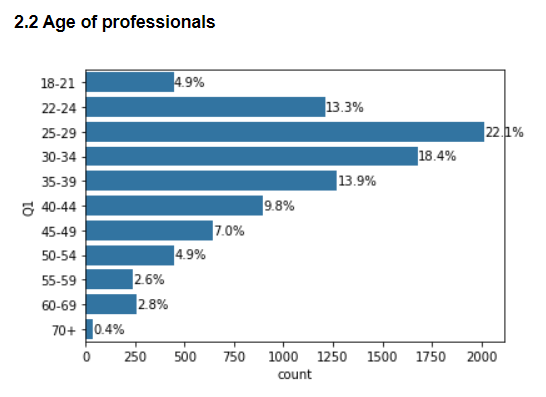
2.2 Age of professionals
Most professionals fall in the 25–29 years age group with 30–34 years and 22–24 years being the next highest groups. Overall more than half of the professionals are aged between 22 and 34 years
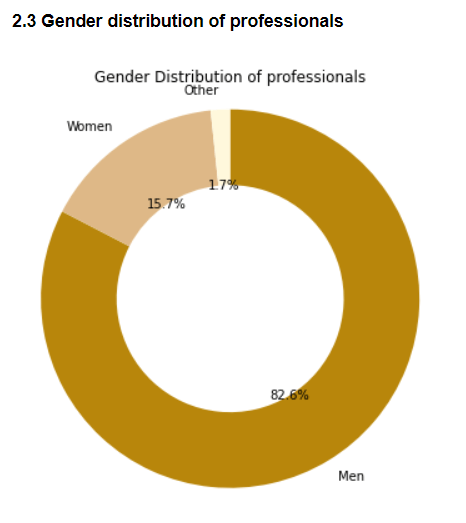
2.3 Gender Distribution of professionals
Similar to the trend observed with the survey respondents, roughly 83% of the professionals are men,16% women and remaining 1% are other genders
2.4 Pay variation with country
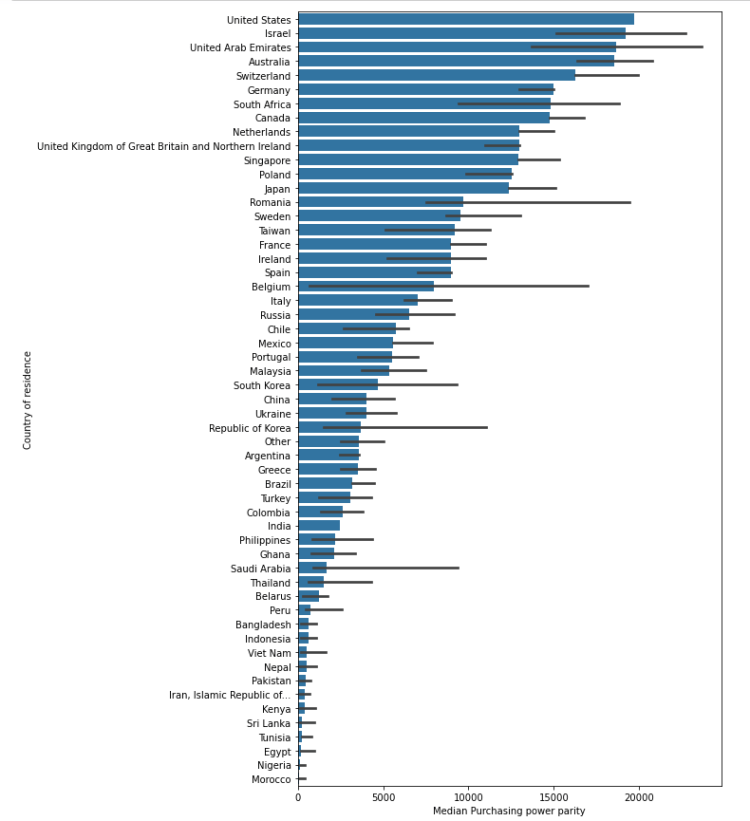
Here I plot the median salaries of each country to find out the where the median salaries for data professionals is the highest. Turns out US, Israel, UAE, Australia and Switzerland are top 5 countries with highest median salaries in the world. PPP here is calculated based on the big mac index which is a widely used number for assessing PPP. All aspects of cost of living may not be represented well by the index, but it gives a good rough estimate of the highest paying places in the world
2.5 Level of formal education
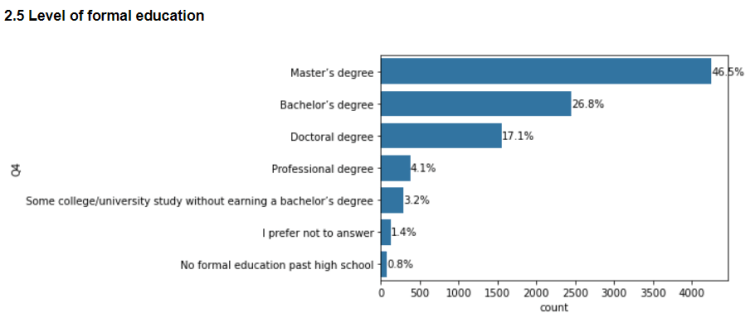
Often newcomers in data related fields wonder how much formal education does one need to break into the field. From the data here, it can be seen that around 46% professionals have master’s degrees, 27% having bachelor’s degrees and 17% having a doctorate. Thus having higher education certainly seems to have a significant impact on one’s career prospects in a data related field
2.6 Distribution of job roles
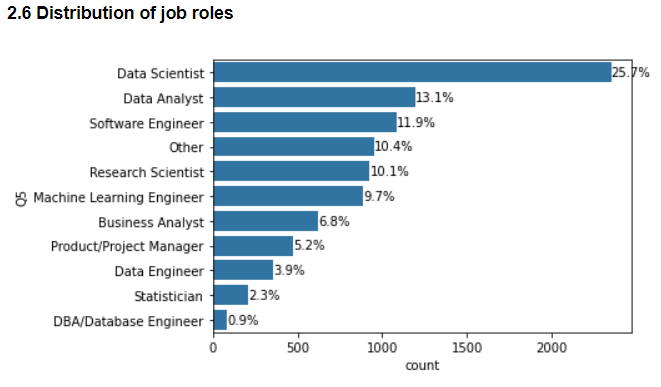
Data scientists make up the largest proportion of professionals who work with data, followed by data analysts and software engineers.
2.7 Age and pay
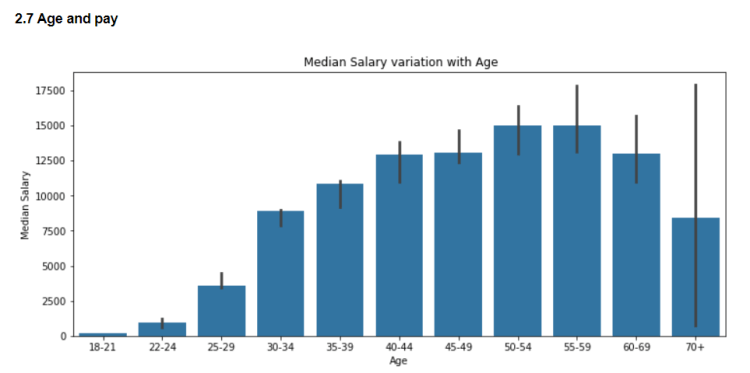
Here I have plotted the median salaries of different age groups. In general it seems that pay increases with age and experience. It’s also interesting to note that pay variation is higher in higher age groups
2.8 Responsibilities by job title
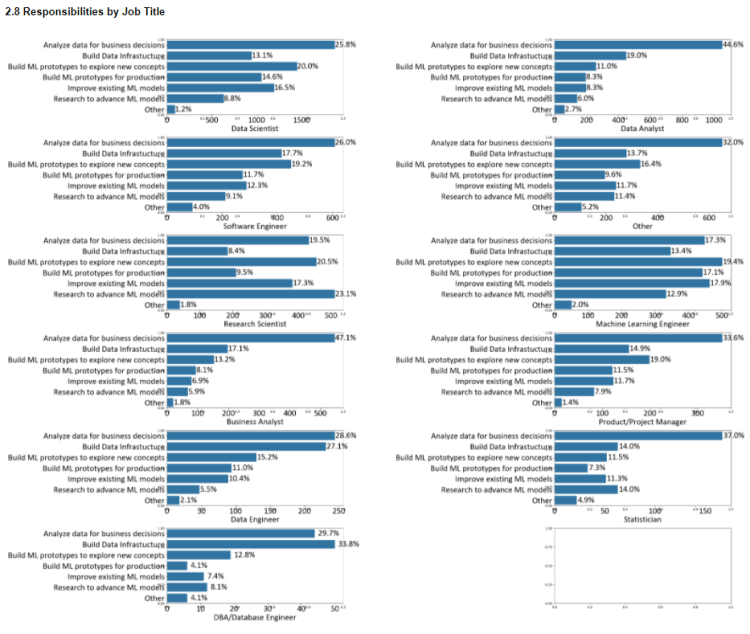
2.9 Job title and education
Here I take a look at education of people across different job titles. Masters degree holders form the largest proportion of people across all job titles except for research scientists where majority of the people hold PhDs

2.10 Count of professionals across companies of different sizes
Here I take a look at the headcount of different job roles across companies of different sizes. It seems like large number of data scientists work in startups and big corporations .Also data scientists form the major proportion of data professionals followed by Data Analysts and software engineers
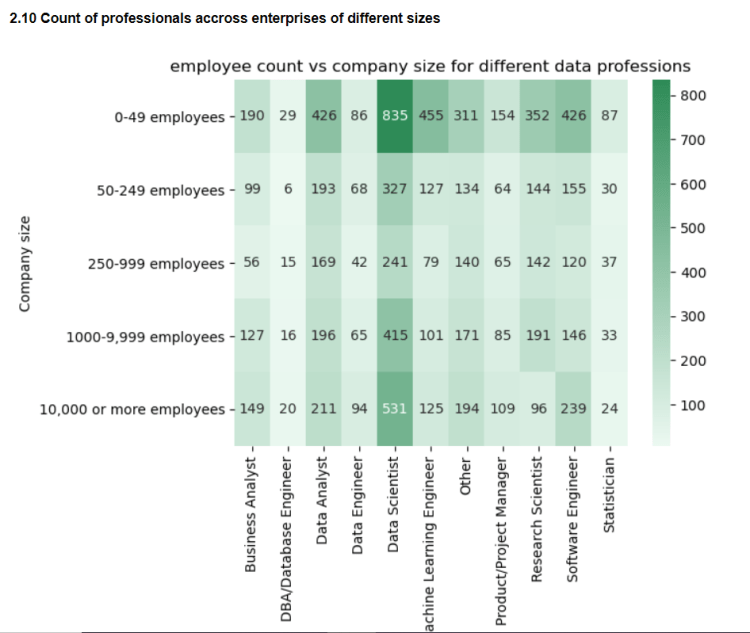
2.11 Pay variation across companies of different sizes
Here I compare median salaries of professionals across organizations of different sizes. In general bigger companies tend to pay more than smaller ones. Also product/project managers seem to be the highest paid positions across organizations of different sizes
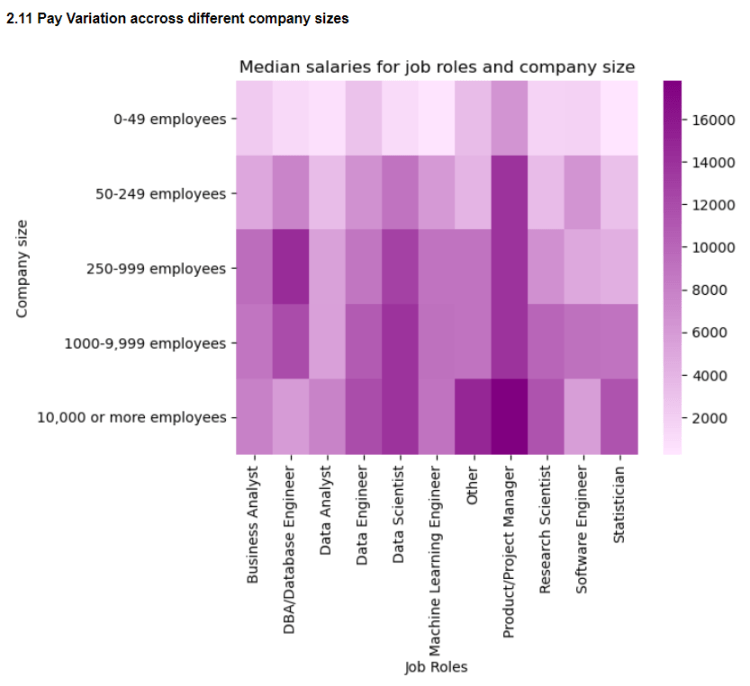
2.12 Extent of ML adoption in companies of different sizes
The extent of machine learning usage is compared across companies of different sizes. It can be seen that big corporations are the ones with well established ML procedures while smaller companies are still at an exploratory stages
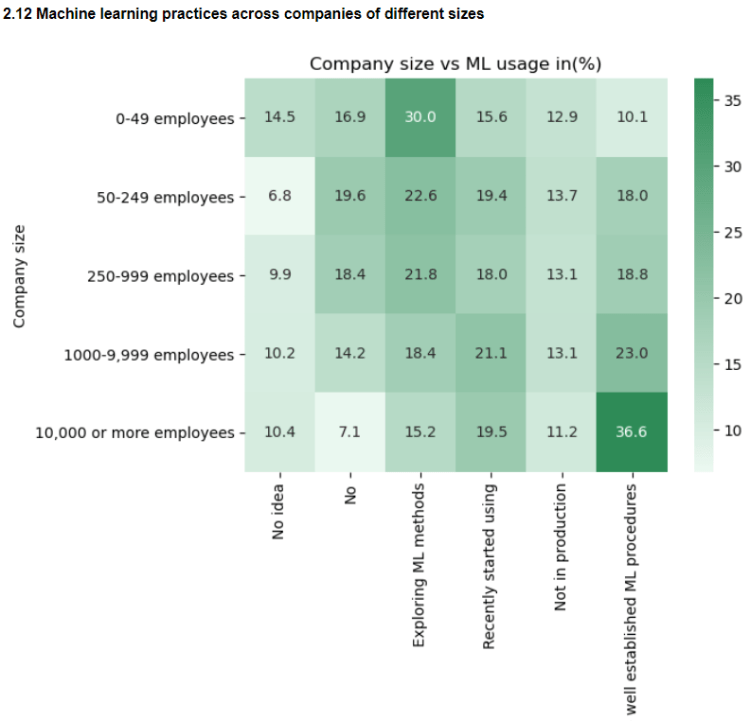
2.13 Preferred development environments
Jupyter notebook/ jupyter lab is by far the most preferred tool for building data science workflows followed by Vscode and Pycharm

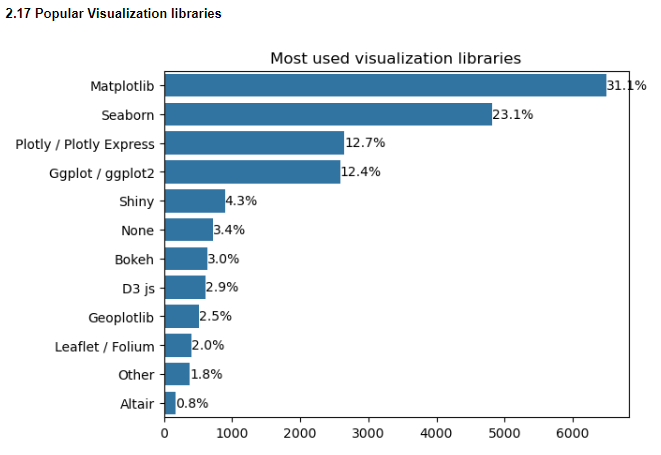
2.14 Popular hosted notebooks
Google colab and Kaggle notebooks seem to be the most popular hosted notebooks. It’s surprising that almost 19% people don’t use any of the hosted notebook services given the amount of compute power available for free
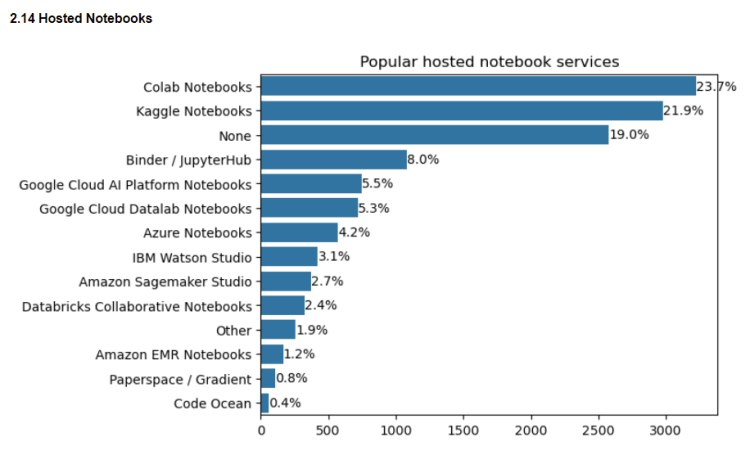
2.15 Coding experience needed for different professions
It’s an interesting question to ask how much coding experience is required to get into these fields. It can be seen that around 30% of professionals across different job titles have less than 2 years of coding experience.
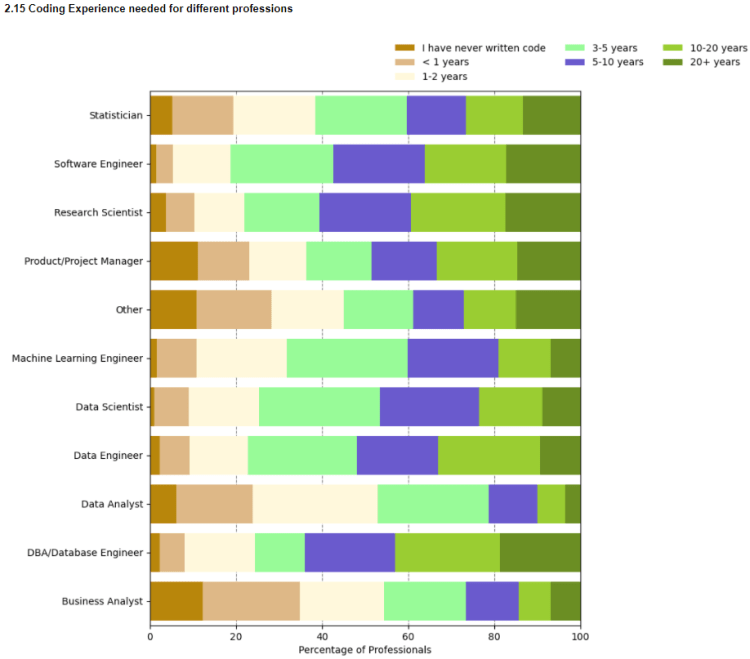
2.16 Programming Languages to learn
Python is by far the most used language in data related jobs while SQL comes in at second. This is not surprising since SQL plays a major role in accessing data from large data warehouses. Thus knowing SQL goes a long way in boosting career prospects of data professionals
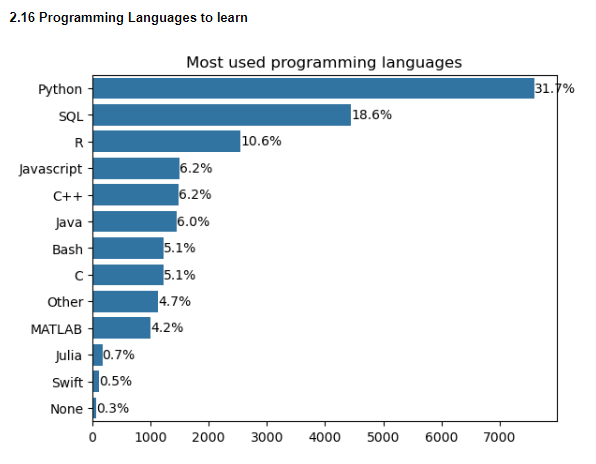
2.17 Popular Visualization libraries
Matplotlib and Seaborn are the most used data visualization libraries since most people start out with these. Plotly produces interactive plots, but requires knowledge of data preprocessing to get certain types of visualizations. ggplot is a visualization library for R
2.18 Years of Machine Learning experience across different professions
About 40% of the people in all professions have machine learning experience of less than 2 years. Professionals like data and business analysts mostly do not have machine learning experience. Also 2 years of coding experience is subjective and can mean different things for different individuals depending on where they studied and number of hours they put in. But 2 years of ML experience is a reasonable goal for people trying to get into the field to strive towards
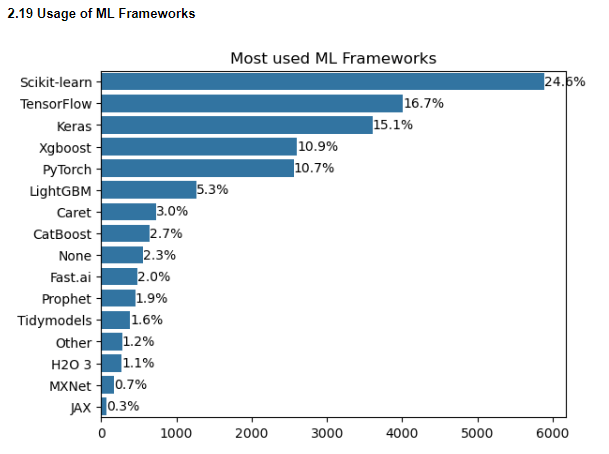
2.19 Usage of ML Frameworks
Scikit learn, Tensorflow and Keras are the most popular ML Frameworks which is mostly what people learn while trying to get into this domain
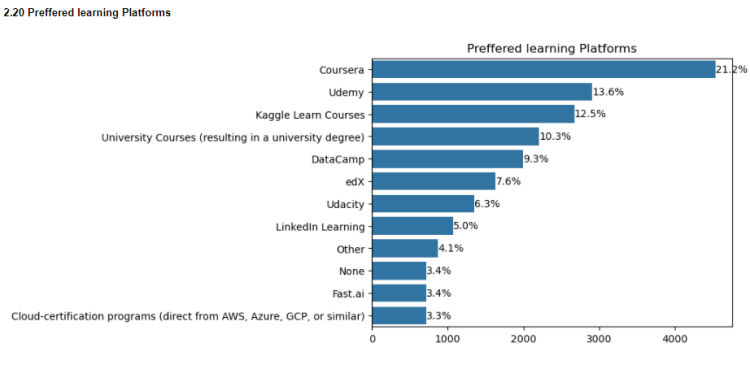
2.20 Preferred learning Platforms
Coursera seems to be the top platform for learning data science followed by Udemy and Kaggle.
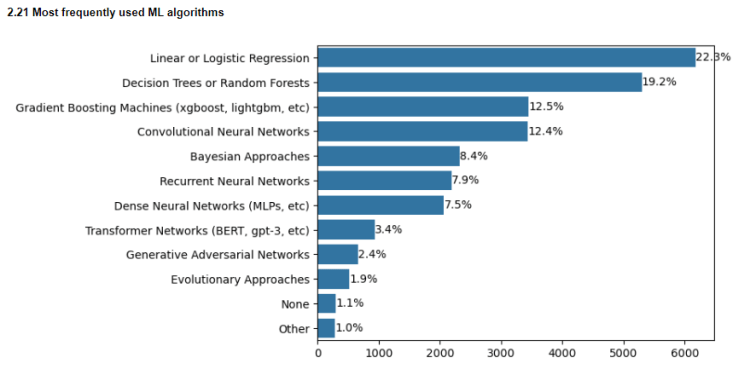
2.21 Most used ML algorithms
Despite the large number of sophisticated ML algorithms, linear/logistic regression and tree based methods remain the top algorithms used for business purposes. This is because the results of these algorithms can be easily explained while more sophisticated deep learning methods may not be interpreted so readily. This also shows the importance of model interpretability for use in business cases
That was a lot of information. But to summarize the major points of this analysis
1. Country of residence plays a big part in determining salaries of data professionals
2. Most professionals across job titles have a bachelor’s or a master’s degree
3. Data scientists form the biggest portion of people working with data
4. Pay increases with experience and company size
5. Python and SQL are go to languages to learn for any data related role
6. A good portion of people working in this feild have less than 2 years of experience with coding and ML and is a reasonable goal for newcomers to strive towards
7. Businesses value deriving insights from data and simple ML algorithms over complex ones
If you are interested in the code for creating the visualizations, check out my Github repository here.
Thank you for reading.
Becoming a Data Professional In 2021 was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
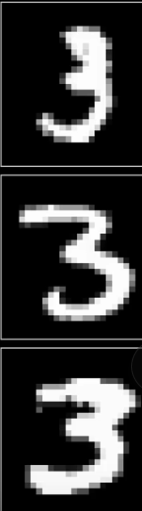
Let’s start with a simple image of digit 3. The digit 3 may be written at various angles or directions, even at an extremely low resolution of 28 by 28 pixels, our brain has no trouble recognizing it as a three. Isn’t it intriguing that human brains can do this so effortlessly?
In all the three images above, even though the pixel value of each image is different from another, it is very easy to recognize each one. The light-sensitive cells, i.e. the rods and the cone cells, present in our eyes that light up when we see the images above are distinct from one another. But, if I told you to write a program that takes in a grid of 28 by 28 pixels like the one above, processes the image and finds out which digit it is, and gives us a number between 0 and 10, then it would be a dauntingly difficult task.
Machines are inherently dumb (as of now, at least), so, to make them smarter we induce some sort of intelligence so that they are capable of making a decision independently. This intelligence is explicitly programmed, say, with a list of if-else conditions. But what if we need to introduce intelligence into a machine without explicitly programming everything into it? Something that enables the machine to learn on its own? That’s where Machine Learning comes into play.
“ Machine learning can be defined as the process of inducing intelligence into a system or machine without explicit programming.”
– Andrew Ng, Stanford Professor.
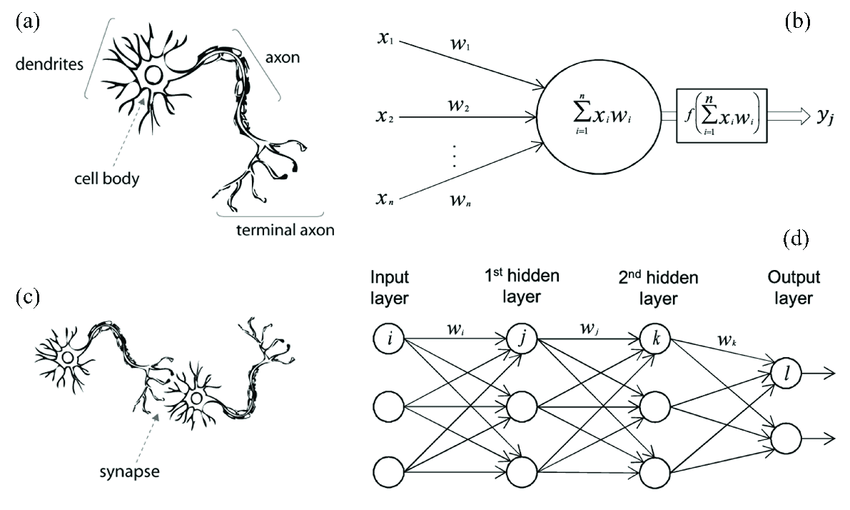
The human body is the most intelligently engineered creation of the Almighty, and on it rests the most complex structure in the world, “Our Brain”. The powerhouse of our brain is the swift neurons. They are the ones running the whole system, from sensing any situation to producing the appropriate response to it. According to the MIT Technology Review, human reaction time shows that the brain processes data no faster than 60 bits per second which are about 30 times faster than the best supercomputers. The human body has, time and again, inspired innovations and new technologies, one of which has been the most revolutionary, the Neural Networks. The idea behind neural networks is inspired by neurons that are the building blocks of our brain.
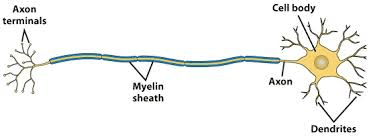
The dendrites in the neuron receive signals via, either the sensors or, from other neurons that act as input to the processor(brain). Now, via a series of action potentials in the neuron itself, the signal passes through the whole neuron(Axon) and then reaches the end, which happens to be, the terminals of the Axon where with the help of a neurotransmitter the signal is balanced and passed onto the other neurons for further processing.
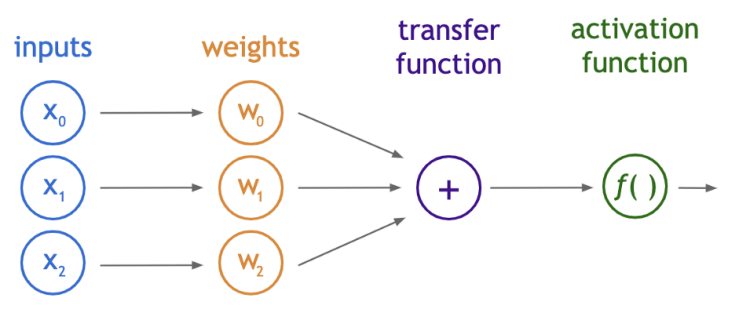
Now, to explain the perceptron which is the functional unit of an artificial neural network; just as the biological neuron is to the biological neural network, we will take a daily life example that most of us happen to come across while in a market. So, how do we figure out if an apple is ripe or not?
Color, firmness, smell, luster are the features that we consider and then we come to a decision. Now, here come our brain and its neurons which help us make the decision on the basis of the inputs received via sensors like the nose, eyes, etc. Now, let’s explore the same process but for a perceptron.

The inputs mentioned in the above paragraph are the features provided, i.e. color, firmness, smell, luster. For example that can be represented in the form of an array as follows: [Light red, good, Lemony, shiny]
Now, these are categorical attributes, later for processing, we will need to convert these into numerical values as in a perceptron the predictions are made via some scalar multiplications and additions.
Next are the weights which are multiplied to the inputs to show or state the importance of each feature of the fruit. For example, the fruit color here is more important than other features. So, it will be given more weight value. In both artificial and biological neural networks, a neuron does not just give out the value it receives from the transfer function. Instead, the activation function which is analogous to the rate of action potential firing in the brain takes the transfer function output and then transforms it once more before finally giving it as an output. The bias neuron is a special neuron added to each layer in the neural network, which simply stores the value of 1. Without a bias neuron, each neuron takes the input and multiplies it by the weight, with nothing else added to the equation. For example, it is not possible to input a value of 0 and output 2. In many cases, it is necessary to move the entire activation function to the left or right of the graph to generate the required output value which is made possible by the bias. Now the transfer function will combine all the outputs from the above-said scalar multiplications to generate a sum which we can say is the single value representing the quality of one apple. The transfer function can be written as:
z1 = w1*x1 + w2*x2 + b1
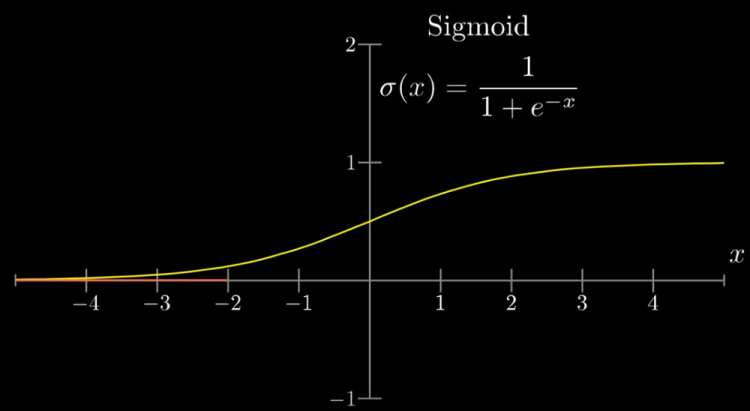
The sigmoid function is the oldest and most popular activation function. It is defined as follows:
σ(z1)=1/(1+e^-z1)
The reason is that the weighted sum is linear with respect to its inputs, i.e. it has a flat dependence on each of the inputs. In contrast, non-linear activation functions greatly expand our capacity to model curved functions and other complex patterns from our given data which are simply not possible with the linear functions. When comparing with the biological neural network that is in our brains, the activation function is at the end deciding what is to be fired to the next neuron.
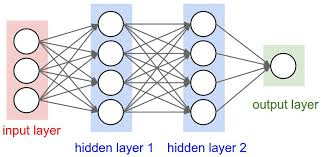
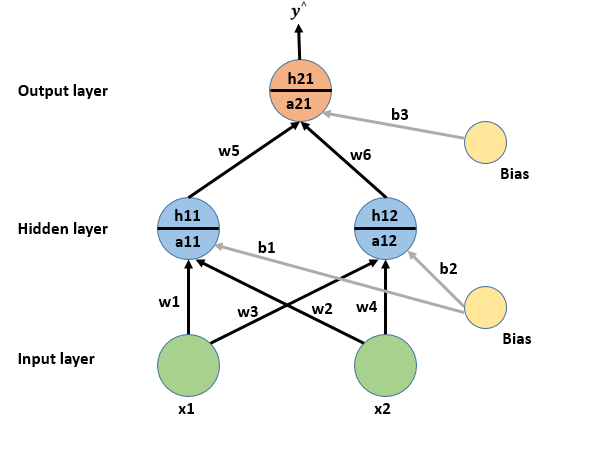
A simplified version of Deep Neural Network is represented as a hierarchical (layered) organization of neurons with connections to other neurons between any two layers. These neurons pass a message or signal to other neurons based on the received input from the previous neuron layer and form a complex network that learns with a feedback mechanism. The above-given figure represents an ’N’ layered Deep Neural Network.
Let’s take the example of recognizing digits which we were talking about earlier, when I say neuron it specifically holds a number between 0 & 1 and not more than that. For example, the network starts with a bunch of neurons corresponding to each of the 28 x 28 pixels of the input image which is 784 neurons stacked on one another for the first layer which is the input and in total each one of these holds a number that represents the grayscale(having only one channel of color) value of the corresponding pixel ranging from 0 for black pixels up to 1 for white pixels. But before jumping into any further math for how one layer influences the next layer, let’s first figure out why it’s even necessary to have a layered structure to give intelligent results similar to our brain?
In this network, we have two hidden layers each one with any number of neurons and which is kind of arbitrary for now. The activations from one layer bring about activations in the next layer which is quite analogous to how in biological neural networks of neurons some groups of neurons firing cause others to fire. Finally, after all the activations brightest neuron of that output layer is the answer to what the digit in the given image represents.
2. Generating neural speech synthesis voice acting using xVASynth
When we break down to the simplest parts of the image, it will be the edges that make up the digits, so we can say that the second layer of the neural network picks up the various edges of the digits being fed into the input or the first layer and this way the next layer neurons identify more complex patterns like loops and lines from the previous layers, thereby finally lighting up the appropriate neuron for a given digit in the output layer.
Now let us get into the details of the whole process of passing one message or signal from the neuron in one layer to that of another:
The neurons in the second layer pick up the edges from the input images as already mentioned above. We are going to assign a weight to each one of the connections between neurons from the first layer and the neurons from the first layer. As already said in the perceptron model above, the weights are just numbers that are multiplied with the numerical values in each neuron from the first layer, and their weighted sum is computed. Now the weighted sum that is computed, we want it to be some value between 0 & 1, so the thing we want to do is to input this weighted sum into some function that squishes the real number line into the range between 0 & 1 and there comes the job of an activation function, here we are taking the popular function that does this is called the sigmoid function also known as a logistic curve where very negative inputs end up close to zero, very positive inputs end up close to 1 and just steadily increases around the input 0. So the activation of the neuron here is a measure of how positive the weighted sum is. Sometimes maybe we don’t want the neuron to light up when the weighted sum is bigger than 0 and want it to be active when the sum is bigger than say 10 and that is where we want some bias for it to be inactive before plugging it through the sigmoid squishification function. So basically the weights tell us what pixel pattern this neuron in the second layer is picking up on and the bias tells us how high the weighted sum needs to be for the neuron to be active. And that is just one neuron. Every other neuron in the next layer is going to be connected to all input pixel neurons from the first layer and each one of those input neuron connections has its weight associated with it also each one has some bias some other number that you add to the weighted sum before squishing it with the sigmoid. This network has many such weights and biases that can be tweaked and turned to make this network behave in different ways. The weights and biases are initialized randomly.
What we discussed above was all about the parameters involved in making the network learn, but now we are going to dive into the actual process of learning:
Forward propagation is the process in which the input data is fed in the forward direction through the network. Each hidden layer then accepts the input data, processes it as per the activation function, and passes it to the next layer. But in order to generate some output, the input data should be fed in the forward direction only. The data should not flow in the reverse direction during output generation otherwise it would form a cycle and the output will never be generated. And such network configurations are known as feed-forward neural networks which help in forward propagation.
So first we calculate the weighted sum of inputs(pre-activation) and then pass it through the activation function (activation) to give it a real value which fires the neurons in the next layers according to the bias added.
For example at the first node of the hidden layer, z1(pre-activation) is calculated first and then a1(activation) is calculated.
z1 is a weighted sum of inputs. Here, the weights are randomly generated.
z1 = w1*x1 + w2*x2 + b1 and a1 is the value of activation function applied on z1(a1 = σ(1/(1+e^-z1) )
Similarly, z2 = w3*x1 + w4*x2 + b2 and a2 is the value of activation function applied on z2(a2 = σ(1/(1+e^-z2)).
For any layer after the first hidden layer, the input of the next layer is the output from the previous layer.
z3 = w5*x1 + w6*x2 + b3 and a3 is the value of activation function applied on z3(a3 = σ(1/(1+e^-z3)).
Now, due to the random initialization of the weights and biases of this network what we do is define a cost function as a way of telling the computer: “Bad choice!”, that output should have activations that are zero for most neurons, but one for the neuron we are trying to predict.
Mathematically what we do is add up the squares of the differences between each of those wrong output activations and the value that we want them to have and this is called the cost of a single training example.

We notice that this sum is small when the network confidently classifies the image correctly but it’s large when the network seems like it doesn’t know what it’s doing. So then we consider the average cost over all of the training examples. This average cost is now our measure of how bad or good the network is and how much more training and learning it needs.
The cost function here takes into consideration the network’s behavior overall training data examples. Now, tell me if you were a teacher, then does only showing a student their bad performance is enough or you should also guide the student for improving their performance by changing his studying or learning tactics? The second one also right? Similarly, we also need to tell our network about how it should change its weights and biases to get better at predicting the correct outputs.

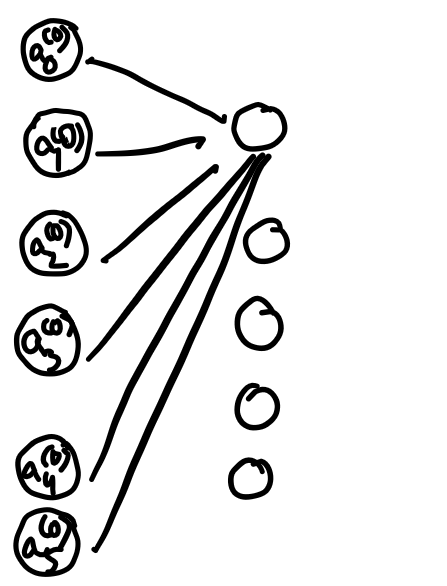
By the way, the actual function here is a little cumbersome to write down. What if we can arrange it in a more compact and neat way, well below its given how:

We organize all of the activations from one layer into a column as a vector and then organize all of the weights as a matrix where each row of that matrix (vectorization) corresponds to the connections between one layer and a particular neuron in the next layer. This means that taking the weighted sum of the activations in the first layer according to these weights corresponds to one of the terms in the matrix-vector product.
We also organize all the biases into a vector and add the entire vector to the previous matrix-vector product and then rap a sigmoid around the outside of the final product. And this now represents that the sigmoid function is applied to each specific component of the resulting vector inside the sigmoid function. So now we have a neat little expression to show the and full transition of activations from one layer to the next.
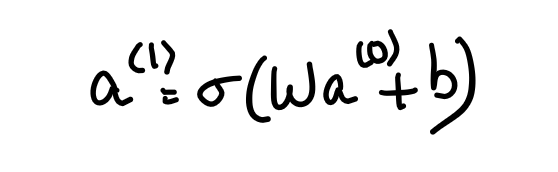
This makes the code a lot simpler and a lot faster since many libraries optimize the matrix multiplications.
We know that the gradient of a function gives us the direction of steepest ascent, where the positive gradient which direction should you step to increase the function most quickly and taking the negative of that gradient gives you the direction to step that decreases the function most quickly and the length of this gradient vector is an indication for just how steep that slope is. This vector tells us what the downhill direction is or the minimum is and how steep it is. Now computing this gradient direction and then taking a small step downhill and repeating this over and over gives us a minimum value for the cost function we were talking earlier about. The negative gradient of the cost function is just a vector or direction that tells us which nudges to all of those weights and biases is going to cause the most rapid decrease to the cost function and now when the slope is flattening out towards the minimum our steps get smaller and smaller and that kind of helps you from overshooting.
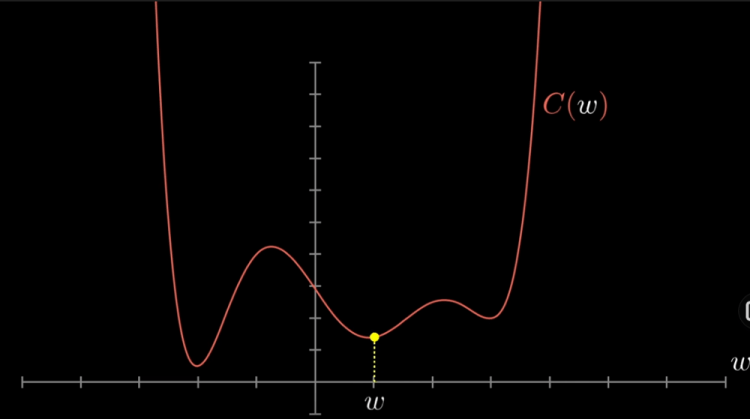
This graph shows the various slopes and the paths the cost function will need to travel in order to minimize itself
Here changing the weights and biases to decrease the cost function means making the output of the network on each piece of training data look less like a random array of ten values and more like an actual decision that we want our network to make.
Again remember that this cost function involves an average over all of the training data. So minimizing it means it’s better performance on all of those data as a whole. The algorithm for computing this gradient efficiently is called backpropagation and this process of repeatedly nudging the weights and biases by some multiple of the negative gradient is called gradient descent.
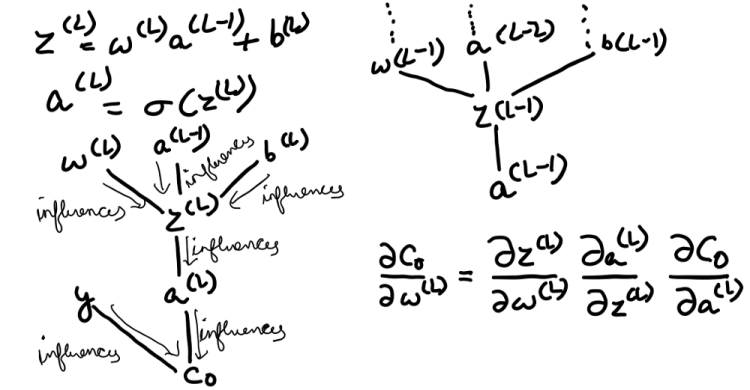
The weight, the previous activation, and the bias altogether are used to compute z, which in turn computes an after passing the z through an activation function, and finally, along with the actual output y, we compute the cost. Now we need to determine how sensitive the cost function is too small changes in our weight w^(L)or what’s the derivative of C with respect to w^(L). The “∂w” term means some tiny nudge to w and the “∂C” term refers to whatever the resulting nudge to the cost is. A slight change to w^(L) causes some change to z^(L) which in turn causes some change to a^(L), which directly influences the cost. So we divide this up by first looking at the ratio of a change to z^(L) to the change in w^(L) which is the derivative of z^(L) with respect to w^(L). Similarly, we then consider the ratio of a change to a^(L) to the change in z^(L) that caused it as well as the ratio between the final change to C and this intermediate change to a^(L). And this whole process is the chain rule, where multiplying together these three ratios gives us the sensitivity of C to tiny changes in w^(L). The derivative of C with respect to a^(L) is 2(a^(L) — y). The derivative of a^(L) with respect to z^(L) is just the derivative of the sigmoid function. And the derivative of z^(L) with respect to w^(L) comes out just to be a^(L-1). In the case of the last derivative(a^(L-1)), the amount that a small change to this weight influences the last layer depends on how strong the previous neuron is.
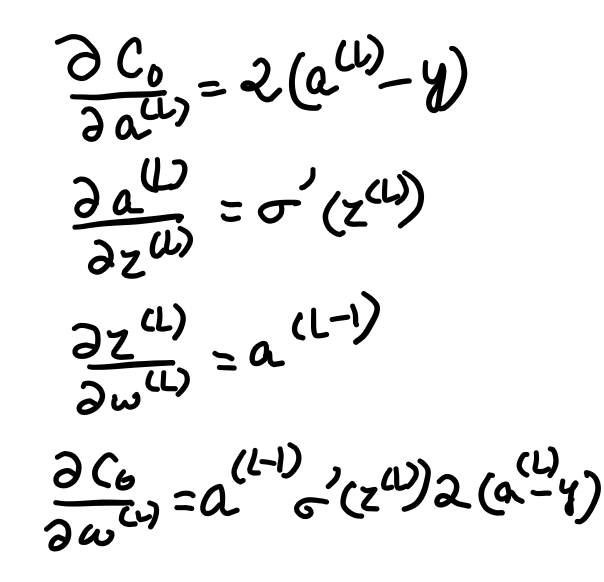
Derivative w.r.t weights
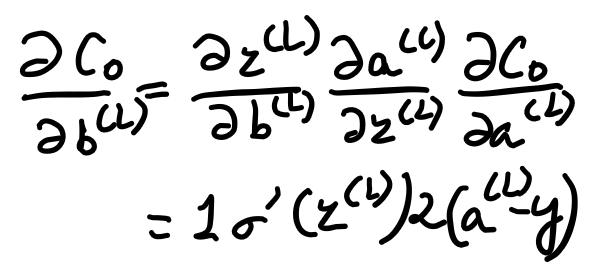
Derivative w.r.t biases
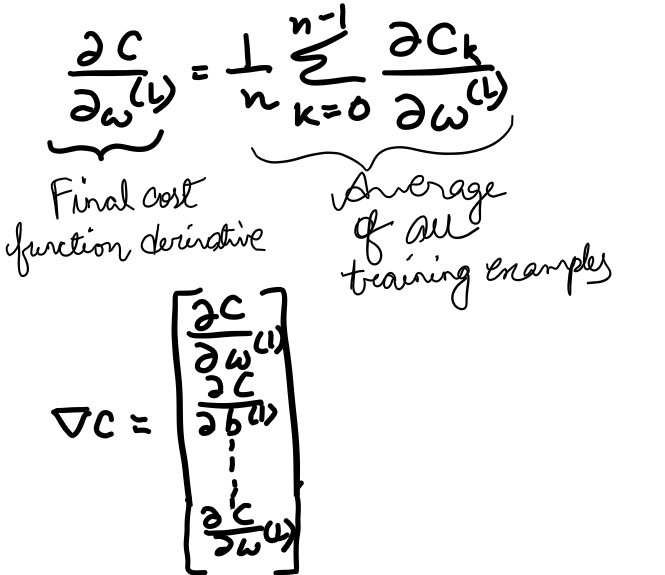
The full cost function involves averaging together all those costs across many training examples, its derivative requires averaging this expression that we found overall training examples. And this is the gradient vector, which itself is built up from the partial derivatives of the cost function with respect to all those weights and biases.
Now we can just keep iterating the chain rule backward to see how sensitive is the cost function is to our previous weights and biases from the previous layers.
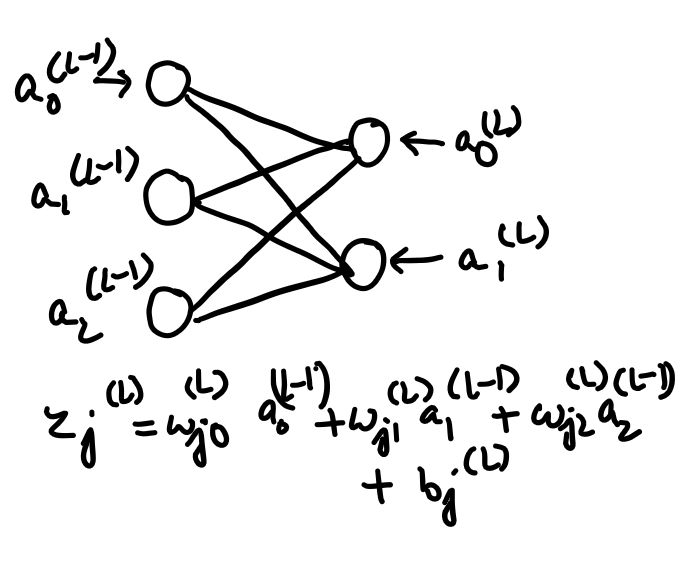
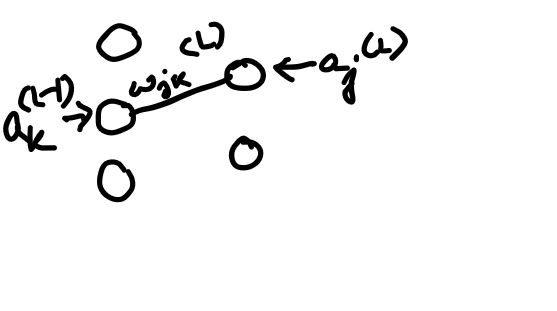
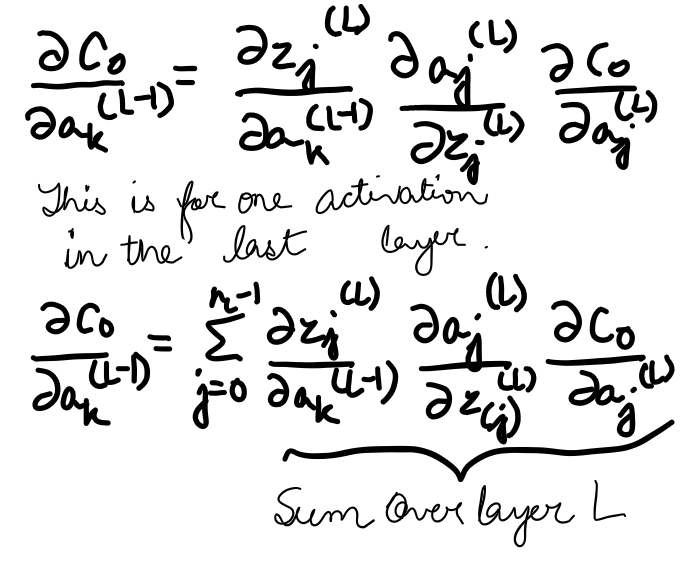
Rather than the activation of a given layer simply being a^(L), it’s also going to have a subscript indicating which neuron of that layer it is. Now let’s use the letter k to index the layer (L-1), and j to index the layer (L). For the cost, we take a sum over (a_j^(L) — y_j)². Let’s call the weight of the edge connecting this k-th neuron to the jth neuron w_{jk}^(L). The activation of the last layer is just your special function, like the sigmoid, applied to z. The chain-rule derivative expression describes how sensitive the cost is to a specific weight. What changes here is the derivative of the cost with respect to one of the activations in the layer (L-1), the neuron influences the cost function through multiple paths, i.e. it influences a_0^(L), which plays a role in the cost function, but it also has an influence on a_1^(L), which also plays a role in the cost function and we add those up. Now once we know how sensitive the cost function is to the activations in this second to the last layer, we can just repeat the process for all the weights and biases feeding into that layer. And finally, after a considerable number of training steps(or epochs), we will have the desired accuracy in recognizing the digits or predicting a good apple.
Well as humans we are familiar and comfortable with all types of data which may be in the form of tables(structured) or images, speech, etc.(unstructured). But it has been much harder for computers to make sense of unstructured data as compared to structured data. And so this is one of the important reasons for the rise of neural networks which made the computers much better at interpreting unstructured data as well compared to just a few years ago. And this creates opportunities for many new applications that use speech recognition, image recognition, natural language processing on text, etc.
Another reason lies in the fact nowadays data is generated in bulk which has eventually led to the Big Data era. So now our traditional machine learning algorithms have failed to show any further improvement with much larger amounts of data. So there come the neural networks to the rescue as it has the capability to learn from its own, unlike the traditional Machine learning algorithms which rely totally on the data. We just need a network with a lot of hidden units, a lot of parameters a lot of connections, as well as a considerable amount of data to get better performance in the neural networks.
Written By: Tanisha Banik
Deep Neural Networks: First step towards thinking like Humans was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.

