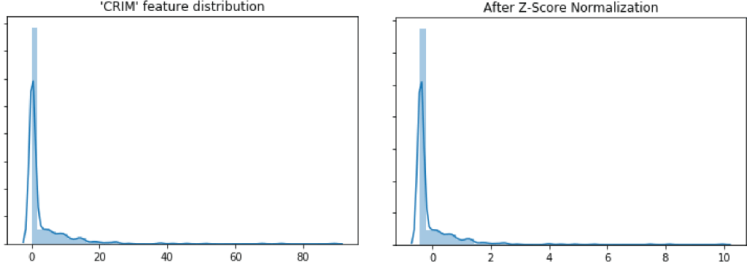
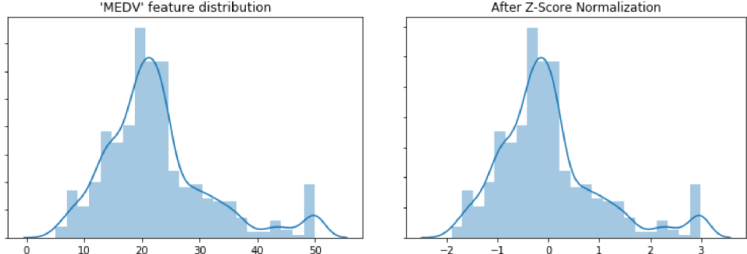
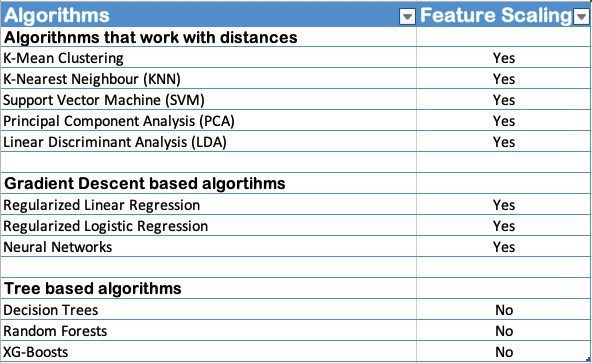
Conversational Artificial Intelligence (AI) has been around for some time now and making a substantial impact on customer acquisition and retention strategies. This subset of AI has influenced business websites, Internet of Things developments, and a whole range of other technologies.

The growth in SaaS tools for marketing has boosted the way businesses market their products and services and conversational AI has taken it one step further. Here is how this technology is transforming MarTech and what the future holds for it.
Voice search algorithms
One of the most commonly used conversational AI algorithms used by individuals on a daily basis in voice search applications. There are just so many of them and it is not like back in the day when Siri was the only voice search assistant.
Nowadays, there is Google Assistant, Alexa, and a couple of others. The use of the Internet of Things (IoT) devices has amplified the need for changes in marketing.

After these applications started being used on a greater scale, marketing teams needed to change their approach. These changes affected mostly search engine optimization teams because they needed to cater to this development. They had to implement different keywords that would lead to higher rankings. Here is how the SEO experts did it and how you can do this:
1. Use long-tail keywords
2. Craft content in a conversational way
3. Implement long-tail keyword tools when researching
These three pointers can help you keep up with the changes conversational AI has brought in the lives of marketers. As devices like Amazon Echo start being more popular and widely used, you should keep up with conversational AI trends caused by this development.
Natural Language Processing in website chatbots
Many websites you use nowadays have been integrated with a chatbot that allows live chat capabilities. This development is another quite common influence conversational AI has on MarTech.
Not all these chatbots are outfitted with the common and widely used AI technology of programmed questions and answers. Instead, it uses deep learning and machine learning to try and understand the context of custom questions.
According to experts on assignment writing services, chatbots mimic the thought process of a real human being and try to gather relevant sources to provide a relevant answer. That is conversational AI manifest at its peak and this integration of Natural Language Processing has started gaining traction. It is a great tool to have in your MarTech box of tools but if you do not have the resources to implement it now, using regular chatbots is still a great alternative.
Trending AI Articles:
As time goes, you can improve and upgrade the chatbot system you’re using to use deep learning and machine learning technologies. However, some chatbot solutions are available in the market currently with these futuristic and advanced features. The only barrier is costing since they are quite expensive for now.

Conversational AI algorithms multi-language approach
Conversational AI can also help marketing teams by using multiple languages at once. How? Automated translation algorithms that can translate text in real-time are must-have in some industries.
Some businesses might be servicing customers from around the globe. To answer their questions or create content specifically for them, you should speak with them using their language.
Science and tech assignment writers on essay writing reviews mention that having multiple languages conversational AI tools can help marketing teams widen their reach and understand the content relevant to each buyer persona they have created. An international reach might be everything you have wanted but were limited by the language barrier.
Perhaps you considered hiring translators for each country is burdensome. To resolve that issue and lower the barrier of tapping into international markets, conversational AI algorithm developers are continually improving translation solutions.
Judging by the capabilities of Google Translate now, the developers have made great progress and their solutions can be implemented for corporate clients. You can use real-time translation or once-off to translate content or comments from users in different countries.
Currently, even Facebook and Twitter use these algorithms. Therefore if you get a comment in a foreign language, it will be much easier to understand and respond to it.
AI Assistants for personalizing content
Personalized content is a huge and ongoing topic in the marketing industry. Many solutions have been introduced to try and do this. Firstly, buyer personas were introduced to try and bridge this gap.
Later on, AI tools were used to try and process data from the buyer personas to find the best type of content for each one. However, this was not as efficient as expected and a new solution was developed.
The division head at a leading dissertation help says that conversational AI has introduced various personalization tools that understand search queries probed by users. At the same time, these algorithms gather and process all other data, such as historic searches and user behaviors. These fragments of information paint a clear picture of how marketers should curate the conversation with the targeted audience.
Personalizing content has never been this easy because customers can use these convenient AI assistants that understand search queries alongside other pieces of information. Utilizing these solutions can prove very fruitful because you will create content specifically designed for the people you’ll send it to.
AI-Powered chatbots on social media
Social media marketing constitutes a great portion of MarTech. This distribution channel provides widespread reach due to the millions of people who use it daily. You can reach users using various methods.
By posting on your timeline, tagging people they follow or utilizing other methods like promoting certain posts. However, after posting something, users might have questions about that post or one of your product or service offerings.
To ensure that this conversation is instantaneous, you can use AI-powered chatbots similar to the ones used for website pages. These AI-powered solutions can provide an effective solution for managing conversations with customers or the targeted audience. Just like website chatbots do, integrating social chatbots can improve the customer journey.
You can move them quickly to the next phase of the sales cycle you’ve created. At the end of the day, your conversion rate can improve exponentially and increase revenue growth greatly.
These chatbots can also keep a track record of conversations that most bother the targeted audience. As a result, you can be proactive and answer these questions when marketing products or services.
Ad targeting using conversational AI
PPC ad campaign hosting providers such as Google Ads, Taboola, and others can be optimized greatly if you have boosted ad targeting using conversational AI. This subset of Artificial Intelligence can improve the reach of your ads.
At the same time, you can get more interested individuals without spending too much. By refining the target audience filters, you can specifically gain access to interested individuals.
That is contrary to paying for your ads to be seen by people who are not interested or will not make a purchase. This type of ad targeting works similarly to personalizing content. The only difference is that it helps save a lot of funds which could be wasted.
Understanding what type of audience resonates with the content you are creating will be much easier to target them specifically and reduce the costs of acquiring customers.
The end result is an exceptionally great Return on Investment (RoI) because you won’t be spending on individuals that do not benefit the business. It is one of the most important tools to reduce costs in MarTech. Therefore, this also lowers the bar for small companies starting with digital marketing.

How conversational AI boosts customer experience
The collective benefit of conversational AI in MarTech is boosting the customer experience users get. Since this subset of Artificial Intelligence focuses greatly on sparking or understanding conversation, it makes it easier for customers to ask for help whenever needed.
In e-commerce solutions, it is like having a shop attendant whom you can ask anything related to their aisle. By boosting the customer journey, you are placed in a better position to influence purchase decisions.
Additionally, by personalizing content and product offers, conversational AI can contribute to higher conversions. That is because you are tailoring content for each specific individual.
The benefits of conversational AI are multifold and most of them are focused on making the lives of customers easier. By simplifying the customer journey, you stand to increase revenue by getting more conversions.
There are many other benefits that can contribute to sales and business growth. Undoubtedly, conversational AI solutions are a must-have in your MarTech toolbox due to their versatile applications and exponential growth potential.
You can start small and grow as time goes on by moving on to more advanced solutions that are high-grade and have better success results.
The bottom line
MarTech has completely been revolutionized by conversational AI because it has made digital marketing practices much more efficient. At the same time, it improves the Return on Investment for digital marketing. As a result, smaller companies can engage fruitfully and grow their operations using conversational AI.
Credits:
Ashley Simmons is a professional journalist and editor who works for a newspaper in Salt Lake City for four years and as a part-time college paper writer for the best essay writing service known for its high-quality assignment assistance and for essay writing service UK. She covers business and economics, marketing, human resources and digital marketing. Feel free to connect with her on Facebook or follow on Twitter.
Don’t forget to give us your ? !




How Conversational AI is Transforming MarTech was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.