365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
A basic appreciation by anyone who builds machine learning models is that the model is not useful without useful data. This doesn’t change after a model is deployed to production. Effectively monitoring and retraining models with updated data is key to maintaining valuable ML solutions, and can be accomplished with effective approaches to production-level continuous training that is guided by the data.
Common Questions and Answers on A/B testing in Data Science Interviews; Interpretable Machine Learning: The Free eBook; Why machine learning struggles with causality; Deep Learning Recommendation Models: A Deep Dive; and more.
Should we still consider data scientists and data engineers as separate roles? When should a team grow with full-stack data developers? Introducing the Checkers-like data team.
Join technology experts, partners and analysts in the industry for this webinar series to see how SAS Viya can help you make the most of AI, analytics and the cloud for faster decisions and trusted results.
In Hollywood movies, artificial intelligence (A.I) is often portrayed as bad and we often witness a bunch of A.I powered robots that turn against their human creators, just as we have seen in movies such as The Matrix, Terminator, iRobot and more. There are a few exceptions were A.I is portrayed as good in movies such as in Interstellar, Star Wars and Star Trek, just to name a few. This negative portrayal of A.I has led to misconceptions about the main concerns that experts have about it. Long story short: the main concerns about A.I isn’t killer robots with Austrian accents per se, but the concerns are mostly about bugs in A.I systems, job losses due to automation, A.I weapons, enforcing the laws concerning A.I systems and superintelligence(although that’s in the remote future).
Big Data Jobs
A Quick Primer on Superintelligence, The Singularity and Artificial General Intelligence
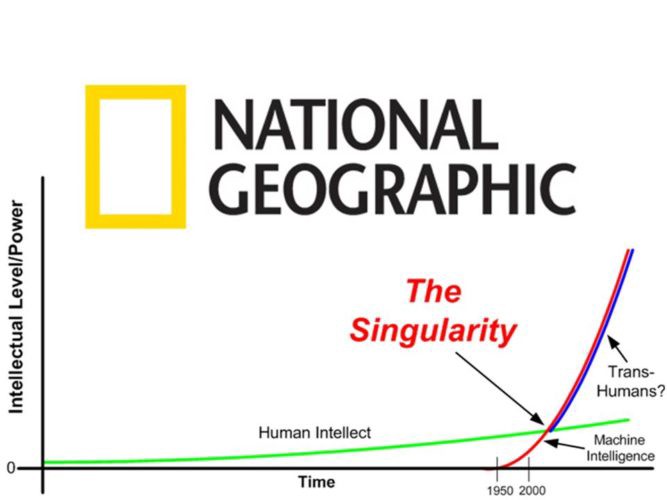
A superintelligence, in terms of machines, would be a machine that surpasses humans in overall intelligence or in some measure of intelligence. An artificial superintelligence (ASI) could be say a 100 times, 1000 times or even a million times smarter than the smartest human in some particular measures of intelligence. Humans would be like ants to an ASI system what ants are to us. We are much smarter than ants. When we want to build, let’s say a road, and there’s an ant hill on the way, chances are that we will just simply destroy the ant hill. No questions asked. Some people have reckoned that something similar may also happen to humans, if we are not careful about an ASI system that has a goal to achieve and humans happen to be on it’s way. So unless we figure out how to code in our morals and human values such as friendliness into an ASI and a way to make it’s goals align with that of humans, it seems plausible to many people that we should be concerned about it. Although no one knows if it’s even possible to build an ASI , there is still some speculation about how an ASI could come about. An ASI could arise from a technological singularity or simply a singularity. A singularity would be a point in time at which technological growth becomes uncontrollable and irreversible, resulting in unforeseeable changes to human civilization. A singularity can lead also bee a point in time at which intelligent machines with human-level intelligence can improve themselves to become much more intelligent, without the need of human intervention nor input (see the Nat Geo picture below).
Simply put, artificial general intelligence(AGI)refers to the ability of a machine to perform tasks that us humans can. So, in other words, AGI machines would be machines with human-level intelligence. There’s speculation that an AGI machine can be responsible for the singularity. So AGI systems could turn out to be a bridge from the regular A.I to an ASI. From my understanding, Ultron is an AGI robot. As a matter of fact, in most movies about A.I, the androids are usually portrayed to have AGI.
Plot Summary
Tony Stark and Bruce Banner originally devised the idea for Ultron as an extension of the Iron Legion, operating independently as a peacekeeping force. They didn’t have the adequate level of A.I to archive that purpose on a large scale. However, later on in the movie they recover Loki’s Scepter and they discover a net of neurons hidden inside the gem which could then help them bring about their Ultron system. This backfired when Ultron supposedly killed J.A.R.V.I.S, got the nuclear launch codes and escaped via the internet before the avengers destroyed his body.
After Ultron’s encounter with the Avengers, he built himself a new robot body in a Sokovia research base, the body that we see for the most part of the movie.
Ultron
Ultron, soon after, recruits Wanda Maximoff and her twin brother Pietro Maximoff, who both have beef with (disdain for) Tony Stark, because Tony is the chairman of Stark Industries which is a company that manufactured weapons of mass destruction that killed their parents in an explosion. Moments later, Ultron gets vibranium from Ulysses Klaue (the character portrayed by Andy Serkis). Then in South Korea, Ultron coerced a doctor called Helen Cho to use her expertise with cellular regeneration, and her regeneration cradle, to build himself a powerful synthetic body using vibranium that they acquired. When Ultron was in the middle of the process of transferring his mind into the new body with the help of the Mind Stone found in the Scepter, Wanda was able discover that Ultron was planning to destroy all of humankind not just taking out the Avengers, prompting her to cancel Dr. Cho’s mind control. The scientist, released from the mind control, then overrode the transfer, causing Ultron to lash out at her in return.
After losing the Maximoff twins, the avengers then battle Ultron and steal the synthetic body from him. Tony Stark then discovered that J.A.R.V.I.S was alive, hiding from Ultron on the internet and that J.A.R.V.I.S was the one who was changing nuclear launch codes to prevent Ultron from launching nukes. “The Vision,” Ultron’s body which had been recovered by the Avengers and was then reconfigured with J.A.R.V.I.S. in the mainframe after a brief fight amongst the Avengers. Vision earned the avengers trust by being able to lift Thor’s hammer the Mjolnir (this was confirmation that Vision is benevolent). Ultron devised to use the remaining vibranium to build a machine that will lift a large part of the capital city skyward, intending to crash it into the ground to cause global extinction (like an asteroid impact).
Vision
At the end, Ultron confronted the avengers with an army of robots that were all carrying Ultron’s mind and the final battle soon began. Vision confronted Ultron and was able to cut him off from the Internet. However, all his robots were destroyed in battle and, in particular, the last robot carrying Ultron’s mind was destroyed by Vision. The end of Ultron.
Afterword
I think that Avengers: Age of Ultron is one of the best sci-fi movies about A.I, especially after I dissected the villain. I think it actually highlights the actual concerns and questions about artificial intelligence that I wrote about at the beginning of this blog post. The real concern about AI isn’t killer robots per se, but it’s actually AGI systems that could lead to a singularity, which may consequently lead to an ASI system that we cannot even control. To me Ultron is the most terrifying robot that I’ve ever seen in a movie. Ultron was self-aware, had uploaded himself to the internet and Ultron kept on improving himself throughout the movie almost without the need for humans. Even more, Ultron is a goal-driven machine; his goal was to replace humans with robots, when he decided that humans are broken and incapable of evolution.
Ultron was a smart robot, but clearly not an ASI. Judging by the fact that he was self-aware and self-improving, I think that he had the potential to either make an ASI or become one himself. He was clearly the dangerous AGI machine that many experts are concerned about. The kind of AGI that could potentially initiate a technological singularity and bring about an ASI. I also liked the fact that Ultron lived on the internet and since no one can turn off the internet. This meant that he was somewhat digitally immortal, because every time the Avengers destroyed his current body, he’ll just sort of download himself into another robot body.
To me, the villain is (and consequently the movie is) underrated. Ultron wasn’t just another malevolent robot that turned on it’s human creators. Ultron was smart, creative, virtually immortal and self-improving; becoming more and more dangerous overtime.
If you liked this blog post, please clap and share.
Zindi Africa is Africa’s largest data science competition platform, solving complex challenges using artificial intelligence (AI) and machine learning (ML). The platform allows data scientists across the African continent to compete to solve challenges that focus on transport, health, social impacts, agriculture, African languages, electricity, or economics, to name a few.
The word Zindi comes from two Swahili words “zidisha”, meaning multiply and “shinda” means to win. Currently, Zindi Africa has more than 20,000 registered Data scientists and they have successfully launched 55 competitions and 40 hackathons. Zindi has 50 awesome Ambassadors in different 25 countries.
Big Data Jobs
Zindi Africa provides different categories of competition:
Prize competition: you win prize money if you are among the top 3 winners of a particular competition.
You win points: Points increase your ranking among other data scientists on the platform.
You gain knowledge: Knowledge competitions are where you can learn and increase your skill set.
As a data scientist or ML engineer in Africa, Zindi Africa is the best platform for you to learn and take your skills to the next level. The following are some of the benefits you can gain by being part of the Zindian family:
Test your skills against top talent across Africa and beyond
Learn by doing and gain practical exposure to real data science problems
Earn income by doing what you enjoy
Build your profile and attract potential employers
Learn from others through collaboration and discussion with other data scientists and ML engineers.
In this article, I am going to provide a walkthrough of how to enter a Zindi competition for the first time. In this article we will:
Understand the competition description and problem statement
Download and analyze the dataset provided
Process the dataset provided
Develop a model to predict who is most likely to have a bank account
Evaluate the model performance
Use the model to make predictions for the test dataset provided in the competition
Make the first submission and get placed on the Zindi leaderboard
Financial Inclusions in Africa
Before we go deep into the competition, let’s understand the competition page first by clicking here. If you don’t already have a Zindi account you can create one for free here.
Zindi competition page
The competition page provides some information to help you understand the problem you are going to solve, by reading the problem statement, how you can participate and how to submit your solution on the platform.
I will go through each tab and explain its functionality.
1. Info
The info tab contains the problem statements of the competition and list of organizations that have either provided the dataset or funded the competition.
On the left side, you can see a list of vertical tabs that provide more information about the competition.
(a) Description It provides the problem statement of the competition and a list of organisations or companies that supported the competition, either by providing the datasets or funding the competition.
I suggest you read the description of this competition in order to understand the problem and machine learning approach you can choose to solve it. If you read the description, you will understand that the objective of this competition is to create a machine learning model to predict which individuals are most likely to have or use a bank account.
(b) Rules
rules
Each competition has its own rules. Breaking the rules can lead to disqualification, so make sure to carefully read and understand all the rules of the competition.
(c) Prizes
Now, this is the best part: the prize section provides details about the prize money that will be provided for the first, second and third place winners of the competition. But remember not all competition provides prize money for its winners; in other competitions, you can get Zindi points or gain knowledge.
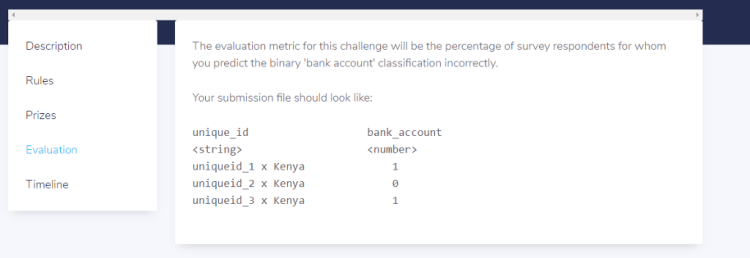
(d) Evaluation
Evaluation
Each competition has its own evaluation metric that will be used to evaluate your results and rank you on the leaderboard. It also shows how you should prepare your submission file before uploading your file on the platform.
For this competition, the evaluation metric will be the percentage of survey respondents for whom you predict the binary ‘bank account’ classification incorrectly.
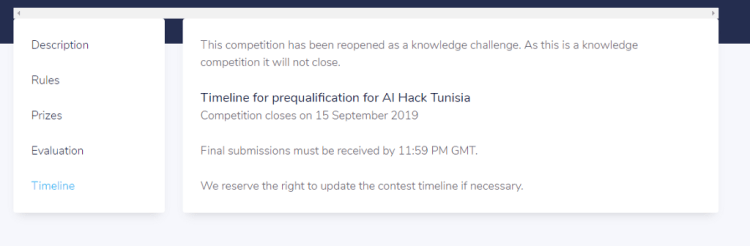
(e) Timeline
Timeline
This section provides information about the start date of the competition and the end date and time of the competition. If you submit your solution after the deadline you will receive a score but it will not reflect on the leaderboard. Make sure to submit before the deadline if you want to be considered for a prize.
This competition has been reopened as a knowledge challenge, this means it will not close.
2. Data
data page
The data tab contains a description of the dataset you are going to use for this competition. On the right side of the page, you can see a list of links to download the dataset and other important files. You will download:
VariableDefinition.csv — This file contains a definition of each variable in the train and test data.
SubmissionFile.csv — The file contains a sample of how the submission file should look like.
Test_v2.csv — This is a test data file you will use for prediction and save your results in the submission file.
Train._v2.csv– This is a train data file that contains both the independent variable and the target one. You will use this dataset to train your model.
These files may differ between competitions. Also, keep in mind that you must join the competition in order to have access to the data files.
3. Discussion
Discussion page
I’m not a Liverpool FC fan but I like their slogan: “You will never walk alone”. That is the purpose of the discussion page, you don’t need to walk alone throughout the competition. If you face any challenge or uncertainty during the competition or you want to ask a question to understand more about the dataset provided, you can post on the discussion page and other data scientists enrolled in the competition can help you to solve the problem.
The discussion board is very active and full of knowledgeable and helpful African data scientists willing to assist you.
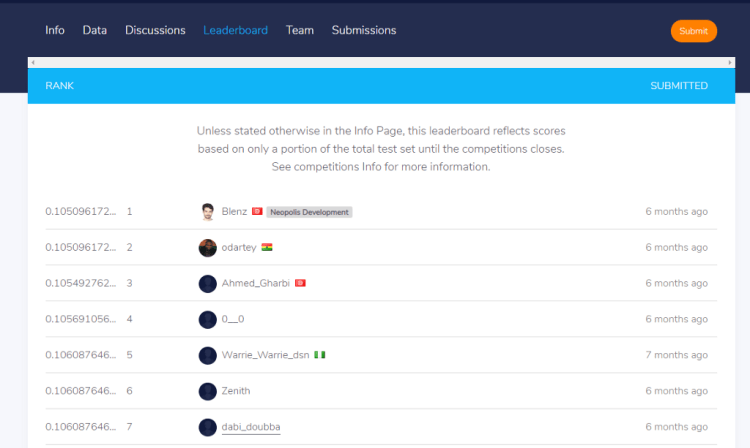
4. Leaderboard
leaderboard
After you have uploaded your submission file, you will appear on the leaderboard. The leaderboard shows your position among all enrolled data scientists in the competition. Your position will depend on your performance after your solution has been evaluated. For this competition, you can submit ten times a day.
5. Team
You don’t want to do the competition on your own? That’s OK! You can create a team with fellow data scientists enrolled in the competition and work together. The maximum number for a team is 4 members. Remember that sharing code between individuals is not allowed, so if you want to share code with someone else, they must be on the same team as you.
6. Submission
Submission file
The submission page is where you will upload your submission file, by clicking the orange button at the top right side of the page. After you have uploaded your solution, it will be evaluated according to the evaluation metric specified in the competition. Then you will see the score that will define your position on the leaderboard.
Solve The Problem
After understanding the Financial Inclusion in Africa competition page and different sections in it, let’s solve the problem provided.
1.Load The Dataset
Make sure you have downloaded the dataset provided in the competition. You can download the dataset here.
Import important python packages.
Load the train and test dataset.
Let’s observe the shape of our datasets.
train data shape : (23524, 13) test data shape : (10086, 12)
The above output shows the number of rows and columns for train and test dataset. We have 13 variables in the train dataset, 12 independent variables and 1 dependent variable. In the test dataset, we have 12 independent variables.
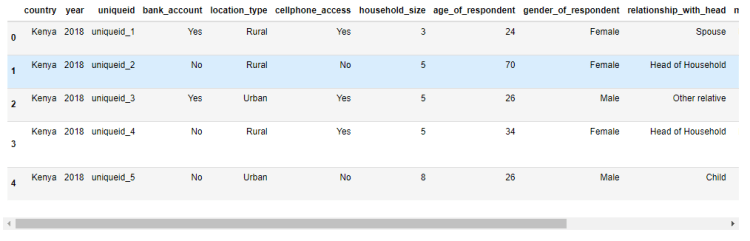
We can observe the first five rows from our data set by using the head() method from the pandas library.
First five rows
It is important to understand the meaning of each feature so you can really understand the dataset. You can read the VariableDefinition.csv file to understand the meaning of each variable presented in the dataset.
The SubmissionFile.csv gives us an example of how our submission file should look. This file will contain the uniqueid column combined with the country name from the Test_v2.csv file and the target we predict with our model. Once we have created this file, we will submit it to the competition page and obtain a position on the leaderboard.
Sample Submission
2.Understand The Dataset
We can get more information about the features presented by using the info() method from pandas.
variables information
The output shows the list of variables/features, sizes, if it contains missing values and data type for each variable. From the dataset, we don’t have any missing values and we have 3 features of integer data type and 10 features of the object data type.
I won’t go further on understanding the dataset because I have already published an article about exploratory data analysis (EDA) with the financial Inclusion in Africa dataset. You can read and download the notebook for EDA in the link below.
Before you train the model for prediction, you need to perform data cleaning and preprocessing. This is a very important step; your model will not perform well without these steps.
Time spend on a Data Science Project
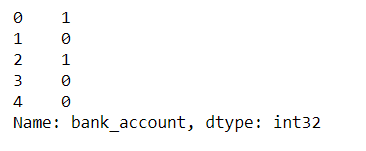
The first step is to separate the independent variables and target(bank_account) from the train data. Then transform the target values from the object data type into numerical by using LabelEncoder.
bank_acount output
The target values have been transformed into numerical datatypes, 1 represents ‘Yes’ and 0 represents ‘No’.
I have created a simple preprocessing function to handle
The processing function will be used for both train and test independent variables.
Preprocess both train and test dataset.
Observe the first row in the train data.
First row from Train set
Observe the shape of the train data.
(23524, 37)
Now we have more independent variables than before (37 variables). This doesn’t mean all these variables are important to train our model. You need to select only important features that can increase the performance of the model. But I will not apply any feature selection technique in this article; if you want to learn and know more about feature selection techniques, I recommend you read the following articles:
A portion of the train data set will be used to evaluate our models and find the best one that performs well before using it in the test dataset.
Only 10% of the train dataset will be used for evaluating the models. The parameter stratify = y_train will ensure an equal balance of values from both classes (‘yes’ and ‘no’) for both train and validation set.
I have selected five algorithms for this classification problem to train and predict who is most likely to have a bank account.
From these algorithms, we can find the one that performs better than the others. We will start by training these models using the train set after splitting our train dataset.
After training five models, let’s use the trained models to predict our evaluation set and see how these models perform. We will use the evaluation metric provided on the competition page. The statement from the competition page stated that:
The evaluation metric for this challenge will be the percentage of survey respondents for whom you predict the binary ‘bank account’ classification incorrectly.
This means the lower the incorrect percentage we get, the better the model performance.
results
XGBoost classifier performs better than other models with 0.110 incorrect.
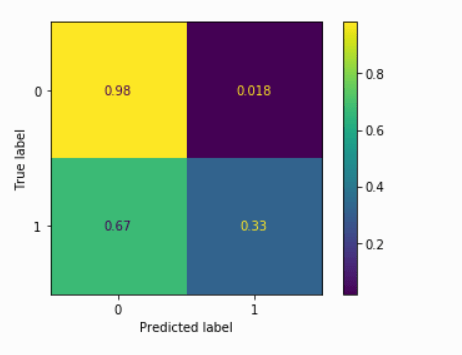
Let’s check the confusion matrix for XGB model.
xg_model confusion matrix
Our XGBoost model performs well on predicting class 0 and performs poorly on predicting class 1, it may be caused by the imbalance of data provided(the target variable has more ‘No’ values than ‘Yes’ values). You can learn the best way to deal with imbalanced data here.
One way to increase the model performance is by applying the Grid search method as an approach to parameter tuning that will methodically build and evaluate a model for each combination of algorithm parameters specified in a grid.
The above source code will evaluate which parameter values for min_child_weight, gamma, subsample and max_depth will give us better performance.
best parameters
Let’s use these parameter values and see if the XGB model performance will increase.
Error rate of the XGB model: 0.10837229069273269
Our XGB model has improved from the previous performance of 0.110 to 0.108.
5.Making the first submission
After improving the XGBoost model performance, let’s now see how the model performs on the competition test data set provided and how we rank on the competition leaderboard.
First, we make predictions on the competition test data set.
Then we create a submission file according to the instruction provided in the SubmissionFile.csv.
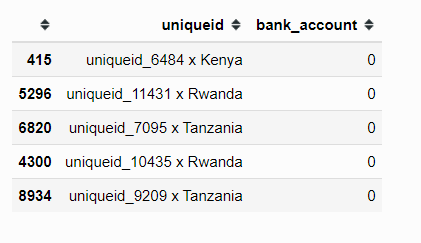
Let’s observe the sample results from our submission dataFrame.
submission samples
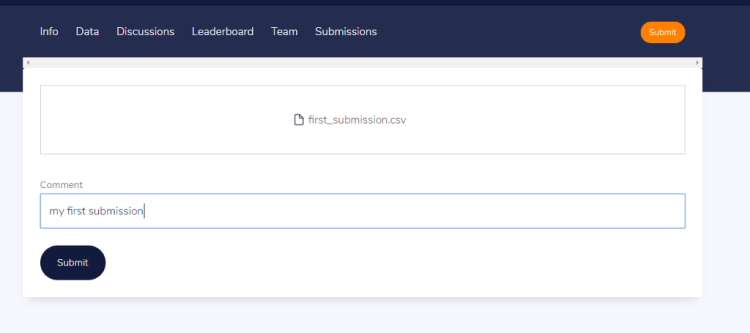
Save results in the CSV file.
We named our submission file a first_submission.csv. Now we can upload it to the Zindi competition page by clicking the submit button and selecting the file to upload., You also have an option to add comments for each submission.
upload submission file
Then click the submit button to upload your submission file. Congratulations, you just made your first Zindi submission! The system will evaluate your results according to the evaluation methods for this competition.
test scores
Now you can see the performance of our XGB model is 0.109 on the test dataset provided.
You can also see your position on the Leaderboard.
Wrap Up
In this article, I have given an overview of how to make your first submission to a Zindi competition. I suggest you take further steps to handle the imbalance of data and find alternative feature engineering and selection techniques you can apply to increase your model performance, or trying other machine learning algorithms. If you get stuck, don’t forget to ask for help on the discussion boards!
You can access the notebook for this article in the link below.
You can watch an interview with the CEO of Zindi Africa, Celina Lee on AI Kenya Podcast.
If you learned something new or enjoyed reading this article, please share it so that others can see it. Feel free to leave a comment too. Till then, see you in the next post! I can also be reached on Twitter @Davis_McDavid
One last thing:Read more articles like this in the following links.
If you are looking for a new role as a Data Scientist — either as a first job fresh out of school, a career change, or a shift to another organization — then check off as many of these critical points as possible to stand out in the crowd and pass the hiring manager’s initial CV screen.