Also: 10 Python Skills They Don’t Teach in Bootcamp; Data Science Volunteering: Ways to Help; A Journey from Software to Machine Learning Engineer; Data Science and Machine Learning: The Free eBook
Originally from KDnuggets https://ift.tt/2WjQGdX

365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Originally from KDnuggets https://ift.tt/2WjQGdX
Originally from KDnuggets https://ift.tt/3ag19iz
Originally from KDnuggets https://ift.tt/2IRsaO9

If you’re reading this you’ve landed straight in our blog post series about machine learning projects. We know that the implementation of these projects is still a big mystery for many of our customers. Therefore, we explain the phases of AI projects in a series of articles.
AI projects are usually carried out in a cyclic process. Our previous article dealt with the first two important phases of the cycle, data collection and data preparation. Today, we’re going to dive into the topic of model evaluation, which is a crucial part of phase 3 in our life cycle. Since this is a particularly complex topic, we will dedicate an entire article to it.
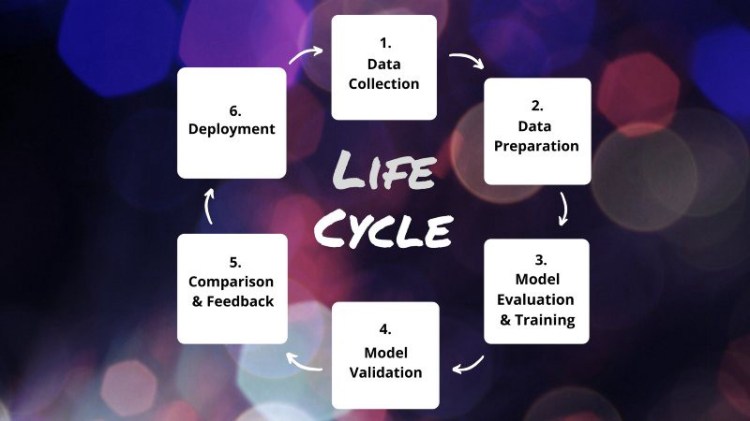
Let’s take a look at our example task again, so that we can figure out the process of selecting and evaluating the appropriate model. Our example project is about an umbrella federation for dance using a Digital Asset Management (DAM) system as a central hub for images. The DAM constantly receives images from all federation members. The dance federation uses these images as marketing collateral, but they do not want to use any of them; they only want to use the ones presenting the work of their members in a visually appealing way. The goal for the dance federation is to find aesthetic images. Consequently, our task here is to classify the images as aesthetic or unaesthetic.

What many of our customers do not know: There are various types of classification tasks — from simple object classification to localization and complex classification on pixel level. The individual use case determines which classification type is right for a task:

In our example task we simply want to classify an entire image as aesthetic or unaesthetic. Convolutional Neural Networks (CNN) are great for image classification tasks and we can choose from different models like InceptionNet, VGG or Resnet. We found Resnet to be a good base architecture since it can easily be extended to suit different levels of task complexities.
The challenge is to find out which complexity is right for a given task and training data. A model that is too shallow will underfit the problem and is simply not complex enough to solve the task. A model that is too deep needs a lot of hardware resources, time for training and tends to overfit. An overfitting model memorizes the training data instead of generalizing the underlying concepts which results in poor classifications for unseen images.
In practice, we start with a simple model and then gradually increase its complexity until the model starts to show signs of overfitting. We then look at the results (loss and accuracy of training and validation data during the training) and choose the level of complexity that slightly overfits the training data. We stick to this model and take care of the overfitting in the training stage by applying regularization techniques. The more experience you have the faster you will be able to find the right model complexity.
Our example dataset consists of 7.400 images, half of which are aesthetic images and the other half unaesthetic images. We split the dataset randomly into three parts: 75% training, 10% validation and 15% test data.

The training data is used to train the model. The validation data is used to assess the performance of the model in each epoch of the training phase. The test data is not used during training but afterwards to check how well the model can generalize and perform on unseen data.
We always want to use as much data as possible for training, because more data means a better model. But we also need to know how well the model generalizes. Basically, the more samples we have the more we can use as training data. If we have millions of samples, the proportion of validation and test data can be smaller, but still meaningful, for example when having a split of 95%, 2.5%, and 2.5%.
What will be the metrics to evaluate the training success of our model? The most essential and popular metrics are accuracy and precision/recall.
Accuracy is given by the number of correctly classified examples divided by the total number of classified examples. Let’s say we have 1k test images. If the model predicts 863 images correctly, then our model accuracy would be 86.3%.
In situations in which different classes have different importance or we have an unbalanced data set, we also use precision/recall as metrics. For example a legitimate message should not be classified as spam (high precision) but we would tolerate some spam in the inbox (lower recall). In those cases we use metrics that can tell us how reliable the model is in classifying samples correctly (precision) and how good it is to correctly classify all available samples from a given class (recall). In practice we have to choose between a high precision or a high recall as it is usually impossible to have both.
However, since nerds want to keep things “simple”, we want to express the model performance in one number. To do so, we can combine precision and recall into one metric by calculating the harmonic mean between those two. The result is called the F1 score.
What we’ve talked about today is the work we have to do inbetween data collection/data preparation and the actual model training. We have defined the classification type for our task, we have chosen the right initial model architecture, we have divided the data set into subsets for model training, and we have defined the metrics we will apply to our chosen model. In the next part of our blog post series we will continue with the actual model training. Stay tuned!
And don’t forget: If you need an experienced helping hand for your own machine learning project, drop us a line.




ML Model Evaluation: Insights Into Our Machine Learning Process was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.

As companies now have lavish amounts of data at their fingertips and AI continues to offer new business opportunities, data strategy becomes a fundamental part of maximizing ROI from AI initiatives. How exactly is data captured? How is it processed? What is the end goal of collecting and processing? These are just a fraction of important questions AI developers need to answer to succeed in their AI technology implementation.
Given that AI offers a myriad of opportunities for driving business growth, companies may be hesitant about where to start. Most importantly, an AI use case should correlate with a specific business objective. Unsurprisingly, organizations often tend to dive into AI implementation haphazardly because of the hype surrounding this technology.
However, the application area largely defines the implementation effort needed for successful AI adoption. For example, deploying AI for product development enhancement usually calls for structural changes, revamping of business workflows, and extensive data preparation. At the same time, augmenting customer service with chatbots will require less hassle when preparing data for this initiative.
Once you have defined the use case, developing a data-centric culture should become a priority. Far too often, organizations are getting heavily invested in all the technicalities of AI implementation, leaving their workforce disincentivized and underprepared for taking advantage of the new tools. For AI adoption to succeed, it’s crucial to ensure that workforce is ready both psychologically and technically.
This is usually done by introducing a succession of training sessions dedicated to data literacy. It’s important to stress how exactly new AI tools will enhance current workflows and help achieve better performance. Workforce training usually takes a considerable amount of time, especially when carried out in large enterprises. This is why it’s often crucial to start upskilling incentives as early as possible in the AI adoption cycle. By creating functional prototypes with all the essential features, you can start retraining way before the actual AI deployment.
When it comes to assessing data readiness, data quality is the place to start. There are many attributes of data quality to consider, including accuracy, completeness, consistency, validity, integrity, and lack of bias.
Far too often, companies put an excessive amount of resources into data cleaning. While it’s certainly logical, determining which exact datasets need to be scrubbed clean is what really matters. Even as companies are faced with a continuous influx of data, most of the time it’s only a fraction of this data that is useful for a particular business case. This is why it’s important to figure out the appropriate strategy and determine a specific AI application before diving into data cleaning.
Ideally, companies need to establish practical data storage and transfer frameworks, meaning that only relevant data should be systematically collected and processed. This way, an AI strategy will become more economically efficient.
It’s also important to route all the incoming data into a single data management hub, be it cloud-based or locally stored. The idea is to make data easily accessible to all important actors, including business analysts, stakeholders, and clients. Moreover, by establishing solid data architecture, it becomes easier to adopt other AI use cases as your business grows.
Migrating to the cloud is one of the most critical steps on the path to AI adoption. The cloud allows organizations to scale, gain much-needed flexibility, and significantly decrease costs. While this step is rarely needed for short-term AI success, it’s one of the main enablers for going full-on in the long term.
Most importantly, AI requires to process huge amounts of data in real time to operate at scale. When data is stored in different organizational systems like corporate email, CRM, or invoices, it becomes hard for AI to process it. Cloud solves all these problem by making it possible to store and process data from a single place.
In most cases, the trick is to store data on multiple cloud platforms, rather than one. Cloud platforms can drastically differ from each other in terms of their functionality. By going multi-cloud from the inception, companies can save themselves from the trouble of relying on any single cloud vendor.
Responsible data aggregation and processing should be at the core of your data governance structure. As users are becoming increasingly concerned about their privacy, this requires organizations to become more transparent about data usage and reevaluate their ethical data use policies when it comes to AI operation.
Logically, the more data AI has access to, the better decisions it can make. This is why it’s often tempting for an organization to stockpile every bit of data available. However, such an approach poses significant discrimination risks that can affect long-term AI success.
For example, AI can consider a customer’s determined gender to decline a loan or a job application, increase the price, or make a totally irrelevant product offering. Moreover, when there are too many data points, it becomes harder for data scientists to explain AI decision-making rationale. Not only is this unethical but also legally risky, as common regulatory frameworks like the GDPR require companies to be able to clearly explain reasoning behind AI-made decisions.
A robust and scalable AI strategy always rests on a solid data foundation. Here are a few steps every company should take to make it happen:
Is Your Data Strategy AI-Ready? was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Via https://becominghuman.ai/is-your-data-strategy-ai-ready-40aa2e0e5c2?source=rss—-5e5bef33608a—4
source https://365datascience.weebly.com/the-best-data-science-blog-2020/is-your-data-strategy-ai-ready
What is Euclidean Space and Non-Euclidean Space?

Euclidean Space
which involves the functional of 1 Dimensional, 2 Dimensional to N number of Dimension.
Whenever a Mathematician creates a formula in Geometry he has to prove that formula works for all Dimensional.

Let’s Get into non-euclidean Space.
Yeah, There is no Euclidean Space it’s about curve like hyperbolic and Sphere like space. Simply Euclidean looks for flat and Surface but non-Euclidean looks for curved.
This is much more useful than Euclidean space many times.
Neural networks are performing well in Euclidean Data. example: Text, Audio, Images, etc.
But what about Non-Euclidean Space? example: Graphs/Networks, Manifolds.Etc. (Likewise complex structures)
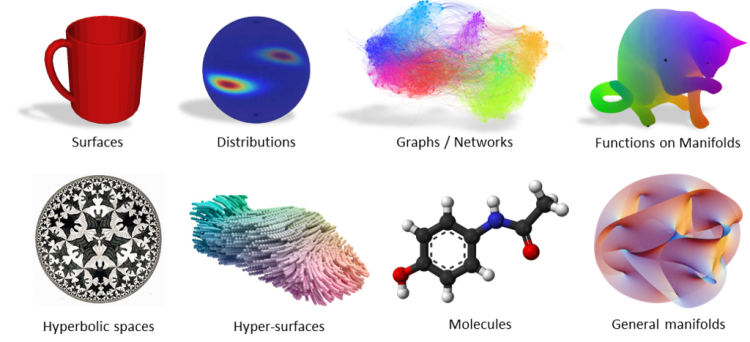
To know more about Non-Euclidean Space
So there comes Geometric Deep learning. Paper
Bronstein et al. first introduced the term Geometric Deep Learning (GDL) in their 2017 article “Geometric deep learning: going beyond euclidean data”
They are trying on the graphs and applying 3d model on CNN and etc.
Now we are going to look into one of that subdomain Graph lets jump into it.
For a little bit, we will brush up on the basic stuff.
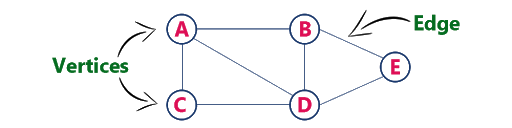
The graph is Simple G= (V, E)
Where, V= Vertices/Nodes. E =Edges.
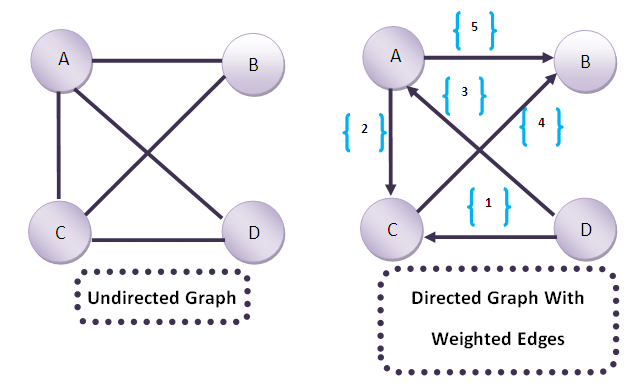
the Weight/Labels can be numeric or string.
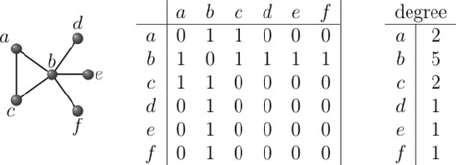
Nodes /vertices can have features , for example node A can be have features like it properties. (Weight and Features are not the same)
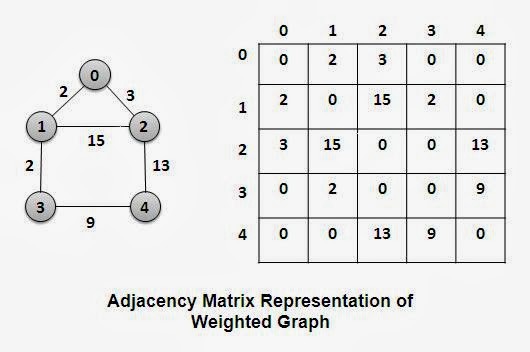
Computer Doesn’t understand the graph, So what to do? We can use Matrix

We know that any graph can be derived as the Matrix(N * M).
N-number of nodes
M-edges of graph
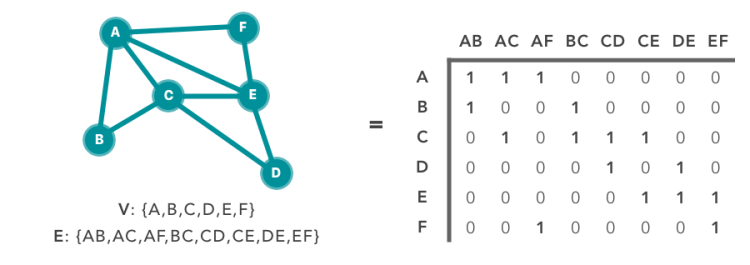
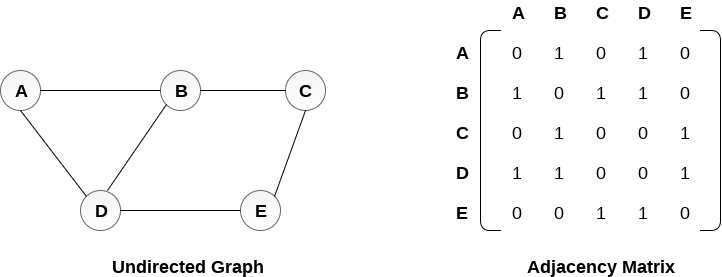
Properties
Simply , Collecting the neighborhood of the each node.
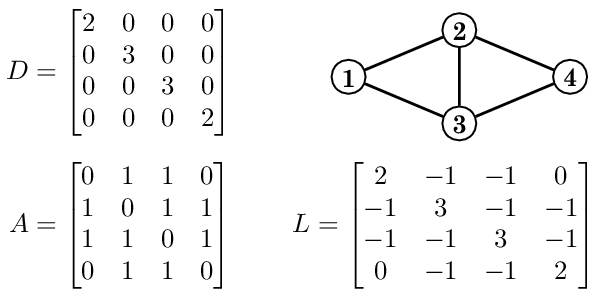
Laplacian = { D - A }
where ,
D - Degree Matrix
A - Adjacency Matrix
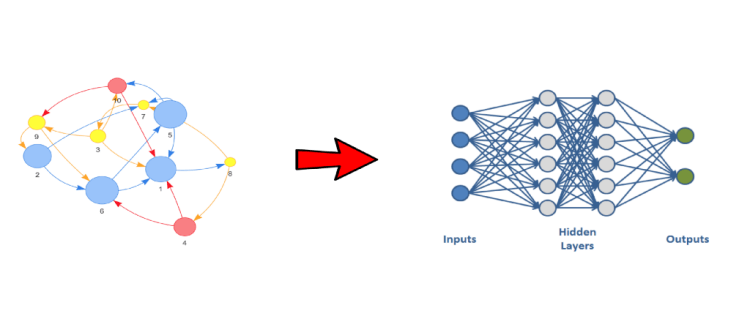
We know Neural networks and CNN are having fixed input values in the model But, Graphs are not fixed. So we have to do new approaches.
Get into CNN, CNN works in 3 steps
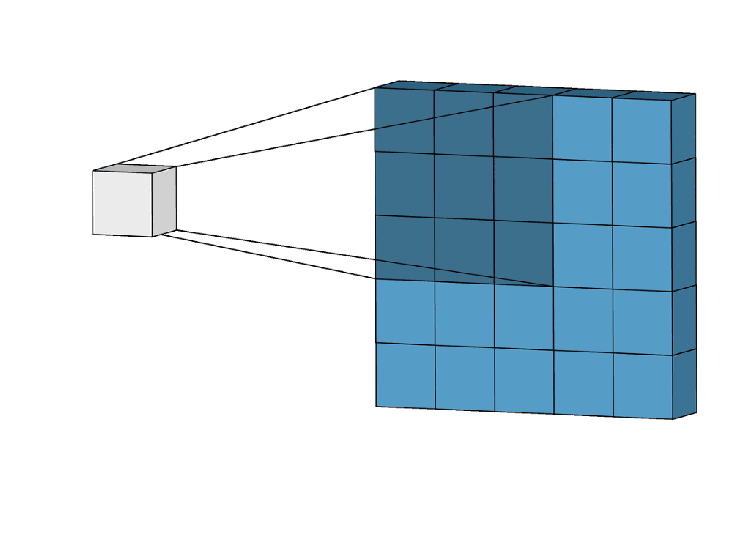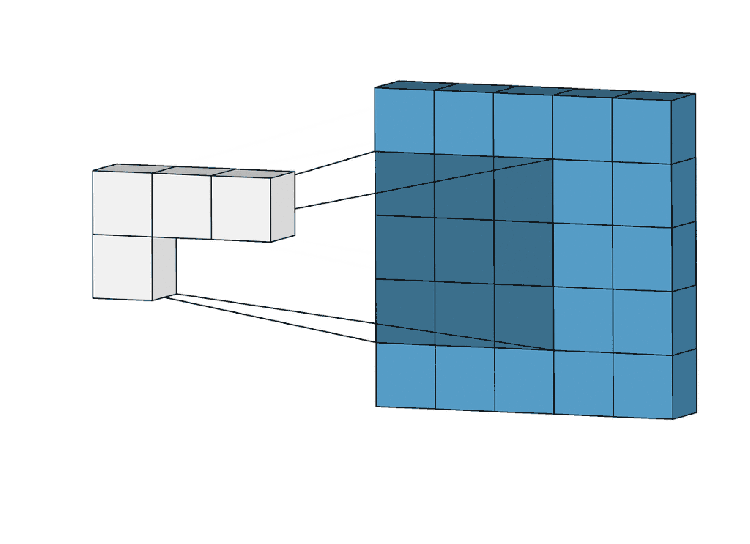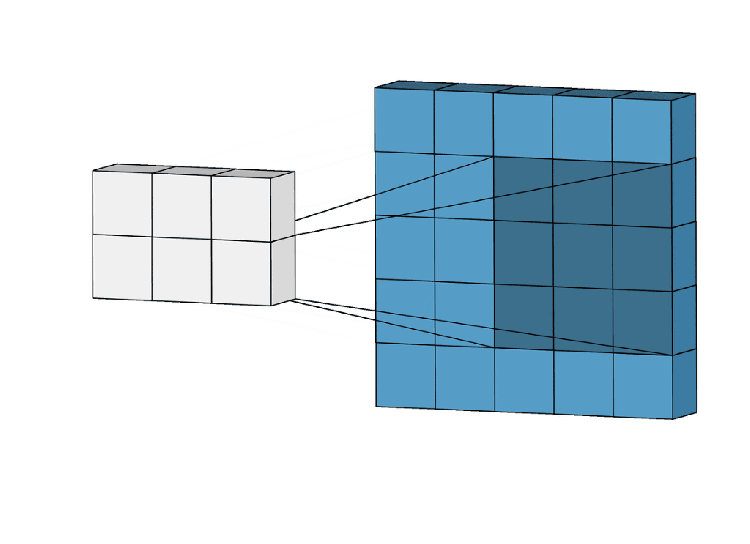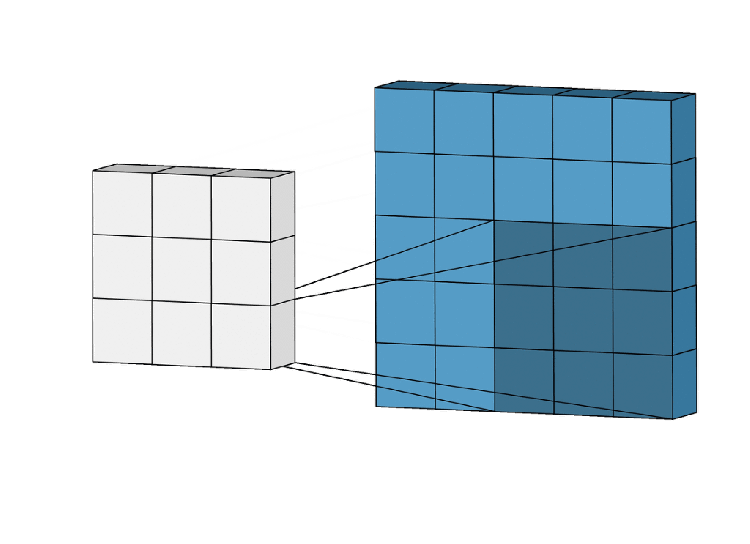
We can use the same methodology for GNN. In here locality will be considered for the neighborhood(how a node is connected to another node localizing the nodes), Aggregation means how they are contributing to their corresponding nodes by weights. Composition (stacking layers) passing to more layers.
Aim : Similarity (u , v)= (z_u)^T(z_v) , z denotes the embedded space.
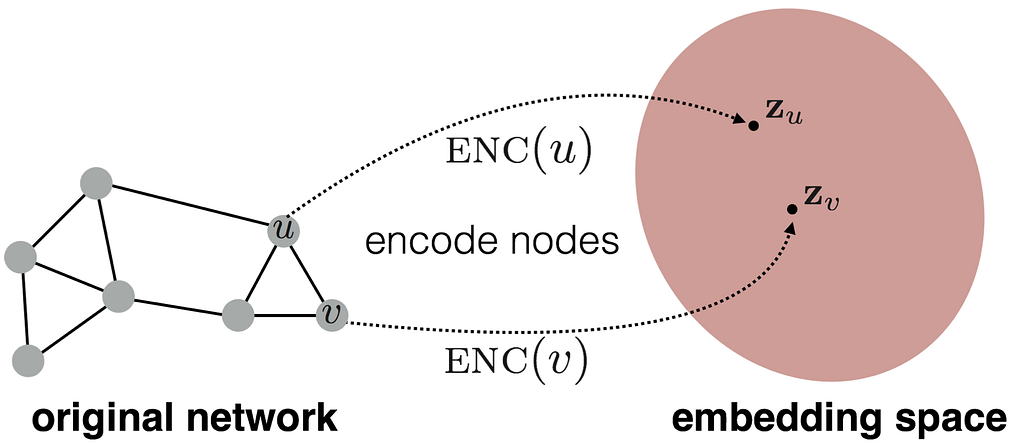
Node embedding converting the node into d-dimensional, where embedding space dimensional is less than the original network space.
encoding function ENC() converts the nodes into d-dimensional without changing the distance of u and v nodes.
Consider, u has the feature vector named x and v has y.
so , (z_u)(z_v) = (x)^T (y).
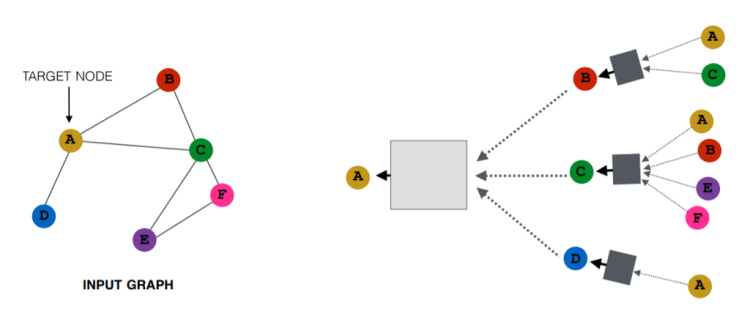
we have to create a computational graph for the target node.A’s neighborhood are B, C, D, so first B, C, D connected towards A, then connecting neighbors of neighbors, B is connected with A, C, Likewise, it goes
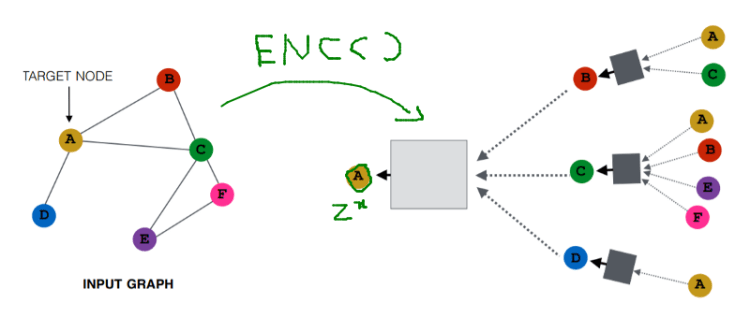
here it is working as an encoder function, A node to Z^x is actually an encoding. (Z^x is the feature vector of the A)
Also, all of the nodes have their own feature vector.
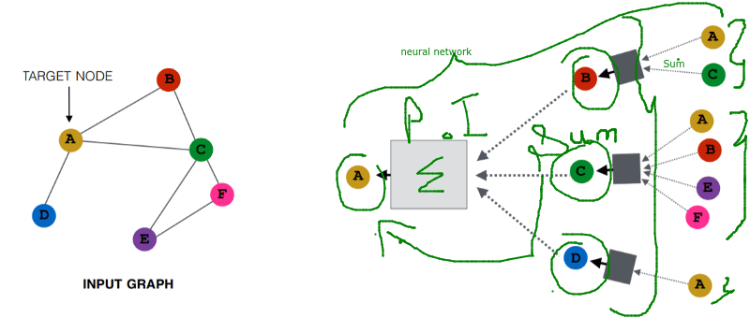
To get B we will sum up the A and C, likewise, for A we will sum up the B, C, D. It is a permutation invariant, that means (A+ B) and (B+A).
In the above, we have taken A has the target node, but after that, we have to take all the nodes as target node, for after this, b will be the target node that will give us the different Computational graph, like for other nodes also.
We know how the Forward propagation works.
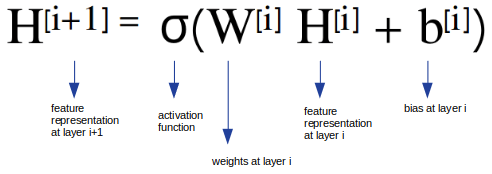
But how Graph Convolutional Networks works? there comes Spectral GCN. Spectral GCNs make use of the Eigen-decomposition of graph Laplacian matrix to implement this method of information propagation. GCN Paper
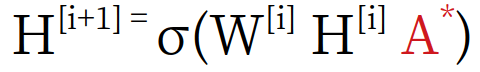
where A is the adjacency matrix. A* is the normalized value of A, For the Self-loops, we can multiply the A with an identity matrix.
Spectral Graph Convolution works as the message passing network by embedding the neighborhood node information along with it.
For training GCN we need 3 elements
Consider, X- as the input features, A as Adjacency matrix, D is degree matrix.
The dot product of Adjacency Matrix and Node Features Matrix represents the sum of neighboring node features
AX = np.dot(A,X)
Normalizing A is can be done in the way of

Doing the dot product with an inverse of degree matrix and AX but in this paper, Kipf and Welling are suggesting to do the symmetric normalization.

#Symmetrically-normalization
D_half_norm = fractional_matrix_power(D, -0.5)
DADX = D_half_norm.dot(A_hat).dot(D_half_norm).dot(X)
Otherwise, there is no need for Backpropagation. the function as it is just we are sending Adjacency matrix and input features with it, and only the forward propagation happens, each node is converted to the computational graph, and the forward propagation formula changes a little bit, also we are avoiding the bias b in the formula for simplicity sake, But the problem with the Graph neural network is data preparation, where we need an edge connectivity data and input features and adjacency matrix, the adjacency matrix is easy to create by one line of code, but the node, feature vectors and edge need to be clear.
For example, let us take Cora dataset :
The Cora dataset consists of 2708 scientific publications classified into one of seven classes. Each publication in the dataset is described by a 0/1-valued word vector indicating the absence/presence of the corresponding word from the dictionary. The dictionary consists of 1433 unique words.
Number of graphs: 1
Number of features: 1433
Number of classes: 7
Code for this Model building.
Geometric Deep learning with Graph Neural Network was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally from KDnuggets https://ift.tt/34fQscb
Originally from KDnuggets https://ift.tt/2LvmFFO
Originally from KDnuggets https://ift.tt/3mhvjnZ
Originally from KDnuggets https://ift.tt/2ITVh3y
