How to generate real-time visualizations of custom metrics while training a deep learning model using Keras callbacks.
Originally from KDnuggets https://ift.tt/2ILGtDQ

365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Originally from KDnuggets https://ift.tt/2ILGtDQ

Machine learning (ML) is the study of computer algorithms that improve automatically through experience. It is seen as a subset of…
Continue reading on Becoming Human: Artificial Intelligence Magazine »
Read time : 10 min
Robust/robustness is a commonly used but often not elaborated concept in statistics/machine learning. We get started with some instance:
1. Robust: median, IQR, trimmed mean, Winsorized mean
2. Non-robust: mean, SD, range
Outline
(1) Definition of “Robust”
(2) Dealing with Errors and Outliers
1. Treat outliers as errors, then remove them
2. Use domain knowledge and find outliers possible
3. Use robust methods
(3) Another Instance
(4) Parametric, Non-parametric and Robust Approaches
1. Parametric approach
2. Robust approach
3. Non-parametric approach
(5) Another Robust Method: Resampling
1. Resampling
2. Jack-knifing
3. Bootstrap
(6) Reference

“All models are wrong, but some are useful” — G. E. P. Box
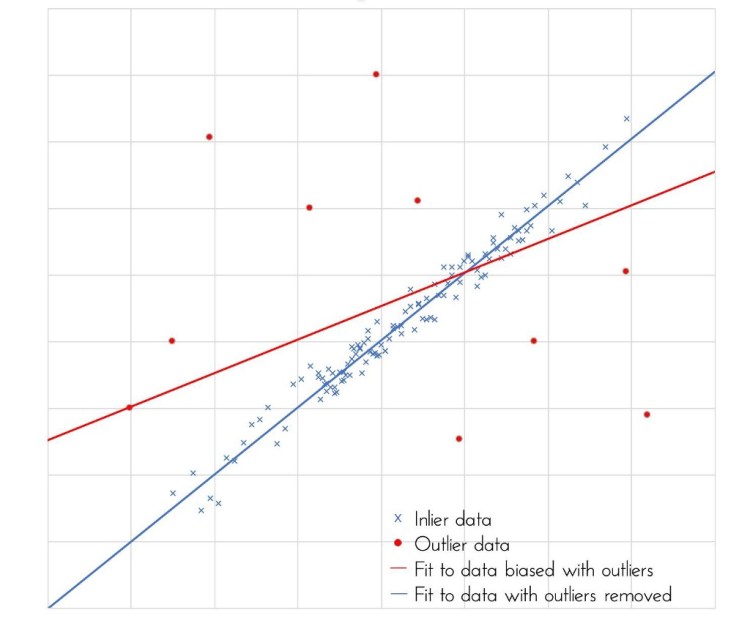
Let’s take a close look at the definitions of “robust / robustness” from a variety of sources:
1. Robust statistics are statistics with good performance for data drawn from a wide range of probability distributions, especially for distributions that are not normal. [2]
2. A robust concept will operate without failure and produce positive results under a variety of conditions. For statistics, a test is robust if it still provides insight into a problem despite having its assumptions altered or violated. In economics, robustness is attributed to financial markets that continue to perform despite alterations in market conditions. In general, a system is robust if it can handle variability and remain effective. [3]
3. Robust statistics, therefore, are any statistics that yield good performance when data is drawn from a wide range of probability distributions that are largely unaffected by outliers or small departures from model assumptions in a given dataset. In other words, a robust statistic is resistant to errors in the results. [4]
Then, we turn to a classic statistics book Problem Solving: A Statistician’s Guide published in 1988:
4. A statistical procedure which is not much affected by minor departures is said to be robust and is fortunate that many procedures have this property. For example the t-test is robust to departure from normality. [5]
Now that we went through all kinds of definitions with few variations, let’s see why we need robust statistics / robust model.
While handling with outliers, we have a couple of approaches at hand:
A straightforward method often be adopt without full consideration. Here, we may remove the outliers, leaving the data points with missing values.
It may be sensible to treat an outlier as a missing observation, but this may be improper if the distribution is heavy-tailed.
Extreme observations which may, or may not, be errors are more difficult to handle. The tests deciding which outliers are ‘significant’, but they are less important than advice from people ‘in the field’ as to which suspect values are obviously silly or impossible and should be viewed with caution. [5]
An alternative approach is to use robust methods of estimation which automatically downweight extreme observations. For example one possibility of univariate data is to use Winsorization by which extreme observations are adjusted toward the overall mean, perhaps to the second or third most extreme value (either large or small as appropriate). However, many analysts prefer a diagnostic parameter approach which isolates unusual observations for further study. [5]
My recommended procedure for dealing with outlying observations, when there is no evidence that they are errors, is to repeat the analysis with and without the suspect values. If the conclusions are similar, then the suspect values “don’t matter”. If the conclusions differ substantially, then one should be wary of making judgements which depend so crucially on just one or two observations (called influential observation). [5]
The assumptions of LDA (linear discriminant analysis) are that features are independent, continuous, normally distributed. If the preceding assumptions are violated, LDA performs badly; then, in this case, regression is more robust than LDA, and neural network is more robust than regression. [6]
After understanding this instance, we shall move on to a larger scope.
Now we know that a model is only an approximation to reality. The model can be spoiled by:
(a) Occasional gross errors. (Gross errors are caused by experimenter carelessness or equipment failure. These “outliers” are so far above or below the true value that they are usually discarded when assessing data. The “Q-Test” is a systematic way to determine if a data point should be discarded. [7])
(b) Departures from the secondary assumptions, i.e. distributional assumptions, e.g. the data are not normal or are not independent.
(c) Departures from the primary assumptions.
“Traditional” statisticians usually get around (a) with diagnostic checks, where usual observations are isolated or ‘flagged’ for further study. This can be regarded as a step towards robustness.
Here are 3 approaches we can adopt to tackle with the issues above:
A classical parametric model-fitting approach comes first in our minds. There are 4 main assumption of parametric approach [8]:
{1} Normal distribution of data
{2} Homogeneity of variance
{3} Interval data
{4} Independence
Robust methods may involve fitting a parametric model but employ procedures which do not depend critically on the assumptions implicit in the model. In particular, outlying observations are usually automatically downweighted. Robust method can therefore be seen as lying somewhere in between classical and non-parametric methods.
Some statisticians prefer a robust approach to most problems on the grounds that little is lost when no outliers are present, but much is gained if there are. Outliers may spoil the analysis completely, and thus some robust procedures may become routine.
A non-parametric (or distribution-free) approach makes few assumptions about the distribution of the data as possible. It’s widely used for analyzing social science data which are often not normally distributed, but rather may be severely skewed.
Non-parametric methods get around problem (b) above and perhaps (a) to some extent. Their attractions are that (by definition) they are valid under minimal assumptions and generally have satisfactory efficiency and robustness properties. Some of the methods are tedious computationally although this is not a problem with a computer available. However, non-parametric results are not always so readily interpretable as those from a parametric analysis. Non-parametric analysis should thus be reserved for special types of data, notably ordinal data or data from a severely skewed or otherwise non-normal distribution.
Let’s further probe into “Nonparametric Tests vs. Parametric Tests” [9], featuring the advantages of each other:
1. Parametric tests can provide trustworthy results with distributions that are skewed and non-normal
2. Parametric tests can provide trustworthy results when the groups have different amounts of variability
3. Parametric tests have greater statistical power
1. Nonparametric tests assess the median which can be better for some study areas
2. Nonparametric tests are valid when our sample size is small and your data are potentially non-normal
3. Nonparametric tests can analyze ordinal data, ranked data, and outliers
Initial data analysis may help indicate which approach to adopt. However, if still unsure, it may be worth trying more than one method. If, for example, parametric and non-parametric tests both indicate that an effect is significant, then one can have confidence in the result. If, however, the conclusions differ, then more attention must be paid to the truth of secondary assumptions.
There are a number of estimation techniques which rely on resampling the observed data to assess the properties of a given estimator. They are useful for providing non-parametric estimators of the bias and standard error of the estimator when its sampling distribution is difficult to find or when parametric assumptions are difficult to justify.
The usual form of jack-knifing is an extension of resampling. Given a sample of n observations, the observations are dropped one at a time giving n (overlapping) groups of (n-1) observations. (cf. Leave-One-Out Cross-Validation, LOOCV) The estimator is calculated for each group and these values provide estimates of the bias and standard error of the overall estimator.
A promising alternative way of re-using the sample is bootstrapping. The idea is to simulate the properties of a given estimator by taking repeated samples of size n with replacement from the observed empirical distribution in which X1, X2, …, Xn are each given probability mass 1/n. (cf. jack-knifing takes sample size (n-1) without replacement.) Each sample gives an estimate of the unknown population parameter.
The average of these values is called the bootstrap estimator, and their variance is called the bootstrap variance. A close relative of jack-knifing, called cross-validation (CV), is not primarily concerned with estimation, but rather with assessing the prediction error of different models. Leaving out one (or more) observations at a time (i.e. Leave-One-Out Cross-Validation, LOOCV), a model is fitted to the remaining points and used to predict the deleted points.
[1] The University of Adelaide (Unidentified). Robust Statistics. Retrieved from
[2] Wikipedia (Unidentified). Robust statistics. Retrieved from
[3] Kenton, W. (2020). Robust. Retrieved from
[4] Taylor, C. (2019). Robustness in Statistics. Retrieved from
Robustness: The Strength of Statistical Models
[5] Chatfield, C. (1988). Problem Solving: A Statistician’s Guide. London, UK: Chapman & Hall.
[6] Lewis, N.D.(2016). Learning from Data Made Easy with R: A Gentle Introduction for Data Science. [Place of publication not identified]: CreateSpace Independent Publishing Platform.
[7] University of California (Unidentified). Analysis of Errors. Retrieved from
http://faculty.sites.uci.edu/chem1l/files/2013/11/RDGerroranal.pdf
[8] Klopper, J.H. (Unidentified). Assumptions for parametric tests. Retrieved from
[9] Frost, J. (Unidentified). Nonparametric Tests vs. Parametric Tests. Retrieved from
Nonparametric Tests vs. Parametric Tests – Statistics By Jim




ML07: What is “robust” ? was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Via https://becominghuman.ai/ml07-f899675ed237?source=rss—-5e5bef33608a—4
source https://365datascience.weebly.com/the-best-data-science-blog-2020/ml07-what-is-robust

An example of how you can count efficiently the cumulative distinct values in R and Python
Continue reading on Becoming Human: Artificial Intelligence Magazine »
Via https://becominghuman.ai/cumulative-count-distinct-values-d8601f145c29?source=rss—-5e5bef33608a—4
source https://365datascience.weebly.com/the-best-data-science-blog-2020/cumulative-count-distinct-values
Originally from KDnuggets https://ift.tt/2KlwpSG
Originally from KDnuggets https://ift.tt/2LvNABn
Summary: Autonomous driving is a hot topic that has gained immense popularity — but is it an actual concept. If yes, what are the probabilities that it brings along as it sounds oxymoron? Let’s understand the challenges of autonomous driving and how agile technology can play an important role in bringing this concept to reality.
Autonomous driving is a new concept, and everyone is excited to know about driverless vehicles. The technology is undergoing testing in several areas; the picture is not clear yet. Autonomous vehicles rely on sensors, machine learning systems, artificial intelligence technology, processors, and complex algorithms.
The self-driving car works on a map of its surroundings that is based on sensors integrated into different parts of the vehicle. The sensors and cameras detect the nearby vehicles, monitor road signs, traffic signals, pedestrian position in the surroundings to help these cars move smoothly. Lidar signals measure distance, identify lane marks to flash the light pulses. Ultrasonic sensors integrated into the wheels allow parking the car considering all the rules.
Software applications that integrate into the autonomous driving vehicles processes and execute all the sensory outputs transmit instructions to the vehicle’s actuators that control the steering and the brakes.

A lot of challenges obstruct the path of autonomous cars, and it seems like the world is still years away from experiencing it.
If you’re thinking about what Lidar is, here’s the answer.
Lidar is an abbreviation used for “light detection and ranging” and also referred to as 3D scanning or laser scanning.
Let’s see what are the challenges involved in autonomous driving.
Implementing Lidar signals across multiple locations is over-expensive. But it’s an important component that must be in place to enable the right balancing of distance and range between vehicles. What if more than one autonomous car drives on the same route? And if their lidar signals would intersect each other.
To bring the concept of autonomous driving to life, it is important to re-build the infrastructure of the cities and metropolitan areas. It’s imperative to figure out if the autonomous cars will have trouble riding on bridges and in tunnels. And what about separate lanes for autonomous and legacy cars.
Humans rely on non-verbal interactions such as understanding the body language or reading other drivers’ facial expressions, and making eye contact with pedestrians while driving. It helps in predicting the behavior of other drivers and pedestrians for safe driving. No matter what, the autonomous cars can never assimilate the same safety instincts.
What if the autonomous car hit an accident? Who will be responsible for the cause? Who is to be blamed — the human passenger, the pedestrian, or the manufacturer? The latest prototype reveals that the Level 5 autonomous car will not have a steering wheel or even a dashboard. It implies that if an emergency occurs, the human passenger will not be able to take control of the car.
Should we get ready for an all-new riding experience? Or we have to wait for a few more years?
Once autonomous cars are ready to take over the roads, they can prove to be a revolutionary innovation that will transform people’s lives, not only the automotive industry. It will provide the flexibility to work while commuting. You can watch movies while on the go or can browse your social media accounts conveniently without fearing the traffic rules and regulations.
Although other industries (such as telecommunication, retail, travel) have disrupted the latest technology advancements, the automotive industry is one that has experienced a little change. However, with the launch of level 3 autonomous cars, the automotive industry has spelled magic in the area of the connected world.
The paradigm shift in technology also reveals that once the Level 5 autonomous cars are launched, the industrial giants will be left with no choice but to enter the new automotive ecosystem. A fully-immersive environment that has emerged as a result of top industry trends and innovative technology landscape.
High-Level Engineering Technologies for Autonomous Driving
The autonomous driving technology landscape can’t be built on the base of high-end concepts or blueprints. There’s a wide array of technologies, skills, and innovations involved in building one. Advanced Driver Assistance Systems (ADAS) is something that the automotive industries will require for preparing consumers and regulators to take over the control from drivers.
Primary challenges involved in the advent of autonomous cars are the pricing, safety issues, and consumer understanding. It can be calculated that regulatory guidelines and consumer acceptance can play a vital role in obstructing the development of autonomous cars.
Agile Java application development, combined with tech expertise, can help to create the roadmap for successfully achieving the goal. Technologies that lay grounds for the development of immersive autonomous driving technology includes:
Each of the above-mentioned components is responsible for handling different domains of software engineering. One of these elements may focus on sensor programming; others might focus on artificial intelligence, while others will handle cameras. All the development team members must distribute the workload as per specialized skills, from developing data layers to building V2X connectivity applications.
Today’s legacy cars have reached level 3 autonomy with innovative software application development in the area of autonomous driving. It will take a couple of years till we see fully automated cars on our roads. Autonomous driving is an exceptional engineering area that requires excellent technical skills and agile software to make it a reality in the near future.
Fully autonomous vehicles are unlikely to rule the market until the regulatory and technological issues are resolved. However, the fact is that, nor the automotive giants or the leading tech players have this outstanding skill set. However, if hardware and software service providers can shake hands and collaborate for developing automated solutions, it is possible that they can meet the business-specific requirements of the automotive industry.
How Autonomous Driving is Transforming Automotive Industry? was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
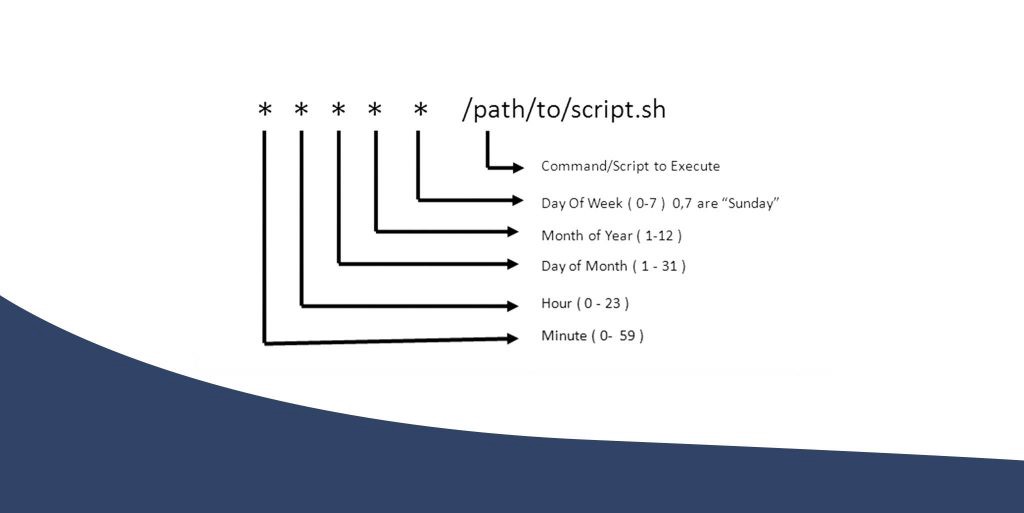
A practical example of how you can schedule your scripts using Cron Jobs in Linux
Continue reading on Becoming Human: Artificial Intelligence Magazine »
Via https://becominghuman.ai/how-to-schedule-a-cron-job-in-linux-2c7d61805cac?source=rss—-5e5bef33608a—4
Originally from KDnuggets https://ift.tt/377pANd
source https://365datascience.weebly.com/the-best-data-science-blog-2020/matrix-decomposition-decoded

Entity extraction, also known as entity identification, entity chunking, and named entity recognition (NER), is the act of locating and classifying mentions of an entity in a piece of text. This is done using a system of predefined categories, which may include anything from people or organizations to temporal and monetary values.
The entity extraction process adds structure and semantic information to previously unstructured text. It allows machine-learning algorithms to identify mentions of certain entities within a text and even summarize large pieces of content. It can also be an important preprocessing step for other natural language processing (NLP) tasks.
With a wide range of potential use cases, from streamlining customer support to optimizing search engines, entity extraction plays a vital role in many of the NLP models that we use every day. An understanding of this field of research can play a role in helping your business to innovate — and stay ahead of the competition. However, as with many fields of machine learning, it can be hard to know where to begin.
With these difficulties in mind, we’ve created this guide as a crash course for anyone keen to start exploring the world of entity extraction. Covering everything from the basic makeup of an entity to popular formatting methods, the content below will help you have your own entity extraction project up and running in no time.
Alternatively, for more on how Lionbridge can help you to build an entity extraction model, check out our entity annotation services.
Generally speaking, an entity is anything that has a distinct and self-contained existence. This can be physical, such as a dog, tree, or building. It can also be conceptual, such as a nation, organization, or feeling. Linguistically, the vast majority of nouns can be considered entities in some shape or form.
However, such a broad definition of entities isn’t particularly helpful when it comes to entity extraction. Instead, researchers tend to extract only named entities from a text. Named entities usually have a proper name, and differ from entities as a whole in that they indicate the exact same concept in all possible instances. “Apple,” “Freddie Mercury,” and “the Bank of Japan” are all named entities, while “apple,” “the musician,” and “the bank” are not. This is because “Freddie Mercury” is inextricably connected to the lead singer of Queen in all its uses, whereas “the musician” could refer to Mick Jagger, Beyoncé, or anyone who enjoys playing the guitar. While the meaning of an entity can change depending on context, a named entity is always linked to one specific concept.
In the strictest possible sense, named entities can also be referred to as rigid designators, while entities with a more fluid meaning can be described as flaccid designators. However, there is actually a slight difference between rigid designators and named entities. Rigid designators only encompass terms with an unbreakable link to a certain concept. In contrast, there is a general consensus amongst NLP researchers that, for practical reasons, certain other things like currency and time periods can be considered named entities.
In this context, extraction involves detecting, preparing, and classifying mentions of named entities within a given piece of raw text data. This can be done manually, using annotation tools like BRAT, or through the use of an NER solution. The categorization system that these entities are sorted into can be unique to each project. Entities can be categorized into groups as broad as People, Organizations, and Places, or as narrow as Soluble and Insoluble Chemicals.
Before it’s possible to extract entities from a text, there are several preprocessing tasks that need to be completed. For example, tokenization helps to define the borders of units within the text, such as the beginning and end of words. Part-of-speech (POS) tagging annotates units of text with their grammatical function, which helps to lay the foundations for an understanding of the relationships between words, phrases, and sentences. These processes help the machine to define the position of entities and begin to extrapolate their likely role within the text as a whole. Despite their necessary role in entity extraction, they’re not usually defined as such. Instead, data scientists will usually assume that these preprocessing steps have already been completed when discussing their extraction project.
However, this doesn’t change the fact that entity extraction is a complex, multi-step process. Under the umbrella of entity extraction, there are several other, slightly different tasks that add to the breadth and depth of what it’s possible to do with named entities. To give just one example, coreference resolution can be vital to the success of any entity extraction project. This process ensures that various different ways to describe a certain named entity are all recognized and labeled. For example, ‘Marshall Mathers’, ‘Mathers’, and ‘Eminem’ all refer to the same person and need to be identified in this way in the text, despite the difference in words used to describe them. Coreference resolution can be performed either in-document or across several documents, which enables an algorithm to link two documents which mention a certain entity together.
Before any entities can be extracted, there has to be some raw text input. Here’s an example of a short paragraph that contains several types of entities to extract:

There are a range of different ways that we could progress here, depending on the classification system we use. We could choose to extract only one general type of entity, such as people, or a range of more specific entity types, such as actors and actresses or fictional characters.
Once we’ve decided on our classification system, labels can be added to a text using open-source tools like BRAT. After we’ve finished annotating, our text output might look something like this:

One important thing to note is that while the meaning of named entities does not change, the way that you choose to classify them is highly subjective. While the phrase Johnny Depp always signifies the same person, he could be labeled as a Person, Actor, or American amongst other things. The categories in our example are just one possible way to group these named entities. Depending on the other pieces of text in the dataset, certain labels may make more sense than others.
The field of entity extraction has a selection of technical terms that it’s important to know. While we’ll discuss some of these in more detail later on, here’s a list that will quickly reinforce your knowledge:
Coreference Resolution
In natural language processing, this task primarily involves finding and tagging different phrases that refer to the same specific entity. For entity extraction purposes, this might involve identifying which categories the words ‘she’, ‘he’, or ‘it’ belong to.
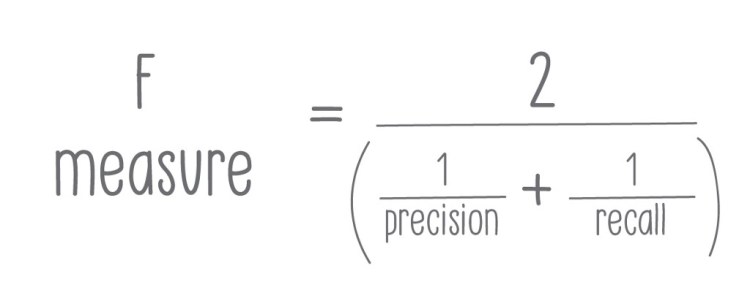
F1 Score
Also called f-score, this is a method used to judge a program’s accuracy. It takes into consideration an algorithm’s precision and recall. The best f-score is 1, while the worst is 0. The formula to calculate f-score is as follows:
Information Extraction
This is the process of retrieving structured information from unstructured documents. It usually involves drawing information out of human-language text through the use of natural language processing.
Inside-Outside-Beginning (IOB)
IOB is a common way to format tags in chunking tasks like named entity recognition. In this system, each word is tagged to indicate whether it is the beginning of a chunk, inside a chunk, or outside a chunk. IOB2 is also a commonly used format, which differs slightly in its use of the ‘B’ tag.
Keyphrase Tagging
This task involves finding and labeling the words or phrases in a text that are most relevant to its subjectIt’s particularly important for those building text mining or information retrieval algorithms.
Named Entity Recognition (NER)
Often used as a synonym for entity extraction, NER involves tagging words or phrases with their semantic meaning, such as ‘Person’ or ‘Product’. These semantic categories are usually laid out in project guidelines.
Precision
This quality metric assesses how many relevant examples are found in an algorithm’s results. For example, if an algorithm returns 10 examples of ‘Person’ entities but only seven are correct, the algorithm’s precision would be 7/10. High precision means that a program returns more relevant results than irrelevant ones.
Recall
Recall measures the number of correct results a program identifies from the total number of correct results. For example, if there are 20 ‘Company’ entities in a text and the algorithm finds 10, its recall is 10/20, or ½. High recall means that an algorithm is able to return most of the correct results.
Semantic Annotation
This is the process of labeling texts with additional information so that machines can understand them. It’s also known as semantic tagging or semantic enrichment. Entity extraction is just one of the methods used to add this information to text segments.
Standoff Format
This is a popular method of formatting entity extraction data which only displays the entities that are found in the text, as opposed to the entire text. It uses a combination of codes to indicate where the entity can be found in the original text.
Entity extraction is one of the building blocks of natural language understanding. By adding structure to text, it paves the way for a whole host of more complex NLP tasks — as well as being an end goal in itself.
Through entity extraction, it’s possible to start summarizing texts, locate mentions of particular entities across multiple documents, and identifying the most important entities in a text. These have a wide variety of business use cases, from improving search and product recommendations to automating customer support processes.
Whether you’re looking to build your own entity extractor or outsource the project to a trusted partner, there are a huge number of pitfalls to navigate as you build the best possible machine-learning model. One of the biggest is the need for clean, focused training data. Regardless of your level of involvement in building your entity extractor, a quality dataset will provide it with some near-perfect examples of how to do the task you’re looking for. It’s crucial to get them right.
For every stage of an annotation project, there are some common mistakes which prevent people from achieving their desired ROI. Below, we’ll outline these mistakes, how to avoid them, and how to ensure that the resulting dataset will help you to build a great entity extractor.
For every project, it’s crucial to have clear guidelines. At the start of a project, it’s essential to build out a comprehensive document that clarifies exactly what you expect from the tagging process and gives clear instructions to your annotators. The development of these guidelines centers on two things: the classification system and best practices for annotation.
When you establish your classification system, the main focus should be on understanding exactly what all of the labels in the system mean on both a macro and micro level. It’s crucial to understand what each category and sub-category contains. For example, in many cases hotels are tagged as companies, but in certain industries, such as travel, they’re often tagged as locations. You should also outline any specific tagging requests in detail. When tagging dates, it’s important to know if the category should be restricted to phrases like ‘August 17th’, or whether ‘tomorrow’ or ‘the 17th’ should be included. While the goal is to cover as many of these things as possible beforehand, it’s inevitable that your guidelines will continue to grow throughout the project as your annotators encounter fresh edge cases.
The second half of the guidelines deals with all of the ways in which you expect tagging to be completed. This goes far beyond knowing how many tiers the classification system will stretch to. To work effectively, your annotators will need to know how to deal with a range of potential issues, such as punctuation, nicknames, symbols, spelling errors, and junk data which falls outside of all categories. It’s also important to give them an idea of the density of annotated entities within each raw text sample.
Annotation initially sounds rather straightforward. At a high level, an annotator should read each raw text sample, highlight certain words or phrases and add an appropriate label using a text annotation tool. However, you have to work extremely carefully to avoid common errors which could compromise your dataset.
It’s commonly forgotten that entity annotation isn’t just a language exercise, but also a cultural exercise. This can manifest itself in unusual ways. To give just one narrow example, many projects require that names are only tagged when they refer to a person entity. In this case, Walt Disney and Snow White should be tagged, but Mickey Mouse should not, since he isn’t human.
Further to this, words have an awkward habit of changing categories, often within the same paragraph. This can often be seen in the names of institutions, such as Bank of Japan. On its own, Japan should be tagged as a location, but as part of this phrase it should be tagged as an organization. This issue is even more apparent in the Japanese translation, where the word for Japan — 日本 — is actually contained within the compound name of the company — 日本銀行. As a result, annotators have to be alive to changes in language use, subject and nuance within a piece of text to ensure that every data point is attached to an appropriate label.
If you have a team of multiple annotators working on your dataset, it can be even more taxing to annotate well. If this is the case, it’s important to put processes in place that enable constant communication and the rapid resolution of any questions from your team of annotators. For example, online forms that allow annotators to quickly and easily submit questions can be a massive help. If it’s within your scope, a project manager can also be invaluable in monitoring submissions, identifying irregularities and providing feedback.
Fortunately, entity extraction is pretty objective when it comes to quality. Inter-reliability checks can be useful in determining whether your team of annotators has correctly understood the task. However, since entity extraction is not as subjective as other data annotation tasks, there shouldn’t be as much need to compensate for a variety of approaches to the initial raw data.
Once all the relevant entities have been identified and labeled, it’s time to format the data. There are several possibilities here, but there are two particular methods of presenting the data that are worth mentioning.
IOB2 format, where IOB stands for inside-outside-beginning, is a method of tagging in which the annotations are attached directly to each word. It looks like this:

In this scenario, B indicates the beginning of the label, while I denotes that this word also falls inside the entity. Tagging with O means that the word falls outside of any entity labeling needs. The key advantage of this method is that it includes the entire text, regardless of whether the word is part of an entity.
Sometimes, entity extraction results are provided in JSON format so that the information is more easily processed by other systems. In JSON, this information is provided in a similar way to IOB2:

Standoff format is most prominently used on the popular text annotation tool BRAT. It differs from IOB2 format in that it only shows the entities which have been tagged. The text and annotations are often split into two separate documents. This makes the files look rather different:

Here, T indicates the entity number, while the three-letter code explains which type of entity it is: in our case, names, locations, and companies. The two numbers indicate which character numbers the entity can be found between. Finally, on the far right is the entity as it appears in the data. One benefit of this format is that it gives you a simple list of entities to work with, making your data more streamlined and easy to work with.
Once the data has been correctly formatted, it’s ready to be used for training your machine learning model.
Entity extraction may not be as glamorous as some of the more famous machine learning tasks, but it’s absolutely critical to the ability of machines to understand language. As the volume of new data available to us increases exponentially, the process that add structure to this chaotic avalanche of noise will be more valuable than ever.
Whether it’s used as a preprocessing step or it’s the end goal in its own right, entity extraction is poised to play a huge role in the business world of the future. By improving machine understanding of language, it will ultimately make us more informed, effective workers — who are able to provide the stellar service our customers deserve.
Lionbridge AI is a provider of training data for machine learning. With a specialism in creating, cleaning, and annotating datasets for NLP use cases, we can help you to make that crucial first step towards a machine-learning model with confidence.
Contact us now to start building the custom dataset you’ve been looking for.
This article was written by Daniel Smith and originally published on: https://lionbridge.ai/articles/the-essential-guide-to-entity-extraction/
A Beginner’s Guide to Entity Extraction was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
