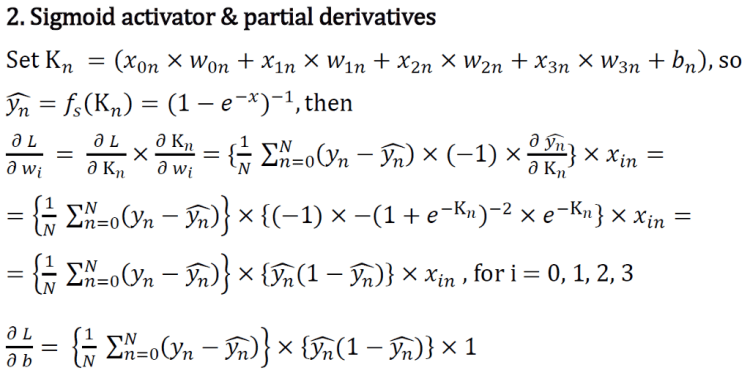365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Beginners of NN often intimidated by the tricky math and complex models at the first sight, so I'd like to share a fairlysimple toy example of NN on iris without leveraging any DL framework like PyTorch or Tensorflowfrom a book written by Japanese[1], and only by NumPy----that is, we need to create the loss functions, activators, and adjusting weights on our own.
Neuron is a minimum unit of neural network. A perceptron is a single-layer neural network. Let’s try to do a binary classification of iris by a perceptron.
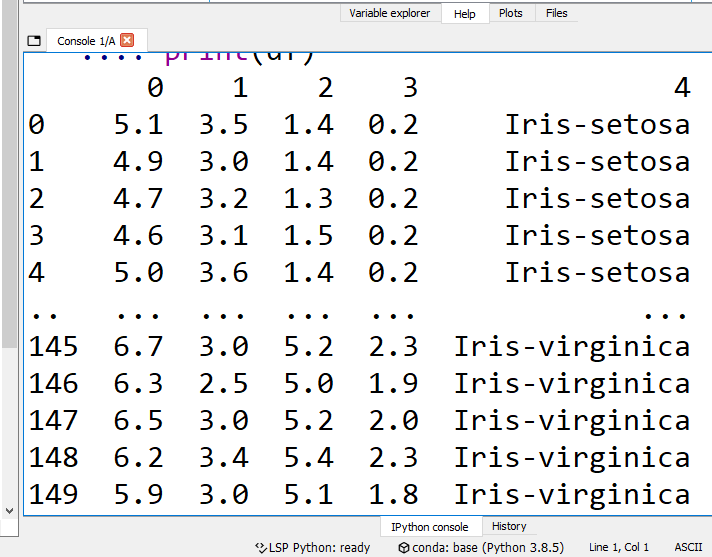
Row 1~50 are “Iris-setosa”, and row 51~100 are “Iris-virginica.” So we collect row 1~40 of and row 51~90 to be the training set, and the rest rows are testing set.
Figure 9: Testing result of epochs = 15Figure 10: Testing result of epochs = 100
If we set the decision boundary at 0.5, then we get 100% accuracy in both epochs = 15 & 100.
The first 10 predictions of epochs = 15 are between 0.46~0.49, while the first 10 predictions of epochs = 100 are between 0.23~0.30. The last 10 predictions of epochs = 15 are between 0.57~0.63, while the last 10 predictions of epochs = 100 are between 0.64~0.81. As epochs rises, values of the two flower group become more distance.
(8) Summary
Without anyNNframework, we built up a single-layer neural network ! We discovered concepts like activator(sigmoid), loss function(MSE), optimizer(gradient descend), weight updates(tiresome math work), initial weights(wi = b= 1), learning rate(eta= 1), epoch(tried epochs= 15 & 100).
(9) Reference
[1] Yoshida, T. & Ohata, S. (2018). Genba de Tsukaera! NumPy Data Shori Nyumon kikaigakushu| datascience de yakudatsu kosoku shorishuho. Japan, JP: SHOEISHA.
[2] Bre, F. et al(2020). An efficient metamodel-based method to carry out multi-objective building performance optimizations. Energy and Buildings, 206, (unknown).
[3] Subramanian, V. (2018). Deep Learning with PyTorch. Birmingham, UK: Packt Publishing.
No matter the field in which you hold some expertise, sharing your skills to benefit the lives of others or supporting non-profit organizations that try to make the world a better place is a noble and time-worthy personal pursuit. Many opportunities exist in data science to contribute to meaningful projects and crucial needs from your local community to a global scale.
This article compares the performance of the well-known pandas library with pypolars, a rising DataFrame library written in Rust. See how they compare.
Many data scientists have implemented machine or deep learning algorithms on static data or in batch, but what considerations must you make when building models for a streaming environment? In this post, we will discuss these considerations.
AdaBoost technique follows a decision tree model with a depth equal to one. AdaBoost is nothing but the forest of stumps rather than trees. AdaBoost works by putting more weight on difficult to classify instances and less on those already handled well. AdaBoost algorithm is developed to solve both classification and regression problem. Learn to build the algorithm from scratch here.
This article is like a concise concept map from ML to ANN to NLP, I wouldn't put attention on the complicated math behind ML, DL and NLP. Instead, I try to just run through all the concepts and leave the details to the readers.
For numeric targets, we have: — MSE — RMSE — MAPE For categorical targets, we have: — Accuracy — Precision — Recall — F1-score
1–5 Data splitting & cross-validation
— Three-way data splits: Splitting the datasets into three parts — training, validation and test datasets. It’s stricter than and have better performance than the two-way data splits—only splitting the datasets into training and test datasets. Three-way data splits is also called “splitting data machine learning validation”, this term strangely doesn’t have a unified name.
— K-fold cross-validation: Preventing overfitting and making the models more stable.
Figure 1: Three-way data splits [2]Figure 2: 4-fold cross validation & three-way data splits [2]
1–6 Data preprocessing and feature engineering
— Vectorization: A must-do process for data of formats like text, sound, image and video. — Handling missing values: Deleting or imputing them. I wrote a very detailed article on missing value imputation a month ago on my medium blog [1], concluding that:
1. In general, the complex ways of missing value imputation (random forest, Bayesian linear regression and so on) won’t perform worse than the simple ways like just imputing mean or median, contradicting to famous and popular some ML books. 2. Theoretically, random forest boasts better speed than kNN with similar accuracy, contradicting to famous and popular some ML books. 3. Bayesian linear regression (BayesianRidge in Python) and random forest model (ExtraTreesRegressor in Python) probably have the best performances in accuracy than other models.
1–7 Overfitting and underfitting
— Getting more data — Reducing the size of the network (i.e. reducing the complexity of ML models) — Apply weight regularization — Dropout (only for ANN models, not suitable for SVM, RF and so forth) — Underfitting
1–8 Workflow of a ML project
— Problem definition and dataset creation — Measures of success — Evaluation protocol — Data preparation — Baseline model — Large enough to overfit — Apply regularization — Learning rate picking strategies
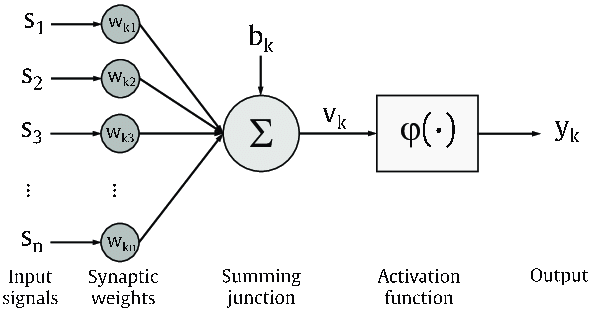
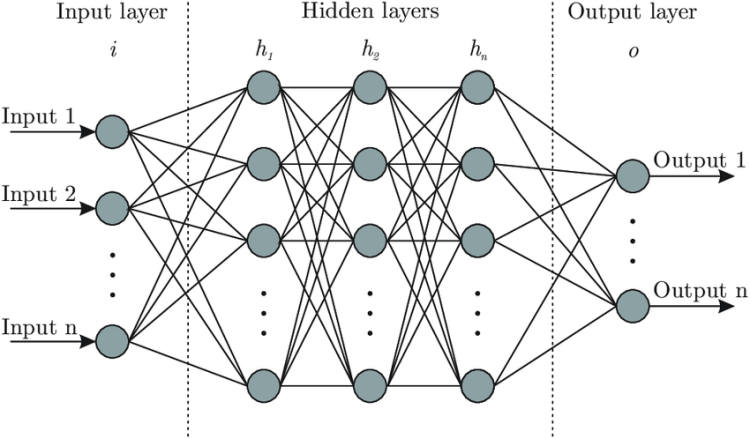
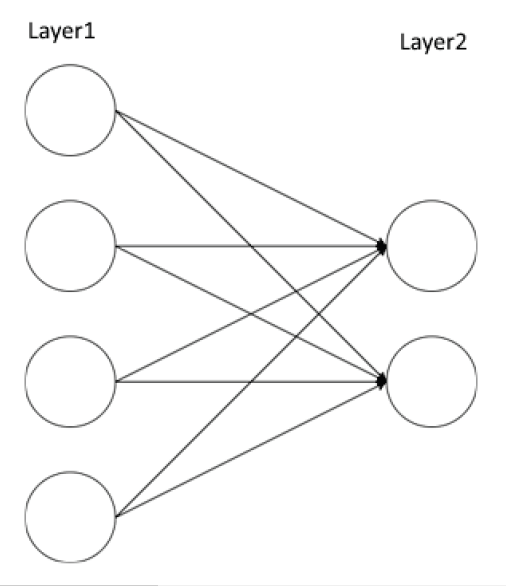
Figure 3: Visualization of a perceptron [3]Figure 4: Visualization of a neural network [3]Figure 5: Low-level operations and DL algorithm [2]
As we can see, there are a few main concepts of NN — — weights, activation function (in a perceptron), loss function, optimizer, weight updates. So, let’s probe into these concepts.
2–2 Activation functions
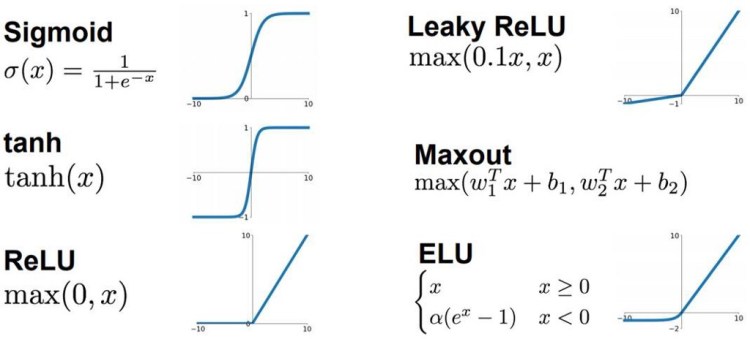
— Sigmoid — Tanh — ReLU — PReLU (leaky ReLU is a kind of PReLU): Eliminate the “dying ReLU” in ReLU. — Softmax: Useful for classification.
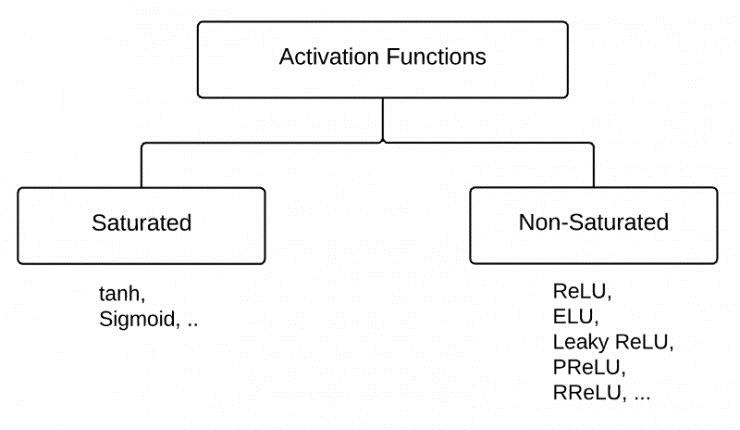
Figure 6: Relation between PReLU & leaky ReLU [4]Figure 7: Plots of common activation functions [5]Figure 8: Saturated & non-saturated activator [6]
2–3 Loss functions
— L1 loss — MSE loss — Cross-entropy loss: for classification — NLL loss — NLL loss2d
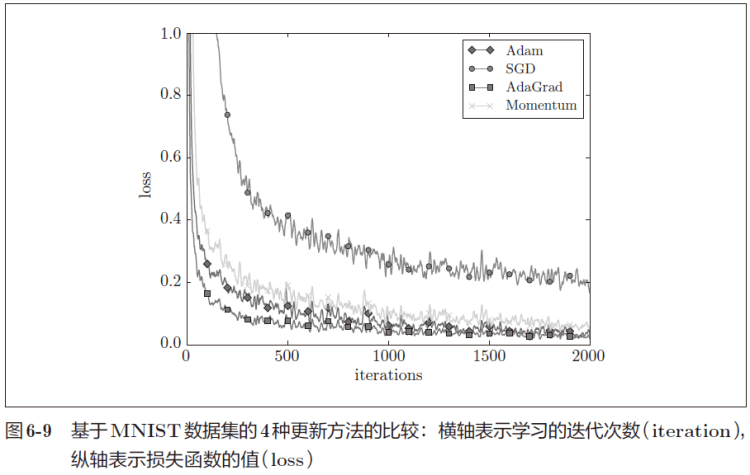
Figure 9: Optimizers comparison: SGD, Momentum, AdaGrad, Adam [7]Figure 10: Optimizers comparison on MNIST: SGD, Momentum, AdaGrad, Adam [7]
In general, Adam > AdaGrad > Momentum > SGD (> represents “better than”), but in the preceding MNIST case, AdaGrad > Adam > Momentum > SGD. For most of the use cases, an Adam or RMSprop optimization algorithm works better.
2–5 Batch learning
— Mini-batch: Close to the concept of bootstrap.
2–6 Batch normalization
Normalization is an essential procedure for NN.
2–7 Dropout
Significant for avoiding overfitting.
2–8 Hyper-parameter
Tuning parameters like: — Amount of perceptron of each layer — Batch size — Learning rate — Weight decay
2–9 Data splitting & cross-validation
Better to adopt three-way data splits & k-fold cross-validation.
(3) Neural Network Models
3–1 Perceptron
Neuron is a minimum unit of neural network. A perceptron is a single-layer neural network.
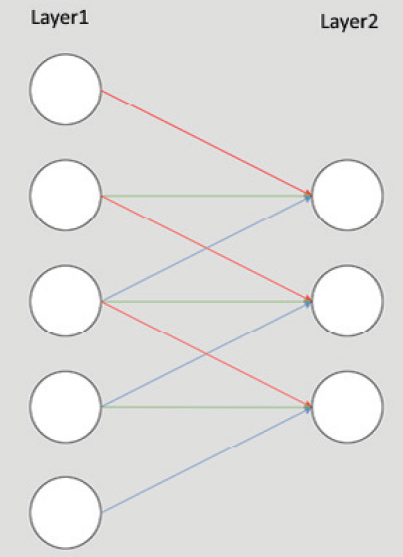
3–2 FNN
Feedforward neural network (FNN), an artificial neural network wherein connections between the nodes do not form a cycle.
3–3 MLP
A multilayer perceptron (MLP) is a class of feedforward ANN.
3–4 CNN
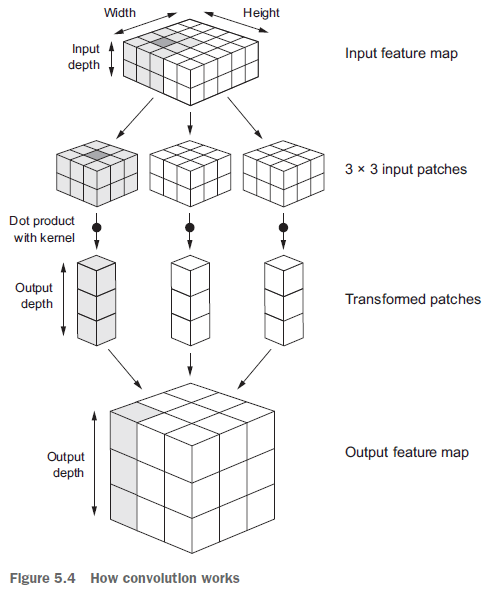
CNN, convolutional neural network, is one kind of FNN. Fully connected layer (or linear layer) is too complex and loses all spatial information, whereas CNN avoid the preceding issues and leverage convolution layers and pooling layers to yield outstanding real-world outcomes in computer vision.
CNN has two major merits in computer visions: [8] — Translation invariant — Spatial hierarchies of patterns
NLP (natural language processing) had developed before ANN (artificial neural network) was feasible, though not until ANN was added into NLP did it prosper. The classic NLP book “Natural Language Processing with Python” [11] , published in 2009, only elaborate the statistical language modeling without mentioning any ANN methods.
4–1 Data Pre-processing
Converting text into matrix before going into NN: — Use contraction dictionary — Tokenization — Deleting stopwords — Stemming
4–2 BOW approaches
Then, we could treat the text as Bag-of-words (BOW) and do vectorization, either one-hot encoding or word embedding.
One-hot encoding: A traditional NLP approach usually used with TF-IDF. Data is too sparse here, facing the curse of dimensionality problem, and hence it’s rarely used with deep learning. Also, it often comes with n-gram model. Word embedding: Converting the data into dense matrix. Word2vec is a popular measure.
However, the BOW approaches lose the sequential nature of text. So, then we turn to RNN to make good use of the sequential nature of text. [2]
4–3 CNN
CNNs solves problems in computer vision by learning features from images. In images, CNNs works by convolving across height and width. In the same way, time can be treated as a convolutional feature. 1-D CNNs sometimes perform better than RNNs and are computationally cheaper. Another usage of CNN in NLP is text classification. [2]
4–4 RNN
Recurrent neural network (RNN), which is not FNN, aims to address sequential data. RNN can solve problems like natural language understanding, document classification, sentiment classification. RNN uses backpropagation through time (BPTT) instead of backpropagation (BP). [11]
Figure 14: A simple RNN [8]
The simple version of RNN, in practice, finds it difficult to remember the contexts that happened in the earlier parts of sequence. LSTMs and other different variants of RNN solve this problem by adding different neural networks inside the LSTM which later decides how much, or what data to remember. [2]
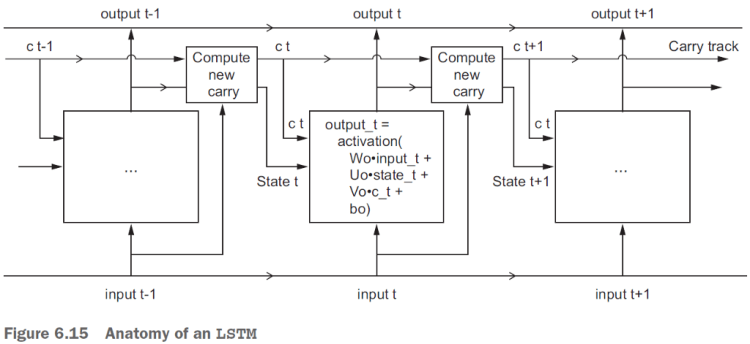
4–5 LSTM
Long short term memory networks (LSTM) is a kind of RNN, capable of learning long-term dependency. The simple RNN has problems like vanishing gradients and gradient explosionwhen addressing large sequence. LSTMs are designed to avoid long-term dependency problems by having a design by which is natural to remember information for a long period of time. [2]
[1] Kuo, M. (2020)。ML02: 初探遺失值(missing value)處理。取自 https://merscliche.medium.com/ml02-na-f2072615158e [2] Subramanian, V. (2018). Deep Learning with PyTorch. Birmingham, UK: Packt Publishing. [3] Bre, F. et al (2020). An efficient metamodel-based method to carry out multi-objective building performance optimizations. Energy and Buildings, 206, (unknown). [4] Guo, H. (2017). How do I implement the PReLU on Tensorflow?. Retrieved from https://www.quora.com/How-do-I-implement-the-PReLU-on-Tensorflow [5] Endicott, S. (2017). Game Applications of Deep Neural Networks. Retrieved from https://bit.ly/2G8nUIQ [6] Taposh Dutta-Roy (2017). Medical Image Analysis with Deep Learning — II. Retrieved from https://medium.com/@taposhdr/medical-image-analysis-with-deep-learning-ii-166532e964e6 [7] 斎藤康毅 (2016). ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装 (中譯:Deep Learning:用Python進行深度學習的基礎理論實作). Japan, JP: O’Reilly Japan. [8] Chollet, F. (2018) Deep learning with Python. New York, NY: Manning Publications. [9] 邢夢來等人 (2018)。PyTorch 深度學習與自然語言處理。新北市,台灣:博碩文化。 [10] Bird, S. et al (2009). Natural Language Processing with Python. California, CA: O’Reilly Media. [11] Rao, D., & McMahan, B. (2019). Natural Language Processing with PyTorch. California, CA: O’Reilly Media. [12] Ganegedara, T. (2018). Natural Language Processing with TensorFlow. Birmingham, UK: Packt Publishing.
A recent survey by Gartner predicts, “By 2021, 40% of new enterprise applications implemented by service providers will include AI technologies.”
The world of business is undergoing a massive change owing to the rapid emergence of artificial intelligence (AI) for enterprise applications. Indeed, artificial intelligence has the power to solve several organizational problems as it offers functionalities that humans cannot practically perform at the same rate and accuracy.
AI has quickly changed status from a “technology to experiment” to a “technology to deploy.” By 2025, most enterprises will be using AI-enabled apps to gain a competitive edge from streamline operations, more incredible product innovation, and improved customer satisfaction.
Machine Learning Jobs
Drivers of this shift include an unprecedented growth of enterprise data, advances in machine learning (ML), natural language processing (NLP) capabilities and the need to accelerate digital transformation journey.
Below, we present you with the latest insights into how AI is transforming enterprise software apps.
A Glimpse At AI For Enterprise Applications
1. Embracing conversational AI to simplify data analytics consumption
AI-enabled virtual assistants, leverage the NLP technology to converse with users in natural language. By merely initiating a chat on the enterprise messaging app, and sending simple messages like “What is the sales of product A for 2017?”, employees and business leaders can procure in-depth insights in the most granular form of data, without switching between multiple tools and dashboards. Users need not manually filter data to analyze information and arrive at crucial decisions.
This, AI is transforming the consumption of business intelligence and analytics, especially for on-field employees (for example, sales agents) or CxOs, who need quick access to information without having to dig through heaps of data.
2. Securing Every Aspect of Enterprise IT through AI
With the rise of remote working across the globe and as IT decision-making becomes more democratic, enterprises cannot ignore the increased threat of cyber attacks.
To combat the threat and secure every aspect of the IT infrastructure, organizations are scrambling to deploy applications that integrate machine learning to detect possible threats and vulnerabilities in real-time.
These tools use ML techniques to spot anomalies in network traffic, emails and user activities. Hence, they can quickly identify a potential attack and take steps to mitigate it, even if the threat is unlike anything the organization has witnessed before.
3. Transforming IT through AIOps
AIOps, an emerging variation of DevOps, uses machine learning (ML) algorithms on IT operative data to derive insights that optimize and improve operations.
While DevOps automates and simplifies IT operations, AIOps goes a step further by extracting information that is useful in overseeing IT activities.
Sometimes, it can automatically take requisite action based on such insights, thus enabling IT personnel to supervise larger IT environments than otherwise possible.
Modern intranets, equipped with AI technologies, serve the following purposes –
Cognitive enterprise search: Cognitive enterprise search is an AI-enabled smart search tool that connects all the internal and external enterprise systems, thus acting as a one-stop-search engine for enterprise-wide knowledge and information It understands natural language phrases and enables shows personalized search results based on the users’ roles, locations, interests and past search activities
Automated metadata management: Enterprises can use AI bots to automate metadata generation, data-tagging, classification, and organization and generate good-quality taxonomy recommendations. As a result, organizations can illuminate and maximize the value of unstructured data
Personalized employee experiences: AI empowers the intranet to break the clutter and deliver personalized content recommendations to the users, based on their interests, locations, and job profiles
Improved collaboration: AI analyzes the user’s persona to suggest the right subject-matter experts to connect with within the organization; thus fostering a collaborative workplace culture
AI-powered analytics: AI-powered analytics help in harnessing and analyzing intranet users’ data. This provides insights into how employees across departments are engaging with the intranet.
5. Combining AI with CRM
The benefits of integrating AI into your customer relationship management are manifold. Here are a few reasons to start contemplating an AI-driven CRM software –
Prediction of future customer behavior: Artificial intelligence can draw learnings from the customers’ past decisions and historical engagement to generate valuable sales. Moreover, AI can analyze customers’ sentiments, to predict their future behavior
Automated segmentation: AI segments customers automatically into groups with similar characteristics and ensures your messages reach the right audience at the right time
Price optimization: AI can analyze past client data to predict the ideal discount rate and pricing that is most likely to lock the sales deal
6. Optimizing Supply Chain Management Through AI
Several enterprises are investing in AI-powered supply chain management apps. Such applications help improve just-in-time deliveries, anticipate potential issues, reduce costs, and recover from supply disruptions.
By leveraging AI-powered analytics, businesses can generate valuable recommendations and forecasts to build a resilient supply chain. Some of these scenarios include — demand forecasting, stock visibility, detecting out-of-stock situations, and supplier risk analysis.
Speaking volumes about the utility of these apps, a study by Mckinsey has found, “among organizations that were using AI for supply chain management, 61% experienced cost decreases, and 63% saw revenue increases.”
7. Simplifying Vendor Billing through AI
AI is capable of simplifying financial operations within the enterprise.
Moving a step ahead from traditional Optical Character Recognition (OCR) systems that extract data from templated documents, an AI-embedded invoice management software can look at any document and extract all the critical information.
For example, by just feeding the software with invoices from different vendors, AI can figure out who the invoice is from, the due date, the amount to be paid, etc., without any human intervention.
Get Started
AI is and will continue playing a significant role in transforming enterprise software applications. As seen above, one cannot deny the essential role of AI-enabled apps in driving improvements in quality, speed, and efficiency within organizations. While it can be overwhelming for organizations to transform their operations and systems overnight, beginning the AI journey with low-hanging fruits can be a good start. Via Botcore.ai
Lift the curse of dimensionality by mastering the application of three important techniques that will help you reduce the dimensionality of your data, even if it is not linearly separable.