365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Data professionals are invited to share their massive data challenges from their own unique perspectives. Learn more about the Massive Data Revolution Video Challenge, your chance at a $50 Amazon gift card, and be sure to submit your entry by December 16th.
Figure 1. Hate Speech Illustration. Source: istock.com
Chances are that you have been involved in a situation of violence against women and you didn’t even notice it. You could have been the victim or you could have been the victimizer and, again, you didn’t notice it.
How is it possible to be the victim or victimizer without being aware of it? Violence against women takes different forms and one of the most common manifestations seems to be so normalized that it unconsciously comes up in our daily life: verbal violence.
We materialize verbal violence in our daily speech and, nowadays, one part of our daily speech has moved to social media. For this reason, we need effective methods to detect this hate speech that takes place online.
In this article, we explain how we used Natural Language Processing (NLP) techniques to detect online gender-based hate speech in Mexican Spanish.
We call this project Violentómetro Online. It was the result of the work we did as part of the Social Data Challenge contest, powered by Datalab Community in Guadalajara, México. With this effort, we won the 3rd place of the contest.
In this section, we problematize the gender violence and online violence topics. We also present some theory that helps to better understand the phenomenon.
Gender Violence
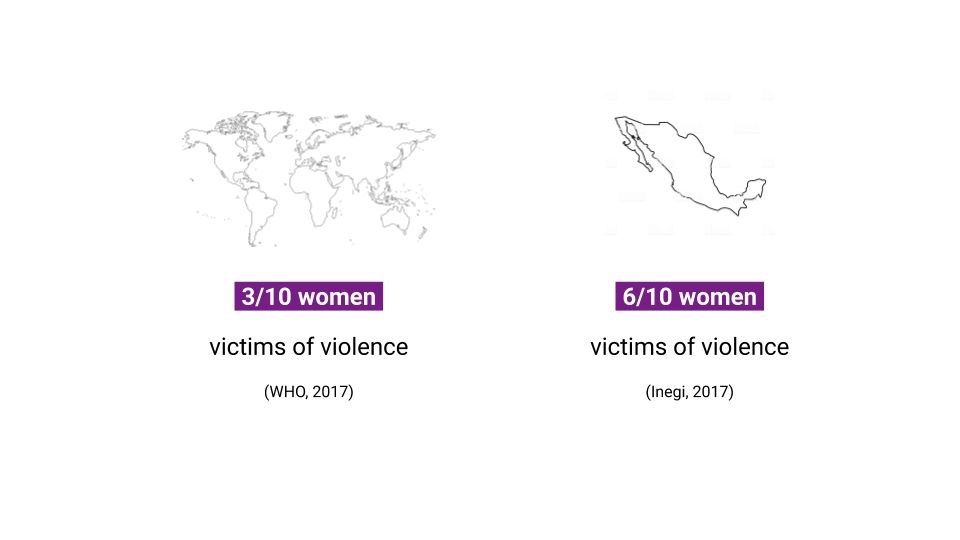
Worldwide, three out of 10 women have suffered any type of violence (WHO, 2017). The situation in Mexico is more critical. From the 46.5 million Mexican women aged 15 and over, six out of 10 (30.7 million) have faced any type of violence at some point in their lives (INEGI, 2017, p. 1 ).
Figure 2. Gender Violence Statistics
Violence against women gets materialized in different ways (INEGI, 2017):
● Emotional
● Physical
● Sexual
● Economic
● Discrimination
● Verbal
To differentiate gender-based violence from other forms of violence, we have to pay attention to the cause. In these cases, there is no other motivation for such abuse than gender. These are women who have been abused in public or private life and there is no other crime (like robbery or drug trafficking) involved as a detonator (WHO, 2017).
Nowadays, hate speech has moved to new forums because of the proliferation of information and communication technologies. Currently, it is necessary to talk about “online violence”, which can go unnoticed from a screen (Ruiz, 2014).
Big Data Jobs
The Internet itself stimulates aggressiveness and creates an environment in which even non-aggressive people can have aggressive behaviors in their interactions (Bañón Hernández, 2010). This is because the media in the Internet have properties related to:
● Anonymity: Provides a hidden identity to the victimizer.
● Distance: Makes the victim invisible.
● Ubiquity: Provides a greater exposure and availability to hate speech.
● Disinhibition: Establishes absence of regulations for content.
In this project, we aimed to develop an effective method to automatically detect online gender-based hate speech in Spanish. To achieve this goal, we worked within the field of Machine Learning and took advantage of Natural Language Processing techniques.
In this section, we describe the tools and data we used in our project. We also report the cleaning and preprocessing methods we applied to better process our data. We explain how we executed the experiments using different Machine Learning models and parameters, and how we obtained the best model. Finally, we present the web application prototype we developed to make Violentómetro Online a user-friendly product.
Tools
The following are the tools we used to obtain, preprocess, analyze, and model the data, as well as to develop the web application prototype:
Python: To develop the code for the data processing and for the web application development. We used the following libraries:
Previous to the Social Data Challenge, one member of our team gathered this dataset using the Facebook API. It was obtained from comments published in news’ posts related to International Women’s Day in the week of March 6 to 13, 2018. The news were published on the Facebook accounts of the following media:
We manually tagged the dataset to identify specific hate speech against women. The dataset ended up with the following characteristics:
1, 968 records
2 columns
2 categories:
1 = Contains hate speech against women
0 = Does not contain hate speech against women
Figure 4. Facebook Comments Dataset
Train Aggressiveness
MEX-A3T: Fake News and Aggressiveness Analysis is an event organized by the NLP community in Mexico to detect fake news and text with hate speech. The researchers that organize this event shared the training dataset with us. The dataset has the following characteristics:
7 mil 332 records
2 columns
2 categories:
1 = Contains general hate speech
0 = Does not contain general hate speech
Figure 5. Train Aggressiveness Dataset
Final Dataset
To perform the experiments, we joined the two datasets described before. The Facebook Comments dataset was modified so that category 1 was replaced by 2 (hate speech against women). We also performed some feature engineering and added more columns (for more details, see the Preprocessing section). The final dataset resulted in the following characteristics:
9,300 records
5 columns
3 categories:
2 = Contains hate speech against women
1 = Contains general hate speech
0 = Does not contain any type of hate speech
Figure 6. Final Dataset
Preprocessing
We performed some preprocessing with both cleaning and feature engineering techniques. The cleaning techniques were useful to prepare the dataset for the analysis, whereas the feature engineering techniques were useful to improve the performance of our model. The preprocessing included the following actions:
Table 1. Cleaning and Feature Engineering Techniques Used in this Project
Exploratory Data Analysis
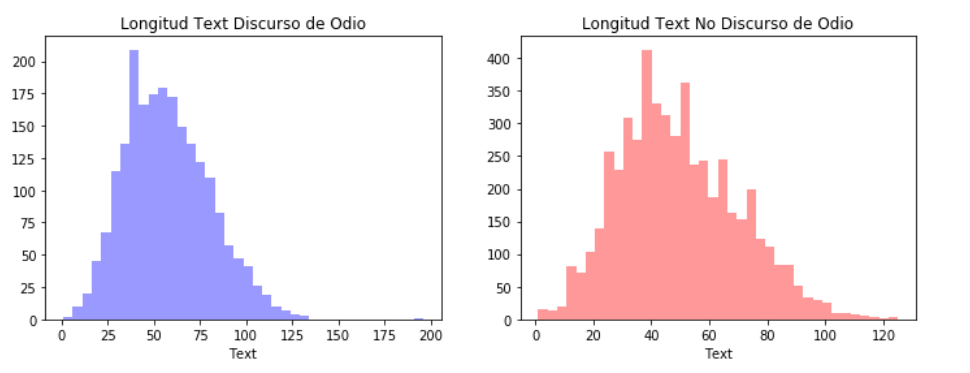
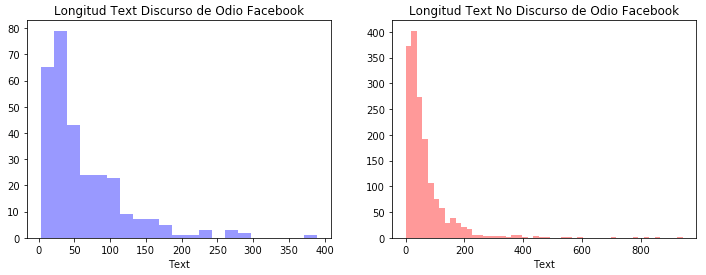
Using basic tools of statistics, we performed an exploratory data analysis (EDA) to inspect the composition of the two original datasets we are using. We examined characteristics such as the length of the messages (records), the quantity of words in general, and the quantity of unique words.
The EDA shows that the distributions of the Train Aggressiveness dataset and the Facebook Comments dataset are different. For example, the distribution of the length of the comments is different according to the platform in which they were published. Comments on Facebook tend to be larger than tweets and the use of words tend to be different.
Figure 6. Distribution of the Train Aggressiveness DatasetFigure 7. Distribution of the Facebook Comments Dataset
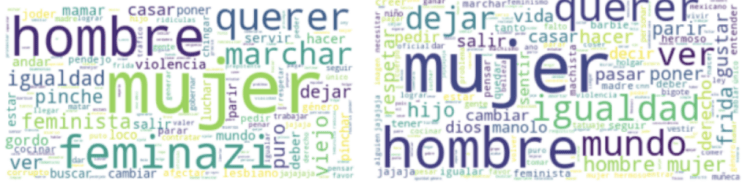
Regarding the type of words, in the Train Aggressiveness dataset, we could notice that the content was similar for both hate speech and no hate speech categories.
We noticed that these similarities occur because one message can contain single words related to vulgarity or obscenity, but in its complete structure, it is not hate speech given that it does not attack a specific group or individual. On the other hand, there are also messages that contain single words related to vulgarity or obscenity, and it does attack a specific group or individual. These similarities made it challenging for our algorithms to classify.
The following word clouds show how similar are the most frequent words of the Train Aggressiveness dataset in both hate speech and no hate speech categories.
Figure 8. Word Clouds Showing the Most Frequent Words of the Train Aggressiveness Dataset
In the Facebook Comments dataset, the content has more variations for both hate speech and no hate speech categories. In the first one, among the most frequent words appear terms with negative connotations such as “feminazi” and “pinche”. Whereas in the second one, among the most frequent words appear terms related to gender equality discussions such as “igualdad” and “derecho”.
The following word clouds show the most frequent words of the Facebook Comments dataset in both hate speech and no hate speech categories.
Figure 9. Word Clouds Showing the Most Frequent Words of the Facebook Comments Dataset
Experiments
In order to develop an effective method to automatically detect online gender-based hate speech in Mexican Spanish, we executed the following experiments:
Creation of base models to see which presented the best performance and improve it. We used Logistic Regression, Naive Bayes, and Random Forest as base models. The following table shows the score results we got with this experiment:
Table 2. Results Experimenting with Different Algorithms
Model training using Random Forest with n-grams ranging from 1 to 3. The following table shows the score results we got with this experiment:
Table 3. Results Experimenting with N-Grams
Model training using Random Forest with additional features: Length_Text, Number_Words_Text, and Number_Unique_Words. The following table shows the score results we got with this experiment:
Table 4. Results Experimenting with Additional Features
Use of the RandomizedSearchCV technique to find the best parameters in Random Forest, using n-grams and the additional features. The following table shows the score results we got with this experiment:
Table 5. Results Experimenting with Additional Features and Best Parameters
Results
With all the experiments, the best result we got was 0.83 of F1 Score, Precision, and Recall. The model with the best score has the following characteristics:
Algorithm: Random Forest
Preprocessing technique: Bag of words
New features: Length_Text, Number_Words_Text, and Number_Unique_Words
Parameters tuning: According to the best parameters that RandomizedSearchCV found
Prototype of a Web Application
Besides, we developed a prototype of a web application with the model that showed the best results. We used the Streamlit framework to develop the web application and GitHub Actions to deploy it (with continuous integration) on Heroku.
In this app, any user can enter a piece of text, then the algorithm analyzes if the text contains general hate speech and hate speech against women, and it provides an output to the user with the following categories:
2 = Contains hate speech against women
1 = Contains general hate speech
0 = Does not contain any type of hate speech
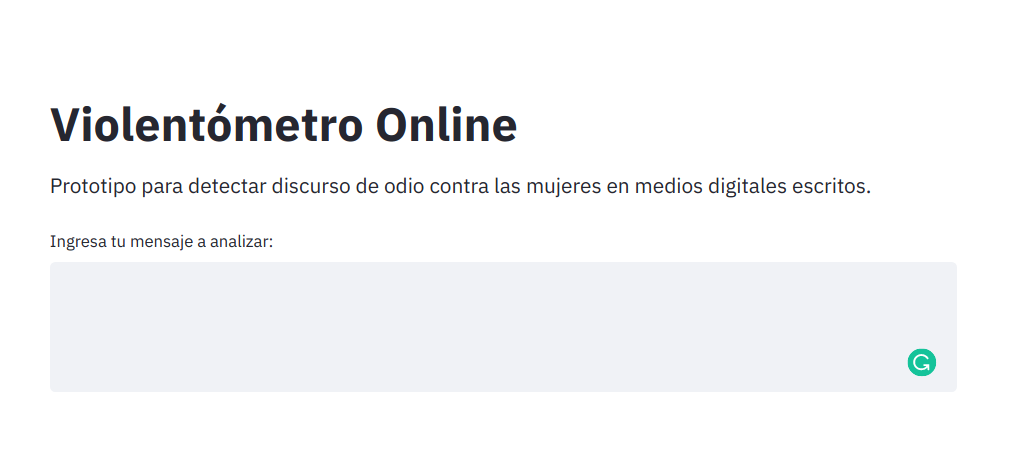
The following image shows a screenshot of the application prototype:
Figure 10. Web Application Prototype of the Violentómetro Online
Our main goal was to develop an effective method to automatically detect online gender-based hate speech in Mexican Spanish. With this project, we were able to develop a method of detection by using Natural Language Processing techniques and by experimenting with Machine Learning models for classification. Besides, we were able to deploy our best model in a web application. However, we still need to validate the effectiveness of both, the model and the web application.
At this point, we only used open-source tools to develop our solution. We have some extra experiments pending, these require more computing capacity but might improve the performance of our model.
Also, there are open possibilities to test this solution with other Spanish variations different from Mexican.
For future work, it is possible to escalate our solution and to add more features to it, given the code quality and its organization. We have set as future steps to move from bag-of-words to more advanced techniques such as Deep Learning.
In addition, the model can be hosted independently to take advantage of the storage capacity. With extra storage, we would like to gather feedback from the users to improve our model and application.
Finally, we decided to approach the topic of gender-based violence with Natural Language Processing because we believe that the discipline of Data Science has the capacity to be a detonator of great solutions for social problems. We are convinced that detection is the first step to prevent any type of violence.
To see the code, experiments, and results of this project, visit this GitHub repository: violentometro-online.
How AI / ML is pioneering a new wave of innovation in the sales org
Digital transformation is accelerating across companies and data has become the number one asset as teams look for competitive advantages, growth avenues, or cost-cutting opportunities. This is permeating throughout organizations and impacting how leaders manage business units and prioritize strategic initiatives, buying decisions, and human capital. Coinciding with this growing data-driven mentality is the adoption of artificial intelligence, which is enabling software applications to learn from, act on, and disseminate information created by businesses’ customers and employees. The combination of these two trends are key drivers in implementing and adopting intelligent software — data provides the fuel and the machine intelligence provide the outsized value. As a result, teams are leveraging these solutions to augment their capabilities, leading to better outcomes and rapid growth ??
These intelligent products have historically been categorized / built for technical data science and development roles, but in the past several years, we have seen a democratization of these tools to more business-centric departments, particularly sales organizations. Sales has long been talked about as one of the most relevant roles that could benefit from AI / Automation given the manual, data-oriented nature of the job. Sales reps have been burdened with prospecting leads in ZoomInfo, transcribing spreadsheet information manually into their system of record, leveraging Outreach to customize follow-ups and scheduling, and building out pipeline / forecast approximating with non-functional software (excel) — all leading to the majority of their time not actually focused on selling. Sales managers have been left to guess the likelihood of revenue targets being met, where to best allocate their time, or how to best align their respective teams.
As organizations generate increasing amounts of data, sales teams are beginning to see the benefits of being able to aggregate, govern and leverage this information for insights into both past and future sales efforts, helping them better understand customer needs and their own strengths and weaknesses. A large part of this can be attributed to the integration of intelligent sales technologies into critical workflows across the entire selling process, increasing efficiency and ultimately, allowing members to spend more time on selling. Sales reps are able to better understand when and how to best communicate with customers, learn in real-time what to say to increase the likelihood of closing prospects, and access relevant information to equip them with the right tools for the entire customer journey. Sales managers now have the opportunity to repeatedly build sales pipelines and forecast team’s deals, monitor rep performance and areas of improvement, and optimize sales playbooks to coach with data rather than emotion.
As a result, we are starting to see a new set of tools — the Intelligent Sales Stack — used by sales teams to acquire and retain customers as well as manage forecasts and commissions. Each layer in the stack is dependent on the other and all require deep integration to maximize the ability to understand customer preferences, sentiment, and actions. This is not an entirely new category — the CRM is still the single source of truth for customer interactions. However, this category has emerged as teams become more data-driven and look to segment the selling process into several disparate key actions.
Intelligent Sales StackBig Data Jobs
Key Tailwinds Driving Sales Innovation
1) Explosion of SaaS Applications ???
One of the biggest trends we’ve seen over the past few years has been the number of software applications available to knowledge workers. Through the combination of a shift from on-premise to cloud and decreasing barriers to entry, it has never been easier, quicker, or cheaper to create and launch a SaaS product. Because of the ubiquity of these applications, organizations can buy products for very niche aspects of their business. Rather than choose a specific platform that covers all essential functions, teams are now moving towards a best-of-breed model to uniquely address and augment every aspect of their respective function.
2) Democratization of Buying Power ???
As mentioned in past posts, there has been a shift in the buying power at most organizations from the CIO level down to the individual end user, where employees are able to sample, test, and discover which applications are best suited for their specific needs. In turn, CIOs now advise and empower business units rather than drive purchasing decisions. This has been driven partly by the abundance of applications mentioned above. However, a primary driver of this shift is that SaaS offerings enable a frictionless, affordable, product-led GTM strategy. This strategy significantly decreases the cost of ownership for these products, allowing users to easily switch from one to the other without having to get executive approval. Given the multi-faceted job of sales reps, this provides them with the ability to potentially have a unique application for evert aspect of their job, regardless of its relevance to other functions or even other sales reps!
3) Increased Reliance on Data ?
Like almost every other sector of business, sales organizations are embracing data. This increased reliance on data is driven from a rising level of trust in these software applications, the growing amount of data from general cloud adoption, and the continued benefits of data network effects. Sales organizations are charting a clear path forward by using data to identify and target the strongest industries, geographies, and accounts and to analyze and improve performance. According to the LinkedIn State of Sales Report, more than half of respondents say their companies are using data to assess the performance of salespeople and drive decisions across the sales org.
Drivers of Value
1) Dissemination of Best Practices
Training and ramping new sales hires costs money and takes time away from managers. Firing underperforming reps costs even more time and money while putting the company at a disadvantage by not operating at full capacity. By leveraging various intelligent sales tools like Gong and Otter, teams are able to record and analyze conversations with customers, capturing relevant and important data points from certain individuals that can be used to their advantage. For example, the actions of top performers can be taken and disseminated across the sales team to advocate best practices, teach new hires the proper tactics, and develop a playbook that gives reps an easy and understandable way to succeed. Additionally, sales engagement tools like Outreach not only give reps relevant and timely information, but also nudge them to act at times most critical to closing prospects. These solutions provide reps with information that spur best practices and allow new hires to ramp faster and more effectively.
2) Personalization is Expected not Rewarded
The consumerization of the enterprise is pushing customer expectations to all-time highs, and sales organizations are constantly trying to keep up. Enterprise prospects expect a personalized, consumer-like experience that reflects a deep understanding of their interests, problems, and future needs. As a result, teams are turning to more data-centric sales approaches, primarily driven by AI / ML, to promote cross-functional collaboration, surface and understand all relevant information, and coach them to be most effective. Intelligent software solutions provide behavioral, sales and profile data that can help deepen customer relationships, thus providing a better experience overall for customers and increasing their propensity to buy
3) Break Down Information Barriers
For these solutions to leverage intelligent applications or, at the very least, enable them, they need access to customer data generated from touchpoints across all customer-facing departments — marketing, sales, product, support, and customer success. However, as companies digitally transform, many times these organizations create unwanted data silos in each department that act as bottlenecks from getting the wholistic picture of the customer or opportunity. Fortunately, the emergence of sales enablement and revenue operations tools like Salesloft and Clari act as intermediaries or system connectors that allow various niche applications to speak to one another. They enable teams to communicate and, importantly, align across goals and timing, while automating various manual sales workflows in the process.
4) Realignment of Priorities / Focus Areas — Deeper not Wider
In the same way we’re seeing the rise of new roles including revenue operations, we’re also seeing a rise of new tools that take a narrow focus within the sales workflow. Part of this can be attributed to barriers of building software being lower than ever before, but it is mainly due to a shift from platform to best of breed mentioned earlier. Previously, teams were handicapped to a solution like Salesforce that was the central source of information, where automated workflows could be triggered in-app only. Now, because of enhanced API integrations and disparate workflow automation platforms like Tray.io or Workato, teams are able to turn to a best of breed approach where solutions are more customizable, flexible, and specific to a certain action without worrying about data quality or breadth of automations. Subsequently, knowledge workers are enabled to have a more quantifiable impact on their specific responsibilities without sacrificing information quality or productivity gains.
Sales involves a mix of creativity, hustle, and strategy — all areas that require human intelligence. However, as more companies digitally transform and vast amounts of relevant data are created daily, there becomes an obvious need for AI — primarily to better understand your end customer, know how to efficiently manage and identify prospects, and for more precise forecasting sales for upcoming quarters. We are seeing the continued adoption of AI / ML products in the sales department, a trend that we believe will only continue as teams realize the productivity gains and data network effects that come from relying on an Intelligent solution.
For a more in-depth overview of each category within the technology stack, view the full post here
There’s a lot of data out there and so many data science techniques to master or review. Check out these great project ideas from easy to advanced difficulty levels to develop new skills and strengthen your portfolio.
Also: Learn Deep Learning with this Free Course from Yann LeCun; Know-How to Learn Machine Learning Algorithms Effectively; 15 Exciting AI Project Ideas for Beginners; How to Get Into Data Science Without a Degree
Data science jobs are one of most sought after and in-demand jobs in the IT industry right now. In order to get into this field and get these data science jobs, certification is needed and that is widely discussed below.
TensorFlow provides a way to move a trained model to a production environment for deployment with minimal effort. In this article, we’ll use a pre-trained model, save it, and serve it using TensorFlow Serving.