Theoretical relevance of features must not be ignored.
Originally from KDnuggets https://ift.tt/3g48jtd

365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Originally from KDnuggets https://ift.tt/3g48jtd
Originally from KDnuggets https://ift.tt/2Rv27QX

Artificial Intelligence, machine learning and data science are transforming technology rapidly . It is revolutionizing every single bit and place- from education to healthcare, from government to automation, agriculture to security and surveillance, none of sectors remained untouched. The global pandemic has had a varying impact on different tech sectors, but for Artificial Intelligence, the demand for more experts and professionals in the industry is expected to boom.
Researchers, technologists and educators are constantly working so as to contribute to society and bring-in the positive impact. It is therefore appalling that little we know about the faces behind this startling technology.

There are many brilliant minds at the forefront of Artificial Intelligence. But the field of A.I. is far too male dominating and the despondent truth is only 12% of A.I. researchers are women. Although women are serving as role model, as an educator, researcher, professor, entrepreneur in the very best and inspiring way.
Let’s get inspired by some of the top women in Artificial Intelligence

Jana Eggers is a CEO of Nara Logics (naralogics.com), a neuroscience-based artificial intelligence company focused on turning big data into smart actions. She’s also an Owner at SureCruise.com and Marketing at Blackbaud. A math and computer nerd who took the business path, Jana has had a career that’s taken her from a three-person business to fifty-thousand-plus-person enterprises. She opened the European logistics software offices as part of American Airlines, dove into the internet in 1996 at Lycos, founded Intuit’s corporate Innovation Lab, helped define mass customization at Spreadshirt, and researched conducting polymers at Los Alamos National Laboratory.

Joy Buolamwini is a Ghanaian-American computer scientist and digital activist based at the MIT Media Lab. She founder of Algorithmic Justice League, an organisation that looks to challenge bias in decision making software. She uses art and research to illuminate the social implications of artificial intelligence. She serves on the Global Tech Panel convened by the vice president of European Commission to advise world leaders and technology executives on ways to reduce the harms of A.I.. Her MIT thesis methodology uncovered large racial and gender bias in AI services from companies like Microsoft, IBM, and Amazon. Her research has been covered in over 40 countries, and as a renowned international speaker she has championed the need for algorithmic justice at the World Economic Forum and the United Nations.

Shivon Zilis focuses on machine intelligence for good. She is the Project Director, Office of the CEO at Neuralink and Tesla, and an adviser to OpenAI. Previously she was a partner and founding member of Bloomberg Beta. Shivon is also a Founding Fellow of CDL AI and CDL Quantum Machine Learning. She hails from Markham, currently lives in Silicon Valley, and is a Leafs fan for life.
2. How AI Will Power the Next Wave of Healthcare Innovation?
Zilis on her attitude toward new technology development: “I’m astounded by how often the concept of ‘building moats’ comes up. If you think the technology you’re building is good for the world, why not laser focus on expanding your tech tree as quickly as possible versus slowing down and dividing resources to impede the progress of others?”

Daniela L. Rus is a roboticist, the Director of the MIT Computer Science and Artificial Intelligence Laboratory, and Andrew and Erna Viterbi Professor in the Department of Electrical Engineering and Computer Science at the Massachusetts Institute of Technology. Rus’ groundbreaking research has advanced the state of the art in networked collaborative robots (robots that can work together and communicate with one another), self-reconfigurable robots (robots that can autonomously change their structure to adapt to their environment), and soft robots (robots without rigid bodies).
Her thoughts on AI: “It is important for people to understand that AI is nothing more than a tool. Like any other tool, it is neither intrinsically good nor bad. It is solely what we choose to do with it. I believe that we can do extraordinarily positive things with AI — but it is not a given that that will happen.”
The contributions of all the women in A.I. is paramount and a necessity. We aspire to shorten the gender gap and want to inspire our youth, hence with that in mind our next blog post will be dedicated to an amazing Women Tech community which aspires to reduce the gender gap and aims to connect with more than 100,000 women and students in tech to guide and inspire them .
Thank you for reading along, we hope you got inspired and loved it. Let us know in the comments who inspires you.
Don’t forget to give it a clap, that motivates us.
For more, follow us twitter @theaithing and on instagram @theaithing
If you also want to join our community or want to contribute drop a mail on theaithing0@gmail.com




WOMEN IN A.I. ~ Future is Female was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Via https://becominghuman.ai/women-in-a-i-future-is-female-9b725d061373?source=rss—-5e5bef33608a—4
source https://365datascience.weebly.com/the-best-data-science-blog-2020/women-in-ai-future-is-female

My Artificial Intelligence Journey Through YouTube
Continue reading on Becoming Human: Artificial Intelligence Magazine »

BERT, introduced by Google in 2018, was one of the most influential papers for NLP. But it is still hard to understand. BERT stands for Bidirectional Encoder Representations from Transformers.
In this article, we will go a step further and try to explain BERT Transformers. BERT is one of the most popular NLP models that utilizes a Transformer at its core and which achieved State of the Art performance on many NLP tasks including Classification, Question Answering, and NER Tagging when it was first introduced.
Specifically, we will try to go through the highly influential BERT paper — Pre-training of Deep Bidirectional Transformers for Language Understanding while keeping the jargon to a minimum.
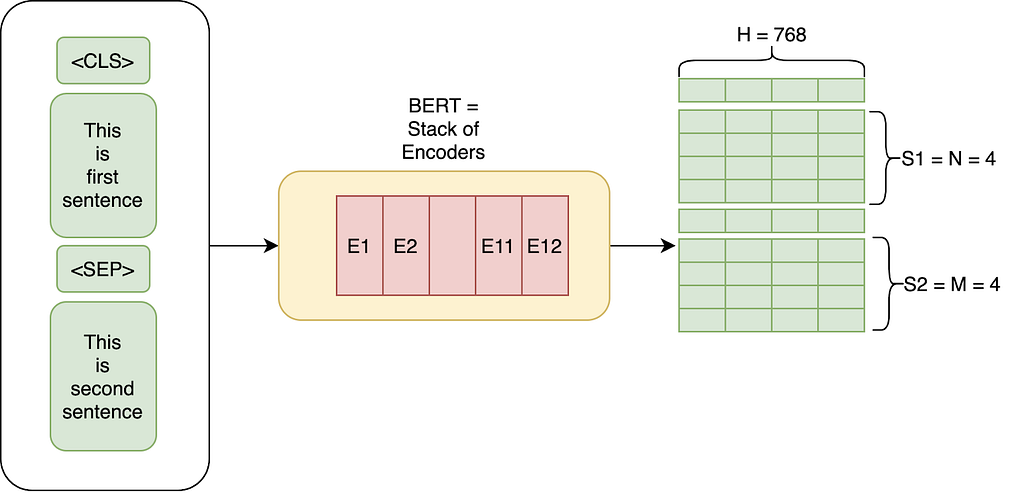
In simple words, BERT is an architecture that can be used for a lot of downstream tasks such as question answering, Classification, NER etc. One can assume a pre-trained BERT as a black box that provides us with H = 768 shaped vectors for each input token(word) in a sequence. Here, the sequence can be a single sentence or a pair of sentences separated by the separator [SEP] and starting with a token [CLS]. We will get into explaining these tokens in more detail in later stages.

A BERT model works like how most Deep Learning models for ImageNet work.
First, we train the BERT model on a large corpus (Masked LM Task), and then we finetune the model for our own task which could be classification, Question Answering or NER, etc. by adding a few extra layers at the end.
For example, we would train BERT first on a corpus like Wikipedia (Masked LM Task) and then Fine Tune the model on our own data to do a classification task like classifying reviews as negative or positive or neutral by adding a few extra layers. In practice, we just use the output from the [CLS] token for the classification task. So, the whole architecture for fine-tuning looks like this:

In other similarly published articles on transformers, all Deep Learning is just Matrix Multiplication, where we just introduce a new W layer having a shape of (H x num_classes = 768 x 3) and train the whole architecture using our training data and Cross-Entropy loss on the classification.
We could have also acquired the sentence features through the last layer and then just run a Logistic regression classifier on top or take an average of all the outputs and then run a logistic regression on top. There are many possibilities, and what works best will depend on the data for the task.
In the above example, we explained how you could do Classification using BERT. In pretty much similar ways, one can also use BERT for Question Answering and NER based Tasks. We will get to the architectures used for various tasks in a few sections below.
2. How AI Will Power the Next Wave of Healthcare Innovation?
This is a great question. Essentially, BERT just provides us with contextual-bidirectional embeddings.
Let’s unpack what that means:
So, for a sentence like “BERT model is awesome.” the embeddings for the word “model” will have context from all the words “BERT”, “Awesome”, and “is”.
Now that we understand the basics, we will divide this section into three major parts: Architecture, Inputs, and Training.
This is the most simple part to understand if you’re familiar with this post on Transformers. BERT is essentially just made up of stacked up encoder layers.
In the paper, the authors have experimented with two models:
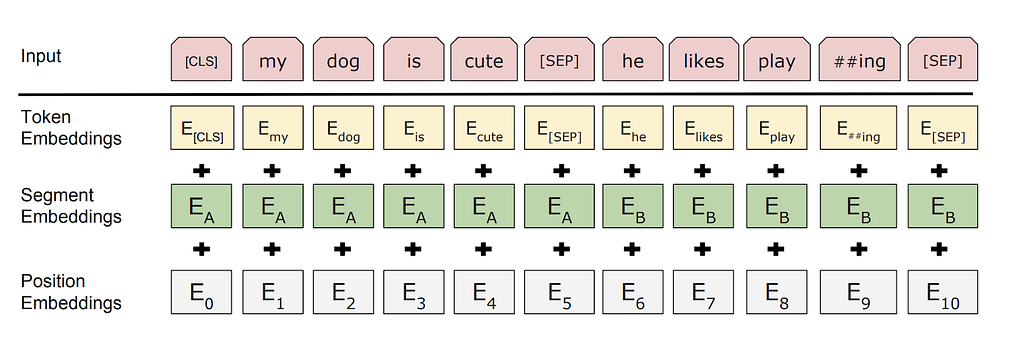
We give inputs to BERT using the above structure. The input consists of a pair of sentences, called sequences, and two special tokens: [CLS] and [SEP].
So, in this example, for two sentences “my dog is cute” and “he likes playing”, BERT first uses wordpiece tokenization to convert the sequence into tokens and adds the [CLS] token in the start and the [SEP] token in the beginning and end of the second sentence, so the input is:

The wordpiece tokenization used in BERT necessarily breaks words like playing into “play” and “##ing”. This helps in two ways:
Token Embeddings: We then get the Token embeddings by indexing a Matrix of size 30000×768(H). Here, 30000 is the Vocab length after wordpiece tokenization. The weights of this matrix would be learned while training.

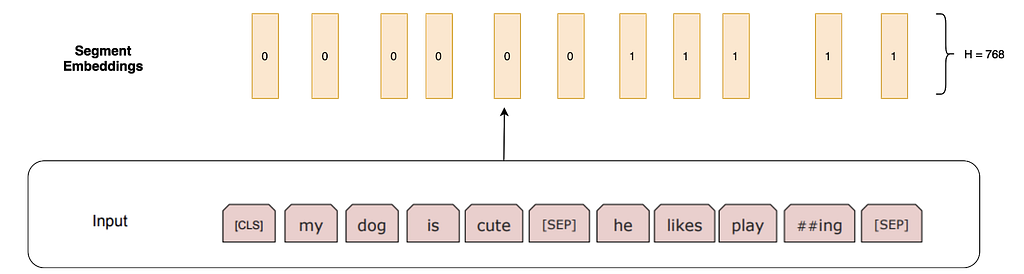
Segment Embeddings: For tasks such as question answering, we should specify which segment this sentence is from. These are either all 0 vectors of H length if the embedding is from sentence 1, or a vector of 1’s if the embedding is from sentence 2.
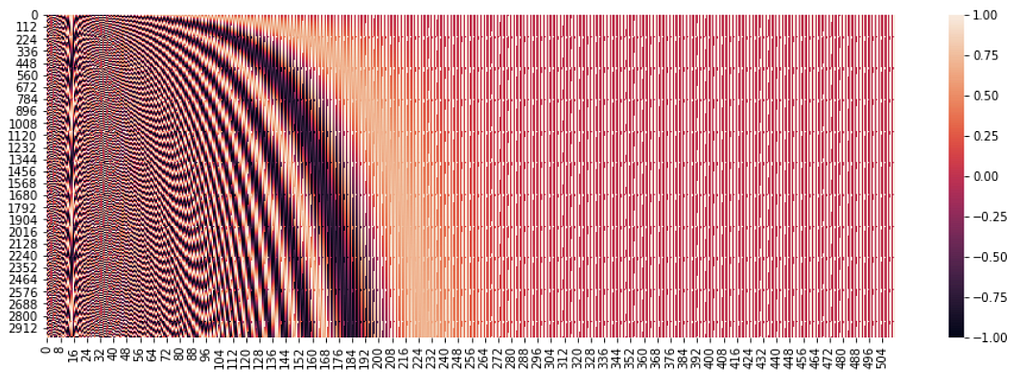
Position Embeddings: These are the embeddings used to specify the position of words in the sequence, the same as we did in the transformer architecture. So we essentially have a constant matrix with some preset pattern. This matrix has the number of columns as 768. The first row of this matrix is the embedding for token [CLS], the second row is embedding for the word “my”, the third row is embedding for the word “dog” and so on.
So the Final Input given to BERT is Token Embeddings + Segment Embeddings + Position Embeddings.
We finally reach the most interesting part of BERT here, as this is where most of the novel concepts are introduced. We will try to explain these concepts by going through various architecture attempts and finding faults with each of them to arrive at the final BERT architecture.
Attempt 1: So, for example, if we set up BERT training as below:
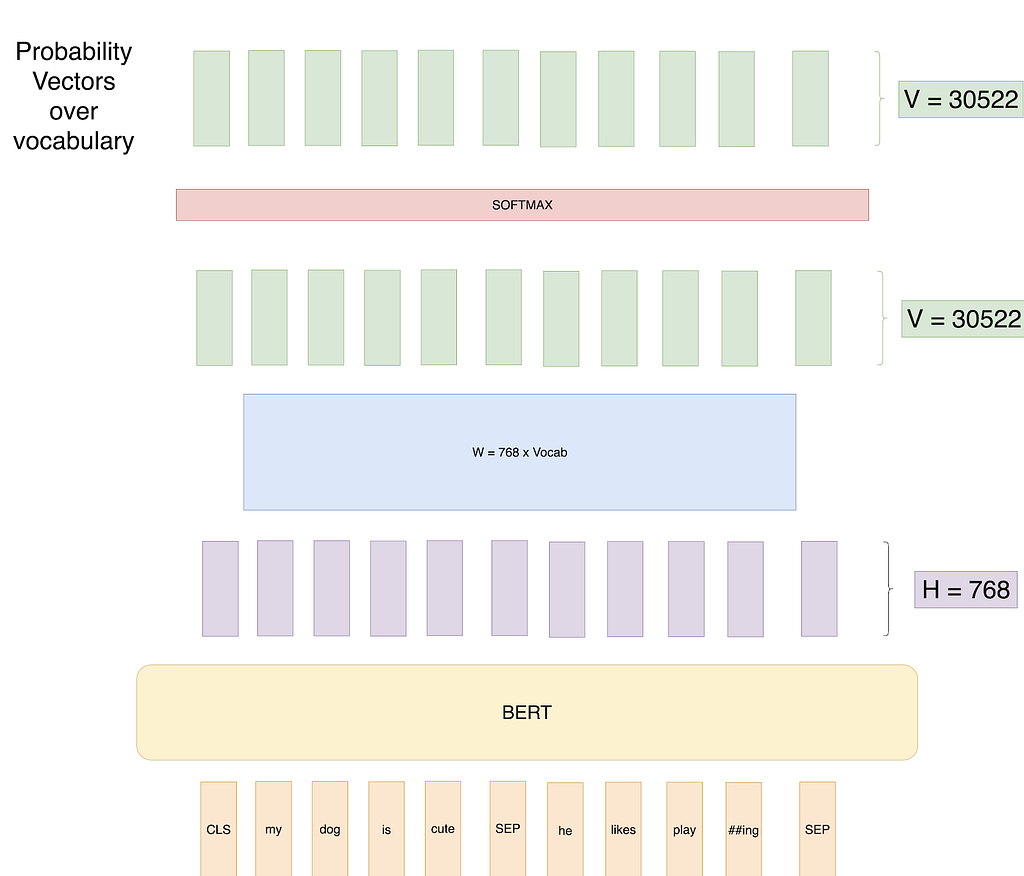
We try to predict each word of the input sequence using our training data with Cross-Entropy loss.
Can you guess a potential problem with this approach?
The problem is that the learning task is trivial.
The network knows beforehand what it has to predict, and it can thus easily learn weights to reach a 100% classification accuracy.
Attempt 2: Masked LM: This starts the beginning of the paper’s approach to overcoming the previous approach’s problem. We mask 15% random words in each training input sequence and just predict output for those words. In Pictorial terms:
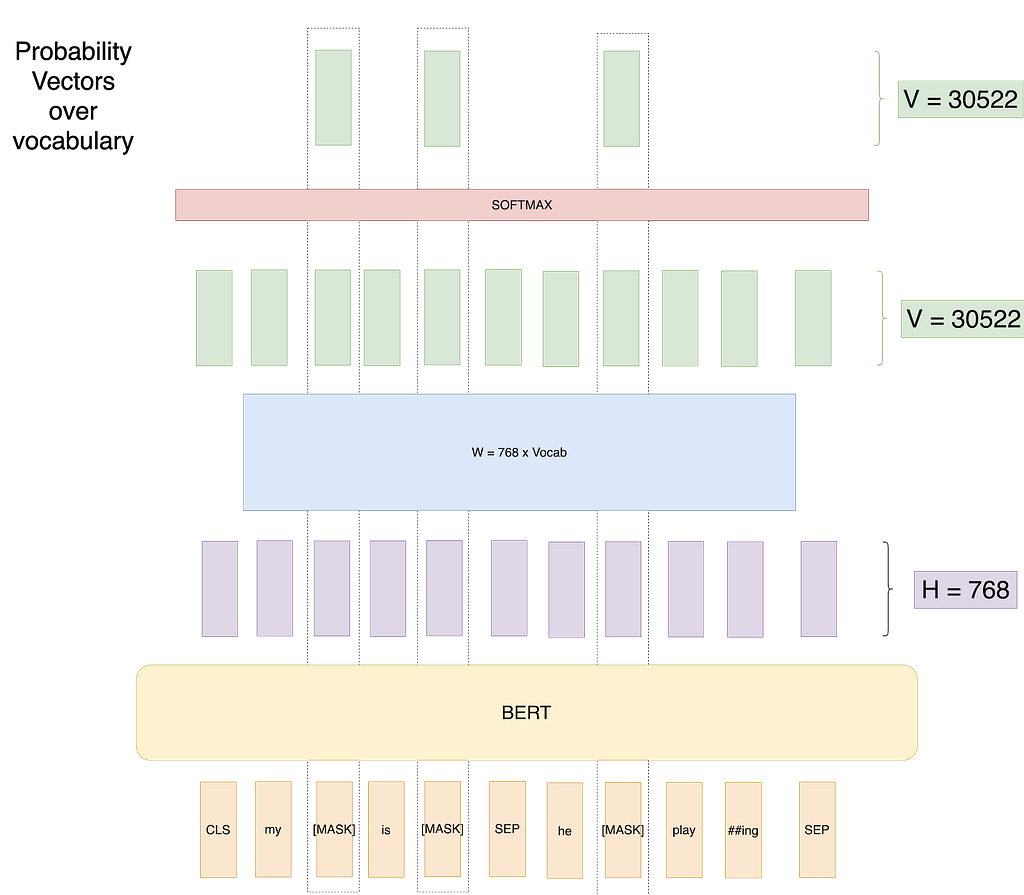
Thus the loss gets calculated only over masked words. So now the model learns to predict words it hasn’t seen while seeing all the context around those words.
Please note, we have masked 3 words here even when we should mask just 1 word as 15% of 8 is 1 to explain in this toy example.
Can you find the problem with this approach?
This model has essentially learned that it should predict good probabilities for only the [MASK] token. That is at the prediction time or at the fine-tuning time when this model will not get [MASK] as input; the model won’t predict good contextual embeddings.
Attempt 3: Masked LM with random Words:
In this attempt, we will still mask 15% of the positions. But we will replace any word in 20% of those masked tokens by some random word. We do this because we want to let the model know that we still want some output when the word is not a [MASK] token. So if we have a sequence of length 500, we will mask 75 tokens(15% of 500), and in those 75 tokens, 15 tokens(20 % of 75) would be replaced by random words. Pictorially, here we replace some of the masks by random words.

Advantage: The network will still work with any word now.
Problem: The network has learned that Input Word is never equal to the Output word. That is the output vector at the position of “random word” would never be “random word.”
Attempt 4: Masked LM with Random Words and Unmasked Words
To solve this problem, the authors suggest the below training setup.
The training data generator chooses 15% of the token positions at random for prediction. If the i-th token is chosen, we replace the i-th token with (1) the [MASK] token 80% of the time (2) a random token 10% of the time (3) the unchanged i-th token 10% of the time
So if we have a sequence of length 500, we will mask 75 tokens(15% of 500), and in those 75 tokens, 7 tokens(10 % of 75) would be replaced by random words, and 7 tokens (10% of 75) will be used as it is. Pictorially, we replace some of the masks with random words and replace some of the masks by actual words.

So, now we have the best setup where our model doesn’t learn any unsavory patterns.
But what if we keep only Mask + Unmask Setup? The model will learn that whenever the word is present, just predict that word.
From the BERT paper:
Many important downstream tasks such as Question Answering (QA) and Natural Language Inference (NLI) are based on understanding the relationship between two sentences, which is not directly captured by language modeling. In order to train a model that understands sentence relationships, we pre-train for a binarized next sentence prediction task that can be trivially generated from any monolingual corpus.
So, now we understand the Masked LM task, BERT Model also has one more training task which goes in parallel while Training Masked LM task. This task is called Next Sentence Prediction (NSP). So while creating the training data, we choose the sentences A and B for each training example such that 50% of the time B is the actual next sentence that follows A (labelled as IsNext), and 50% of the time it is a random sentence from the corpus (labelled as NotNext). We then use the CLS token output to get the binary loss which is also back propagated through the network to learn the weights.
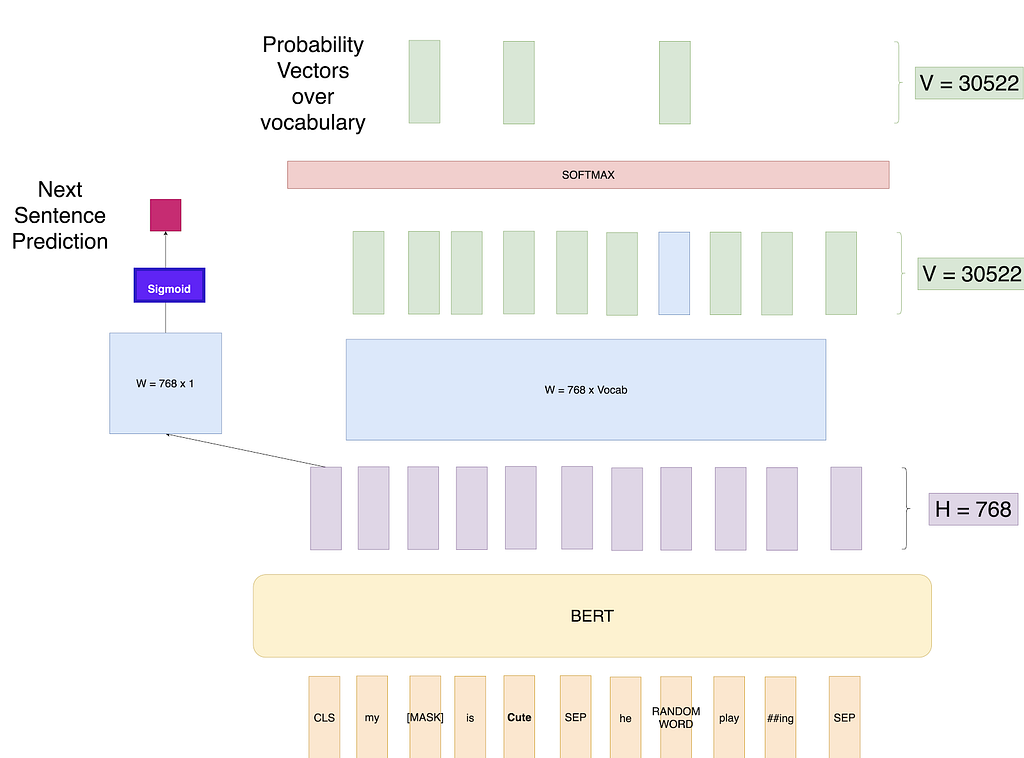
So we have got the BERT model now that can provide us with contextual embeddings. How can we use it for various tasks?
We already have seen how we can use BERT for the classification task by adding a few layers on top of the [CLS] output and fine tuning the weights.

BERT Finetuning for Classification
Here is how we can use BERT for other tasks, from the paper:
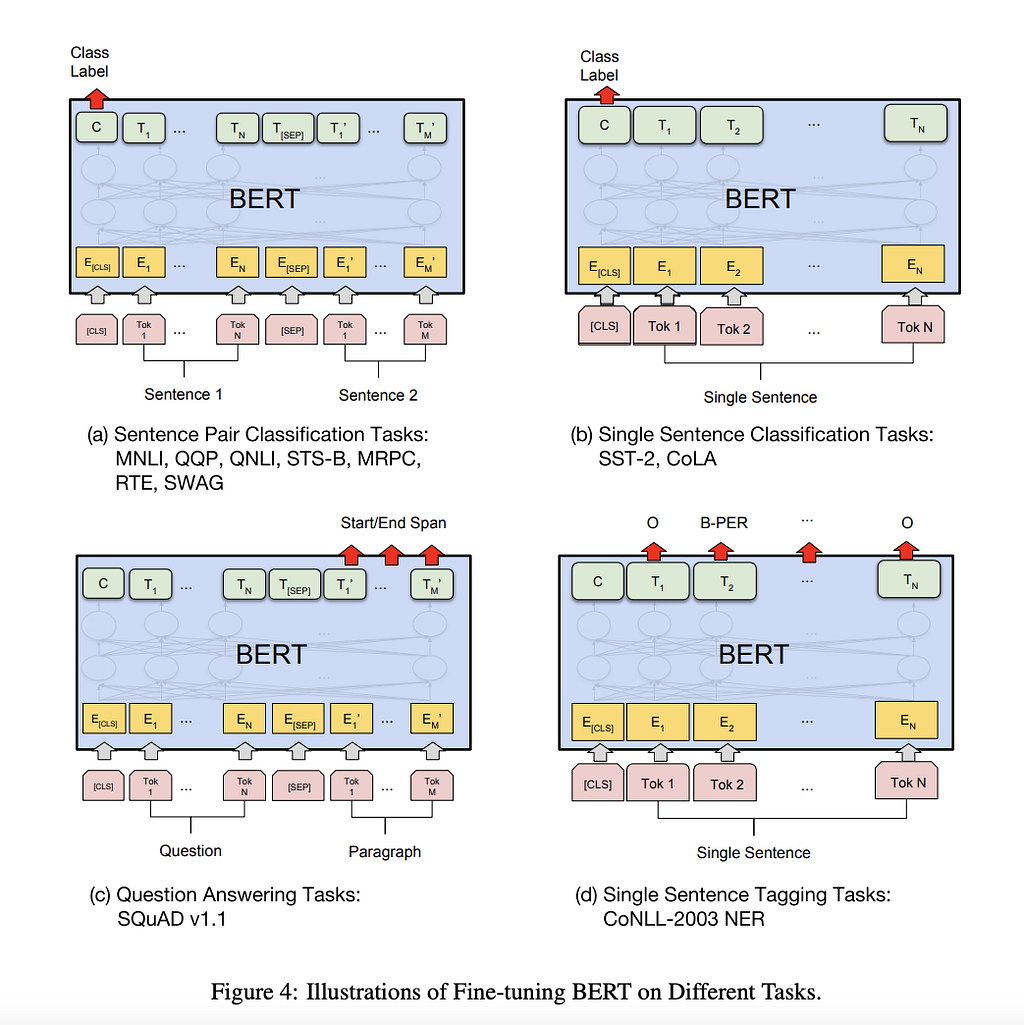
Let’s go through each of them one by one.
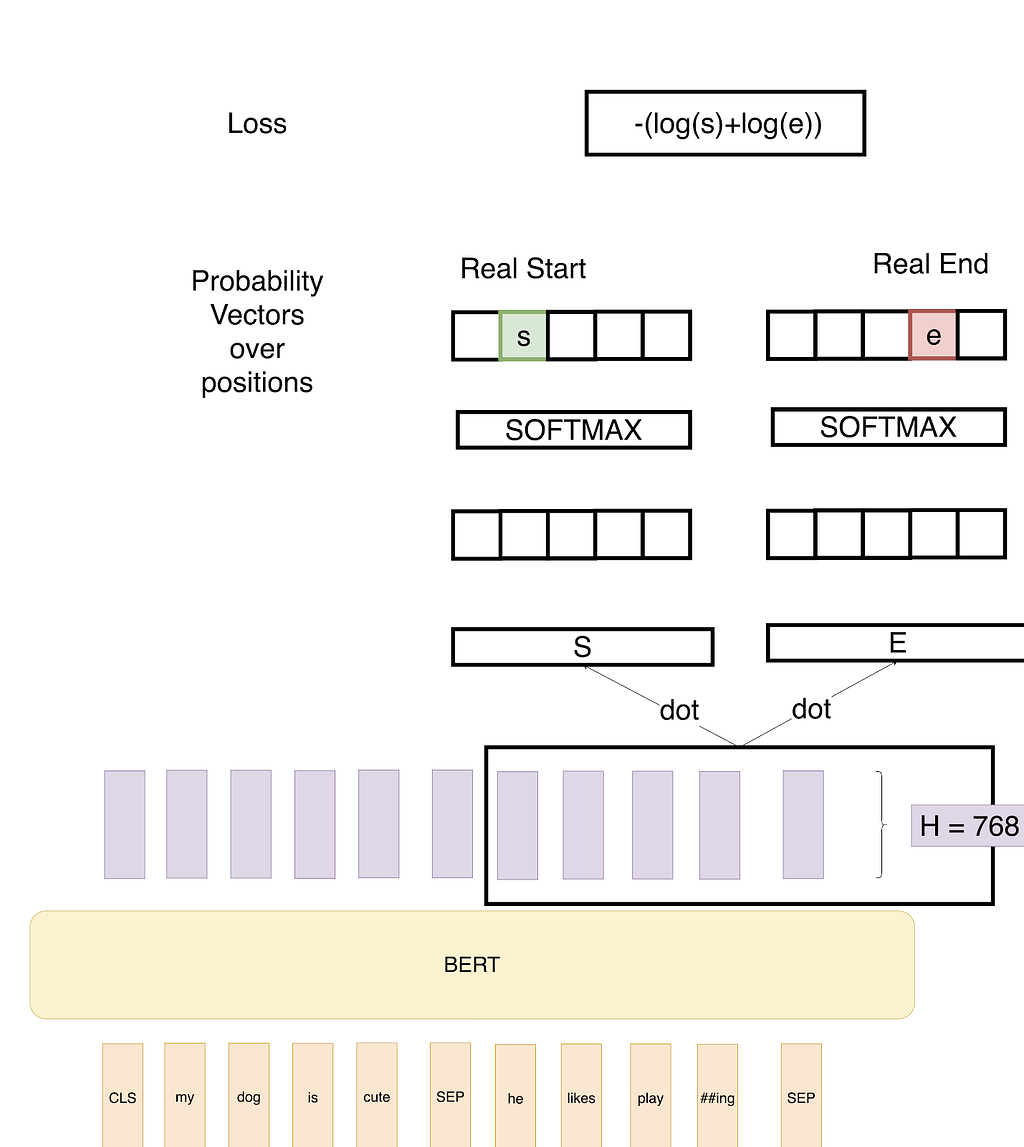
So in the above example, we define two vectors S and E (which will be learned during fine-tuning) both having shapes(1×768). We then take a dot product of these vectors with the second sentence’s output vectors from BERT, giving us some scores. We then apply Softmax over these scores to get probabilities. The training objective is the sum of the log-likelihoods of the correct start and end positions. Mathematically, for the Probability vector for Start positions:
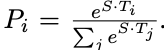
where T_weis the word we are focusing on. An analogous formula is for End positions.
To predict a span, we get all the scores — S.T and E.T and get the best span as the span having the maximum Score, that is max(S.T_we+ E.T_j) among all j≥i.
BERT Transformers — How Do They Work? was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Via https://becominghuman.ai/bert-transformers-how-do-they-work-cd44e8e31359?source=rss—-5e5bef33608a—4
source https://365datascience.weebly.com/the-best-data-science-blog-2020/bert-transformershow-do-they-work
Originally from KDnuggets https://ift.tt/3uMGNV8
Originally from KDnuggets https://ift.tt/3sbDzsH
Originally from KDnuggets https://ift.tt/325znjw
Originally from KDnuggets https://ift.tt/3d2CrTP

First, a little context…
Deep learning is a subset of machine learning, which in turn is a subset of artificial intelligence, but the origins of these names arose from an interesting history. In addition, there are fascinating technical characteristics that can differentiate deep learning from other types of machine learning…essential working knowledge for anyone with ML, DL, or AI in their skillset.
If you are looking to improve your skill set or steer business/research strategy in 2021, you may come across articles decrying a skills shortage in deep learning. A few years ago, you would have read the same about a shortage of professionals with machine learning skills, and just a few years before that the emphasis would have been on a shortage of data scientists skilled in “big data.”
Likewise, we’ve heard Andrew Ng telling us for years that “AI is the new electricity”, and the advent of AI in business and society is constantly suggested to have an impact similar to that of the industrial revolution. While warnings of skills shortages are arguably overblown, why do we seem to change our ideas about what skills are most in-demand faster than those roles can be filled in the first place?
More broadly, and with the benefit of 20/20 hindsight, why does AI research have so many different names and guises over the years?

Searching jobs site Indeed.com for “deep learning” yields about 49,000 hits as of this writing. That’s a bit funny, because deep learning is a subset of machine learning, which in turn is a field within artificial intelligence, and searches for ML and AI yielded ~40,000 and ~39,000 jobs, respectively.
If deep learning is a part of AI, why are there ~20% fewer jobs open for the latter? The answer is that the terms we use for these fields often have as much to do with trends and marketability as they do with any substantive differences. That’s not to say that we can’t differentiate the different categories based on technical characteristics, we’ll do that too!
In fact, there are several very interesting emergent characteristics separating deep learning from “classical” machine learning including shallow neural networks and statistical learning. Before we talk about those, let’s take a walk through the history of AI, where we’ll see that much of the popularity of various AI terms has to do with generating high expectations before later falling short and eventually re-branding to re-establish credibility when new ideas lead to new solutions to old problems.

The Dartmouth workshop was an extended summer conference of a small number of prominent mathematicians and scientists in 1956.
The workshop is widely considered to be the founding of artificial intelligence as a field, and it brought together many different disciplines known under a variety of names (each with their own conceptual underpinnings) under the umbrella of AI. Before John McCarthy proposed the meeting in 1955, the idea of thinking machines was pursued under the disparate approaches of automata theory and cybernetics, among others. In attendance were such well known names as Claude Shannon, John Nash, and Marvin Minsky among a few others. The Dartmouth workshop not only tied together several independent threads of research pertaining to intelligent machines, it set ambitious expectations for the next decade of research.
Those ambitions, as it turned out, would ultimately end with disappointment and the first AI winter — a term used to describe the lulls in the waxing and waning fortunes of the AI hype cycle.
In 1973, Professor Sir James Lighthill of the UK wrote “Artificial Intelligence: A General Survey,” also known as the Lighthill Report. In his report, Lighthill describes three categories of AI research: A, B, and C. While he describes some missed expectations in categories A and C (advanced automation and computational neuroscience), Lighthill describes the field as falling short most noticeably in the very visible category B, aka robots. The Lighthill report, along with a treatise demonstrating some shortcomings of an early form of shallow neural network, Perceptrons by Marvin Minsky and Seymour Paypert, are to this day considered to be major harbingers of the AI winter that took hold in the 1970s.
“Students of all this work have generally concluded that it is unrealistic to expect highly generalized systems that can handle a large knowledge base effectively in a learning or self-organizing mode to be developed in the 20th century.” — James Lighthill, Artificial Intelligence: A General Survey
It wasn’t long before interest returned to AI and, in the 1980s, funding also began to creep back into the field. Although the field of neural networks and perceptrons had fallen distinctly out of favor the first time around (with many blaming Minsky and Paypert), this time they would play a major role. Perhaps in an effort to distance themselves from earlier disappointments, neural networks would re-enter legitimate research under the guise of a new moniker: connectionism.
In fact, many of the most recognizable names in the modern era of deep learning such as Jürgen Schmidhuber, Yann LeCun, Yoshua Bengio, and Geoffrey Hinton were doing foundational work on topics like backpropagation and the vanishing gradient problem in the 1980s and early 1990s. But the real headliner of AI research in the 1980s was the field of expert systems. Unlike the “grandiose claims” critiqued by Lighthill in his report, expert systems were actually providing quantifiable commercial benefits, such as XCON developed at Carnegie Mellon University.
XCON was an expert system that reportedly saved the Digital Equipment Corporation up to $40 million per year. With utility demonstrated by systems like XCON and several high-profile game-playing systems, funding returned to AI in both commercial R&D labs and government programs. It wouldn’t last, however.
2. How AI Will Power the Next Wave of Healthcare Innovation?
The combinatorial explosion, in which the complexity of real world scenarios becomes intractable to enumerate, remained an unsolved challenge. Expert systems in particular were too brittle to deal with changing information, and updating them was expensive. Convincing and capable robots, again, were nowhere to be seen.
Roboticists such as Rodney Brooks and Hans Moravec began to emphasize that the manual work of painstakingly trying to distill human expert knowledge into computer programs was not sufficient to solve the most basic of human skills, such as navigating a busy sidewalk or locating a friend in a noisy crowd. It soon became apparent under what we now know as Moravec’s paradox that for AI, the easy things are hard while the hard things like calculating a large sum or playing expert checkers, are comparatively easy.
Expert systems were proving to be brittle and costly, setting the stage for disappointment, but at the same time learning-based AI was rising to prominence, and many researchers began to flock to this area. Their focus on machine learning included neural networks, as well as a wide variety of other algorithms and models like support vector machines, clustering algorithms, and regression models.
The turning over of the 1980s into the 1990s is regarded by some as the second AI winter, and indeed hundreds of AI companies and divisions shut down during this time. Many of these companies were engaged in building what was at the time high-performance computing (HPC), and their closing down was indicative of the important role Moore’s law would play in AI progress.
Deep Blue, the chess champion system developed by IBM in the later 1990s, wasn’t powered by a better expert system, but rather a compute-enabled alpha-beta search. Why pay a premium for a specialized Lisp machine when you can get the same performance from a consumer desktop?
Although Moore’s law has essentially slowed to a crawl as transistors reach physical limits, engineering improvements continue to enable new breakthroughs in modern AI, with NVIDIA and AMD leading the way. And now, a turnkey AI workstation designed specifically with components that best support modern deep learning models can make a huge difference in iteration speed over what would have been state-of-the-art hardware just a few years ago.
In research and practical applications, however, the early 1990s were really more of a slow simmering. This was a time when future Turing award winners were doing seminal work, and neural networks would soon be used in the real-world application of optical character recognition used for tasks like sorting mail. LSTMs made headway against the vanishing gradient problem in 1997, and meaningful research continued to be done in neural networks and other machine learning methods.
The term machine learning continued to gain in popularity, again perhaps as an effort by serious researchers to distance themselves from over-ambitious claims (and science fiction stigma) associated with the term artificial intelligence. Steady progress and improved hardware continued to power useful AI advances into the new millennium, but it wasn’t until the adoption of highly parallel graphics processing units (GPUs) for the naturally parallelizable mathematical primitives of neural networks that we entered the modern era of deep learning.
When thinking about the beginning of the deep learning era of AI, many of us will point to the success of Alex Krizhevsky et al. and their GPU-trained model at the 2012 ImageNet Large Scale Visual Recognition Challenge. While the so-called AlexNet was modest in size by today’s standards, it decisively bested a competitive field of diverse approaches.
Succeeding winners of the challenge were built on similar principles of convolutional neural networks from then on, and it’s no surprise that many of the characteristics of convolutional networks and the kernel weights learned during training have analogues in animal vision systems.
AlexNet wasn’t a particularly deep convolutional neural network, stretching across 8 layers from tip to tail and only 3 layers deeper than LeNet-5 (pdf), a convolutional network described more than 2 decades earlier. Instead, the major contribution of AlexNet was the demonstration that training on GPUs was both feasible and well worth it.
In a direct lineage from the development of AlexNet, we now have GPUs specifically engineered to support faster and more efficient training of deep neural networks.
The 2012 ILSVRC and performance of AlexNet in the competition was so iconic that it has become the archetype for AI breakthroughs of the last decade.
For better or worse, people talk about “ImageNet moments” for natural language processing, robotics, and gait analysis, to name a few. We’ve come a long way since then, with deep learning models demonstrating near-human performance or better in playing games, generating convincing text, and other categories that fall under the types of “easy is hard” tasks referred to under Moravec’s paradox mentioned earlier.
Deep learning has also contributed to basic scientific research, and in 2020 made an unequivocal contribution to the fundamental challenge in biology of protein structure prediction.
Hardware acceleration has made training deep and wide neural networks feasible, but that doesn’t explain why or even how larger models produce better results than smaller models. Geoffrey Hinton, widely credited as one of the progenitors of the modern deep learning era, suggested in his Neural Networks for Machine Learning MOOC that machine learning with neural networks becomes deep learning at 7 layers.
We don’t think that’s a bad rule of thumb for approximating the start of the deep learning paradigm, but we think we can draw the line more meaningfully by considering how deep learning models train differently than other forms of machine learning. It’s also worth noting that while deep learning most often refers to models made up of multiple layers of fully connected or convolutional neural layers, the term also encompasses models like neural ordinary differential equations or neural cellular automata.
It’s the computational complexity and depth of operations that make deep learning, and the layers don’t necessarily need to be made up of artificial neurons.
A subset of machine learning which hasn’t been mentioned yet in this article but which remains an important area of expertise for millions of data and basic research scientists is statistical learning.
One of the most important concepts in statistical learning and machine learning in general with smaller models and datasets is that of the bias-variance tradeoff. Bias corresponds to underfitting the training data, and is often a symptom of models that don’t have the fitting power to represent patterns in the dataset.
Variance, on the other hand, corresponds to models that are fitted too well to the training data so much so that generalization to held-out validation data is poor. Synonymous terminology that’s a little easier to keep in mind is under/over-fitting.

For statistical models and shallow neural networks, we can generally interpret under-fitting as a symptom of a model being too small, and overfitting a symptom of too large of a model. Of course there are numerous different strategies to regularize models so that they exhibit better generalization, but we’ll leave that discussion mostly for another time.
Larger models also tend to be better capable of taking advantage of larger datasets.

Overfitting is often seen in the difference between model performance on the training and validation datasets, and this deviation can get worse with more training/bigger models. However, an interesting phenomenon occurs when both the model and the dataset gets even larger. This fascinating emergent property of deep double descent refers to an initial period of improved performance, followed by decreasing performance due to overfitting, but finally superseded by even better performance. This occurs with increasing model depth, width, or training data, and might be most logical place to draw the distinguishing line between deep learning and shallower neural networks.

Somewhat counter-intuitively, in the deep learning regime marked by deep double descent, models actually tend to generalize better and regularization techniques like dropout tend to yield better results. Other hallmarks of deep learning, like the lottery ticket hypothesis, are likely related.
This concludes our discussion of the history and rationale of a few sub-fields of AI, and what they’ve been called at different points in their history.
We also discussed an interesting identifying characteristic of deep learning models that allows them to continue to improve with increasing scale or data when we would intuitively expect them to massively overfit. Of course, if you are pitching a project to investors/managers/funders, or pitching yourself to a potential employer, you may want to consider your terminology from a marketing perspective instead.
In that case you may want to describe your work to the public as AI, to investors as deep learning, and to your colleagues and peers at conferences as machine learning.
Disentangling AI, Machine Learning, and Deep Learning was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.

{kind=link}