A classic KDnuggets Thanksgiving cartoon examines the predicament of one group of fowl Data Scientists.
Originally from KDnuggets https://ift.tt/378bs5n

365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Originally from KDnuggets https://ift.tt/378bs5n
Originally from KDnuggets https://ift.tt/39eD6Al
Originally from KDnuggets https://ift.tt/2Ky2tmc
Hello fellow reader (and hello again if you read the first part of this article series). My name is Artur, and I am the head of the Machine Learning team in Akvelon’s Kazan office and you are about to read the second part of the tutorial for anomaly detection in a time series.
During our own research, we’ve managed to gather a lot of information from tiny useful pieces all over the internet and we don’t want this knowledge to be lost!
We already dove into theory and data preparation in Part I:
1 more part is coming very soon, stay in touch and don’t miss it! This item will become a link to the next chapter:
We reuse our code so if something seems unclear, consider visiting the previous part once more.
Alright then, let’s move on!
1. How to automatically deskew (straighten) a text image using OpenCV
3. 5 Best Artificial Intelligence Online Courses for Beginners in 2020
4. A Non Mathematical guide to the mathematics behind Machine Learning
Just to briefly remind the tools that we use:
Amongst all possible approaches listed in Part I, we chose these suitable ones:
Let’s start with the ARIMA model.
ARIMA is an autoregression statistical model that optimizes coefficients (also known as hyperparameters) during training. Then these hyperparameters are used in inference.
It is logical that during nighttime and daytime CPU usage may vary which is totally normal behavior. To consider this behavior, we can think of night and day times as separate “seasons”. And because of this, we will use SARIMAX — which is just a modified ARIMA model with the same idea that adds seasonal causes into ARIMA. SARIMAX will deal with the separation of seasons for us, so we don’t have to provide anything else except our dataset.
Here you can see the schema for the training process of SARIMAX:
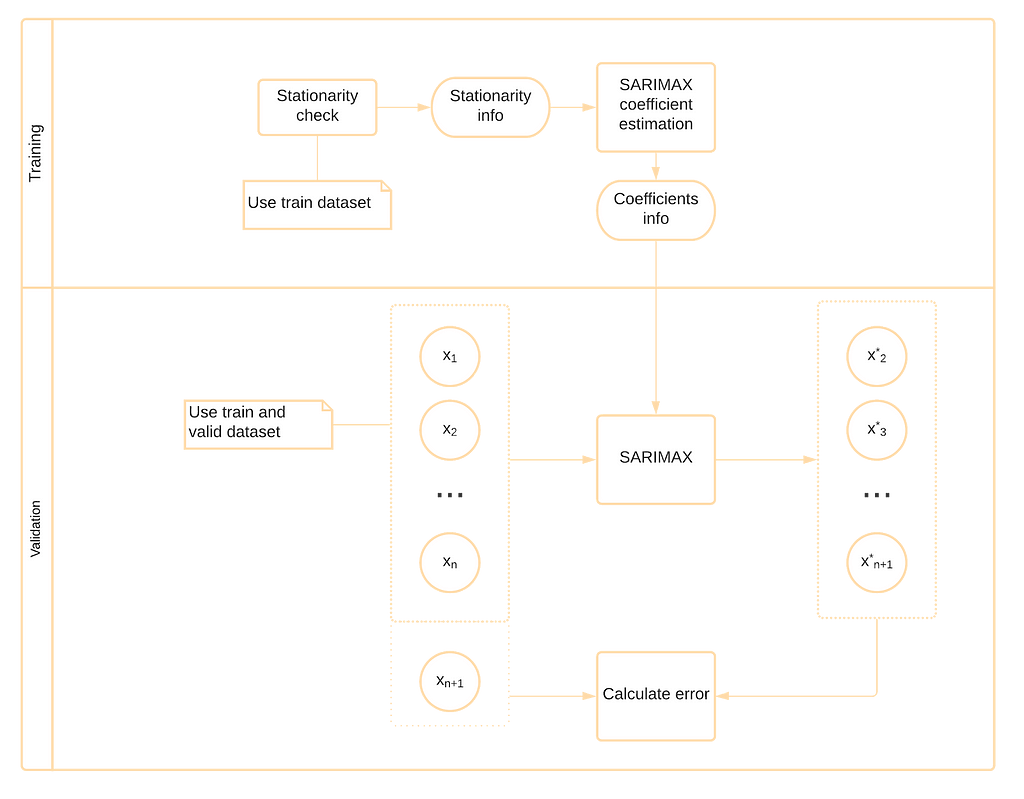
The model tries to predict the next value using the current one and then it compares the predicted result with actual value.
Implementation of this model is not so interesting since all we can play with are hyperparameters for this model. To find the model that produces the best predictions we will iterate over hyperparameters and will pick the combination.

All we need is just the model itself from the statsmodels.api package and product function from itertools for iteration over hyperparameters.
And also, it would be a good idea is to write predictions of the best model into the new column of the DataFrame with initial data to ease further metrics calculation.
Here is the code to pick the best model and write its predictions into training and validation DataFrames:
At this very moment, we have the best set of parameters and predictions for both training and validation data. To understand how good our model is, we should calculate different metrics such as precision, recall, and F-score. We will fully cover the metrics theme in Part III, however, we already can visualize the predictions and see how our model performs:
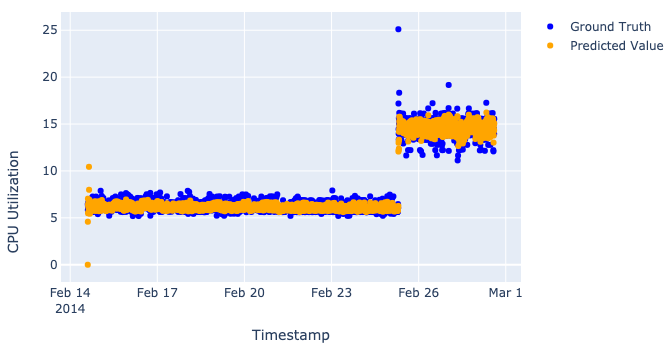

Note: one important thing about ARIMA is that time for training and optimizing the coefficients takes ~10 times longer than it takes to complete the same training of both neural networks.
Convolutional neural networks are usually applied to image-connected tasks, such as image classification, segmentation, etc. But the purpose of the convolutional layers is to find and recognize patterns, which is totally applicable for analysis of the CPU utilization metric.
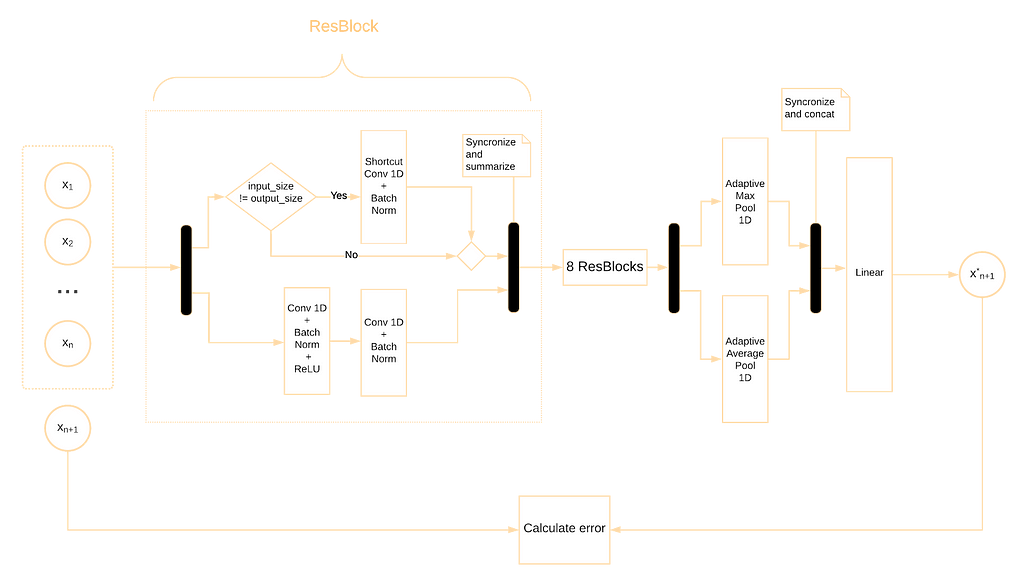
We use ResNet-ish architecture (which has already become the best type of architecture to use in CNNs) that consists of Residual Blocks (ResBlocks). The idea behind ResBlock is simple yet efficient — add the input of the block to its output. This idea allows neural networks to “remember” each intermediate result and take it into account in the final layers.
CNN tries to predict the next value using some number of previous values. In our case, this number equals 10, but of course, it may be configured.
Before coding CNN itself we should make a few additional preparations of the data. In general, since we use PyTorch, the data should be wrapped into something compatible with PyTorch’s Dataset. This may be as well the class inherited from the Dataset class, a generator, or even a simple iterator.
We will use the class option due to its readability and implicit PyTorch’s enhancements.
Once again, there are some necessary imports for Dataset creation:
Let’s recall the task for CNN. We want the model to predict the next value using some amount of the previous values. This means that our Dataset class should contain each item in a specific format — divided into 2 parts:
Coming back to the implementation — actually, it is very easy to wrap data with our custom class that just inherits from PyTorch’s Dataset. It should implement only __init__, __len__ and __getitem__ methods:
Now it is the right time to define the number of previous values that are to be used for the prediction of the next one. And, of course, wrap the data with our CPUDataset class.
Here comes the best part — the definition of the neural network.
Let’s rewind how Residual block looks like in regular ResNets. It consists of:
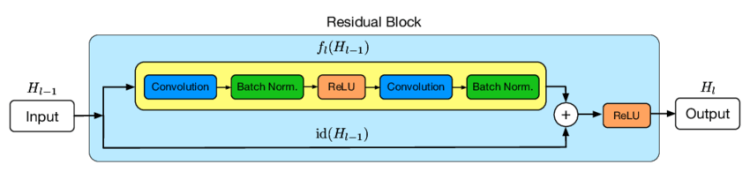
The only difference between the regular ResBlock and ours is that we removed the last ReLU activation — it turned out that in our case CNN without the last ReLU in ResBlock generalizes better.
Many Residual Blocks bring twice more Convolution + Batch Norm. (+ ReLU) combinations. So, such a combination is a good starting point to define.
In each Residual Block, we should remember about the case of changing the number of output channels (when in_feat != out_feat). One possible way to synchronize the number of channels is to multiply or cut them. However, there is another greater way — we can handle this using a 1×1 convolution without padding. This trick not only allows us to fit layer input into layer output but also adds more reasonable computations for the neural network.
It is widely used to finish the base block of the convolutional net with Max Pooling or Average Pooling depending on the task. Here comes another useful trick for Convolutional Neural Nets (thanks to Jeremy Howard and his fantastic fast.ai library) — concatenate Average Pooling and Max Pooling. It allows our neural net to decide, which approach is better for the current task and how to combine them to get better results:
And here is our resulting CNN class that is made of the building blocks that we implemented above:
Now we have the definition of CNN and can create a randomly initialized model, pass items from our Datasets, and check that data shapes are correct and that no exceptions are raised.
After the model is defined, we can move to the training loop. This loop is quite general and may be used with the majority of the neural nets:
Alright, we are almost ready to start fitting our CNN model. The only thing left is to initialize the model, dataloaders, and training parameters.
Here we use:
Eventually, we can run the most desired line of code — execution of the training process:
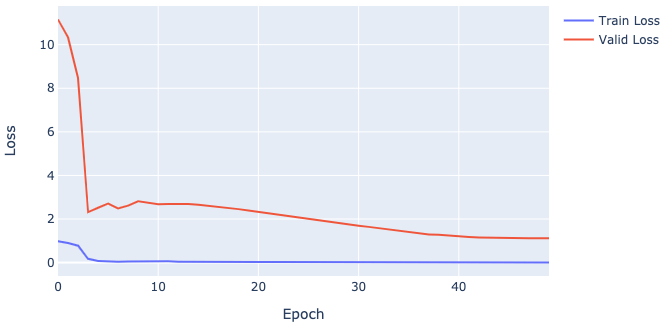
And see the losses of our model.

We always want both training and validation losses to move down because this behavior means that the model has learned something useful about our data. If any loss eventually moves up, then the model can’t figure out how to solve the task, and you should change or modify it.
These losses on the picture above seem pretty nice because they eventually move down, but it is an early assumption (their niceness) since we haven’t checked the predictions yet.
At this very moment, we can easily calculate them with our model:
And take a look:
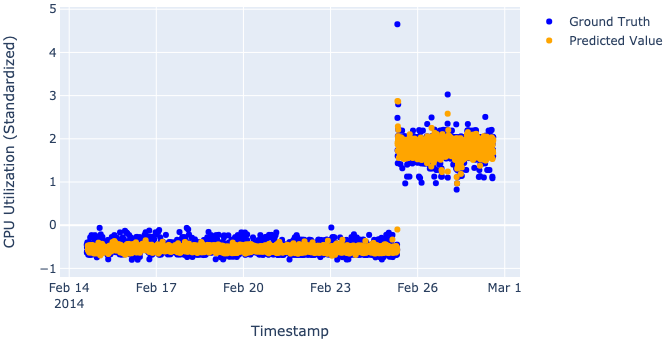
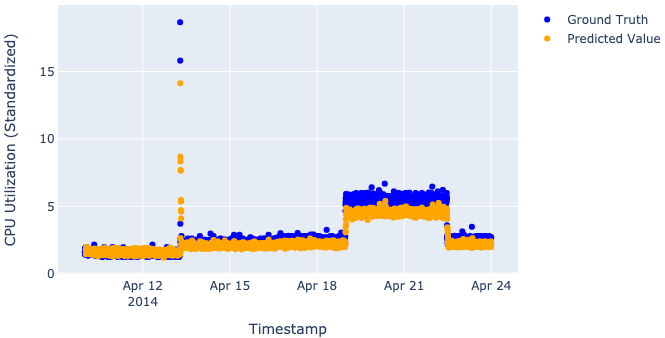
Just to be clear, we don’t really want our models to perfectly predict values, as such perfection would destroy the whole idea of the anomaly detection process (described in “Saying what we want from our models out loud” in Part I). That’s why when we look at plots, we want to see our model catch the main trend, not the particular values.
LSTM neural networks have an internal memory state that allows them to remember its’ previous evaluations that make this architecture the perfect candidate for time series anomaly detection.
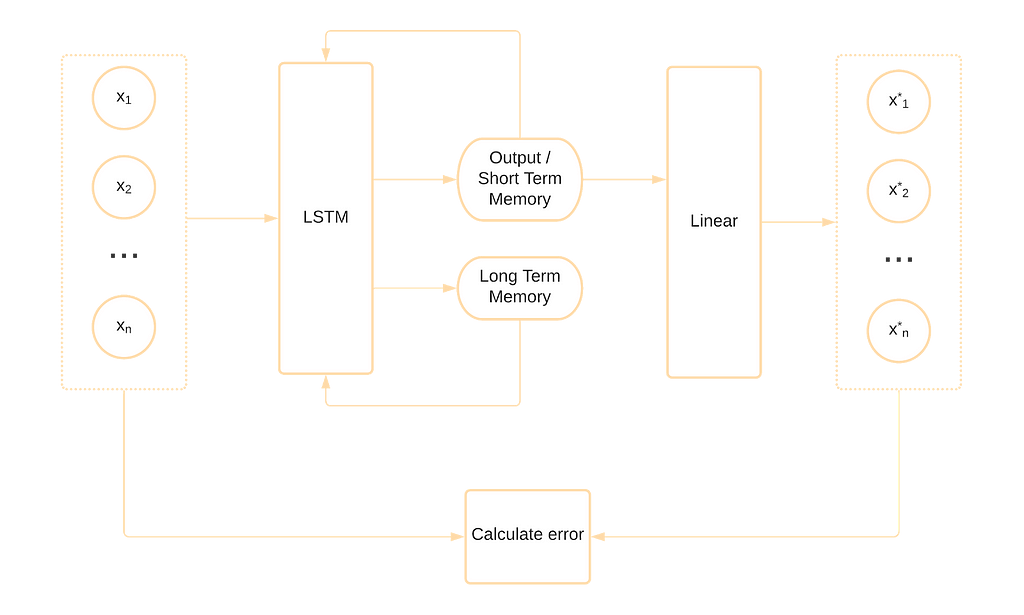
Unlike the previous two models, this neural network tries to reconstruct the current value using the value itself. It may seem trivial, but this approach has extremely good results in anomaly detection.
We can simplify the wrapping of data into the Dataset from CNN because we need the very same output as input for reconstruction. That is why we get rid of the first part of each item and just keep 1 value. We also should consider that LSTM models usually can’t be fed with the whole sequence at once (because of the memory consumption for the whole sequence)— we have to separate data accordingly into partial sequences to train. Moreover, as training with the whole sequence may reduce the model’s ability to generalize, it may simply get used to the data this way.
The definition of the LSTM neural net is much easier than the CNN one. PyTorch already has an implemented class of LSTM cells that we can use.
Considering that we changed the Dataset class a bit we also should change the training loop to fit data.
In LSTM case we also use:
One more time we face the most desired line of the code with its result:
Because of the training with partial sequences, we can’t directly send the Dataset instance to get the results, but we certainly can extract the entire sequences from DataFrames:
And then we calculate the predictions:
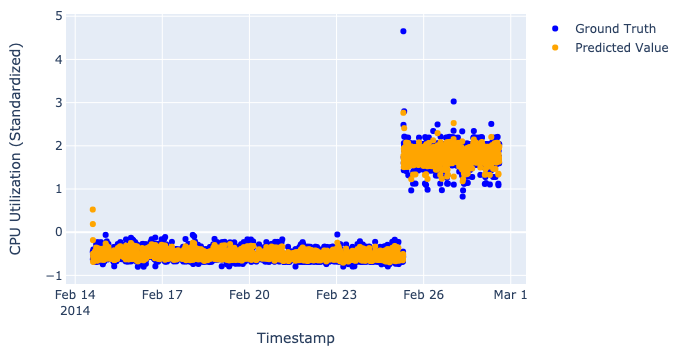
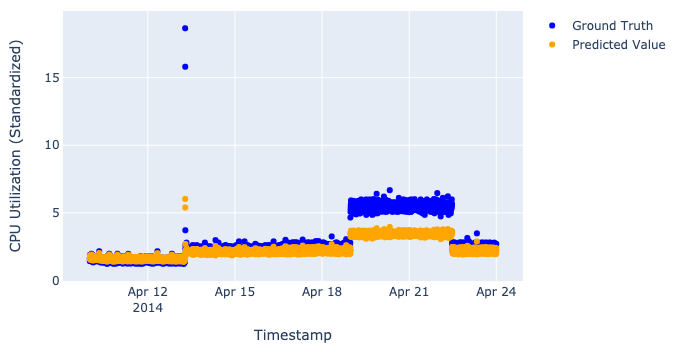
Terrific, we have 3 trained models and their results on our dataset!
The toughest part is behind us and now we are prepared to make our final steps towards anomaly detection. In the last chapter, we will do some extra preparations and reveal the detection process along with its results.
If you want to refresh some theory or data preprocessing, don’t be shy and go to the first part:
Otherwise, the third part awaits (this item will become link like the one from the header):
We at Akvelon Inc love cutting edge technologies in mobile development, blockchain, big data, machine learning, artificial intelligence, computer vision, and many others. This article is the result of one of many projects developed in our Office Strategy Labs where we’re testing new technologies and approaches before delivering them to our clients.

If you would like to work with our strong Akvelon team — please see our open positions.
Designed and implemented with love in Akvelon:
Team Lead — Artur Khanin
Delivery Manager — Sergei Volynkin
Technical Account Manager — Max Kostin
ML Engineers — Irina Nikolaeva, Rustem Saitgareev




Time Series and How to Detect Anomalies in Them — Part II was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Intelligence boils down to two things for me ->
1. Acting when certain/necessary.
2. Not acting/staying pensive when uncertain.
Point (2.) is what we are going to dive in!
Uncertainty is inherent everywhere, nothing is error free. So, it is frankly quite surprising that for most Machine Learning projects, gauging uncertainty isn’t what’s aimed for!
1. How to automatically deskew (straighten) a text image using OpenCV
3. 5 Best Artificial Intelligence Online Courses for Beginners in 2020
4. A Non Mathematical guide to the mathematics behind Machine Learning
As a not-so-real-world example, consider a treatment recommendation algorithm. We are given a patient’s medical data that we feed into our network. For a plain NN(Neural Network), it would just output a single class, say treatment type ‘C’. While for BNNs you would be able to see the whole distribution of the output, and gauge the confidence of your output label based on that. If the standard deviation is low of your output distribution, we are good to go with that output label. Otherwise, chuck it, we need human intervention.
So, BNNs are different from plain neural networks in the sense that their weights are assigned a probability distribution instead of a single value or point estimate. Hence, we can assess the uncertainty in weights to estimate the uncertainty in predictions. If your input parameters are not stable, how can you expect your output to be?! Makes sense, eh.
Say you have a parameter, you try to estimate its distribution and using the distribution’s high probability points you estimate the output value of your neural network. By high probability, I mean the more probable points. (Mean is the most probable point in a Normal distribution)
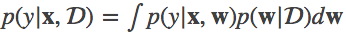
Looking at Equation #1,
On the left hand side, we have the probability distribution of the output classes, which we get after feeding in our data ‘x’ to our model which has been trained on Dataset ‘D’.
On the right hand side, we have an integral. The middle term inside the integral is the posterior, which is a probability distribution of the weights GIVEN we have seen the data.
Think of this integral as an ensemble, where each unique model is identified by a unique set of weights (because different weights means different models). Greater the posterior probability for a unique set of weights(therefore that unique model), greater weight will be given to that prediction. Hence, each model’s respective prediction is weighed by the posterior probability of it’s unique set of weights!
Sounds good, eh? Just search the whole weight space and weigh in the good(high probability) parts. Wondering why people don’t do this? It is because even a simple 5–7 layer NN has around a million weights, so it is just not computationally feasible to construct an analytical solution for the posterior(p(w|D)) in NNs.
So the next step is, we need to approximate the posterior distribution. We cannot get the exact posterior distribution, but we surely can choose another distribution that replicates it to a good extent.
We can do this using a variational distribution whose functional form is known! By ‘functional form is known’, I mean it is one of the standard statistical distributions which can be denoted using just a few parameters, like the Normal distribution( We just need two parameters, i.e. the mean and variance, to denote a Normal distribution). So, we are essentially trying to form a Normal distribution replica of the posterior distribution. Even though the actual posterior distribution might not be a Normal distribution, we are still going to replicate it as well as we can using the variational distribution, which is a Normal distribution in our case. You can pick any standard statistical distribution for the variational distribution.
How do we go about replicating it? I’ll cover that and more in the next article. Hope this works up an appetite for the world of Bayesian Machine Learning! It’s a beautiful topic and one that has got a lot of exploring to do.
So yeah, see you!
Testing the waters of Bayesian Neural Networks(BNNs) was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.

Hi! My name is Martin. I’m a Master of Science in Economic and Social Sciences from Bocconi University in Milan, Italy but to all my students, I am also the author and instructor of the Python, SQL, and Integration courses in the 365 Data Science Program. And I am excited to share that we just launched the latest addition to our training – Data Cleaning and Preprocessing with pandas Course!
I wrote this brief post to share with you the main course features, its structure, and the hands-on skills it will help you build up. I’ll also tell you a bit more about myself and the projects I’ve worked on here, at 365 Data Science.
The pandas library is one of the go-to Python tools for data manipulation and analysis. It is fast, flexible, and super valuable because it allows you to import large datasets efficiently and manipulate all sorts of information, including numerical tables, time series data, and text.
By the time you finish the course, you’ll be comfortable cleaning data from all types of sources (not just flawless ones) and preprocess it for actual visualizations and analysis by implementing the right statistical tool and advanced pandas techniques.
The Data Cleaning and Preprocessing with pandas course is a perfect fit not only for beginners, but for anyone who wants to take their Python programming skills to the next level and learn how to use pandas second-to-none features to produce a complete and consistent data analysis independently.
The course comprises 28 lectures, 105 exercises, and 10 downloadables. If you’d like to explore all topics in the course curriculum, you can find them on the Data Cleaning and Preprocessing with pandas course page.
This course covers all the pandas basics you need to know – from installation and running, to mastering and applying its rich methods and functions in your tasks.
You will learn how to:
As I mentioned, I have MSc in Economic and Social Sciences. Over the years, I have built advanced knowledge of Python programming, SQL, Mathematics, Statistics, Econometrics, Time-Series, and Behavioral Economics & Finance. My experience includes assisting in empirical research for Innocenzo Gasparini Institute of Economic Research. I’ve also worked for DG Justice and Consumers at the European Commission where I dealt with data pre-processing; data quality checking; econometric and statistical analyses. You can learn more about me and my overview of the most in-demand programming languages in my 365 Meet-the-Team Interview.
The Data Cleaning and Preprocessing with pandas course is part of the 365 Data Science Program, so enrolled students can access the courses at no extra cost.
If you aren’t a current subscriber, now is the best time to save 60% with our time-limited Black Friday offer and get full-year access to this one and all the other 28 beginner-to-advanced courses, 136 hours of video lectures, 880+ practical exercises, and 1,500+ downloadable resources for just $139 with our annual plan.
The post New Course! Data Cleaning and Preprocessing with pandas appeared first on 365 Data Science.
from 365 Data Science https://ift.tt/2V3qqDT
Originally from KDnuggets https://ift.tt/3pZaReM
Originally from KDnuggets https://ift.tt/3qaRb7Y
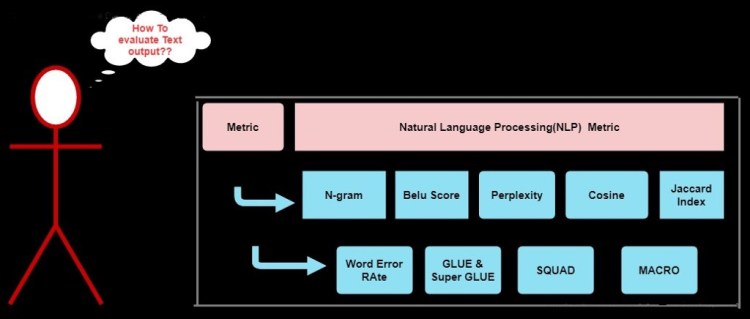
This is the fourth part of the metric series where, we will discuss about evaluation of the ML/DL model using metric NLP model are little tricky to evaluate because the output of these model is text/sentence/paragraph. So, we have to check the syntactical, semantic and well as the context of the output of the model So we uses different types of techniques to evaluate these model.
Before we start to dig deep, lets have some basic intuition about NLP model. NLP deals with Natural Language Processing i.e. it deals with the text data. We all know that ML model take input as numerical value i.e. numeric tensor and give numeric output. So we need to convert these text data into numerical format for this we have various preprocessing techniques such as Bog of Words. Word2vector, Doc2vector, Term Frequency(TF), Inverse Term Frequency(ITF), Term Frequency-Inverse Term Frequency(TF-IDF) or you can do manually by various techniques. For now you don’t need to get carried away just assume that Text have been converted by some algorithm or method into numerical value and vice versa.
1. How to automatically deskew (straighten) a text image using OpenCV
3. 5 Best Artificial Intelligence Online Courses for Beginners in 2020
4. A Non Mathematical guide to the mathematics behind Machine Learning
In ML gram is refers as word and N is an integer. So N-gram refers to the count of words in a sentence, if a sentence is made-up of 10 words it will be called as 10-gram. It is used to predict the probability of the next word in the sentence depending how the model is trained i.e. om Bigram trigram and so on using the probability of occurrence of the word related to its previous word.

Jupyter Notebook Link
BELU stand for the BiLingual Evaluation Understudy — it was invented to evaluate the language translation from one language to another.
Steps to calculate BELU are as follows:
Step 1: From the predicted word assign the value 1 if the word matches with the training set else assign 0.
Step 2: Normalise the count so that it is has range of [0–1] i.e. total count/no. of words in reference sentence.

BELU with N-grams
As I have mentioned that we assign 1 if the predicted word matches with the training set and there is a case where the words are repeated and it can have have BELU score of 1. In this case we use combination of the words i.e. N-gram to extract the order or the word in sentence. We also limit the number of times to count each word based on the highest number of times it appears in any reference sentence, which helps us avoid unnecessary repetition of words. Finally, we try to mitigate the loss of detail in the sentence produced by the sentence at least equal to the reference sentences or sentence in the training or larger than it set by introducing brevity_penality.

Problem with the BELU Score are as follows:
Jupyter Notebook Link
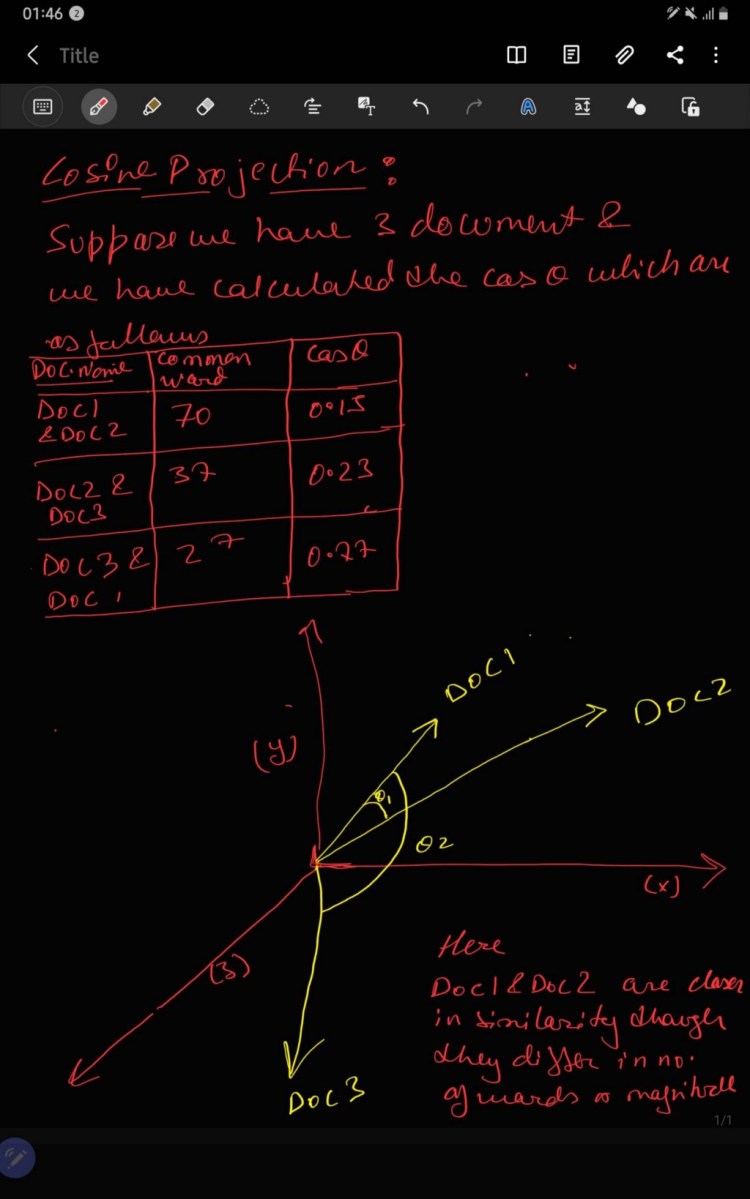
It is a metric which is used to define the similarity between two documents earlier commonly used approach which was use to match similar documents is based on counting the maximum number of common words between the documents. But this approach has flaw i.e. the size of the document increases, the number of common words tend to increase even if the two documents are unrelated. As a result cosine come into existence which removed the flaw of “ count the common word or the euclidean distance.
Mathematically, cosine is the measurement of the angle between two vectors projected in a multi-dimensional space. In this context with the NLP, the two vectors arrays of word counts of associated with the two documents. Cosine calculate the direction instead of the magnitude where as the euclidean distance calculate magnitude. It is is advantageous because even if the two similar documents are far apart by the Euclidean distance because of the size (like, the word ‘cricket’ appeared 50 times in one document and 10 times in another) they could still have a smaller angle between them. Smaller the angle, higher the similarity.

Projection of Cosine Similarity is shown below:
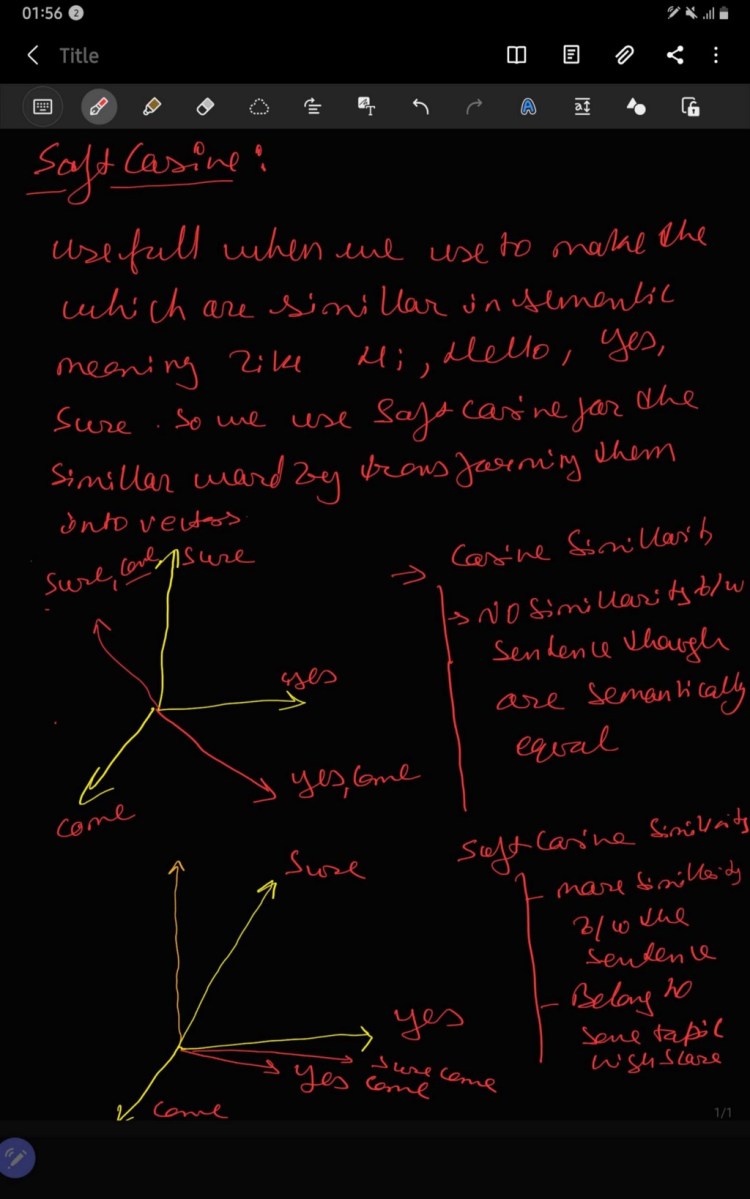
Suppose if you have another set of documents on a completely different topic, say ‘food’, you want a similarity metric that gives higher scores for documents belonging to the same topic and lower scores when comparing docs from different topics. So we need to consider the semantic meaning i.e. words similar in meaning should be treated as similar. For Example, ‘President’ vs ‘Prime minister’, ‘Food’ vs ‘Dish’, ‘Hi’ vs ‘Hello’ should be considered similar. For this, converting the words into respective word vectors, and then, computing the similarities can address this problem by soft cosine.
Jupyter Notebook Link
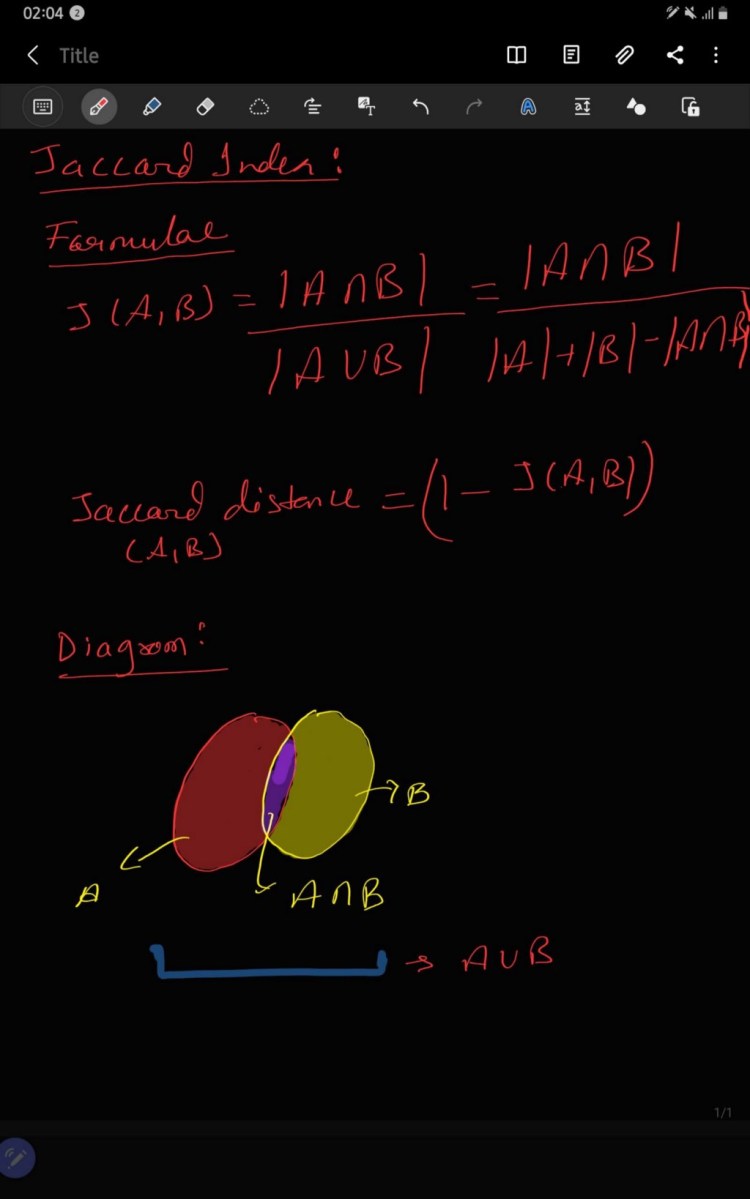
Jaccard Index is defined as the Jaccard similarity coefficient — used to understand the similarity or diversity between two finite sample set and have range [0, 1]. If the data is missing in the sample set it is replaced by zero, mean or the missing data is produced by the k-nearest algorithm or Expectation Maximisation Algorithm (EM algorithm).
Jupyter Notebook Link
WER is derived from the Levenshtein distance i.e. working at word level instead of the phoneme level. Word Error Rate is one of the most common metric use to compare the accuracy of the transcript produced by speech recognition APIs as well as machine translation system. Instead of working with the phoneme level WER work with the word level. It is very important metric when we compare one system with other system and as well as evaluating the subsystem but it does not provide the nature of translation error.
This problem is solved by first aligning the recognized word sequence with the reference (spoken) word sequence using dynamic string alignment. Examination of this issue is seen through a theory called the power law that states the correlation between perplexity and word error rate.
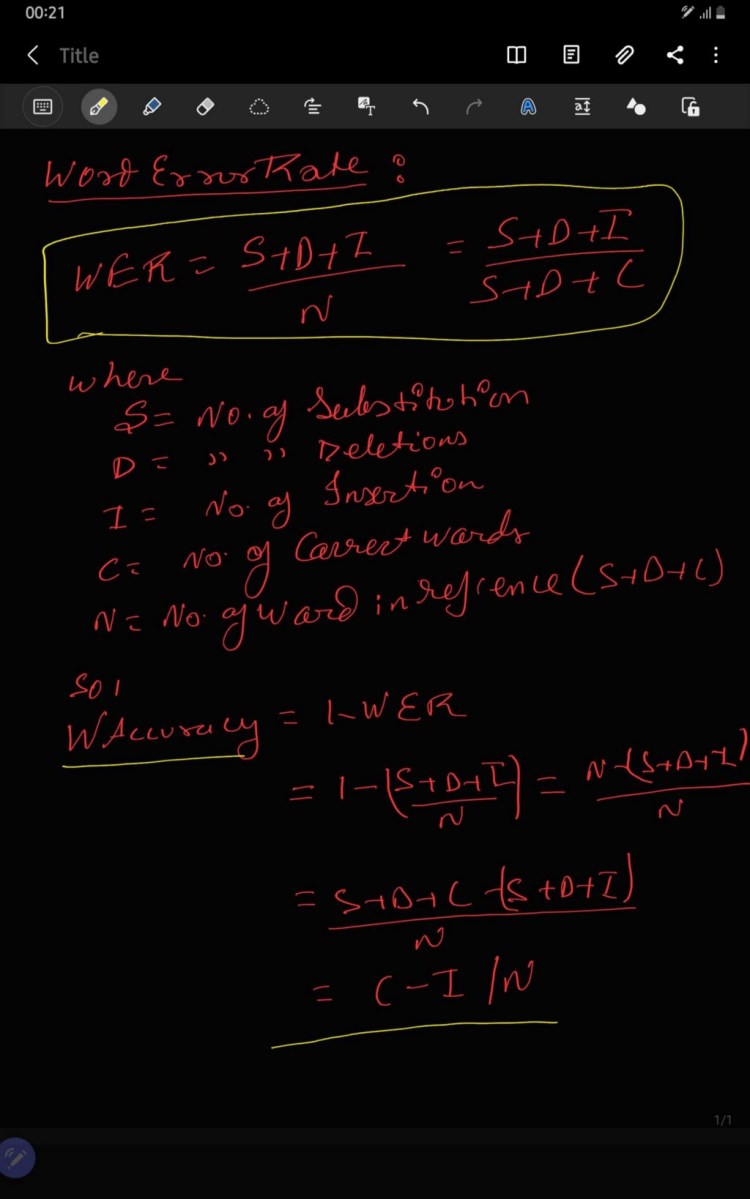

Jupyter Notebook Link
ROGUE stands for Recall- Oriented Understudy for Gisting Evaluation is collection of the metric for evaluation of the transcripts produced by the machine i.e. generation of summarise text and as well as the text generation by NLP model based on overlapping of N-grams.
The metrics which are available in ROGUE are as follows:
ROUGE-N: Overlap of N-grams between the system and reference summaries.
ROUGE-1 refers to the overlap of unigram (each word) between the system and reference summaries.
ROUGE-2 refers to the overlap of bigrams between the system and reference summaries.
ROUGE-L: Longest Common Subsequence (LCS) based statistics. Longest common subsequence problem takes into account sentence level structure similarity naturally and identifies longest co-occurring in sequence n-grams automatically.
ROUGE-W: Weighted LCS-based statistics that favors consecutive LCSes .
ROUGE-S: Skip-bigram based co-occurrence statistics. Skip-bigram is any pair of words in their sentence order.
ROUGE-SU: Skip-bigram plus unigram-based co-occurrence statistics.
NIST stands for National Institute of Standard and Technology situate in the US. This metric is use to evaluate the quality of text produced by the ML/DL model. NIST is based on BELU score -calculate n-gram precision by giving equal weight to each one where as NIST calculates how much information is present in N-gram i.e. when model produces correct n-gram and the n-gram is rare them it will ne given more weight. In simple words we can say that more weight or credit is given to the n-gram which is correct and rare to produce as compared to the n-gram which is correct and easy to produce.
Example, if the trigram “task is completed” is correctly matched, it will receive lower weight as compared to the correct matching of trigram “Goal is achieved”, as this is less likely to occur.
SQUAD refers to Stanford Question Answering Dataset. It is collection of the dataset which includes the Wikipedia article and question related to it. The NLP model are trained on this dataset and try to answer the questions. SQUAD consist of 100,000+ question answer pairs and 500+ articles from Wikipedia. Though it is not defined as a metric but it is used to judge the model usability and predictive power to analyze the text and answer question which is very crucial in NLP applications like chatbot, voice assistance chatbots etc.
The key feature of SQUAD are as follows:
MACRO stands for Machine Reading Comprehension Dataset similar to SQUAD, MACRO also consist of 1,1010,916 anonymized question collected from Bing’s Query Log’s with answers purely generated by humans. It also contains human written 182,669 question answers — extracted from 3,563,535 documents.
NLP models are trained on this dataset and try to perform the following tasks:
How to evaluate the Machine Learning models? — Part 4 was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.

